阅读国外的技术博客和技术网站是跟随时代脚步的重要方式,Netflex 有自己的开源门户OSS,更是微服务架构的推崇者,拥有自己的微服务架构技术站,其技术博客中有不少干货,于是在地铁阅读时光里便有了这篇译文。
原文自:
http://techblog.netflix.com/2016/05/application-data-caching-using-ssds.html
随着Netflix的全球化扩张,也带来了数据的急剧膨胀。在Active-Active 项目和现在的N+1架构之后, 最新的个性化推荐数据遍布各地,在任何时间服务于所有地区的任何人。缓存作为用户个性化推荐数据的驻留层扮演着一个非常关键的角色。
在Netflix架构中有两个基本元素,一个是控制平面,运行在AWS之上,用于用户登录,浏览和播放以及一般性服务。另一个是数据平面,叫做Open Connect, 这是一个全球性的视频分发网络。本文介绍了如何在EVCache中利用经济的SSD能力,EVCache是Netflix中所使用的基本缓存系统,它运行在AWS的控制平面。
使用EVCache的一个典型用例是对个性化数据作全局的副本存储,服务于8100万Netflix用户。EVCache 在Netflex内部扮演着不同的角色,处理保存用户的个性化推荐数据,还包括作为标准的缓存工作集来存储用户的信息。但是最大的角色还是个性化推荐。为任何地区的任何人服务意味着,我们必须为已运营的三个地区的每个人持有用户的个性化推荐数据。这保证了所有AWS 可用区的一致性体验,同时便于切换区域间的流量来平衡负载。http://techblog.netflix.com/2016/03/caching-for-global-netflix.html 已经介绍了全球化的副本系统。
在稳定状态,在Netflex的区域内可以反复地看到同一个用户,区域切换对用户而言并不是常态。尽管数据在三个区域的内存中,只有一个区域中的每个用户正常使用。由此推断,在每个区域有着这些缓存的不同工作集,一个小的子集是热数据,其他是冷数据。
除了冷热数据的分类之外,所有在内存中的这些数据存储成本随着用户的基数在增加。 另外, 不同的 A/B 测试和其他的内部改变增加了更多的数据。对于用户的工作集,Netflix已经有了数十亿的主键,而且数目还在增长。面对的挑战是持续支撑Netflix业务并平衡成本,从而引入了多级缓存机制,即同时使用 RAM 和SSD。
基于EVCache 充分利用这种全局化请求发布和成本优化的项目叫做 Moneta, 源自拉丁记忆女神的名字,也是罗马神话中财富守护神——Juno Moneta。
当前的架构
先看一下 EVCache 服务器的当前架构,然后讨论如何演变成对SSD 的支持。
下图展示了EVCache 的典型部署结构和单节点客户端实例于服务器的关系。一个EVCache客户端连接了多个EVCache的服务器集群。 在一个区域内,Netflix有多个全数据集的拷贝,由AWS的可用区隔离开来。虚线框描述了区域内的副本,每个拥有数据的全量拷贝作为一个单元,作为隔离AWS的自动伸缩组来管理这些拷贝。某些缓存在一个区域内有两个拷贝,有的拥有更多。这种高层架构对我们长期来看还是有效的,不会改变。每个客户的连接自己区域内所有可用区的所有服务器。写操作被发往所有的拷贝,读操作优先选择离读请求近的服务器。关于EVCache 架构的更多细节,参见最初的博文。
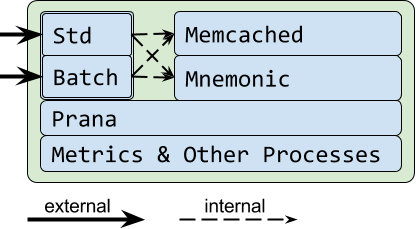
