一、MySQL+Redis常用部署方式
1.1 拓扑
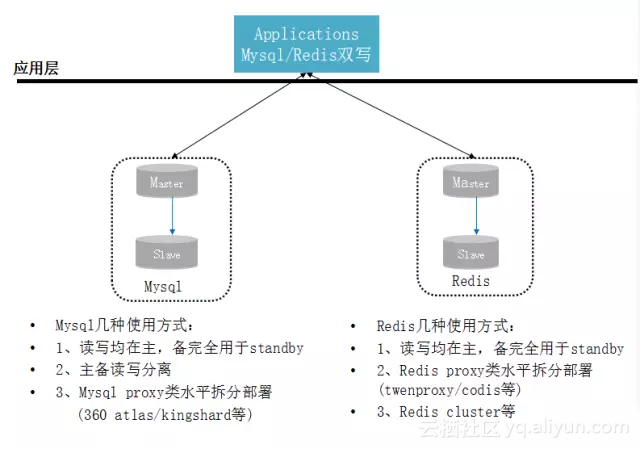
1.2 特点
业务层通过双写同时写MySQL及Redis。读通常在Redis,若读取不到,则从MySQL读取,然后将数据同步到Redis,Redis通常设置expire或者默认LRU进行数据淘汰。
这种使用方式会有如下问题:
1)MySQL及Redis存在数据不一致风险,尤其是长时间运行的系统
2)业务层需要处理MySQL sql schema与Redis kv数据结构上的逻辑差异
3)无统一运维
4)无法方便扩容/缩容
二、KV化的存储使用理念
2.1 MySQL Is great NoSQL
参考文档:
http://www.aviransplace.com/2015/08/12/Mysql-is-a-great-nosql/
为什么要用MySQL:
“在可扩展系统构建时,一个很重要的考量是使用的技术是否成熟,选择成熟的技术意味着出错时能够迅速恢复。当然,开发者也可以在项目中使用最新最牛的NoSQL数据库,而这个数据库在理论上也可以良好地运行,然而在生产环境中出现了问题恢复需要多久?技术上已有的知识和经验积累对于问题缓解至关重要,当然这个积累也包括了Google可以搜索到的内容。
相比之下,关系型数据库已经存在了超过四十年,业界对于关系型数据库的维护也积累了大量的经验。基于这些考虑,在新项目做技术选型时通常会选择Mysql,而不是NoSQL数据库,除非NoSQL真的有非常非常明显的优势。”
2.2 KV理念
对于亿级规模的数据存储,尤其是涉及到水平拆分跨机分库分表的情况下,线上对数据库的访问只能做的越简单越好,group by/order by/分页/通用join/事务等等的支持 在这个量级下的MySQL系统都是不合适的。
基本上目前所有的类proxy的MySQL方案真正上规模线上应用只能使用按拆分键进行读写操作,实际上也是一个用拆分键做的一个kv系统。
若想使用复杂的sql处理,最合理的部署方案是将Mysqlbinlog流水同步服务抽象出来,通过实时同步到OLAP类的系统进行处理。
所以面向海量存储服务,MySQL从一开始就设计为一个KV系统是可行的。value使用mediumblob存储xml/json/protobuf/thrift格式化数据序列化之后的数据。
2.3 MySQL KV化的使用方式
1、用MySQL原来的主键或者索引键当做key
2、其他所有的非主键非索引键,全部包装到value里面,value使用mediumblob存储xml/json/protobuf/thrift格式化数据序列化之后的数据。
3、数据读写操作,均基于key一整行数据做读写,由业务层对里面value的结构做解析及对内部结构做增删改差,而不用变更MySQL本身的schema.
