版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u010046908/article/details/56015388
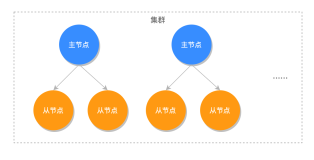
前面写过一篇关于dubbo2.5-spring4-mybastis3.2-springmvc4-mongodb3.4-redis3.2整合(九)之 spring中定时器quartz的整合。今天主要来继续总结quartz在集群中的使用。
1、说明
- quartz可以通过jdbc直连连接到MYSQL数据库,读取配置在数据库里的job初始化信息,并且把job通过java序列化到数据库里,这样就使得每个job信息得到了持久化,即使在jvm或者容器挂掉的情况下,也能通过数据库感知到其他job的状态和信息。
- quartz集群各节点之间是通过同一个数据库实例(准确的说是同一个数据库实例的同一套表)来感知彼此的。
2、数据库表的创建
创建quartz要用的数据库表,此sql文件在:quartz-2.2.3\docs\dbTables。此文件夹下有各个数据库的sql文件,mysql选择tables_mysql.sql。总共有11张表。
- QRTZ_CALENDARS 以 Blob 类型存储 Quartz 的 Calendar 信息
- QRTZ_CRON_TRIGGERS 存储 Cron Trigger,包括 Cron表达式和时区信息
- QRTZ_FIRED_TRIGGERS 存储与已触发的 Trigger 相关的状态信息,以及相联 Job的执行信息
- QRTZ_PAUSED_TRIGGER_GRPS 存储已暂停的 Trigger 组的信息
- QRTZ_SCHEDULER_STATE 存储少量的有关 Scheduler 的状态信息,和别的 Scheduler实例(假如是用于一个集群中)
- QRTZ_LOCKS 存储程序的悲观锁的信息(假如使用了悲观锁)
- QRTZ_JOB_DETAILS 存储每一个已配置的 Job 的详细信息
- QRTZ_JOB_LISTENERS 存储有关已配置的 JobListener 的信息
- QRTZ_SIMPLE_TRIGGERS 存储简单的Trigger,包括重复次数,间隔,以及已触的次数
- QRTZ_BLOG_TRIGGERS Trigger 作为 Blob 类型存储(用于 Quartz 用户用 JDBC创建他们自己定制的 Trigger 类型,JobStore 并不知道如何存储实例的时候)
- QRTZ_TRIGGER_LISTENERS 存储已配置的 TriggerListener 的信息
- QRTZ_TRIGGERS 存储已配置的 Trigger 的信息
3、 quartz.properties的配置
#调度标识名 集群中每一个实例都必须使用相同的名称
org.quartz.scheduler.instanceName = MyScheduler
#线程数量
org.quartz.threadPool.threadCount = 10
#线程优先级
org.quartz.threadPool.threadPriority = 5
#数据保存方式为持久化
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX
#数据库平台
org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
#表的前缀
org.quartz.jobStore.tablePrefix = QRTZ_
#库的别名
org.quartz.jobStore.dataSource = myDS
# Cluster开启集群
org.quartz.jobStore.isClustered = true
#ID设置为自动获取 每一个必须不同
org.quartz.scheduler.instanceId = AUTO
org.quartz.dataSource.myDS.driver = com.mysql.jdbc.Driver
