数组
数组在编码中很常见,就是把数据码成一排存放。

这就表示一个数组,这个数组有八个元素存放。对于元素的获取,主要就是通过下标获取,所以索引对于数组是很重要的,这个索引可以是有意义的,也可以是没有意义的。比如array【2】这个数组,可以是仅仅代表下标,也可以是有一个意义在里面,代表学号分数等等。Java里面有存在静态数组,直接int[]赋值,但是这种方法是不能动态初始化的,我们二次封装一个:
public class Array<E> {
private E[] data;
private int size;
public Array(int capacity) {
data = (E[]) new Object[capacity];
size = 0;
}
public Array(){
this(10);
}
public int getSize(){
return size;
}
public int getCapacity(){
return data.length;
}
public boolean isEmpty(){
return size == 0;
}
public void addLast(E e){
add(size, e);
}
public void addFirst(E e){
add(0, e);
}
public void add(int index, E e){
if (size == data.length){
resize(2 * data.length);
}
if (index < 0 || index > size){
throw new IllegalArgumentException("index must be in range[0, size]");
}
for (int i = size-1; i >= index; i --) {
data[i+1] = data[i];
}
data[index] = e;
size ++;
}
public E get(int index){
if (index < 0 || index > size){
throw new IllegalArgumentException("index must be in range[0, size]");
}
return data[index];
}
public void set(int index, E e){
if (index < 0 || index > size){
throw new IllegalArgumentException("index must be in range[0, size]");
}
data[index] = e;
}
public E remove(int index){
if (index < 0 || index > size){
throw new IllegalArgumentException("index must be in range[0, size]");
}
E ret = data[index];
for (int i = index + 1; i < size; i ++){
data[i-1] = data[i];
}
size --;
return ret;
}
private void resize(int newCapacity){
E[] newData = (E[]) new Object[newCapacity];
for (int i = 0; i < size; i++) {
newData[i] = data[i];
}
data = newData;
}
@Override
public String toString(){
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append(String.format("Array: size = %d , capacity = %d\n", size, data.length));
stringBuilder.append('[');
for (int i = 0; i < size; i++) {
stringBuilder.append(data[i]);
if (i != size-1){
stringBuilder.append(", ");
}
}
stringBuilder.append(']');
return stringBuilder.toString();
}
}
在添加的时候如果遇到空间不够会自动进行扩容操作,扩容两倍,按照两倍人容量创建一个新数组,然后把原数组的内容复制进去,再把原数组指向新数组即可。对于数组的复杂度,由于添加和删除的期望都是,所以复杂度都是O(n),而修改这些就是O(1)了。
栈
栈原理
首先要了解一下什么是线性表,线性表是一个线性的数据结构,含有n>=0个节点的有限序列,对于其中的一个节点,有一个没有前驱只有一个后继的开始节点和一个只有前驱没有后继的结束的节点。线性表和数组的区别还是很大的,这是两种不同的数据结构,数组有维度的概念,线性表没有,线性表有前驱后继的概念,各个元素之间是有联系的,数组没有。线性表可以使用一维的数组存储,但是并不代表线性表就是一维数组。
stack栈就是一种特殊的线性表,先进后出,操作数据这端就叫做栈顶,表尾称为栈尾,所有的操作只能从栈顶开始,无论是取出还是删除操作,都只能从一端操作。栈的基本操作就三个:push压栈,pop出栈,peek查看栈顶元素。
package Stack;
public class Stack {
private int[] datas;
private int tapIndex = -1;
private int lenght = 0;
public Stack(int lenght){
