日志服务托管服务数据加工已经发布,参考: https://yq.aliyun.com/articles/704935
背景
使用日志服务,在搜索、分析时是否经常遇到以下数据格式规整的痛点?

1. 采集时ETL的痛点:
- 交换机、服务器、容器、Logging模块等,通过文件、标准输出、syslog、网络等途径收集时,里面是各种日志格式的混合,只能做部分提取,例如使用logtail先提取某些基础字段,例如时间、log level、IP等,但是日志主体
message中很多有价值的信息因为混合了各种日志,无法在导入时提取? - 单一场景下的日志,例如NGNIX,的
QueryString中的字符串,或者HttpCookie、甚至HttpBody信息等,里面字段内容变化巨大,格式信息复杂度也很高,难以在提取的时候一次性使用正则表达式完成提取。 - 某些常规日志包含了敏感信息(例如秘钥的密码,用户手机号、内部数据库连接字符串等),很难在提取时过滤掉或者做脱敏。
- 某些JSON日志信息包含多条日志,需要分裂为多条日志进行处理等,但无法操作?
- 其他方法例如使用SDK规则后再上传、通过Logstash channel转换后导入等方法试图解决时,事情变得复杂,数据收集的性能也变得更慢?

2. 查询分析时做ETL的痛点:
- 因为日志非常复杂,SQL本身处理时,语句膨胀的比较厉害,难以修改和维护?
- 好不容易使用SQL的正则表达式完成了某一类日志的提取,但是因为计算的动态字段没有索引,性能又受到很大影响?
- 某些字段的关键字名都是不固定,例如KV格式、甚至待转义的KV等,使用SQL提取字段时,更加困难。
- 对多个特定字段进行
lookup富化时,Join后多个关联的复杂度和性能比较难以接受。 - JSON日志格式的分析有一定的限制,例如:基于数组的对象内容无法很好的分析、复杂的JSON格式无法很好关联等。
3. 投递归档时做ETL的痛点:
- 投递到OSS、MaxCompute等并不支持内容上的过滤或者格式转换?
4. 对接外部系统做ETL时的痛点:
- 可以在其他系统(例如DataWorks、FunctionCompute)等中将日志导入进行规整后再导回日志服务,但在整个过程中因为要解决编程、配置、调试等方面的工作,相对要耗费不少功夫。
5. 花费大量时间在ETL上
以上只是部分举例,事实上,这些都是非常典型的ETL的问题。并且在业界,一种普遍的共识是大数据分析中大部分时间(有时达到80%)花费在了数据规整(Data Wangling、或者ETL)上,真正重要的分析在时间占比上反而并不高。

概述
我们希望提供一套简单的(稍微配置一下)、可靠(性能、稳定性、扩展性)、一站式的(不引入额外资源、概念、技术)的方案来缓解在以上日志服务场景中的主要ETL相关的痛点。

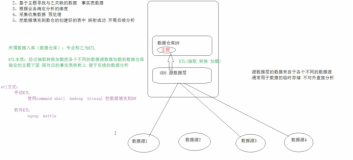
我们首先提供命令行工具(通过日志服务 CLI)的方式的解决方案,可以看到,通过命令行工具+简单配置文件将源日志库中日志经过处理后流出到另外一个logstore。与托管服务比起来,更加灵活、强大、可控性强,但需要您在特定Region部署运行环境。
从经济角度出发,推荐将源logstore保留1-7天,临时存储,无索引,将目标logstore作为真正分析消费的logstore。
运行场景1:实时流式处理, 自动平衡与恢复
通过依赖日志服务的消费组,完成实时流式处理,并可以自动获得负载均衡与断点恢复功能,而这些都不需要编程和额外配置:

运行场景2:批处理历史数据
通过相对直接的方式,并发、切分的方式,将特定时间段、分区的日志进行ETL处理:

使用场景1:自由编排
通过一个简单的Python风格的配置文件进行编排,一般情况下不需要写代码即可达到80%的ETL的需求和自由度:

提供内置的编排能力包括如下,并具备扩展能力:
- 分派转换
- 串联转换
- 分裂事件
- 保留事件
- 丢弃事件
- 保留字段
- 丢弃字段
- 自动提取KV
- 重命名字段
这里的配置文件选择Python,而不是其他如JSON、YAML、ini、XML等方式,主要是以下几个原因:
- 使用通用语言例如Python,比使用一套JSON、YMAL上的DSL(Domain Specific Language)要灵活、简单、学习曲线平滑。
- Python本身语言特性有利于学习和扩展,Python自身对于数据结构的灵活性和处理就很强(无论是tuple、dict、list、set、字符串)还是函数式计算(map、filter、reduce、labmda等)支持都是非常自然的。这就使得其做数据处理时,代码简单易读。
- Python扩展性和生态比较强大,可以借力丰富的Python库做任何自由的ETL处理。默认任意的Python库都可以无缝作为ETL的插件进行使用、Python的其他生态工具都可以支持ETL的编写与调试等。
- 性能上使用Pypy与多进程可以较好的解决Python的GIl与性能问题。
使用场景2:使用内置转换模块
日志服务CLI ETL功能提供了完整的内置的处理模块,尤其对于正则表达式、KV、JSON、Lookup等支持灵活且完整。总体内置转换模块对常规ETL转换支持度完整,可以覆盖总体80%的转换需求:
- 设置列值(静态/复制/UDF):各种函数计算支持
- 正则提取列:正则的完整支持,包括动态提取字段名等
- CSV格式提取:CSV标准的支持
- 字典映射:直接字段映射
- 外部CSV多列映射:从外部CSV关联对数据进行富化,支持宽匹配等。
- 自动KV:自动提取KV,也支持自定义分隔符、auto-escape场景
- JSON自动展开:支持自动展开JSON内容,包括数组,支持展开过程的定制。
- JSON-JMES过滤:支持基于JMES的动态选择与计算后再处理。
- 分裂事件(基于JSON数组或字符串):基于字符串数组或JSON数组进行事件分裂
- 多列合并(基于JSON数组或字符串):基于字符串数组或JSON数组进行多字段合并
使用场景3:扩展插件或UDF
理论上任意Python的库都可以无缝在配置文件中使用,与此同时,内置的模块也提供了更加轻量级的细微的策略或者逻辑上的UDF支持:
编排级别扩展:
- 保留事件
- 丢弃事件
- 分裂事件
- 分派转换
- 串联转换
- 自定义条件转换
内置函数扩展:
- 设置列值-动态值
- JSON自动展开格式
一个例子
这里我们举一个服务器上多钟复杂日志格式的混合通过syslog发送给日志服务后的ETL的例子:
部署安装
推荐使用pypy3来安装部署:
pypy3 -m pip insall aliyun-log-python-sdk>= 0.6.42 aliyun-log-cli编写配置文件
可以使用任何Python适配的编辑器(例如sublime、Pycharm、VIM等),推荐自带Python插件的工具,这样可以自动高亮代码以及检查语法错误。
# 丢弃所有无关的元字段,例如__tag:...___等
DROP_FIELDS_f1 = [F_TAGS, "uselss1", "useless2"]
# 分发:根据正则表达式规则,设置__topic__的值
DISPATCH_EVENT_data = [
({"data": "^LTE_Information .+"}, {"__topic__": "let_info"}),
({"data": "^Status,.+"}, {"__topic__": "machine_status"}),
({"data": "^System Reboot .+"}, {"__topic__": "reboot_event"}),
({"data": "^Provision Firmware Download start .+"}, {"__topic__": "download"}),
(True, {"__topic__": "default"})] # 不匹配的默认__topic__值
# 转换:根据特定__topic__使用特定正则表达式,对字段`data`进行字段提取
TRANSFORM_EVENT_data = [
({"__topic__": "let_info"}, ("data", r"LTE_Information (?P<RSPR>[^,]+),(?P<SINR>[^,]+),(?P<global_cell_id>[^,]+),")),
({"__topic__": "machine_status"}, ("data", r"Status,(?P<cpu_usage_usr>[\d\.]+)% usr (?P<cpu_usage_sys>[\d\.]+)% sys,(?P<memory_free>\d+)(?P<memory_free_unit>[a-zA-Z]+),")),
({"__topic__": "reboot_event"}, ("data", r"System Reboot \[(?P<reboot_code>\d+)\]")),
({"__topic__": "download"}, ("data", r"Provision Firmware Download start \[(?P<firmware_version>[\w\.]+)\]"))
]这里虽然是Python文件,但并没有任何编程内容,但却可以借助于Python的工具进行语法校验。
运行程序
批量运行,这里仅仅针对shard 0做一个2分钟的数据ETL做一个检验:
aliyunlog log transform_data --config=./my_etl.py --project=p1 --logstore=abc --to_project=p2 --to_logstore=xyz --to_client=account1 --client-name=account2 --shard_list=0 --from_time="2019-1-15 12:59:00+8:00" --to_time="2019-1-15 13:01:00+8:00"验证OK后,可以直接使用持续运行,额外增加一个参数cg_name即可(表示消费组名称):
aliyunlog log transform_data --config=./my_etl.py --project=p1 --logstore=abc --to_project=p2 --to_logstore=xyz --to_client=account1 --client-name=account2 --from_time="2019-1-15 12:59:00+8:00" --cg_name="elt1"进一步资料
相关链接
- 日志服务SLS命令行工具(CLI)
- 依赖的模块Python SDK
- Github上的ETL的配置代码案例
- 扫码加入官方钉钉群 (11775223):