近日发现一篇不错的文章,文中列举了一些 GC 场景,探讨了 在 .NET 中是需要实现像 JVM 的中的幻像引用。有人质疑其不切实际,也有像 Ayende 大神一言不合就自己做了个 demo。
Do we need JVM’s PhantomReference in .NET?
原文 : Do we need JVM’s PhantomReference in .NET?
作者 : Konrad Kokosa
编校 : 张蘅水
TL;DR – would be post-mortem finalization available thanks to phantom references useful in .NET? What is your opinion, especially based on your experience with the finalization of your use cases? Please, share your insights in comments!
Both JVM and CLR has the concept of finalizers which is a way of implicit (non-deterministic) cleanup – at some point after an object is recognized as no longer reachable (and thus, may be garbage collected) we may take an action specified by the finalizer – a special, dedicated method (i.e. Finalizein C#, finalize in Java). This is mostly used for the purpose of cleaning/releasing non-managed resources held by the object to be reclaimed (like OS-limited, and thus valuable, file or socket handles).
However, such form of finalization has its caveats (elaborated in detail below). That’s why in Java 9 finalize() method (and thus, finalization in general) has been deprecated, which is nicely explained in the documentation:
“Deprecated. The finalization mechanism is inherently problematic. Finalization can lead to performance issues, deadlocks, and hangs. Errors in finalizers can lead to resource leaks; there is no way to cancel finalization if it is no longer necessary; and no order is specified among calls to finalize methods of different objects. Furthermore, there are no guarantees regarding the timing of finalization. The finalize method might be called on a finalizable object only after an indefinite delay, if at all.”
While finalization mechanism has been deprecated, the underlying problem should still be solved somehow. What is being suggested instead of it then? Simply put – an explicit cleanup (which AFAIK anyway was a preferred approach instead of finalization for a long time in Java). As the cited documentation continues:
“(…) Classes whose instances hold non-heap resources should provide a method to enable explicit release of those resources, and they should also implement AutoCloseable if appropriate. (…)”
In other words, programmers should not rely on “magic” implicit cleanup but use objects will well-known lifetime to explicitly close/release any underlying resources (by calling its close or Disposemethods at an appropriate time). Mentioned AutoCloseable is just a mechanism that helps to automate that:
static String readFirstLineFromFile(String path) throws IOException {
try (BufferedReader br =
new BufferedReader(new FileReader(path))) {
return br.readLine();
}
}which obviously resembles us IDisposable and using statement in .NET. At this moment we could stop any further discussion – assuming finalization is problematic also in .NET, we can “deprecate” it mentally (and by the way avoiding finalization is suggested approach in .NET either) and just go with explicit cleanup everywhere. However, we could not assume that it is always applicable – for example, there may be scenarios where a lifetime of our resource-holding object could not be easily limited to a single using statement.
So it happens in JVM world and so documentation continues:
“(…) The Cleaner and PhantomReference provide more flexible and efficient ways to release resources when an object becomes unreachable.”
And here our story begins – what is the PhantomReference mentioned (and related Cleaner class)? For curious – currently, there is no CLR’s counterpart of such finalization alternative. Thus, the title question arises – would it be beneficial to introduce it to CLR (and thus, C#)? To answer to such question we need to understand two things:
- if finalization is also somehow problematic in CLR world (so we would like to have some alternative to it)
- if it is worth to implement it (taking into consideration implementation-specific overhead and problems)
Let’s start with the first issue then.
Finalization problems
Putting aside the defects of finalization in JVM (which I do not know well because of my limited JVM’s knowledge), let’s consider why it may be problematic in CLR:
1) It is not guaranteed that finalization code will be executed at all, exactly once, or may be executed only partially
This is one of the most “magical” caveats of finalization. For example, if some finalizer is malfunctioned and blocks its execution indefinitely, other finalizers won’t be called at all. This is because currently finalization is processed sequentially by a dedicated, single thread. Another problem may arise if the process is terminated rapidly without giving the GC chance to execute some finalizers (which may or may not be a problem because process termination should release underlying handles anyway). Moreover, it is even possible that finalizer will be executed more than once because of a resurrection technique, described later.