this.lenght = lenght;
datas = new int[this.lenght];
}
public void push(int data){
datas[++tapIndex] = data;
}
public int pop(){
return datas[tapIndex --];
}
public int peek(){
return datas[tapIndex];
}
public boolean isEmpty(){
return tapIndex == -1;
}
public boolean isFull(){
return tapIndex == (lenght - 1);
}
}
应用
①括号匹配
栈的实现还有一种链表的形式,这里不写了。 栈的应用很多,字符串的倒序,括号匹配,计算算术表达式。字符串反转这个比较简单,不用解释,括号匹配,如果进来的是括号的左边,那么就入栈,遇到一个右边的括号就出栈,看看这个时候出栈的元素和当前的元素是不是匹配的,如果是继续,不是直接返回false就好了。
public static boolean checkBrackets(String string) {
char[] charString = string.toCharArray();
Stack stack = new Stack(10);
for (int i = 0; i < charString.length; i++) {
char c = charString[i];
if (c == '{' || c == '[' || c == '(') {
stack.push(c);
} else if (c == '}' || c == ']' || c == ')') {
char popElement = (char) stack.pop();
if ((popElement == '{' && c != '}')
|| (popElement == '[' && c != ']')
|| (popElement == '(' && c != ')')
) {
return false;
} else {
continue;
}
} else {
continue;
}
}
if (stack.isEmpty())
return true;
else {
return false;
}
}
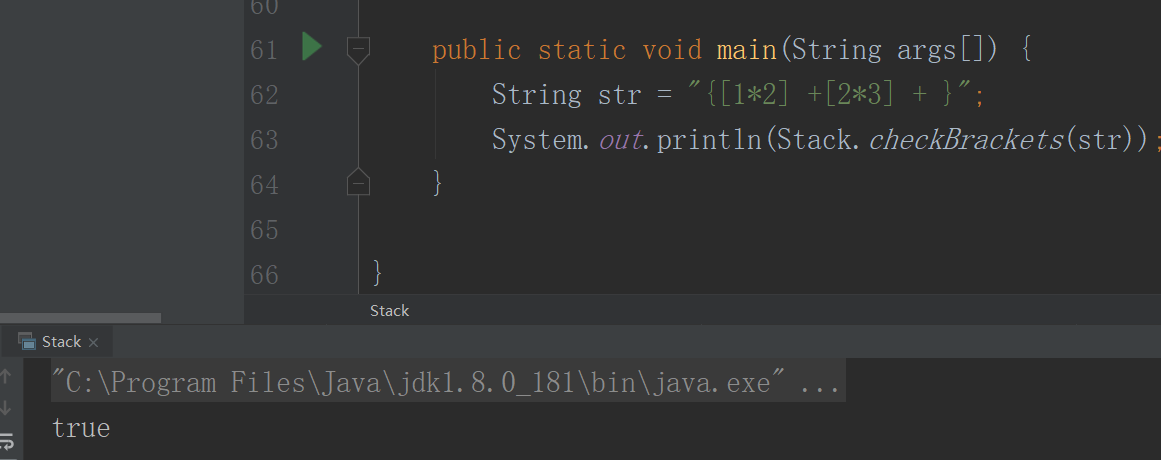
②计算算术
类似计算器上的计算,给出一条式子计算他的结果。首先要提到的就是逆波兰表达式,也称为是后缀表达式,这种表达式是把运算符号写在了运算对象后面,比如a+b写成ab+,所以也叫后缀表达式。当然有后缀自然就有前缀,只不过前缀用的比较少一般都是用后缀。这种方法的优点就是根据运算对象和运算符的出现次序进行计算,不需要使用括号,也便于程序实现求值。中缀转后缀是不需要做任何的计算:
1,从左到右顺序读取表达式的字符。
2,是操作数那么就赋值到后缀表达式的字符串。
3,是左括号就把字符压进栈中。
4,是右括号,从栈中弹出符号到后缀表达式,直到遇到左括号,然后把左括号弹出。
5,是操作符,如果这个时候栈顶元素操作符的优先级大于或者等于此操作符,弹出栈顶操作符到后缀表达式,直到遇到优先级更低的元素的位置,把操作符压入栈。
public String midToPost() {
String postString = "";
Stack stack = new Stack(str.length() + 1);
char[] charString = str.toCharArray();
for (int i = 0; i < charString.length; i++) {
char c = charString[i];
if (c >= '0' && c <= '9') {
postString += c;
} else if (c == '(') {
stack.push(c);
} else if (c == ')') {
char pop = (char) stack.pop();
while (pop != '(') {
postString += pop;
pop = (char) stack.pop();
}
} else {
if (!stack.isEmpty()){
char pop = (char) stack.pop();
if (pop == '('){
stack.push(pop);
stack.push(c);
continue;
}
if (map.get(pop) > map.get(c)){
postString += pop;
stack.push(c);
}else {
stack.push(pop);
stack.push(c);
}
}else {
stack.push(c);
}
}
}
while (!stack.isEmpty()){
char pop = (char) stack.pop();
postString += pop;
}
return postString;
}
中缀表达式转后缀表达式,按照上面的步骤进行判断即可。里面用到了一些优先级的比较,我把运算符都用一些数字表达。比较优先级的时候比较数字大小就好了。
public CalculatePost(String str) {
this.str = str;
map.put('+', 0);
map.put('-', 0);
map.put('*', 1);
map.put('/', 1);
}
然后就是计算后缀表达式:
public int getValue(String str1) {
char[] charString = str1.toCharArray();