2.4 不适用场景
1、数据量和访问量不大并且业务逻辑依赖MySQL数据库进行处理的业务场景
2、涉及到多表join等的处理
对于此限制,也可以通过将关联表加工成基于关联条件的一张宽表进行KV化。
3、涉及到事务等的处理。
三、将MySQL+Redis设计为统一的KV存储服务
3.1 目标
1)业务层通过统一方式访问MySQL及Redis,不再使用MySQL客户端及Redis客户端访问
2)MySQL集群化/Redis集群化部署
3)将业务双写改为MySQL到Redis底层binlog数据同步方式完成同步
4)异构数据存储支持最终一致性数据读写服务
5)支持存储层面扩容缩容、failover且业务无感知
6)单机群日百亿次QPS/TPS支持(大类业务适度拆分到不同集群中)
3.2 最终实现
基于MySQL+Redis的统一存储服务(UniStore) =
MySQL跨机分库分表集群
+ Redis集群
+ MySQL->Redis实时数据同步服务
+ 统一的对外数据访问接口
+ 内在的完整运维支持系统(支持在线扩容/缩容、failover等)
3.3 架构图
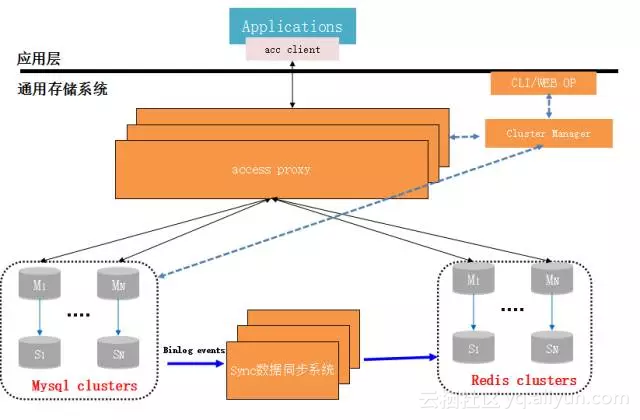
3.4 架构说明-将存储设计为一种服务
1、将MySQL+Redis做成统一KV存储服务
2、通过acc proxy提供统一的数据访问接口,通过统一协议支持跨语言数据访问
访问协议(自定义协议,protobuf协议,thrift协议等)
3、MySQL cluster支持跨机的分库分表,schemaless设计,所有业务表KV化设计
4、Redis cluster支持跨机的实例拆分
5、Sync数据同步服务提供统一的Mysql到Redis 跨IDC/不跨IDC数据同步服务,小于100ms延时
6、整个系统不涉及到分布式事务处理
3.5 三种部署方式
1、纯MySQL集群部署
此种部署方式等同于其他MySQL proxy跨机分库分表方案,读写均在MySQL
2、纯Redis集群部署
此种部署方式等同于其他Redis proxy跨机分库分表方案,读写均在Redis
3、MySQL+Redis异构部署
写在MySQL,读可以从MySQL读或者Redis读,取决于业务对最新数据的读取要求。
3.6 接口说明
1、int get(int appid, string key,string& value)
Redis读操作专用
2、int get_with_version(int appid,string key, string& value, int64& version)
MySQL读操作专用,自带版本号,防止写覆盖
3、int set(int appid, string key,string value, int64 version)
通过appid区分MySQL还是Redis,均支持写操作
4、int delete(int appid, string key)
通过appid区分MySQL还是Redis, 不支持批量删除
5、int multiget(int appid,vector<string> keys, map<string, string>& key_value_pairs)
支持批量读操作,内部的数据路由及数据合并不用关心
6、intmultiset(int appid, map<string, string>& key_value_pairs)
不建议支持,涉及到跨机事务问题,无法保证ACID
7、int Redis_op(string cmd, ……)
Redis其他原生接口封装(incr/expire/list/setnx等)
四、Cluster Manager服务
4.1 Cluster Manager是一个service
cluster manager主要由如下几种功能
1)MySQL/Redis分片路由信息的管理
1、MySQL分库分表路由信息
2、Redis Slot路由信息
3、路由信息变更管理
2)Redis实例的探活及Redis扩容及缩容数据的迁移
比如连续3次,每次间隔30sRedis ping失败,认为实例挂掉,发出报警或者自动切换