在过去的几年中,这一服务器已经包含了一组进程,两个主要的进程是: Memcached, 一个流行的且久经考验的内存型键值对存储,和 Prana, 这是一个 Netflix sidecar 进程。 Prana 是连接Netflix 生态系统中其他服务的服务器,也是基于Java开发的。客户端直接连接运行在每个server上的Memcached进程。服务器是独立的,互相之间不通信。

优化
EVCache作为Netflix云中最大的子系统之一,在系统优化中占有相当的比例,位置独一无二。将所有数据存储在内存的成本随着用户基数的增长而上扬,单日个性化批处理输出将加载超过5 T的数据到专用的 EVCache 集群。 数据存储成本是所存储数据与全局副本个数的乘积。如前所述,不同的 A/B 测试和其他内部数据也增加了更多的数据。对于用户的工作集,如今已经有数十亿的键值,而且在持续增加。
根据不同区域不同的数据访问的情况,Netflix 构建了一个系统将热数据存储在RAM ,冷数据存储在硬盘。这是典型的两级缓存架构 ( L1 代表 RAM,L2 代表硬盘), Netflix的工程师依赖于EVCache的强一致性和低时延性能。面对尽量低的时延需求,要使用更多的昂贵内存,使用低成本的SSD也要满足客户端对低时延的预期。
内存型 EVCache 集群运行在 AWS r3系的实例类型上,对大规模内存的使用进行了优化。通过转移到 i2 系的实例上,在相同的RAM和CPU的条件下,可以获得比SSD存储(r3 系)扩大十倍的增益 (80 → 800GB ,从 r3.xlarge 到 i2.xlarge) 。Netflix也降级了实例的大小到小型内存实例上。结合这两点,就可以在数千台服务器上作优先的成本优化了。.
Moneta 架构
Monte 项目在EVCahce 服务器中引入了2个新的进程: Rend 和 Mnemonic。 Rend 是用Go语音写的一个高性能代理,Mnemonic 是一个基于RocksDB的硬盘型键值对存储。Mnemonic 重用了Rend 服务器组件来处理协议解析 (如Memcached 协议), 连接管理和并行锁。这三种服务器都使用Memcached 的文本和二进制协议,所以客户端与它们的交互有着相同的语法,给调试或者一致性检查带来了便捷。
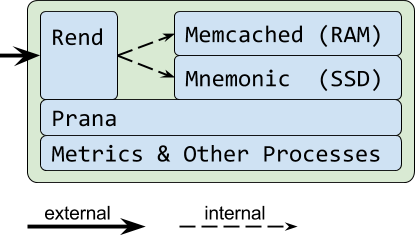
客户端以前是直接与 Memcached 连接, 现在连接 Rend. 由此开始, Rend 将处理在 Memcached 和Mnemonic之间的 L1/L2 交互。甚至当服务器不使用Mnemonic时, Rend 仍然提供了与原来使用Memcached时类似的服务器性能,例如请求时延。Rend引入的时延,与Memcached 一起工作时,平均只有几十毫秒。
作为重新设计的一部分,已经将三个进程集成在一起了。三个独立的进程运行在每个服务器上比保持分离。这种配置更好地保证了数据的持久性, 一旦 Rend 挂了,数据还可以与 Memcached 和Mnemonic进行操作。一旦客户端重新连接到Rend进程,服务器就能够服务用户的请求了。 如果Memcached 挂了,将丢失所有的工作集数据,但L2中的数据(Mnemonic) 还是可用的。一旦数据被再次请求,将重新变为热数据,和原来的服务一样。 如果 Mnemonic挂了, 它并没有丢失所有的数据,只损失了最近写入的数据。即使它丢失了数据,至少RAM中的热数据还在,对使用服务的用户还是可用的。This resiliency to crashes is on top of the resiliency measures in the EVCache client.