Stack stack = new Stack(charString.length + 1);
for (int i = 0; i < charString.length; i++) {
char c = charString[i];
if (c >= '0' && c <= '9') {
stack.push((int) (c - '0'));
} else {
int num2 = stack.pop(), num1 = stack.pop(), temp = 0;
if (c == '+') {
temp = num2 + num1;
} else if (c == '-') {
temp = num1 - num2;
} else if (c == '*') {
temp = num1 * num2;
} else if (c == '/') {
temp = num1 / num2;
}
stack.push(temp);
}
}
return stack.pop();
}
最后测试用例:
public static void main(String args[]){
String str = "((3+2)*(6+7))*5";
CalculatePost calculatePost = new CalculatePost(str);
System.out.println(calculatePost.midToPost());
System.out.println(calculatePost.getValue(calculatePost.midToPost()));
}
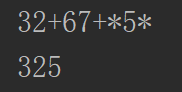
队列
队列原理
队列是一种特殊的线性表,它和栈有点相似,栈是先进后出,队列是先进先出,和排队买票一样,但是就是不能插队。队列有两个操作点,一个是队尾,只能做插入,另一个是队头,只能取元素。队列的基本操作有三个,插入队列,出队列,查看队头元素。队列有两种实现方式,一种是数组实现,一种是链表实现,链表实现比较简单。但是数组实现会出现资源浪费的情况,一出一进整个队列就会往前移动,有部分空间就使用不了了,所以就出现了循环队列。下面用数组实现循环队列:
public class Queue {
private int [] queue;
private int front;
private int end;
private int nItem;
public Queue(int count){
front = 0;
end = 0;
nItem = count;
queue = new int[count];
}
public void insert(int data){
if ((end+1)%nItem == front){
System.err.println("Queue is Full");
}else {
queue[end] = data;
end = (end+1)%nItem;
}
}
public void remove(){
if ((end-front + nItem)%nItem == 0){
System.err.println("Queue is empty!");
}else {
front = (front + 1)%nItem;
}
}
public int peekFront(){
return queue[front];
}
public boolean isEmpty(){
return (end-front + nItem)%nItem == 0;
}
public boolean isFull(){
return (++end)%nItem == front;
}
public int count(){
return (end-front + nItem)%nItem;
}
public static void main(String args[]){
Queue queue = new Queue(11);
for (int i = 0;i < 10; i++){
queue.insert(i);
}
System.out.println(queue.peekFront());
queue.remove();
System.out.println(queue.peekFront());
queue.remove();
queue.insert(13);
}
}
由于整个队列一删一添的操作会导致整个队列移动,所以要对前后标识做循环处理,求余数来得到下一个位置,这样加上一永远是再最大范围里面,而且为了方便判断是否满,会留出一个空间来做判断。除了最基本的队列,还有双端队列和优先队列,双端队列比较少用。优先队列和普通队列的排列方式不一样,优先队列是按照优先级出队,每一次插入元素队列动态按照优先级维护,少用可以用堆这种数据结构。实现优先队列:
public class PrioriityQueue {
private int [] queue;
private int nItem;
private int capacity;
public PrioriityQueue(int count){
queue = new int[count];
nItem = 0;
capacity = count;
}
public void insert(int data){
if (nItem == 0){
queue[nItem] = data;
nItem ++;
}else {
int i = 0;
for (i = nItem - 1; i >= 0; i--){
if (data > queue[i]){
queue[i+1] = queue[i];
}else {
break;
}
}
