使用这些库把 Python 变成一个科学数据分析和建模工具。
Python 的许多特性,比如开发效率、代码可读性、速度等使之成为了数据科学爱好者的首选编程语言。对于想要升级应用程序功能的数据科学家和机器学习专家来说,Python 通常是最好的选择(比如,Andrey Bulezyuk 使用 Python 语言创造了一个优秀的机器学习应用程序)。
由于 Python 的广泛使用,因此它拥有大量的库,使得数据科学家能够很容易地完成复杂的任务,而且不会遇到许多编码困难。下面列出 3 个用于数据科学的顶级 Python 库。如果你想在数据科学这一领域开始你的职业生涯,就去了解一下它们吧。
NumPy
NumPy(数值 Python 的简称)是其中一个顶级数据科学库,它拥有许多有用的资源,从而帮助数据科学家把 Python 变成一个强大的科学分析和建模工具。NumPy 是在 BSD 许可证的许可下开源的,它是在科学计算中执行任务的基础 Python 库。SciPy 是一个更大的基于 Python 生态系统的开源工具,而 NumPy 是 SciPy 非常重要的一部分。
NumPy 为 Python 提供了大量数据结构,从而能够轻松地执行多维数组和矩阵运算。除了用于求解线性代数方程和其它数学计算之外,NumPy 还可以用做不同类型通用数据的多维容器。
此外,NumPy 还可以和其他编程语言无缝集成,比如 C/C++ 和 Fortran。NumPy 的多功能性使得它可以简单而快速地与大量数据库和工具结合。比如,让我们来看一下如何使用 NumPy(缩写成 np)来实现两个矩阵的乘法运算。
我们首先导入 NumPy 库(在这些例子中,我将使用 Jupyter notebook):
import numpy as np
接下来,使用 eye() 函数来生成指定维数的单位矩阵:
matrix_one = np.eye(3)
matrix_one
输出如下:
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
让我们生成另一个 3×3 矩阵。
我们使用 arange([starting number], [stopping number]) 函数来排列数字。注意,函数中的第一个参数是需要列出的初始数字,而后一个数字不包含在生成的结果中。
另外,使用 reshape() 函数把原始生成的矩阵的维度改成我们需要的维度。为了使两个矩阵“可乘”,它们需要有相同的维度。
matrix_two = np.arange(1,10).reshape(3,3)
matrix_two
输出如下:
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
接下来,使用 dot() 函数将两个矩阵相乘。
matrix_multiply = np.dot(matrix_one, matrix_two)
matrix_multiply
相乘后的输出如下:
array([[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.]])
太好了!
我们成功使用 NumPy 完成了两个矩阵的相乘,而不是使用普通冗长vanilla的 Python 代码。
下面是这个例子的完整代码:
import numpy as np
#生成一个 3x3 单位矩阵
matrix_one = np.eye(3)
matrix_one
#生成另一个 3x3 矩阵以用来做乘法运算
matrix_two = np.arange(1,10).reshape(3,3)
matrix_two
#将两个矩阵相乘
matrix_multiply = np.dot(matrix_one, matrix_two)
matrix_multiply
Pandas
Pandas 是另一个可以提高你的 Python 数据科学技能的优秀库。就和 NumPy 一样,它属于 SciPy 开源软件家族,可以在 BSD 自由许可证许可下使用。
Pandas 提供了多能而强大的工具,用于管理数据结构和执行大量数据分析。该库能够很好的处理不完整、非结构化和无序的真实世界数据,并且提供了用于整形、聚合、分析和可视化数据集的工具
Pandas 中有三种类型的数据结构:
- Series:一维、相同数据类型的数组
- DataFrame:二维异型矩阵
- Panel:三维大小可变数组
例如,我们来看一下如何使用 Panda 库(缩写成 pd)来执行一些描述性统计计算。
首先导入该库:
import pandas as pd
然后,创建一个序列series字典:
d = {'Name':pd.Series(['Alfrick','Michael','Wendy','Paul','Dusan','George','Andreas',
'Irene','Sagar','Simon','James','Rose']),
'Years of Experience':pd.Series([5,9,1,4,3,4,7,9,6,8,3,1]),
'Programming Language':pd.Series(['Python','JavaScript','PHP','C++','Java','Scala','React','Ruby','Angular','PHP','Python','JavaScript'])
}
接下来,再创建一个数据框DataFrame:
df = pd.DataFrame(d)
输出是一个非常规整的表:
Name Programming Language Years of Experience
0 Alfrick Python 5
1 Michael JavaScript 9
2 Wendy PHP 1
3 Paul C++ 4
4 Dusan Java 3
5 George Scala 4
6 Andreas React 7
7 Irene Ruby 9
8 Sagar Angular 6
9 Simon PHP 8
10 James Python 3
11 Rose JavaScript 1
下面是这个例子的完整代码:
import pandas as pd
#创建一个序列字典
d = {'Name':pd.Series(['Alfrick','Michael','Wendy','Paul','Dusan','George','Andreas',
'Irene','Sagar','Simon','James','Rose']),
'Years of Experience':pd.Series([5,9,1,4,3,4,7,9,6,8,3,1]),
'Programming Language':pd.Series(['Python','JavaScript','PHP','C++','Java','Scala','React','Ruby','Angular','PHP','Python','JavaScript'])
}
#创建一个数据框
df = pd.DataFrame(d)
print(df)
Matplotlib
Matplotlib 也是 Scipy 核心包的一部分,并且在 BSD 许可证下可用。它是一个非常流行的科学库,用于实现简单而强大的可视化。你可以使用这个 Python 数据科学框架来生成曲线图、柱状图、直方图以及各种不同形状的图表,并且不用担心需要写很多行的代码。例如,我们来看一下如何使用 Matplotlib 库来生成一个简单的柱状图。
首先导入该库:
from matplotlib import pyplot as plt
然后生成 x 轴和 y 轴的数值:
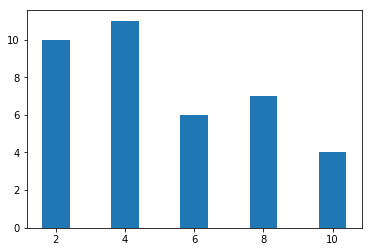
x = [2, 4, 6, 8, 10]
y = [10, 11, 6, 7, 4]
接下来,调用函数来绘制柱状图:
plt.bar(x,y)
最后,显示图表:
plt.show()
柱状图如下:
下面是这个例子的完整代码:
#导入 Matplotlib 库
from matplotlib import pyplot as plt
#和 import matplotlib.pyplot as plt 一样
#生成 x 轴的数值
x = [2, 4, 6, 8, 10]
#生成 y 轴的数值
y = [10, 11, 6, 7, 4]
#调用函数来绘制柱状图
plt.bar(x,y)
#显示图表
plt.show()
59*-40.00000000+
630.0000000
<p></p>
<h2>总结</h2>
<p>Python 编程语言非常擅长数据处理和准备,但是在科学数据分析和建模方面就没有那么优秀了。幸好有这些用于<a href="https://www.liveedu.tv/guides/data-science/">数据科学</a>的顶级 Python 框架填补了这一空缺,从而你能够进行复杂的数学计算以及创建复杂模型,进而让数据变得更有意义。</p>
<p>你还知道其它的 Python 数据挖掘库吗?你的使用经验是什么样的?请在下面的评论中和我们分享。</p>
原文地址:https://linux.cn/article-10080-1.html