org.quartz.dataSource.myDS.URL = jdbc:mysql://localhost:3306/db_my?characterEncoding=utf-8
org.quartz.dataSource.myDS.user = root
org.quartz.dataSource.myDS.password = 123456
org.quartz.dataSource.myDS.maxConnections = 54.创建任务
package com.lidong.dubbo.core.util.quartz;
import java.io.Serializable;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.quartz.DisallowConcurrentExecution;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import org.quartz.PersistJobDataAfterExecution;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.scheduling.quartz.MethodInvokingJobDetailFactoryBean;
import org.springframework.scheduling.quartz.QuartzJobBean;
/**
* @项目名称:lidong-dubbo
* @类名:SpringQtz
* @类的描述: 作业类的调度
* @作者:lidong
* @创建时间:2017/2/8 下午5:41
* @公司:chni
* @QQ:1561281670
* @邮箱:lidong1665@163.com
*/
public class SpringQtz extends QuartzJobBean{
static Logger logger = LoggerFactory.getLogger(SpringQtz.class);
private static int counter = 0;
@Override
protected void executeInternal(JobExecutionContext jobExecutionContext) throws JobExecutionException {
long ms = System.currentTimeMillis();
logger.error(" SpringQtz start 执行");
logger.info("-------"+new SimpleDateFormat("yyyy-MM-dd hh:mm:ss").format(new Date(ms))+" "+"(" + counter++ + ")");
}
}5.spring-quartz.xml的配置
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<!-- 定义调用对象和调用对象的方法 -->
<bean id="SpringQtzJobDetail"
class="org.springframework.scheduling.quartz.JobDetailFactoryBean">
<property name="jobClass" value="com.lidong.dubbo.core.util.quartz.SpringQtz"/>
<property name="durability" value="true"/>
<property name="group" value="job_work"/>
<property name="name" value="job_work_name"/>
</bean>
<bean id="SpringQtzJobDetail1"
class="org.springframework.scheduling.quartz.JobDetailFactoryBean">