queue[i+1] = data;
nItem ++;
}
}
public int remove(){
int temp = queue[0];
for (int i = 0; i < nItem-2; i++){
queue[i] = queue[i+1];
}
nItem --;
return temp;
}
public int peekFront(){
if (nItem == 0){
System.err.println("PriorityQueue is empty!!!");
}
int temp = queue[0];
return temp;
}
public static void main(String args[]){
PrioriityQueue prioriityQueue = new PrioriityQueue(10);
Random random = new Random();
for (int i = 0; i < 8; i++){
int num = random.nextInt();
prioriityQueue.insert(num);
}
for (int i = 0; i < 8; i++) {
System.out.println(prioriityQueue.remove());
}
}
}
链表
链表原理
链表是一类特殊的线性表,由一系列点组成,节点顺序是通过节点元素的指针连接次序进行。链表中节点包含两部分,一个是自身的数据,一个是指向下一个节点的引用。链表和数组:这两种数据结构都可以作为数据的存储结构,但是数组是顺序存放,长度是固定的,而链表长度不限制,不是连续的存储。另外从效率上说,链表在插入和删除操作上效率很高,因为只需要改变各自的索引,不需要移动等等。而数组就牛逼了,在某一个地方添加元素,后面的都要全部往后移动,删除全部要往前移动,但是数组在查询上是高于链表的,直接索引即可,所以基本能用数组的地方也可以用链表。链表的基本操作:插入数据,删除数据,查看所有数据,查找指定节点,删除指定节点。链表基本实现。
首先是定义一个节点,一个节点应该有当前数据和下一个节点的数据:
public class LinkNode {
private int id;
private LinkNode next;
public int getId() {
return id;
}
public LinkNode getNext() {
return next;
}
public void setNext(LinkNode node) {
this.next = node;
}
public void setId(int id) {
this.id = id;
}
public LinkNode(int id){
super();
this.id = id;
this.next = null;
}
public void printNode(){
String s = "id = " + id + " ";
if (next != null){
s += ",next = " + next.getId() + " ";
}
System.out.print(s);
}
}
然后就是基本的删除添加操作了:
public class SingleLinkList {
private LinkNode firstNode;
private int count;
public SingleLinkList() {
firstNode = null;
count = 0;
}
public void insertFirst(int id) {
LinkNode linkNode = new LinkNode(id);
linkNode.setNext(firstNode);
firstNode = linkNode;
count++;
}
public void insertNode(int id, int index) {
if (index < 0 || index > count + 1) {
throw new IllegalArgumentException("index must be in range[0, N+1]");
}
LinkNode linkNode = new LinkNode(id);
if (index == 1) {
linkNode.setNext(firstNode);
firstNode = linkNode;
count++;
return;
}
LinkNode p = firstNode, q = p;
for (int i = 0; i < index - 1; i++) {
q = p;
p = p.getNext();
}
q.setNext(linkNode);
linkNode.setNext(p);
count++;
}
public LinkNode removeNode(int index) {
LinkNode p = firstNode, q = p, a = p;
if (index < 0 || index > count) {
throw new IllegalArgumentException("index must be in range[0, N]");
}
if (index == 1) {
p = firstNode;
firstNode = firstNode.getNext();
count--;
return p;
}
for (int i = 0; i < index - 1; i++) {
a = p;
p = p.getNext();
q = p.getNext();
}
a.setNext(q);
return p;
}
public LinkNode find(int id) {
