11+大数据行业应用实践请见https://yq.aliyun.com/activity/156,同时这里还有流计算、机器学习、性能调优等技术实践。此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps;更多精彩内容参见云栖社区大数据频道:https://yq.aliyun.com/big-data 。
自1959年ChristopherStrachey发表虚拟化论文,到1984年Sun联合创始人JohnGage提出“网络即计算机”,再到2000年左右的SaaS出现及兴起,云计算服务已经经历了近20年的发展。着眼国内,从吸收概念及技术至今已近10年,然而,相信对于大部分人来说,云还只是临渊羡鱼,如何真正地利用云给业务最大赋能仍然无从参考。为此,云栖社区以大数据场景,通过一系列的客户走访带大家探索互联网赋能之路。本或许该有个开篇,但考虑再三,无非多一篇鸡汤尔,遂决定直入主题,从第一个接触的大数据实践公司开始——上海云贝,也就是网聚宝。
网聚宝定位于帮助品牌提供全域的大数据服务,时下帮助马克华菲、杜蕾斯、奔驰等用户,打通全渠道的消费者数据资产,无论是淘宝天猫,还是线下门店,通过数据整合提供了数据可视化和洞察的能力,每天可以处理上亿笔交易,做到不同维度的整合以及个性化地展现,实现数据背后的运营和挖掘,给品牌提供了数据最后一公里的落地。
挑战 vs. 机遇,瞬息万变演化的商机
作为一个快速发展中的创业团队,大部分精力必须集中在为用户提供数据应用的能力,这对于网聚宝来说既是挑战亦是机遇——熊大。
时至今日,对于品牌来讲,随着移动支付,和整个电商的更大规模覆盖,品牌已经积累了足够多(海量)的数据,网聚宝创始人兼CEO熊大(熊晓东)表示。在这之外,随着各行各业竞争的加剧,品牌对实时性的需求也越来越大,在原销售模式中,一个报表30天出来给到决策部门可能并没问题,但是在市场瞬息万变的当下,上一秒交易,这一秒可能就要出分析。同时,更大的挑战在于未来对商业智能的应用场景,怎么样使用大数据帮助品牌洞察出更多“意料之外,情理之中”的商业价值,更加关键。举个例子来说,有个洗车机的用户,其本身定位是二三线的有车一族,但通过数据洞察发现,买洗车机的都是农民,他们更多是买回去洗红薯,这证明大数据可以帮助用户分析出潜在的商机,这里存在的挑战就是帮助用户发现数据背后的价值,为品牌赋能。因此,这里需要一个非常专业的大数据平台,提供丰富的大数据处理能力,对于这个时代的人来说,这既是挑战也是机遇。
自建 vs. 上云,创业路上的生死抉择
