
【场景】
用户搭建网站会不断的产生访问日志(Nginx,Apache访问日志)。为了从访问日志中挖掘出更多价值,本文主要阐述如果利用阿里云数加从沉睡中的访问日志中获取更有价值的数据,包括用于实时统计和展示网站访问的一系列指标,例如PV,UV,设备,地理,状态码,爬虫,网络流量等指标。
【具体分析需求】
用户想根据访问日志来实时统计和展示网站访问重要指标,需要设计到流式计算和离线计算,那么阿里云数加·StreamCompute更好的可以解决日志的实时计算场景,而阿里云数加·MaxCompute则更好的来处理批量数据,适合于离线数据计算。
那么如何来使用阿里云数加来构建一个高可用的数加架构两者计算场景都可以满足?
【日志字段】
- 日志格式:
$remote_addr - $remote_user [$time_local] “$request” $status $body_bytes_sent”$http_referer” “$http_user_agent” [unknown_content];
- 日志字段说明:
| 字段名称 |
字段说明 |
| $remote_addr |
发送请求的客户端IP地址 |
| $remote_user |
客户端登录名 |
| $time_local |
服务器本地时间 |
| $request |
请求,包括HTTP请求类型+请求URL+HTTP协议版本号 |
| $status |
服务端返回状态码 |
| $body_bytes_sent |
返回给客户端的字节数(不含header) |
| $http_referer |
该请求的来源URL |
| $http_user_agent |
发送请求的客户端信息,如使用的浏览器等 |
- 真实的访问日志数据示例如下:
192.168.1.101 - - [17/Mar/2016:10:28:30 +0800] "GET /fonts/fontawesome-webfont.woff?v=4.2.0 HTTP/1.1" 0.021 1207 304 0 "https://sls.console.aliyun.com/css/lib.css" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.87 Safari/537.36"