LinkNode linkNode = firstNode;
while (linkNode != null){
if (linkNode.getId() == id){
return linkNode;
}
linkNode = linkNode.getNext();
}
return null;
}
public void display() {
LinkNode linkNode = firstNode;
while (linkNode != null) {
linkNode.printNode();
linkNode = linkNode.getNext();
}
System.out.println();
}
public int count(){
return count;
}
public static void main(String args[]) {
SingleLinkList singleLinkList = new SingleLinkList();
for (int i = 0; i < 10; i++) {
singleLinkList.insertFirst(i);
}
singleLinkList.display();
singleLinkList.insertNode(15, 11);
singleLinkList.removeNode(5);
singleLinkList.display();
}
}
都比较简单。
有单向链表自然就有双向链表。单向链表只是有一个指向下一个节点的信息,而双向链表就是包含指向了前一个和后一个节点信息的。这样做带来了节点的开销,但是对于插入删除带来了极大的便利,原来单向链表需要三个变量来控制,现在用双向链表,只需要一个就好了,因为通过这个节点就可以获得前后节点,然后前一个节点指向后一个,后一个节点指回前一个即可。
public class FirstLastList {
private int count;
private DouleLinkNode firstNode;
public FirstLastList() {
count = 0;
firstNode = null;
}
public void insertFirst(int id) {
DouleLinkNode douleLinkNode = new DouleLinkNode(id);
DouleLinkNode p = firstNode;
if (p != null)
p.setPrevious(douleLinkNode);
douleLinkNode.setNext(firstNode);
firstNode = douleLinkNode;
count++;
}
public void insetNode(int id, int index) {
if (index < 0 || index > count + 1) {
throw new IllegalArgumentException("index must be in range[0, N+1]");
}
if (index == 1) {
insertFirst(id);
count++;
return;
}
DouleLinkNode douleLinkNode = new DouleLinkNode(id);
DouleLinkNode p, q;
p = q = firstNode;
for (int i = 0; i < index - 1; i++) {
q = p;
p = p.getNext();
}
douleLinkNode.setNext(p);
q.setNext(douleLinkNode);
douleLinkNode.setPrevious(q);
count++;
}
public DouleLinkNode removeNode(int index) {
if (index < 0 || index > count) {
throw new IllegalArgumentException("index must be in range[0, N]");
}
DouleLinkNode p = firstNode;
if (index == 1) {
firstNode = firstNode.getNext();
firstNode.setPrevious(null);
count--;
return p;
}
for (int i = 0; i < index - 1; i++) {
p = p.getNext();
}
DouleLinkNode q, l;
q = p.getPrevious();
l = p.getNext();
q.setNext(l);
l.setPrevious(q);
count--;
return p;
}
public void display() {
DouleLinkNode linkNode = firstNode;
while (linkNode != null) {
linkNode.printNode();
linkNode = linkNode.getNext();
}
System.out.println();
}
public static void main(String args[]) {
FirstLastList singleLinkList = new FirstLastList();
for (int i = 0; i < 10; i++) {
singleLinkList.insertFirst(i);
}
singleLinkList.display();
singleLinkList.insetNode(15, 5);
singleLinkList.removeNode(1);