“Bad finalizer” example
We can easily create potentially bad-behaving finalizer:
public class EvilFinalizableClass
{
private readonly int finalizationDelay;
public EvilFinalizableClass(int allocationDelay, int finalizationDelay)
{
this.finalizationDelay = finalizationDelay;
Thread.Sleep(allocationDelay);
}
~EvilFinalizableClass()
{
Thread.Sleep(finalizationDelay);
}
}If we will be creating EvilFinalizableClass instances with finalizationDelay bigger than allocationDelay, we will starve finalization thread endlessly! Not only it is a big problem by itself, but it is also really hard to diagnose such issue. We do not have any easy way to monitor finalization programmatically (like a number of object being finalized etc.).
“Resurrection” example
A finalizer is just a regular instance method and as such, it has access to this reference. This allows to use a technique called resurrection because out of a sudden, reference to an object that was just to be reclaimed, is being assigned to some globally accessible point, making it reachable (and thus, life from the GC perspective) again:
class FinalizableObject
{
~FinalizableObject()
{
Program.GlobalFinalizableObject = this;
GC.ReRegisterForFinalize(this);
}
}It is arguable whether this is an issue or not and whether programmers should be limited to not do this. In most cases, such a technique is barely usable and just makes things awkward. But worse, it implies runtime-level implementation. If an object may be resurrected, it cannot be garbage collected at the moment of the finalization but only afterward.
2) Execution time is non-deterministic
Finalizer most probably will be called but it is not defined when. This is bad from the resource management point of view. If an owned resource is limited, it should be released as quickly as possible. Waiting for non-deterministic cleanup is barely optimal. Moreover, maybe we know our resources well and we would like to have control over finalization – to make it at some specific moments of the program execution.
But due to a reasonable design decision, finalizers are not executed during the GC – it would introduce a risk that user-defined code from finalizer would stop/block/harm GC process, which should be as fast as possible. Moreover, finalizers have to be able to allocate objects (as any other user-code) so they must be executed during normal program execution. Thus, by design, finalizers are run at “some time” after the GC – we do know when and we do not have any control over it. For most cases, it may be just enough, but for some one could have more strict control over it.
3) Order of execution of finalizers is not defined
Even if one finalizable object refers to the other finalizable object, it is not guaranteed their finalizers will run in any logical order (like the e.g., “owning” object before the “owned” one or vice versa). Thus, we should not refer to any other finalizable objects inside a finalizer, even if we “own” them. This may be problematic both in unmanaged scenarios (stream and underlying handle) but even in non-obvious only-managed ones.
class LoggedObject
{
private ILogger logger;
public LoggedObject(ILogger logger)
{
this.logger = logger;
// ...
this.logger.Log("Object created.");
}
// Destructor
~LoggedObject()
{
this.logger.Log("Object destroyed.");
}
}In the above example, a finalizer could be using a dependency-injected logger via an interface. It means we are not guaranteed that an injected, concrete logger instance will not be finalizable and thus we are exposing ourselves to the problem of unordered finalization execution – the logger may be already disposed inside our finalizer.
4) The thread on which the finalizer will be executed is also not defined
All we know that it is some “internal finalizer thread” maintained by GC. It is not defined whether there are single or multiple such threads. We have no control over it so we cannot introduce any optimizations. For example, maybe for some kind of resource, we would like to introduce parallel finalization with the help of multiple dedicated threads?
Moreover, not knowing explicitly what thread will execute our finalizer exposes us to various synchronization problems if we decide to use locks and so forth.
5) Throwing an exception from the finalizer is very dangerous
By default, it simply kills the entire process. While it is a current implementation detail of the CLR, the rule of thumb is (and it always be) to not throw any exceptions from within finalizer. Still, this is enforced by common sense, not by any formal rule.
6) Finalizable objects introduce an additional overhead
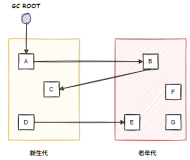
If a type has a finalizer, a slower allocation path will be used. The GC must be aware of all finalizable objects, to call their finalizers when they become unreachable. It records these objects on what’s called the finalization queue. In other words, finalization queue at any moment contains a list of all finalizable objects currently live. Mentioned slower allocation path contains registering a newly-created object in the finalization queue.
During GC, at the end of Mark phase, GC checks the finalization queue to see if any of the finalizable objects are dead. If they are some, they cannot be yet deleted because their finalizers will need to be executed. Hence, such an object is moved to yet another queue called fReachable queue. Its name comes from the fact that it represents finalization reachable objects – the ones that are now reachable only because of finalization. If there are any such objects found, GC indicates to the dedicated finalizer thread there’s work to do.
Finalization thread removes objects from the fReachable queue one by one and calls their finalizers. Since the only root to this object is removed from the fReachable queue, the next GC that condemns the generation this object is in will find it to be unreachable and reclaim it.