<property name="jobClass" value="com.lidong.dubbo.core.util.quartz.SpringQtzDemo"/>
<property name="durability" value="true"/>
<property name="group" value="job_work1"/>
<property name="name" value="job_work_name1"/>
</bean>
<!-- ======================== 调度触发器 ======================== -->
<bean id="CronTriggerBean"
class="org.springframework.scheduling.quartz.CronTriggerFactoryBean">
<property name="jobDetail" ref="SpringQtzJobDetail"></property>
<!-- cron表达式 -->
<property name="cronExpression" value="0/20 * * * * ?"></property>
</bean>
<bean id="CronTriggerBean1"
class="org.springframework.scheduling.quartz.CronTriggerFactoryBean">
<property name="jobDetail" ref="SpringQtzJobDetail1"></property>
<!-- cron表达式 -->
<property name="cronExpression" value="0/30 * * * * ?"></property>
</bean>
<!-- ======================== 调度工厂 ======================== -->
<bean id="SpringJobSchedulerFactoryBean"
class="org.springframework.scheduling.quartz.SchedulerFactoryBean">
<property name="dataSource">
<ref bean="dataSource"/>
</property>
<property name="applicationContextSchedulerContextKey" value="applicationContext" />
<property name="configLocation" value="classpath:config/quartz.properties"/>
<!--启动时更新己存在的Job,这样就不用每次修改targetObject后删除qrtz_job_details表对应记录了-->
<property name="overwriteExistingJobs" value="true"/>
<property name="triggers">
<list>
<ref bean="CronTriggerBean" />
<ref bean="CronTriggerBean1" />
</list>
</property>
<property name="jobDetails">
<list>
<ref bean="SpringQtzJobDetail" />
<ref bean="SpringQtzJobDetail1" />
</list>
</property>
</bean>
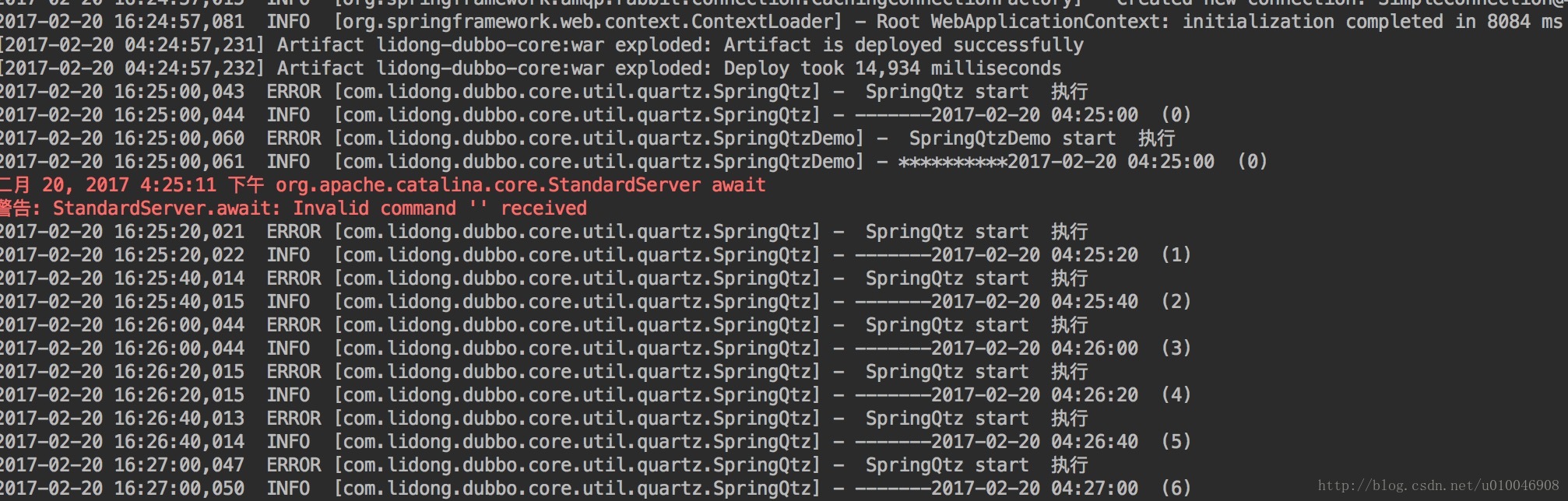
</beans> 6. 分别部署到两台Tomcat服务器查看效果
第1个tomcat的结果:
第2个omcat的结果:
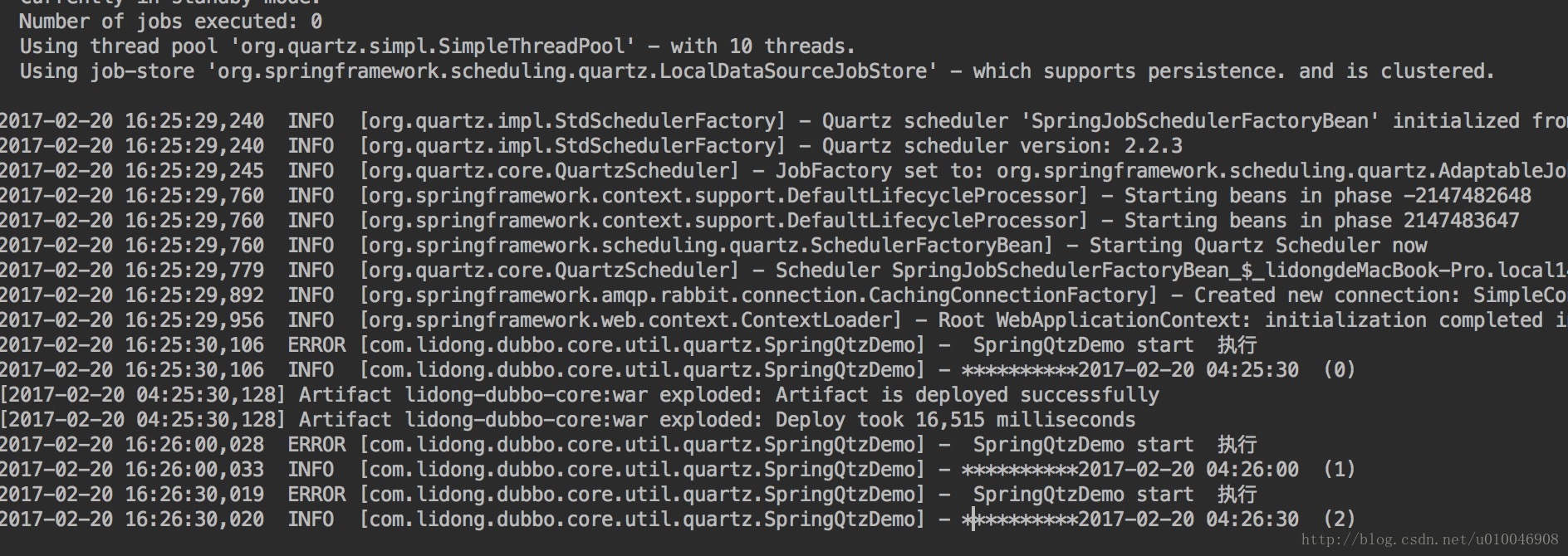
可以看到。任务不会重复执行。