【数据架构】
根据实时计算场景和批量计算的场景要求,笔者尝试从如下数据架构来满足:
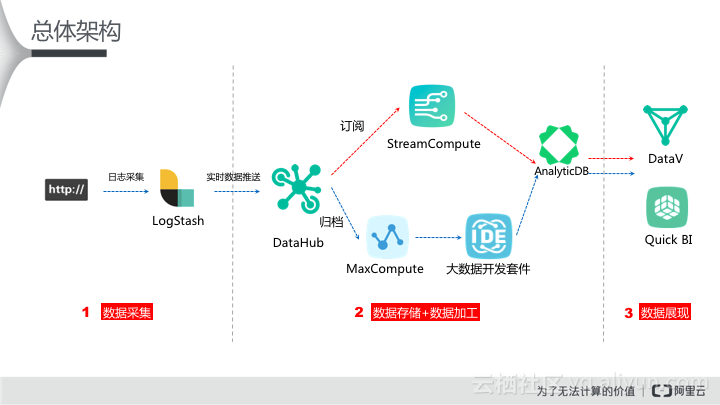
如上数据架构图,用户可根据红色箭线来完成实时数据处理场景,根据蓝色箭线来完成离线数据处理需求。
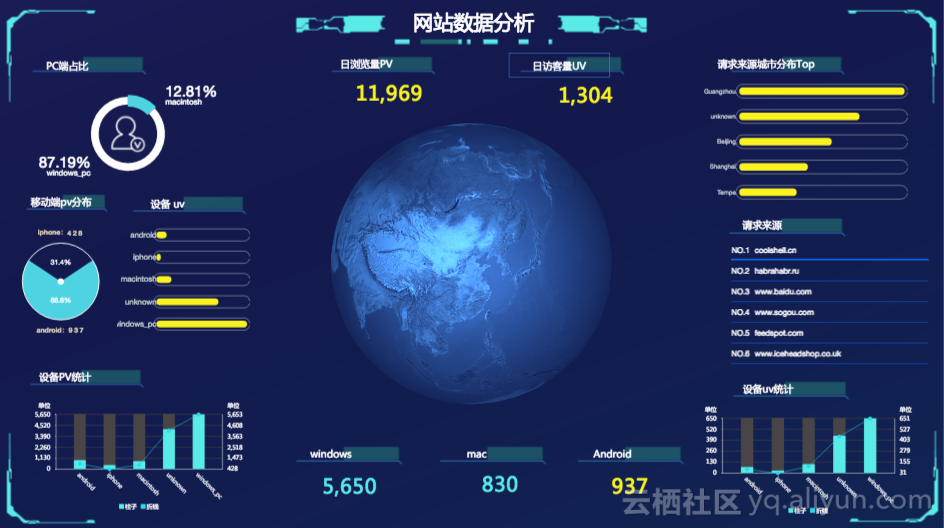
- 实时处理逻辑:Logstash-->DataHub-->StreamCompute-->AnalyticDB-->DataV,笔者做出来的最终效果图如下:
-
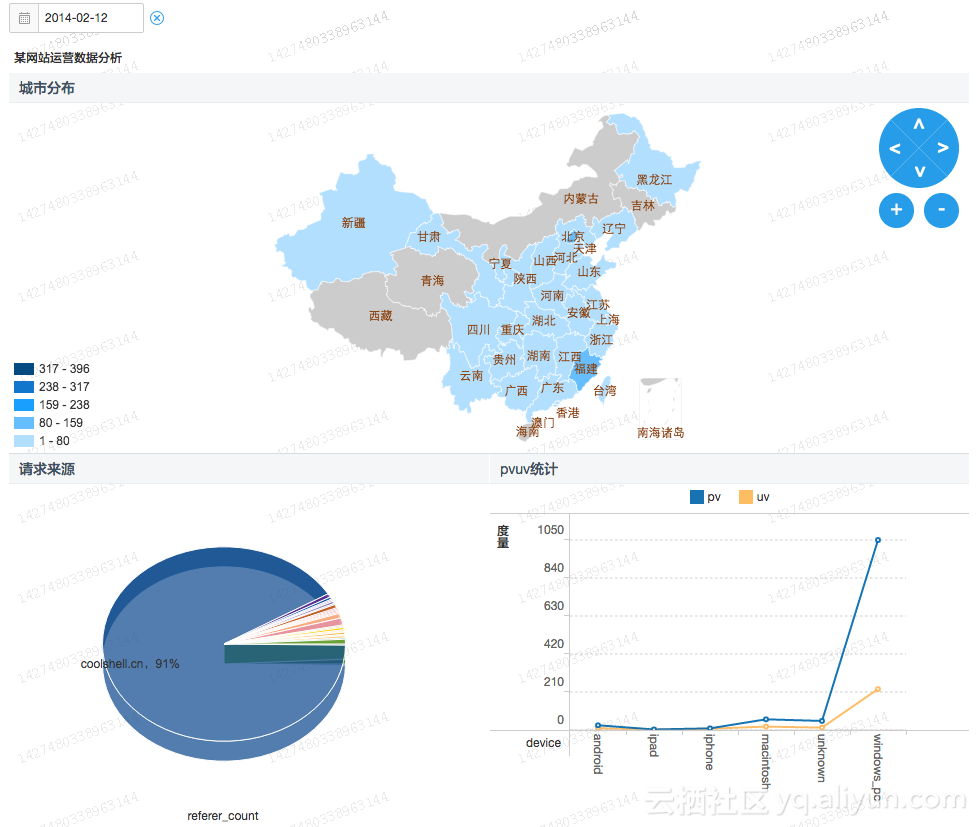
- 离线计算逻辑:Logstash-->DataHub(DataConnector)-->MaxCompute-->大数据开发套件Data IDE -->Quick BI.效果图如下:
-
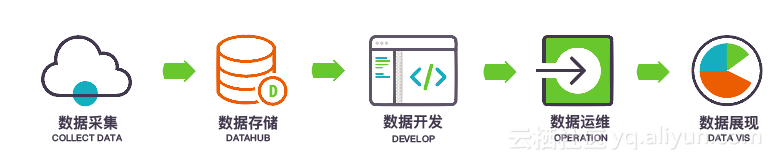
- 数据采集:笔者采用了自己熟悉的开源工具Logstash,当然用户也可以选择自己熟悉的比如Fluentd,都是开源中比较常用来做日志的并发采集。其中DataHub顾名思义为数据中枢,其实pub/sub系统,负责将实时采集的数据进行采集和消费。阿里云数加DataHub提供了Logstash和Fluentd Output插件,无缝支持讲日志数据写入到DataHub并由下游消费。具体文件详见:https://datahub.console.aliyun.com/intro/introduction.html
- 数据存储:在实时计算中StreamCompute是没有存储的,因为流式数据场景就是无界的数据持续不断的写入,持续不断的计算并将结果输出给下游存储供消费。而在离线计算场景中,数据被DataHub 的归档功能给存储在MaxCompute,用来做批量计算。
- 数据展现:两者都是讲最终处理好的数据写入到阿里云数加AnalyticDB中,其中AnalyticDB支持海量数据的毫秒级查询和分析,最终实时场景展示采用数据可视化DataV制作的实时指挥大屏,而离线采用了Quick BI制作的报表。