Rend
Rend, 如前所述, 作为另外两个真正存储数据的进程的代理,是一个高性能服务器,使用二进制和文本Memcached 协议进行通信。它是Go语言写的,依赖了其对并发处理的高性能。这个项目已经在 available on Github.上开源了。 决定使用Go时明智的,因为我们需要比Java更好的低时延(这里垃圾回收时的暂停是个问题),以及比C更好的生产效率,同时能处理成千上万的客户端连接,Go非常适合这样的场景。
Rend 的职责是管理 L1 和 L2 缓存的关系,根据不同的内部使用场景采用不同的策略,还具有裁剪数据的特性,能够将数据分割成固定的大小插入到Memcached中以避免内存分配时的pathological 行为。这种服务器侧的分片代替了客户端分片,已经证明时可行的。至此,拥有了2倍读和30倍写的速度提升。幸运的是, Memcached 的1.4.25版本, 已经对客户端异常引起的问题有了更多的健壮性处理。Netflex将来可能废弃chunking的特性 feature in the future as we can depend on L2 to have the data if it is evicted from L1.
设计
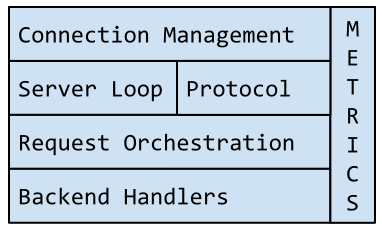
Rend的设计是模块化的,并且可配置。在内部,有这样一些分层: 连接管理,服务器循环,协议代码,请求编排和后台处理器。使用Pranna的定制化包来避免轮询信息的侵入方式。 Rend 也有着独立用来测试的客户端代码库,能够集中发行协议中的bug或者其他错误,例如错误对齐,未清除的缓存以及未完成的响应等。
Rend的设计允许不同后台的插件式嵌入,通过一个接口和一个构造函数即可。已经证明了这种设计的有效性,一个工程师在一天哪熟悉了相关代码并学习了 LMDB,把它集成起来作为了存储后台。这些代码参见https://github.com/Netflix/rend-lmdb.
生产环境的使用
作为Moneta服务最好的那些缓存,一个服务器就可以服务多种不同的客户端。一类是热路径上的在线分析流量,用户请求的个性化数据。其他是离线分析的流量和近限系统所产生的数据。这些典型的服务是整夜允许的巨量批处理和结束时几个小时的持续写操作。
模块化允许使用默认的实现来优化Netflix夜间的批处理计算,直接在 L2 中插入数据并且在 L1中更换热数据, 而不是在夜间预计算时引起L1缓存的写风暴。来自其它区域的副本数据不像是热数据,所以也直接插入 L2。下图展示了一个 Rend 进程有多个端口连接了各种后台存储。因为Rend的模块化,很容易在不同的端口上引入其它的服务器,几行代码就能实现批处理和流量副本。
性能
Rend 自身有着很高的吞吐量。独立地测试 Rend,在CPU最大化前,看一下网络带宽和包处理的限制。 单个服务器,请求不发往后端存储,可以处理 286万请求每秒。 这是原始数据,不是真正的数字。 只使用Memcached作为后端存储的话, Rend 可以承受22.5 万每秒的插入操作, 20万每秒的读操作,在Netflix最大的实例上测试的结果。一个 i2.xlarge 实例被配置成 L1 和 L2 (内存和硬盘 ) 以及 data chunking, 这是Netflix 生产集群的标准实例,能够执行 22k插入每秒(只是sets) 21k 读操作每秒 (只是 gets ), 并且是 10k sets 和 10k gets 每秒的并发。这些是生产环境的下限,因为测试数据包含了大量的随机键值从而避免了数据访问的局部性。真正的流量在L1中的命中率要比随机键值频繁的多。
作为一个服务器应用,Rend 打开了EVCache 服务器智能化的各种可能性,也完全从协议到通信实现了基础存储的解耦合。 依赖于Netflix的需要,可以将L2存储下架,将 L1 Memcached 配合上其他的存储,或者改变服务器的逻辑来增加全局锁或者一致性。这些是还没计划的项目,但是已经有定制化代码运行在服务器上了。
Mnemonic
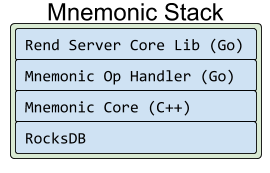
Mnemonic 是基于RocksDB的L2 解决方案,在硬盘上存储数据。协议解析,连接管理,Mnemonic 的并发控制等所有的管理都使用了和Rend 相同的库。Mnemonic 是嵌入到Rend 服务器的一个后台服务, Mnemonic项目暴露出一个定制化的C API 供Rend handler使用。
Mnemonic中有趣的部分是在 C++ 的核心层封装了 RocksDB. Mnemonic 处理 Memcached风格的请求,实现了Memcached所有行为的所需操作,包括了 TTL 支持。它包含了一个重要的特性:将请求分发到一个本地系统的多个 RocksDB 数据库,减少了每个RocksDB数据库实例的负载。 下面解释一下这么做的理由。
RocksDB
在研究过有效访问 SSD的几种技术之后,Netflix 选择了RocksDB, 一个 嵌入式键值对存储,它使用了日志结构合并树的数据结构设计。写操作首先插入到一个内存数据结构中(一个内存表),当满的时候再写入到硬盘上。当写入硬盘的时候,内存表是一个不可修改的SST 文件。这这样形成了大量的序列化写入SSD的操作,减少了大量的内部垃圾回收,改善了SSD在长时间运行的实例上的时延。
一种类型的负载已经由RocksDB的各个独立实例在后台完成了。 Netflix开始使用了有层次的精简配置,主要原因是在多个数据库中分发请求。然而,当评估生产数据的精简配置以及与生产环境类似的流量的时候,发现这样的配置会引起大量额外的SSD读写,增加了时延。SSD 读流量经常达到 200MB/sec。评估时的流量包括了长时间的高写操作,仿真了每天的批处理计算进程。在此期间,RocksDB 持续的移动了新的 L0 记录达到了一个很高的水平,放大为非常高的写操作。
为了避免过载,Netflix切换到FIFO 型的精简配置。在这种配置中,没有真正的精简操作被完成。基于数据库的最大尺寸,删除旧的 Old SST 文件。记录在硬盘的 level 0中,所以只在多个SST文件中按时间排序。这种配置的下降趋势在于读操作必须在判断一个键是否命中之前以时间倒序检查每个SST文件。这种检查通常不需要硬盘读操作, as the RocksDB的大量过滤器杜绝了高比例的对每个SST的硬盘访问。然而,SST文件的数量影响了赋值操作的有效性,将低于正常有层次风格的精简操作。初始进入系统的读写请求在多个RocksDB的分发减少了扫描多个文件的负面影响。
性能
通过最终的配置重新运行测试,在预计算负载的期间,能够得到99% 的读请求时延在9ms左右。 在预计算负载完成后,对于相同水平,99% 的读操作削减到 ~600μs。 所有这些测试都在没有Memcached 和 RocksDB 块缓存的情况下运行。
这种方案可以有更多的变种,可以减少SST 文件的数量来减少查询请求的需要。探索像 RocksDB的统一型精简配置或者定制化精简操作来更好的控制精简比率从而降低与SSD之间的数据传输。
结论
Netflex 推出了生产环境的解决方案。 Rend 现在在生产环境中服务了一些最重要的个性化推荐数据集。数字表明了增加了稳定性并加快了操作的速度,减少了临时的网络问题。Netflix在早期的适配器上正在部署 Mnemonic (L2) 后端,同时在调优系统,结果看起来时有保证的,简单易用并有效地降低了成本,保证了 EVCache 的一贯速度。
生产环境的部署是一个漫长旅程,还有很多事情要做:广泛部署,监控,优化,重复清洗等。EVCache 服务器的新架构可以用这样的方法持续创新。