3)Cluster manager不建议参与Mysql group主备层面的管理
MySQL主备层面的集群管理方案:
1、MHA+VIP (互联网公司最常用)
2、微信phxsql系统:https://github.com/tencent-wechat/phxsql 金融级可靠性
五、MySQL集群方案
5.1 架构图
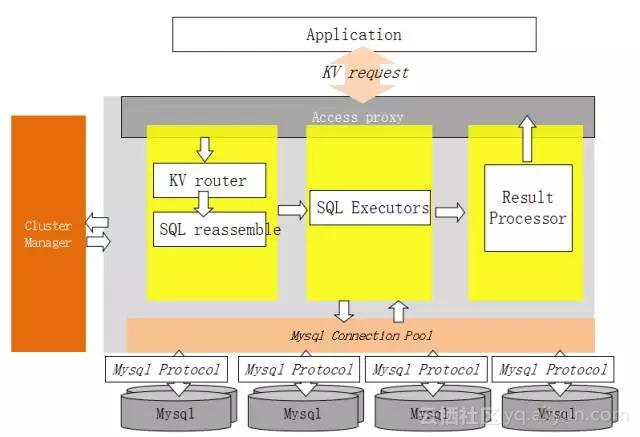
5.2 设计原则
1)统一的schemaless表结构
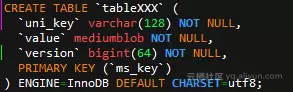
2)跨机的数据分布
支持将单逻辑表水平拆分到多个Mysql服务器中
3)其他说明
1、数据存储可靠性高,所有业务数据通过序列化存储到value列
2、每行数据自带版本号,业务通过cas方式防止业务层多实例同时写造成写覆盖
全局唯一版本号实现:本机微秒时间戳+server_id+proccess_id
3、固定百库百表/百库十表的数据拆分方式,多机跨Mysql实例部署
5.3 路由策略
1) 一致性hash
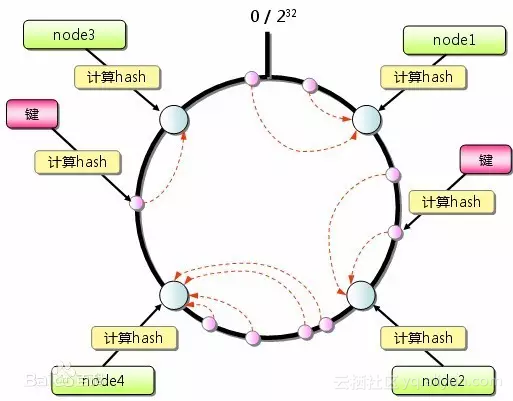
2) 路由计算算法
crc32/md5/基于字符串的各类hash算法
3) 路由信息格式
CREATETABLE `Mysql_shard_info` (
`appid` int(32) NOT NULL,
`begin` int(32) NOT NULL,
`end` int(32) NOT NULL,
`ip` varchar(20) NOT NULL DEFAULT '',
`port` int(11) NOT NULL DEFAULT '0',
`user` varchar(50) NOT NULL DEFAULT '',
`pwd` varchar(50) NOT NULL DEFAULT '',
PRIMARY KEY (`appid`,`begin`)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
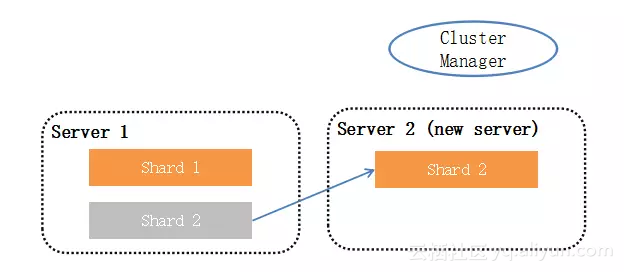
5.4 数据迁移/自动扩展
数据迁移:
STEP1:利用MySQL主备复制机制进行数据复制
STEP2:数据差异小于某一临界值,停止老分片写操作(read-only)
STEP3:等待新分片数据更新完毕
STEP4:更路由规则路由规则,Cluster Manager向所有access proxy更新路由信息
STEP5:删除老分片
自动扩展:
过程类似于数据迁移
六、Redis集群方案
6.1 部署方式
1、异构读写分离-MySQL写,Redis读
1) 数据写操作在MySQL,读操作在Redis
2) 数据通过Sync系统对binlog进行解析从Mysql同步到Redis
3) 数据有同步延迟(小于100ms),实现最终一致性
适用场景:要求数据高可靠,且读量比较大,允许读数据短时间不一致,若期望一直读到最新数据,请使用get_with_version()接口从MySQL读取
2、独立的Redis集群服务
1)读写均在Redis,提供独立的KV存储服务
2) 用户不用关注扩容/缩容/故障恢复等问题
3) 集群内多业务混存,提高内存的使用率
适用场景:独立的Redis集群服务,类似twenproxy/codis
6.2 设计要点
1、一致性hash
支持数据跨Redis实例拆分,固定Slot数进行拆分
2、单机多实例部署
1)每个物理机支持多Redis实例
2)每个Redis实例只服务单个业务
3)Redis实例内存大小取决于业务需求,同时考虑业务访问量和数据量
以RedisIP+port标示唯一实例,对于128G内存机器,
可配置3 Redis实例*每实例30G
或10 Redis实例*每实例10G
或20 Redis实例*每实例5G
拆分原则:单实例最大内存使用 < 本机剩余内存
3、以Slot为单位的平滑扩容/缩容
4、以Redis实例为单位的failover处理