Note. BTW this is why trying to fully reclaim memory at some point requires magical formula of two following GCs:
GC.Collect();
GC.WaitForPendingFinalizers();
GC.Collect();
But note that such mechanism introduces overhead related to the finalization: a finalizable object by default survives for at least one more GC. Moreover, fReachable queue is treated as a root considered during Mark phase because the finalizer thread may not be fast enough to process all objects from it between GCs. This exposes the finalizable objects more to a Midlife crisis – they may stay in fReachable queue for a while consuming generation 2 just because of pending finalization.
Knowing all the implementation details described so far, we can summarize finalization as having the following overhead:
- it forces slower allocation by default, including the overhead of manipulating finalization queue during allocation,
- it promotes finalizable object at least once by default, making Mid-life crisis more likely. It introduces some overhead of finalizable objects handling even while they are still alive – mostly keeping up-to-date generational finalization list
7) Finalization is not optional
An object must be “finalizable” from the very beginning because the only way to make it so is by defining a finalizer method in it. We cannot create a regular object and only, later on, enable finalization for it (although, we may disable it with the help of GC.SuppressFinalization method).
…
All those points lead to one conclusion – implementing finalizers is tricky, using them may be unreliable and problematic even from the performance perspective. Thus, they should be generally avoided.
Avoiding resurrection, synchronization locks, throwing exceptions, dependency on other finalizable objects – all this may be done only on a good-practice basis, not by any formal technique. Thus, we depend on developers’ common sense, rather on any formally enforced rules.
Knowing all that, does currently exist in .NET any preferred alternative or technique? There are, so let’s look at them now.
Critical finalizers
Due to various problems with finalizers mentioned above, in .NET a little firmer counterpart was introduced in the form of critical finalizers. They are simply regular finalizers with additional guarantees – designed for a situation where a finalizer code must be executed with certainty, even in case of rude AppDomain or thread abort cases. To define such a critical finalizer, one must define a finalizer in the CriticalFinalizerObject-derived class. The CriticalFinalizerObject itself is abstract and has no implementation. As MSDN says:
“In classes derived from the CriticalFinalizerObject class, the common language runtime (CLR) guarantees that all critical finalization code will be given the opportunity to execute, provided the finalizer follows the rules for a CER (Constrained Execution Region), even in situations where the CLR forcibly unloads an application domain or aborts a thread.”
Runtime makes some precautions to make executing critical finalizers possible in any circumstances. For example, it is JITting critical finalizer code in advance, to avoid a situation when later on there is not enough memory for the generated code in an out-of-memory exception scenario. Moreover, critical finalizers added some guarantees on order of execution. As MSDN says:
“The CLR establishes a weak ordering among normal and critical finalizers: for objects reclaimed by garbage collection at the same time, all the noncritical finalizers are called before any of the critical finalizers.”
Thus, critical finalizers are designed to solve problems 1 and 3 (at least partially) from the list above.
SafeHandle
You will rarely need to define types derived directly from CriticalFinalizerObject. More often, you use them via deriving from special SafeHandle type. It was designed from an observation that most of the time, unmanaged resources that need to be “finalized” are represented simply by some handle or pointer – thus IntPtr type. SafeHandle is a type designed to wrap such handle, with finalization support.
So instead of implementing a finalizer, the preferred and suggested alternative is to create a type that derives from the abstract System.Runtime.InteropServices.SafeHandle class and use it as handle wrapper. Having much of the logic already implemented in such type, we are less exposed to any problems we may introduce implementing our own finalization logic. SafeHandle is critically finalizable and implements Disposable pattern. Both its Dispose and Finalize logic is, in fact, internal (implemented in the runtime itself), we only need to implement abstract ReleaseHandle method and IsInvalid property used by them.
Unfortunately, even really useful, in the context of our consideration, SafeHandle does not really solve problems 3, 4, 6 and 7 from the above list. Moreover, they are strictly limited to handling IntPtr and nothing else so it is not a general-purpose finalization alternative.
Note. CLR treats instances of SafeHandle class in a special way during P/Invoke calls – they are being protected from being garbage collected (treated as roots). This prevents to run finalizer during P/Invoke call, which would be very unfortunate (releasing handle being used). When introducing any finalization alternative, we should be aware of this special behavior.
Knowing what .NET currently offers, let’s now get familiar with what PhantomReference is and why it may solve some issues listed below.
What is a phantom reference in JVM?