singleLinkList.display();
}
}
链表和递归
首先来看一个Leecode的问题,203,删除链表节点,这个问题很简单: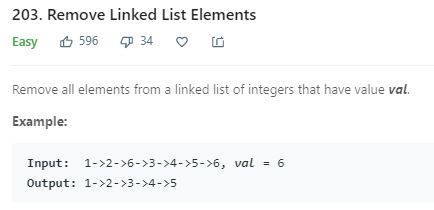
删除一个链表里面所有的节点。删除链表节点有两种,一种是用虚拟头结点删除,这种删除方法可以使得每一个节点的删除都可以一视同仁,一种算法可以搞定,但是如果不用虚拟头结点,就要把第一个节点提出来单独处理。这里使用的是没有虚拟头节点的方法。
class Solution {
public ListNode removeElements(ListNode head, int val) {
while (head != null && head.val == val){
ListNode delNode = head;
head = head.next;
delNode.next = null;
}
if (head == null){
return null;
}
ListNode pre = head;
while (pre.next != null){
if (pre.next.val == val){
ListNode delNode = pre.next;
pre.next = delNode.next;
delNode.next = null;
}else {
pre = pre.next;
}
}
return head;
}
}
回到递归,递归本质上就是把一个原来的问题转化成更小的同一个问题。通常这个·问题的规模是小到不能再小为止,这样最后再往回退回去。而链表有天然的递归性,每一个节点后面都挂着另一个节点,所以可以看成是:
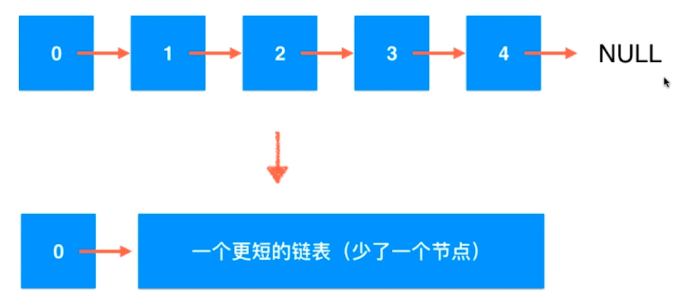
每一次递归只是处理当前头部的节点是不是,如果是,那就不用返回头节点了,直接用下一层递归的结果返回即可。这种方法写起来非常简单,不用考虑递归内部的运行流程,写起来很抽象:
public ListNode removeElements_version2(ListNode head, int val){
if (head == null){
return null;
}
ListNode res = removeElements(head.next, val);
if (head.val == val){
return res;
}else {
head.next = res;
return head;
}
}
运行结果是一样的,但是更容易理解。
哈夫曼
哈夫曼编码是一种统计编码,属于无损压缩。基本思路就是对于每一个字符编码的码长是变化的,对于出现频率高的,编码长度会比较短,而对于出现频率较低的,编码长度较长。编码规则还规定了每一个编码都不能是其他字符编码的前缀。哈夫曼编码是基于二叉树的一种树。
哈夫曼树又称为最优二叉树,是一种带权路径长度最短的二叉树。所谓树的带权路径长度,就是树中所有叶子节点的权值乘上其到根节点的路径长度。树的带权路径长度为,要做到权值越小,必须要保证权值越大的越靠近根节点,越小的越远离。所以构造方法就出来了:1.给定n个权值,构成n棵只有根节点的二叉树,可以按照权值升序排列。2.在这些二叉树里面选择权值最小的两棵树作为构造的二叉树的新左右节点,这棵二叉树的权值就是两颗树之和。删除两棵树,重复上述步骤直到只有一棵树。
对于构造的这棵哈夫曼树,可以对他实现压缩和解压操作。首先是统计文本出现单词的次数,把次数作为这个单词出现的权值,然后按照上面的方法构造哈夫曼树,把左边的作为0,右边的作为1,编码输出就是压缩的数据。一般的操作流程是:先把用数据建立霍夫曼树,然后按照左0右1的原则建立编码,然后替换文本的编码,把文本的编码替换成0101的格式,也就是二进制,这样就是可以使得整个文件变成二进制,再8位8位的分开就可以压缩成字节了。
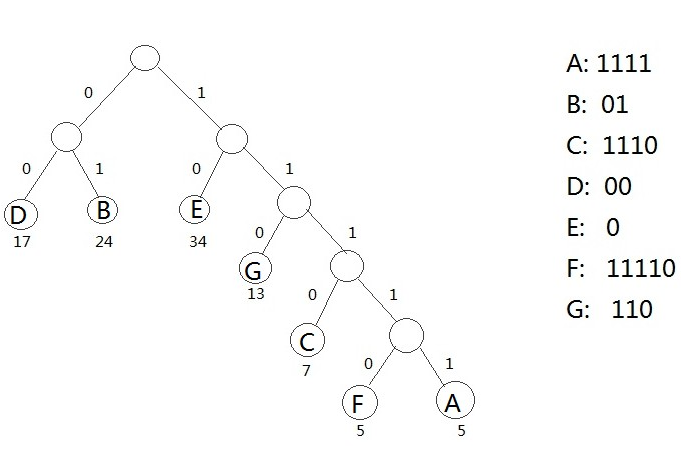
霍夫曼树实现压缩解压
实现压缩也就是几个步骤:首先要统计词频,也就是统计每一个词出现的数量,然后建立霍夫曼树,得到霍夫曼编码,变成字节,输出到压缩文件中。
private HuffmanPriorityQueue statistics(String str) {
Map<Character, Integer> map = new HashMap<>();
char[] charString = str.toCharArray();
for (char c : charString) {
Object object = map.get(c);
if (object == null) {
map.put(c, 1);
} else {
map.put(c, ((Integer) object) + 1);
}
}
HuffmanPriorityQueue huffmanPriorityQueue = new HuffmanPriorityQueue(map.size());
for (char c : map.keySet()) {
HuffmanNode node = new HuffmanNode(c, map.get(c));
huffmanPriorityQueue.insert(node);
}
return huffmanPriorityQueue;
}
建立霍夫曼树,首先是节点,霍夫曼树的节点需要左右子节点和代表字符:
public class HuffmanNode {
private char c;
private int count;
private HuffmanNode leftNode;
private HuffmanNode rightNode;
public HuffmanNode(char c, int count){
this.c = c;
this.count = count;
}
建立霍夫曼树的过程很简单,每一次从优先队列里面出两个最小值,构造一个新的节点,放回优先队列,循环上述操作。
private HuffmanNode buildHuffmanTree(HuffmanPriorityQueue huffmanPriorityQueue) {
while (huffmanPriorityQueue.size() > 1) {
HuffmanNode left = huffmanPriorityQueue.remove();
HuffmanNode right = huffmanPriorityQueue.remove();
HuffmanNode root = new HuffmanNode((char) 0, left.getCount() + right.getCount());
root.setLeftNode(left);
root.setRightNode(right);
huffmanPriorityQueue.insert(root);
}
return huffmanPriorityQueue.peekFront();
}
然后就是建立霍夫曼编码的过程,通过递归构造即可,递归到左边子树添0,右边子树添1。
private void buildHuffmanCode(Map<String, String> map, HuffmanNode huffmanTree, String stringCode) {
if (huffmanTree.getLeftNode() == null && huffmanTree.getRightNode() == null) {
map.put("" + huffmanTree.getC(), stringCode);
return;
}
if (huffmanTree.getLeftNode() != null) {
buildHuffmanCode(map, huffmanTree.getLeftNode(), stringCode + "0");
}
if (huffmanTree.getRightNode() != null) {
buildHuffmanCode(map, huffmanTree.getRightNode(), stringCode + "1");
}
}
因为只有节点才是字符,其他都是相加的中间节点而已。递归到叶子就停下。输出到文件函数:
private void outData(String str, Map<String, String> map, String outName) {
File outFile = new File(outName);
DataOutputStream dataOutputStream = null;
try {
dataOutputStream = new DataOutputStream(new FileOutputStream(outFile));
outCode(dataOutputStream, map);
String dataHuffmanCode = source2Code(str, map);
outDataHuffmanCode(dataOutputStream, dataHuffmanCode);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
dataOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
首先要把编码输入文件,告诉别人编码是多少,长度是多少,然后再输入内容。转成了二进制字符之后,就需要八位八位的切分开来。然后把八位变成字节即可:
private byte char2bytes(String s) {
byte ret = 0;
char[] cs = s.toCharArray();
for (int i = 0; i < cs.length; i++) {
byte tempB = (byte) (Byte.parseByte("" + cs[i]) * Math.pow(2, cs.length - i - 1));
ret = (byte) (ret + tempB);
}
return ret;
}

最后压缩成了字节文件。
解压就简单了,和上面相反操作即可:
public String decompress(String fileName) {
DataInputStream in = null;
String srcContent = "";
try {
in = new DataInputStream(new FileInputStream(new File(fileName)));
Map<String, String> map = readCode(in);
byte[] data = readDatas(in);
int[] dataInt = bytes2intArray(data);
srcContent = Huffman2Char(map, dataInt);
System.out.println(srcContent);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return srcContent;
根据第一行读出来的还原即可。但是要注意在后面字节变成二进制字符的时候有可能存在不少八位的问题,有可能是4 5 6这样的,这个时候就要在左边补上0了,补齐8位,因为是按照8位分的。
成功还原。
最后附上github地址:https://github.com/GreenArrow2017/DataStructure/tree/master/DataStucture