对于任何创业公司来说,人才是不得不面临的问题,因此对于网聚宝来说,招业务还是技术上有深入钻研的人并没有什么好纠结的。现在,网聚宝零DBA、零运维,而公司需要更多懂大数据、懂业务的综合人才——熊大。
2011年刚开始创业,最初托管几台机器,老是断网。而Hadoop最早也有涉猎,但是创业公司人力资源有限,特别是那个时候的上海;同时,如果只招一个两个肯定不够,搭建、运维、开发,至少也得五六个。限于这些原因,那个时候面对竞争对手很被动,他们会说我们有十五六个在搞Hadoop,数据只需要放在自己的机房中,这些对客户来说都有着很大的吸引力,在交流中熊大回忆道。
DT和IT的区别就好比汽车与马车的生产力区别,谁胜谁负取决于市场现状,几年前,云还没有那么完善,跑在泥土路上的汽车日子显然没有马车好过,然而随着阿里等有能力的互联网公司建立了足够好的道路后,汽车服务提供商给用户带来的速度与体验显然超过了以往——熊大。
在阿里云的强力配合和支持下,我们还是坚持了下来,放弃了原有的Hadoop。而随后,到云变成像水电煤一样的基础设施后,对于创业公司来说,云服务成熟度远超Hadoop这些开源软件,这个时候就会发现,这些会应用阿里云的人,业务创造能力是那些玩Hadoop同学的许多倍,直接产生业务价值,而用户最需要的就是这些。这样一来,我们就拥有了足够竞争优势的成本,和业务拓展的速度,来给用户提供大数据处理的能力。对于原来的那些对手,Hadoop已成为技术负担,积累全在上面,丢掉则放弃了原有的竞争力,不丢掉是否还要上云,这时候变成了我们乘胜追击的时候。ALL IN云上,为用户提供更多的数据能力。在网聚宝30个人的技术团队,就可以PK基于Hadoop的百人技术团队。员工具备业务思维,看得懂背后的需求,和需求背后的价值。
自建 vs. 上云,技术选型优势及网聚宝架构
网聚宝拥有一支很萌的团队,熊大是创始人,机器猫是首席架构师,尼莫是市场策划总监。而对于上云在技术选型上的优势,机器猫表示:选择云服务架构,对创业团队发展有非常大的优势。
在使用云服务做架构时,底层基础能力对用户来说相当于一个黑盒,这样就可以把注意力放到业务的价值模型和技术的架构模型的统一上,从而对市场反应速度远超他人。如果真的发展到某一天,云服务满足不了业务需求,但是鉴于云服务已经划分清楚了明确的边界,所以在此边界内自主实现相应能力是一个收敛的问题,所以完全可以自己根据业务建设边界内的基础能力。如果创业公司一开始从零开始完全自主建设所有能力,很可能造成边界的蔓延,比如一部分本来应该在数据层的能力放到应用层中,AP的数据放到了TP来实现等等。这些蔓延最终会表现为隐性的耦合,从而大大减少了技术架构的生命期。云服务有一个非常明显的特性,他会将底层能力与上层应用切割,同时将通用能力与具体业务逻辑分开,所以在未来开发中,很适合创业团队根据业务需求去快速搭建自己的系统。基于这些,网聚宝现在的架构如下:
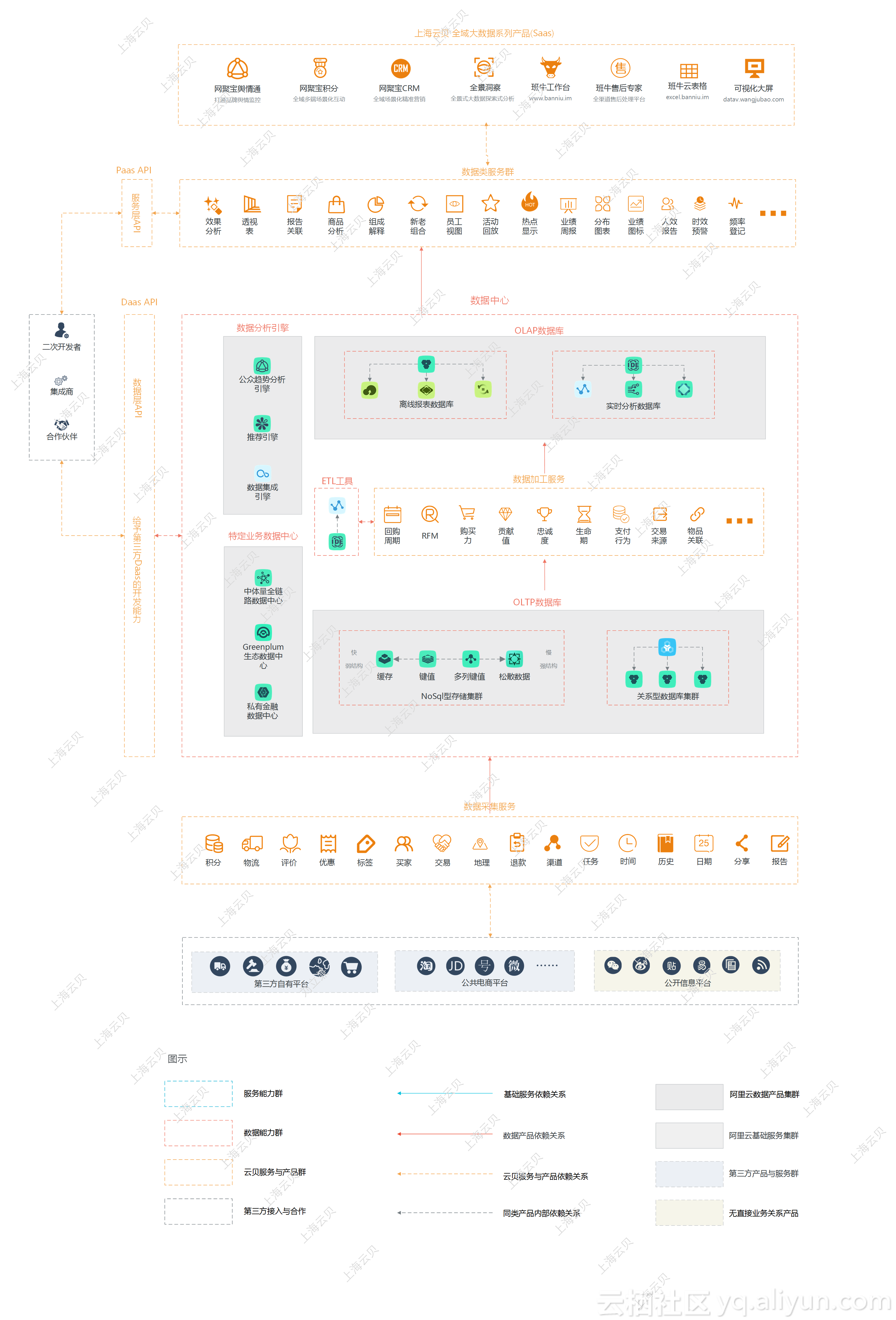
数据来源。最下面是底层可以收到的数据来源,第三方自有的平台,给自己的系统做对接和同步;公共的电商平台;公开的信息平台,百度贴吧、微博;三大种类数据源,通过十几个,几十个数据采集服务,采集到数据中心。
数据中心。采集到数据以后,强关系型数据会进入关系型数据库;同时,使用了大量的高性能的非关系型存储,使用了阿里云大致4种产品,分别对应了快和慢,弱结构和强结构,规范和零散。
数据处理层。通过数加提供的IDE来做数据加工的服务,主要目的是为了上层的数据分析。
数据分析。离线型报表,和实时分析。
通过机器猫了解到,网聚宝还使用了一些数加的特有服务,比如趋势分析、推荐引擎。此外,还使用了一些特色生态服务,在不是特别大体量下做全链路的数据处理。当然,在此之下是一些基础服务,比如云服务器、可配置部署、任务调度器、消息队列等等,此外,同样也使用了整体服务治理的微服务框架,以及运维套件、展现监控信息、自动部署组件、对于开发有用持续化发布的套件等等。上层是具体的应用服务,比如数据分析类服务,带有很强的数据聚合和处理特性,比如效果分析、透视表、报告关联、商品分析等等。
最上层则是网聚宝具体的应用,不同服务解决不同问题,最终解决问题有一定方向性,以此组成这个SaaS应用的产品链路。其实有很多产品,有很多小的服务组成。相对SaaS来说,还有一些PaaS,比如一些API,PaaS+DaaS,非常细粒度的服务,支撑特定维度下的特定数据的相关服务,可以给二次开发者,及其他数据集成伙伴使用。最后,还有一些营销相关服务,与平台中其他的服务做关联。为品牌在大数据的精准营销和多端互动上,提供了真实的场景,给消费者提供基于大数据的完整体现。
3000多家品牌客户,大数据红利已经到来
作为数加用户,该平台能够提供的大数据能力是什么,无论是海量数据处理,还是实时计算,首先考虑的就是平台的成熟度,当然背后还有能陪我们996战斗的数加兄弟,无论是技术能力的判断,还是从商业合作的角度,这是选择数加的原因,被问到为什么会选择阿里云和数加,熊大如是说。
同时,发展至今,网聚宝现在已有3000多家品牌客户,国际上包括,哥伦比亚,狼爪,The North Face®北面;国内,佐丹奴,意尔康,丽婴房;纯电商,顺丰海淘,美美箱,新兴的移动电商;零售、快消、线下服务业、金融方面,各个维度的消费者品牌用户。
最后,熊大还表示,大数据对很多品牌已经不是概念,帮助提升业务销售的资源,杜蕾斯,威露士通过大数据的深度营销和应用,提升老客户付购这一端带来直接销售提升。