In shortest words, phantom reference is a reference to an object that may be already garbage collected. At first glance, it may sound strange and useless but as you will see, it makes perfect sense in some scenarios.
In the context of reachability, it adds one new level not seen in .NET – we say that an object may be phantom reachable, as the documentation says:
“An object is phantom reachable if it is neither strongly, softly, nor weakly reachable, it has been finalized, and some phantom reference refers to it.”
Phantom references are represented in Java by PhantomReference class, derived from more general Reference class (with other subclasses representing strong and weak references). PhantomReference overrides Reference‘s get() method to always return null – not allowing to get an object being referenced. This may sound strange but makes a perfect sense – providing such referent would expose the possibility to resurrect an object, but it might be already dead.
Because there is no way to get a referenced object from PhantomReference, such phantom reachable object, in fact, does not need to be alive. GC is perfectly fine to reclaim memory after it. Thus, we can see a phantom reference as a post-mortem notification. We only get information that an object has become unreachable without any possibility to access it any more.
But if PhantomReference does not inform us about what object it refers to, how it can be usable? This is solved by an additional ReferenceQueue class – each PhantomReference is being registered to an instance of it (by specifying it in its constructor). Afterward, we can poll such a queue to observe changes and be notified about an object reclamation. If we are interested in a single, specific object, we can create a dedicated ReferenceQueue for it. But most often, there will be a ReferenceQueue for various types/groups of resources.
An obvious question arises – if we cannot access an object from phantom reference, how one can take any cleanup/”finalization” action for it? This is done by a simple workaround – we do not need a whole object to cleanup resource, we just need some representation (handle) of the resource it owns. Thus, altogether with the phantom reference itself we can store some necessary data, taken from an object at the time of phantom reference creation, which will be used afterward. Even if an object will be already garbage collected, our side data will allow us to cleanup resources of our interest.
Let’s now see two main use cases of PhantomReference to make things more clear.
Use case 1 – determine that object is no longer reachable
The simplest use case is just to observe a queue and make some action when registered reference has become unreachable:
ReferenceQueue<SomeObject> referenceQueue = new ReferenceQueue<>();
SomeObject obj = new SomeObject();
Reference<SomeObject> ref = new PhantomReference<>(obj, referenceQueue);
// Now somewhere we can wait for changes in a queue
Reference<? extends SomeObject> polled = referenceQueue.poll();
if (polled!=null) {
// take some action
}This obviously perfectly works for a single instance and (quite rare) use cases when we do not need to access the data of reclaimed objects.
Use case 2 – take a post-mortem action without finalization
In this scenario, we need somehow to remember resources to be released after an object will die. We can maintain a map between a phantom reference and such data but typically it is stored in an object derived from PhantomReference itself, for convenience:
public class PhantomReferenceFinalizer extends PhantomReference<Object> {
// handle field - some resource to be released
public PhantomReferenceFinalizer(
Object referent, ReferenceQueue<? super Object> queue) {
super(referent, queue);
// get handle from referent
}
public void finalizeResources() {
// free handle
}
}Then usage is simple. We may create a phantom reference from our code, registering them in the reference queue of our choice:
new PhantomReferenceFinalizer(someObject, referenceQueue);Then, most probably from our dedicated thread, we may observe such queue to take appropriate actions:
while ((referenceFromQueue = referenceQueue.poll()) != null) {
((PhantomReferenceFinalizer)referenceFromQueue).finalizeResources();
}
Note. Until Java 9, we would need to manually clear phantom reference after pooling it (by calling referenceFromQueue.clear() in the above example). In Java 9 it is not necessary to call clear, as a phantom reference will be cleared automatically when enqueued. See https://bugs.java.com/bugdatabase/view_bug.do?bug_id=JDK-8071507 and https://bugs.java.com/bugdatabase/view_bug.do?bug_id=8173071: “An object becomes phantom reachable after it has been finalized. This change may cause the phantom reachable objects to be GC’ed earlier – previously the referent is kept alive until PhantomReference objects are GC’ed. This potential behavioral change might only impact existing code that would depend on PhantomReference being enqueued rather than when the referent be freed from the heap.”.
Please note we cannot store referent reference directly in PhantomReferenceFinalizer (exposing it to resurrection) because it would make referent always alive as long as ReferenceQueue is alive – making the whole mechanism useless.
Summary
So, knowing what phantom reference (and related queue) provides, let’s consider the answer to the title question.
Probably, you can already spot advantages of phantom references over classic finalization:
-
manual control over the finalization process – what we can get by PhantomReference and ReferenceQueue is a way of manually implementing the finalization process. We can create many different “finalization queues” and structure them as we wish, for example, to create:
- parallel finalization – we can process single or multiple queues from a set of multiple threads
- fine-grained finalization – we can create queues for objects of different types of resources
- ordered finalization – by observing and processing queues in a specified order we may provide ordered finalization
- no prolonged life of “finalized” object – because there is no access from phantom reference to an object, it does not need to be kept alive. There is no additional GC cycle needed to handle it. This is quite an important performance advantage over regular finalization!
- no resurrection possible – by design we cannot resurrect objects from phantom references. One problem less.
- optional finalization – an object does not have to be created as “finalizable” from the very beginning. Finalization may be enabled for it by creating a phantom reference for it. This may be convenient for itself. Moreover, it allows finalization to be “injected” to domain entities like any other infrastructural concern.
- better monitoring – as we have “finalization” queues under our control, we can monitor them and detect any issues (like starvation)
On the disadvantages side there is one major – using phantom references is much more complex than simple finalization or SafeHandles. Thus, it is hard to expect that each and every resource management scenario would be handled that way. On the other hand, with the help of a good library covering the repetitive code, we would gain the benefits of phantom references without a big complexity overhead (like Java’s Cleaner class).
So, would it be wise to introduce phantom references to .NET? Obviously, I do not know the definite answer. In my humble opinion, yes. It is an optional feature. Without using them, there is no additional overhead to the runtime and the GC. On the other hand, having them may be useful in performance and memory critical scenarios. The other thing is – is it worth to complicate finalization API to cover narrow, like 1%, possible scenarios? Please, share your thoughts!
Note. As I am heavily considering implementing a proof of concept for phantom references in CoreCLR, I am thinking about various implementation details of such mechanism. There are some obvious steps like implementing PhantomReference counterpart on the CoreFX level. Also, there should be a new type of handle inside CoreCLR (besides strong, weak and so forth) that is maintaining PhantomReference instances. Moreover, the runtime would need to manipulate a managed object of the ReferenceQueue to enqueue phantom reference after referent becomes unreachable – this is, as far as I know, something not done currently in any scenario.
Follow-ups
As a great response to my post, you can find the following articles as a part of the discussion:
- Implementing Phantom Reference in C# by Ayende Rahien
- Implementing Java ReferenceQueue and PhantomReference in C# by Kevin Goose
References
https://www.baeldung.com/java-phantom-reference
https://www.logicbig.com/tutorials/core-java-tutorial/gc/phantom-reference.html
https://stackoverflow.com/questions/53822132/java-phantomreference-vs-finalize
Implementing Phantom Reference in C#]
原文 : Implementing Phantom Reference in C#
作者 : ayende
转载: 张蘅水
I run into this very interesting blog post and I decided to see if I could implement this on my own, without requiring any runtime support. This turned out the be surprisingly easy, if you are willing to accept some caveats.
I’m going to assume that you have read the linked blog post, and here is the code that implement it:
public class PhantomReferenceQueue<THandle>
{
private BlockingCollection<THandle> _queue = new BlockingCollection<THandle>();
private ConditionalWeakTable<object, PhatomReference> _refs = new ConditionalWeakTable<object, PhatomReference>();
public void Register(object instance, THandle handle)
{
_refs.Add(instance, new PhantomReference(this, handle));
}
public void Unregister(object instance)
{
if (_refs.TryGetValue(instance, out var val))
GC.SuppressFinalize(val);
_refs.Remove(instance);
}
public THandle Poll()
{
return _queue.Take();
}
private class PhantomReference
{
THandle _handle;
PhantomReferenceQueue<THandle> _parent;
public PhantomReference(PhantomReferenceQueue<THandle> parent, THandle handle)
{
_parent = parent;
_handle = handle;
}
~PhantomReference()
{
_parent._queue.Add(_handle);
}
}
}Here is what it gives you:
- You can have any number of queues.
- You can associate an instance with a queue at any time, including far after it was constructed.
- Can unregister from the queue at any time.
- Can wait (or easily change it to do async awaits, of course) for updates about phantom references.
- Can process such events in parallel.
What about the caveats?
This utilize the finalizer internally, to inform us when the associated value has been forgotten, so it takes longer than one would wish for. This implementation relies on ConditionalWeakTable to do its work, by creating a weak associating between the instances you pass and the PhantomReference class holding the handle that we’ll send to you once that value has been forgotten.