6.3 平滑扩容/缩容
主要步骤如下:
STEP1:确认扩容/缩容
Cluster manager通过对系统负载和数据量进行告警,进而确认进行扩容或者缩容
STEP2:修改路由表
1)修改路由表,将对应shard的状态修改为migrate状态,并将新路由推送到所有接入层
2)acc proxy会将写操作转到新的Redis实例中,读操作默认先读新Redis实例,key不存在会继续从老的Redis实例中读取
STEP3:数据迁移
1)Cluster manager通过自动数据迁移工具开始数据迁移,计划依赖Redis的scan命令将相关的key扫出来,通过MIGRATE进行数据迁移
2)多次扫描执行该过程,确认Slot中所有数据迁移完成
STEP4:修改路由表,迁移完成
Cluster manager将读写均切到新Redis实例,不再从老Redis中进行操作
七、Sync数据同步服务
7.1 架构
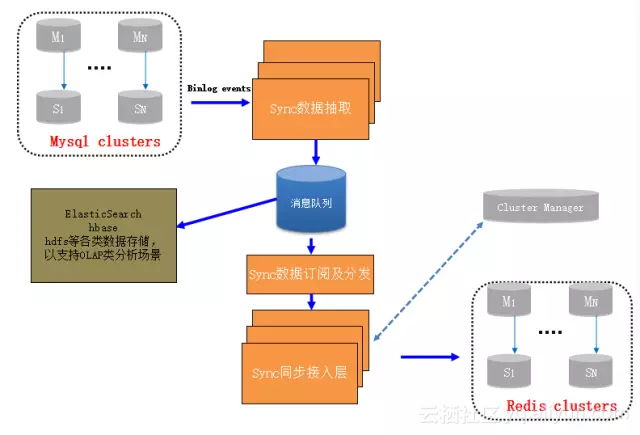
7.2 应用场景
该服务完全可以抽象成独立的数据同步分发服务,对于因为KV化而丢失的sql处理完全可以通过该服务同步到偏OLAP类的系统中进行处理。除了同步到Redis还可以同步到ElasticSearch或者hbase或者写hdfs文件基于hadoop生态去实现复杂计算和分析。
7.3 设计要点
1、集群对集群的实时数据同步
MySQL统一要求binlog日志为row格式
2、不涉及DDL处理
由于MySQL schemaless的设计,不用考虑DDL处理,简化同步服务(跨/不跨IDC)
3、基于时间戳的同步延迟监控
MySQL binlog row格式日志自带时间戳,基于此时间戳进行同步延迟监控
4、基于binlog文件名+offset的同步位置管理
定时定量持久化保存当前同步的binlog文件名及offset,用于各种场景下的同步恢复
5、基于行的并行同步
多线程同步模式,主线程通过对tableid或者key做hash,将binlogevent时间分发到对应worker线程的队列中,worker线程依次从队列中获取binlog event执行
7.4 实现原理
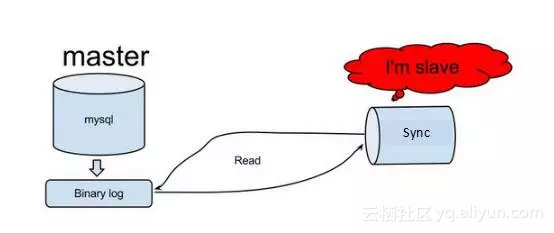
原理相对比较简单:
1)Sync同步工具模拟Mysql slave的交互协议,伪装自己为MySQLslave,向Mysqlmaster发送dump协议
2)Mysqlmaster收到dump请求,开始推送binary log给slave(也就是同步工具)
3)Sync同步工具解析binary log对象(原始为byte流),并转换成Redis或其他存储(hdfs/hbase/ES等数据库)相应数据操作接口或者作为消息存储到MQ中(rocketmq或者kafka)
7.5 ROW格式events
MySQL 5.5 Binlog的事件类型有多种,这里只介绍与ROW模式相关的事件
1) QUERY_EVENT:与STATEMENT模式处理相同,存储的是SQL,主要是一些与数据无关的操作,eg: begin、drop table
2) TABLE_MAP_EVENT:记录了下一条事件所对应的表信息,在其中存储了数据库名和表名
3) WRITE_ROWS_EVENT:操作类型为insert
4) UPDATE_ROWS_EVENT:操作类型为update
5) DELETE_ROWS_EVENT:操作类型为delete
6) XID_EVENT, 用于标识事务提交(commit)
典型的insert语句有如下4个events组成:

7.6 其他开源同步方案
1. tungsten-replicator(JAVA)
http://code.google.com/p/tungsten-replicator/
2. linkedin databus(JAVA)
https://github.com/linkedin/databus
3. Alibaba canal(JAVA)
https://github.com/alibaba/canal /
分享者简介:



