在系列的第一篇文章中,我已经介绍过如何在阿里云基于kubeasz搭建K8S集群,通过在K8S上部署gitlab并暴露至集群外来演示服务部署与发现的流程。文章写于4月,忙碌了小半年后,我才有时间把后续部分补齐。系列会分为三篇,本篇将继续部署基础设施,如jenkins、harbor、efk等,以便为第三篇项目实战做好准备。
需要说明的是,阿里云迭代的实在是太快了,2018年4月的时候,由于SLB不支持HTTP跳转HTTPS,迫不得已使用了Ingress-Nginx来做跳转控制。但在4月底的时候,SLB已经在部分地区如华北、国外节点支持HTTP跳转HTTPS。到了5月更是全节点支持。这样以来,又简化了Ingress-Nginx的配置。
一、Jenkins
一般情况下,我们搭建一个Jenkins用于持续集成,那么所有的Jobs都会在这一个Jenkins上进行build,如果Jobs数量较多,势必会引起Jenkins资源不足导致各种问题出现。于是,对于项目较多的部门、公司使用Jenkins,需要搭建Jenkins集群,也就是增加Jenkins Slave来协同工作。
但是增加Jenkins Slave又会引出新的问题,资源不能按需调度。Jobs少的时候资源闲置,而Jobs突然增多仍然会资源不足。我们希望能动态分配Jenkins Slave,即用即拿,用完即毁。这恰好符合K8S中Pod的特性。所以这里,我们在K8S中搭建一个Jenkins集群,并且是Jenkins Slave in Pod.
1.1 准备镜像
我们需要准备两个镜像,一个是Jenkins Master,一个是Jenkins Slave:
Jenkins Master
可根据实际需求定制Dockerfile
FROM jenkins/jenkins:latest USER root # Set jessie source RUN cecho '' > /etc/apt/sources.list.d/jessie-backports.list \ && echo "deb http://mirrors.aliyun.com/debian jessie main contrib non-free" > /etc/apt/sources.list \ && echo "deb http://mirrors.aliyun.com/debian jessie-updates main contrib non-free" >> /etc/apt/sources.list \ && echo "deb http://mirrors.aliyun.com/debian-security jessie/updates main contrib non-free" >> /etc/apt/sources.list # Update RUN apt-get update && apt-get install -y libltdl7 && apt-get clean # INSTALL KUBECTL RUN curl -LO https://storage.googleapis.com/kubernetes-release/release/`curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt`/bin/linux/amd64/kubectl && \ chmod +x ./kubectl && \ mv ./kubectl /usr/local/bin/kubectl # Set time zone RUN rm -rf /etc/localtime && cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && \ echo 'Asia/Shanghai' > /etc/timezone # Skip setup wizard、 TimeZone and CSP ENV JAVA_OPTS="-Djenkins.install.runSetupWizard=false -Duser.timezone=Asia/Shanghai -Dhudson.model.DirectoryBrowserSupport.CSP=\"default-src 'self'; script-src 'self' 'unsafe-inline' 'unsafe-eval'; style-src 'self' 'unsafe-inline';\""
Jenkins Salve
一般来说只需要安装kubelet就可以了
FROM jenkinsci/jnlp-slave USER root # INSTALL KUBECTL RUN curl -LO https://storage.googleapis.com/kubernetes-release/release/`curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt`/bin/linux/amd64/kubectl && \ chmod +x ./kubectl && \ mv ./kubectl /usr/local/bin/kubectl
生成镜像后可以push到自己的镜像仓库中备用
1.2 部署Jenkins Master
为了部署Jenkins、Jenkins Slave和后续的Elastic Search,建议ECS的最小内存为8G
在K8S上部署Jenkins的yaml参考如下:
apiVersionv1 kindNamespace metadata namejenkins-ci --- apiVersionv1 kindServiceAccount metadata namejenkins-ci namespacejenkins-ci --- apiVersionrbac.authorization.k8s.io/v1beta1 kindClusterRoleBinding metadata namejenkins-ci roleRef apiGrouprbac.authorization.k8s.io kindClusterRole namecluster-admin subjects kindServiceAccount namejenkins-ci namespacejenkins-ci --- # 设置两个pv,一个用于作为workspace,一个用于存储ssh key apiVersionv1 kindPersistentVolume metadata namejenkins-home labels releasejenkins-home namespacejenkins-ci spec # workspace 大小为10G capacity storage10Gi accessModes ReadWriteMany persistentVolumeReclaimPolicyRetain # 使用阿里云NAS,需要注意,必须先在NAS创建目录 /jenkins/jenkins-home nfs path/jenkins/jenkins-home serverxxxx.nas.aliyuncs.com --- apiVersionv1 kindPersistentVolume metadata namejenkins-ssh labels releasejenkins-ssh namespacejenkins-ci spec # ssh key 只需要1M空间即可 capacity storage1Mi accessModes ReadWriteMany persistentVolumeReclaimPolicyRetain # 不要忘了在NAS创建目录 /jenkins/ssh nfs path/jenkins/ssh serverxxxx.nas.aliyuncs.com --- apiVersionv1 kindPersistentVolumeClaim metadata namejenkins-home-claim namespacejenkins-ci spec accessModes ReadWriteMany resources requests storage10Gi selector matchLabels releasejenkins-home --- apiVersionv1 kindPersistentVolumeClaim metadata namejenkins-ssh-claim namespacejenkins-ci spec accessModes ReadWriteMany resources requests storage1Mi selector matchLabels releasejenkins-ssh --- apiVersionextensions/v1beta1 kindDeployment metadata namejenkins namespacejenkins-ci spec replicas1 template metadata labels namejenkins spec serviceAccountjenkins-ci containers namejenkins imagePullPolicyAlways # 使用1.1小结创建的 Jenkins Master 镜像 imagexx.xx.xx/jenkins1.0.0 # 资源管理,详见第二章 resources limits cpu1 memory2Gi requests cpu0.5 memory1Gi # 开放8080端口用于访问,开放50000端口用于Jenkins Slave和Master的通讯 ports containerPort8080 containerPort50000 readinessProbe tcpSocket port8080 initialDelaySeconds40 periodSeconds20 securityContext privilegedtrue volumeMounts # 映射K8S Node的docker,也就是docker outside docker,这样就不需要在Jenkins里面安装docker mountPath/var/run/docker.sock namedocker-sock mountPath/usr/bin/docker namedocker-bin mountPath/var/jenkins_home namejenkins-home mountPath/root/.ssh namejenkins-ssh volumes namedocker-sock hostPath path/var/run/docker.sock namedocker-bin hostPath path/opt/kube/bin/docker namejenkins-home persistentVolumeClaim claimNamejenkins-home-claim namejenkins-ssh persistentVolumeClaim claimNamejenkins-ssh-claim --- kindService apiVersionv1 metadata namejenkins-service namespacejenkins-ci spec typeNodePort selector namejenkins # 将Jenkins Master的50000端口作为NodePort映射到K8S的30001端口 ports namejenkins-agent port50000 targetPort50000 nodePort30001 namejenkins port8080 targetPort8080 --- apiVersionextensions/v1beta1 kindIngress metadata namejenkins-ingress namespacejenkins-ci annotations nginx.ingress.kubernetes.io/proxy-body-size"0" spec rules # 设置Ingress-Nginx域名和端口 hostxxx.xxx.com http paths path/ backend serviceNamejenkins-service servicePort8080
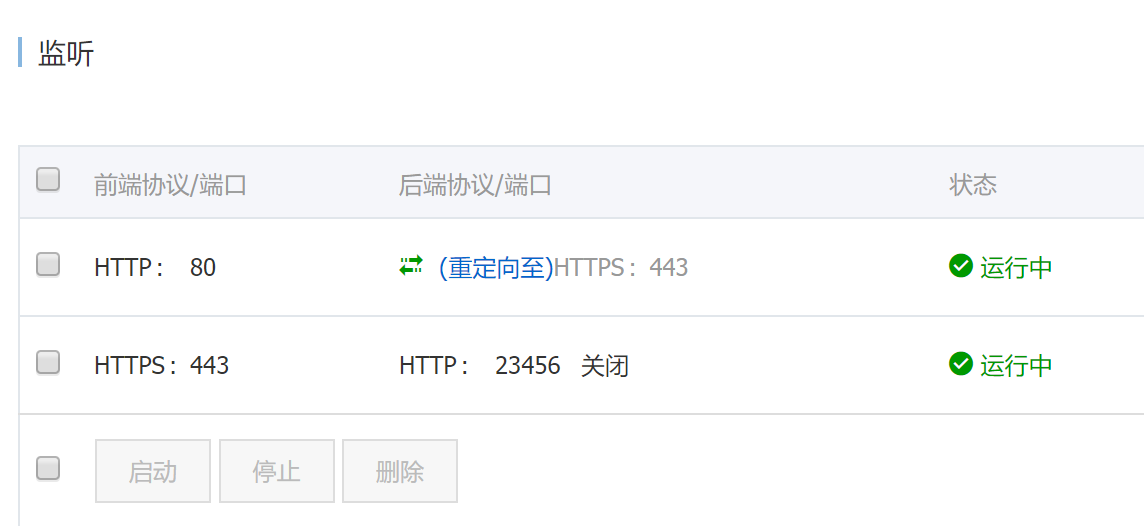
最后附一下SLB的配置
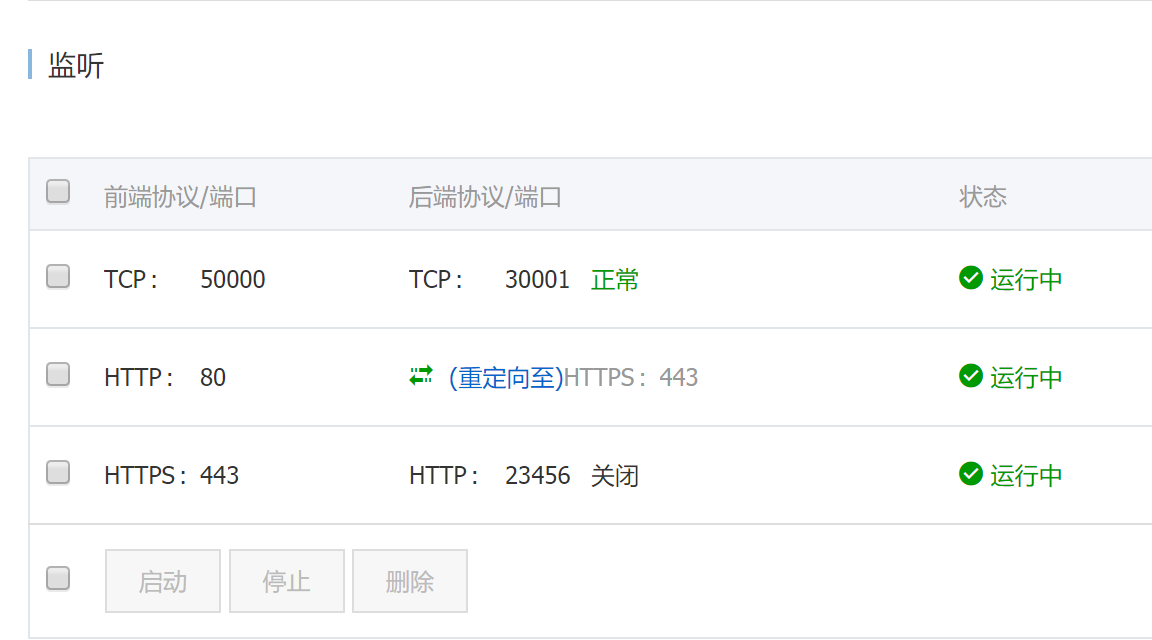
这样就可以通过域名xxx.xxx.com访问Jenkins,并且可以通过xxx.xxx.com:50000来链接集群外的Slave。当然,集群内的Slave直接通过serviceName-namespace:50000访问就可以了
1.3 配置Jenkins Slave
以管理员进入Jenkins,安装”Kubernetes”插件,然后进入系统设置界面,”Add a new cloud” – “Kubernetes”,配置如下:
- Kubernetes URL:https://kubernetes.default.svc.cluster.local
- Jenkins URL:http://jenkins-service.jenkins-ci:8080
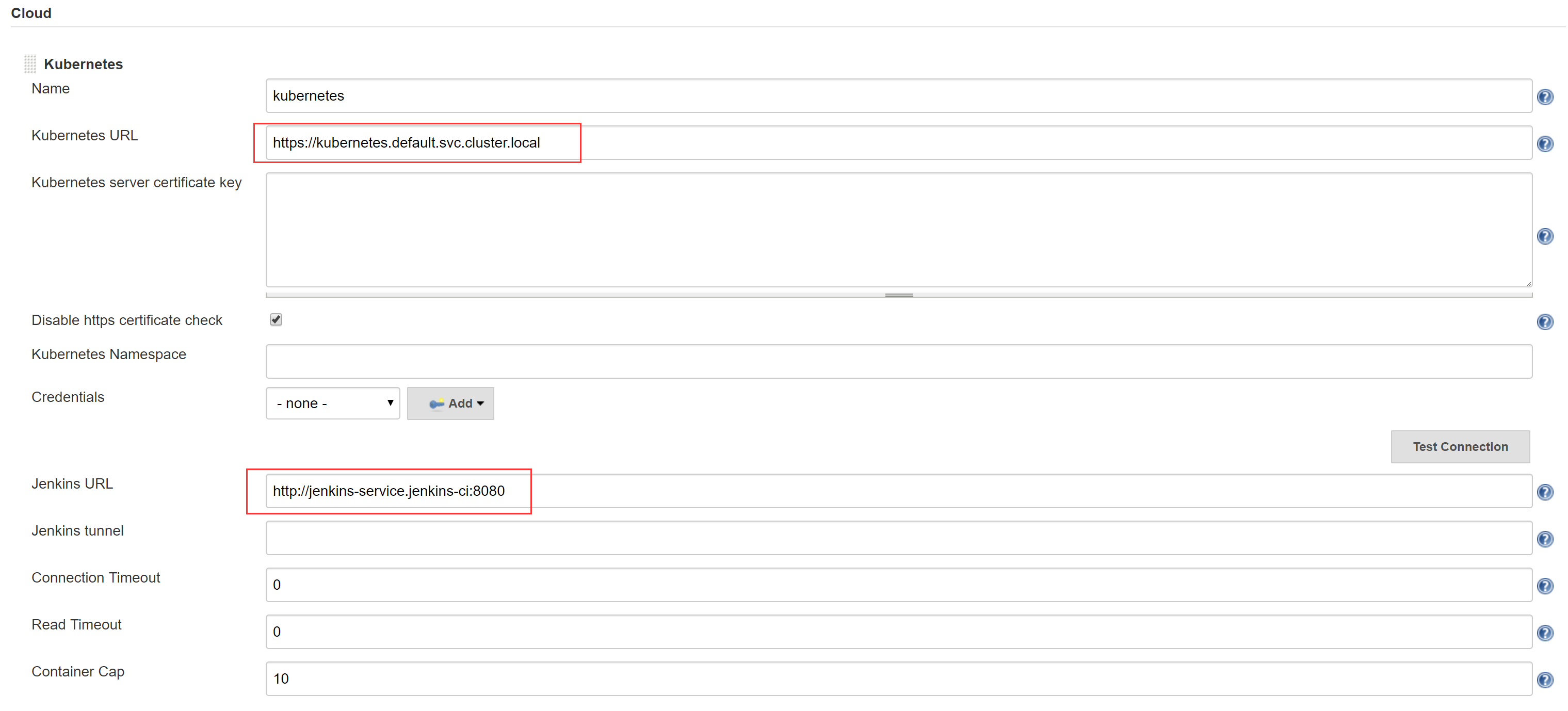
- Test Connection 测试看连接是否成功
- Images – Add Pod Template – Kubernetes Pod Template
- 注意设置Name为”jnlp-agent”,其他按需填写,设置完成后进入Advanced
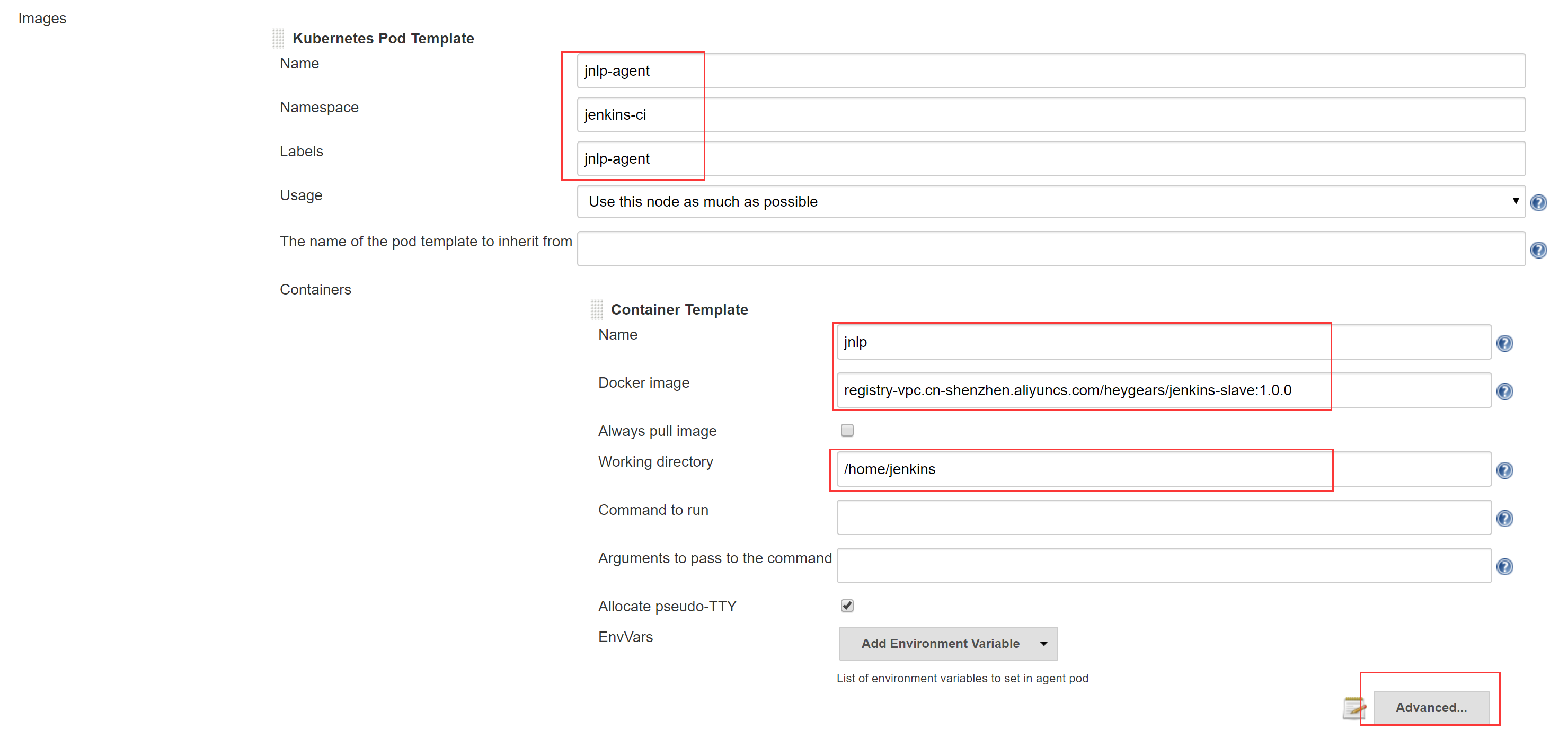
- 根据需要设置资源管理,也就是说限制Jenkins Slave in Pod所占用的CPU和内存,详见第二章
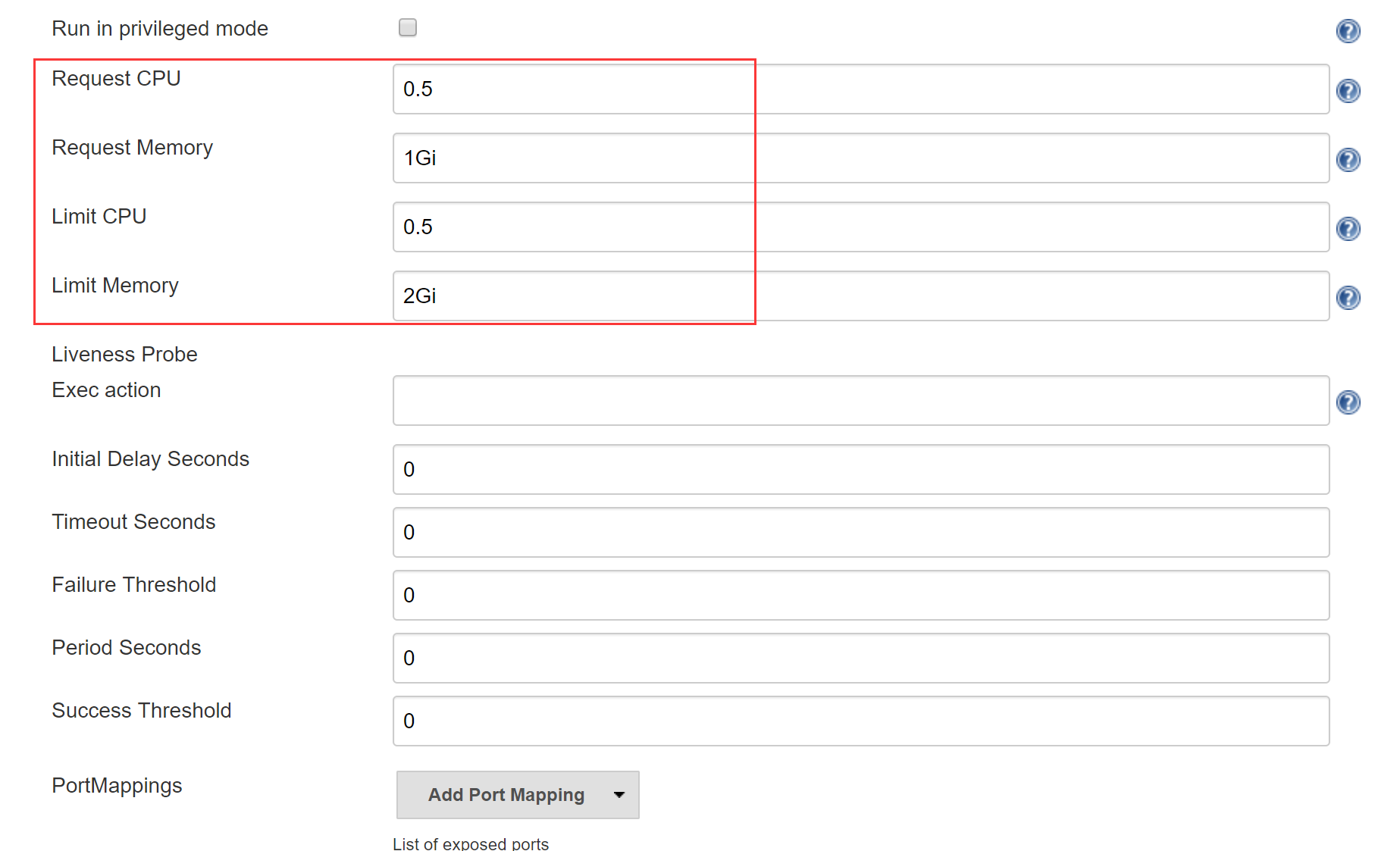
- 设置Volume,同样采用docker outside docker,将K8S Node的docker为Jenkins Slave Pod所用;设置Jenkins Slave的工作目录为NAS
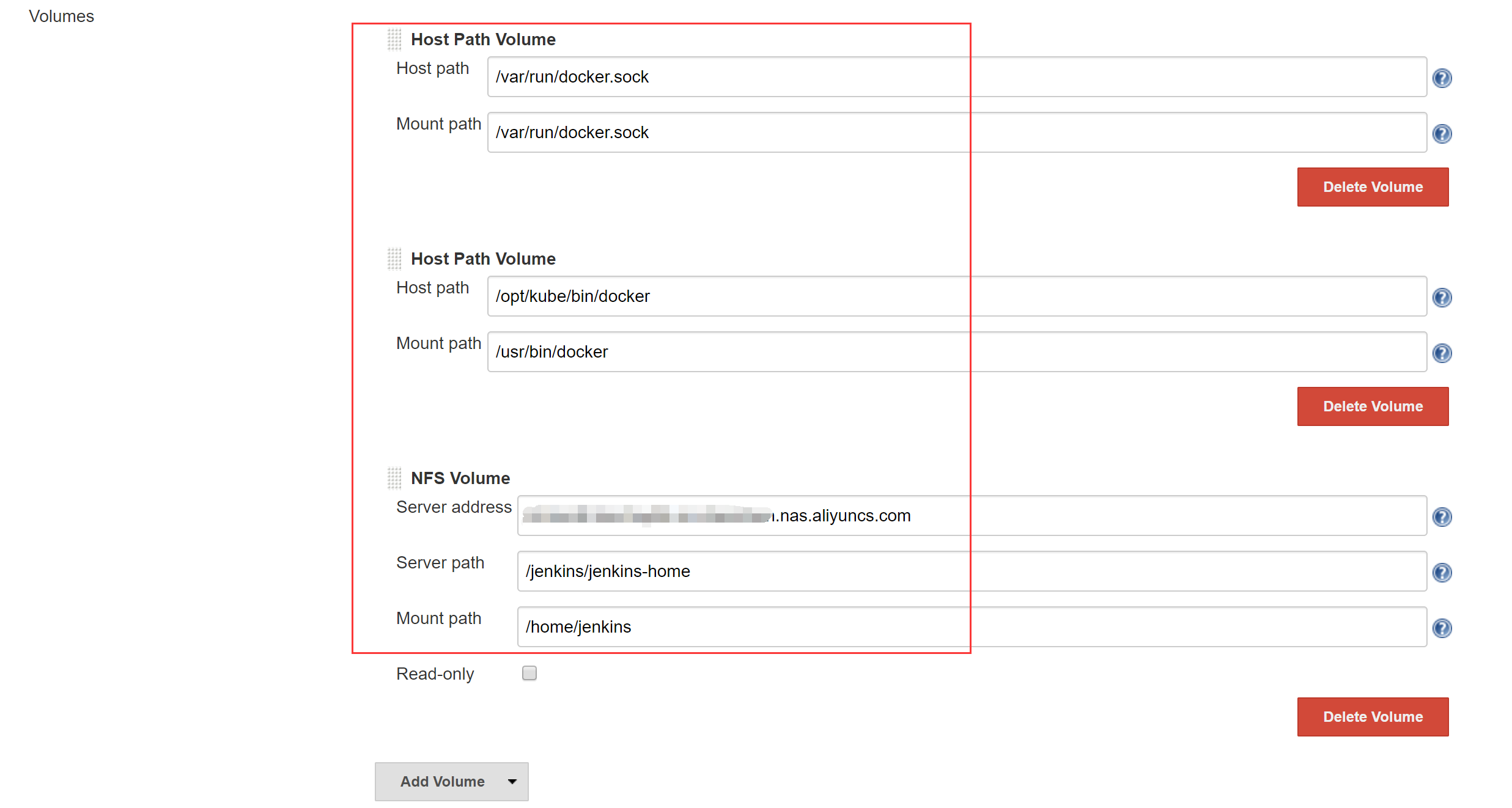
- 设置最多允许多少个Jenkins Slave Pod 同时运行,然后进入Advanced
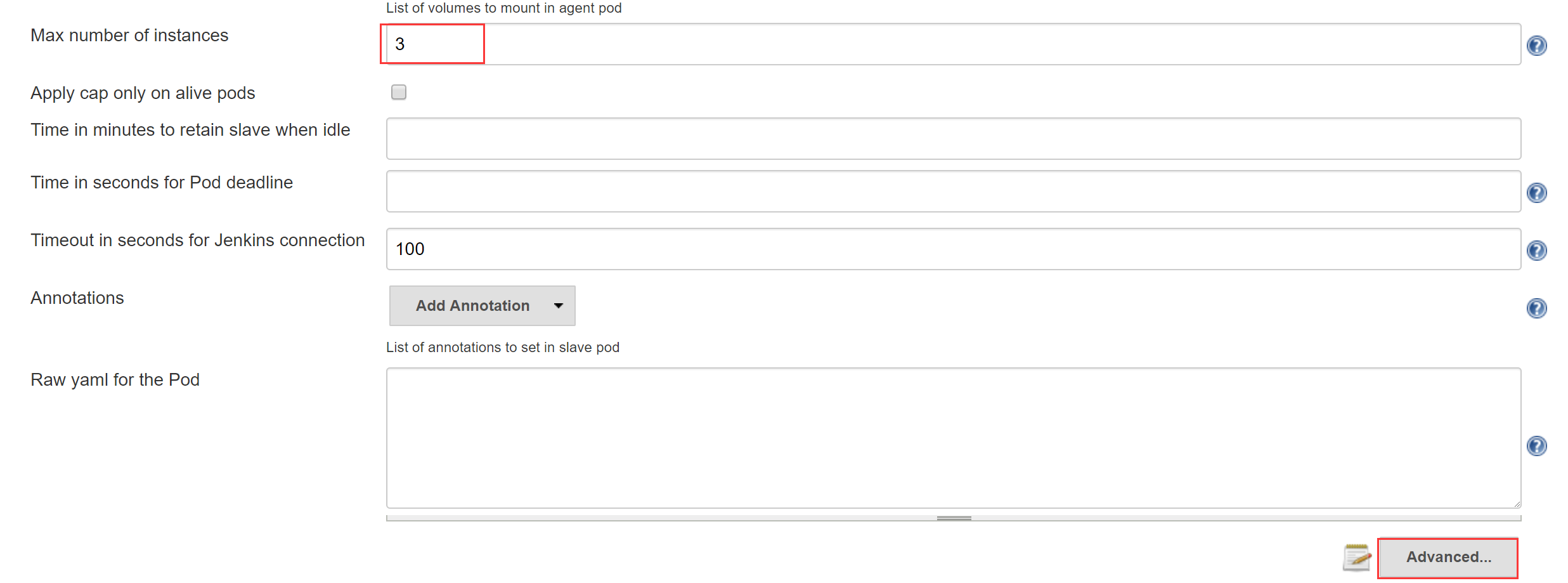
- 填写Service Account,与部署Jenkins Master的yaml文件中的Service Account保持一致;如果你的Jenkins Slave Image是私有镜像,还需要设置ImagePullSecrets

- Apply并完成
1.4 测试验证
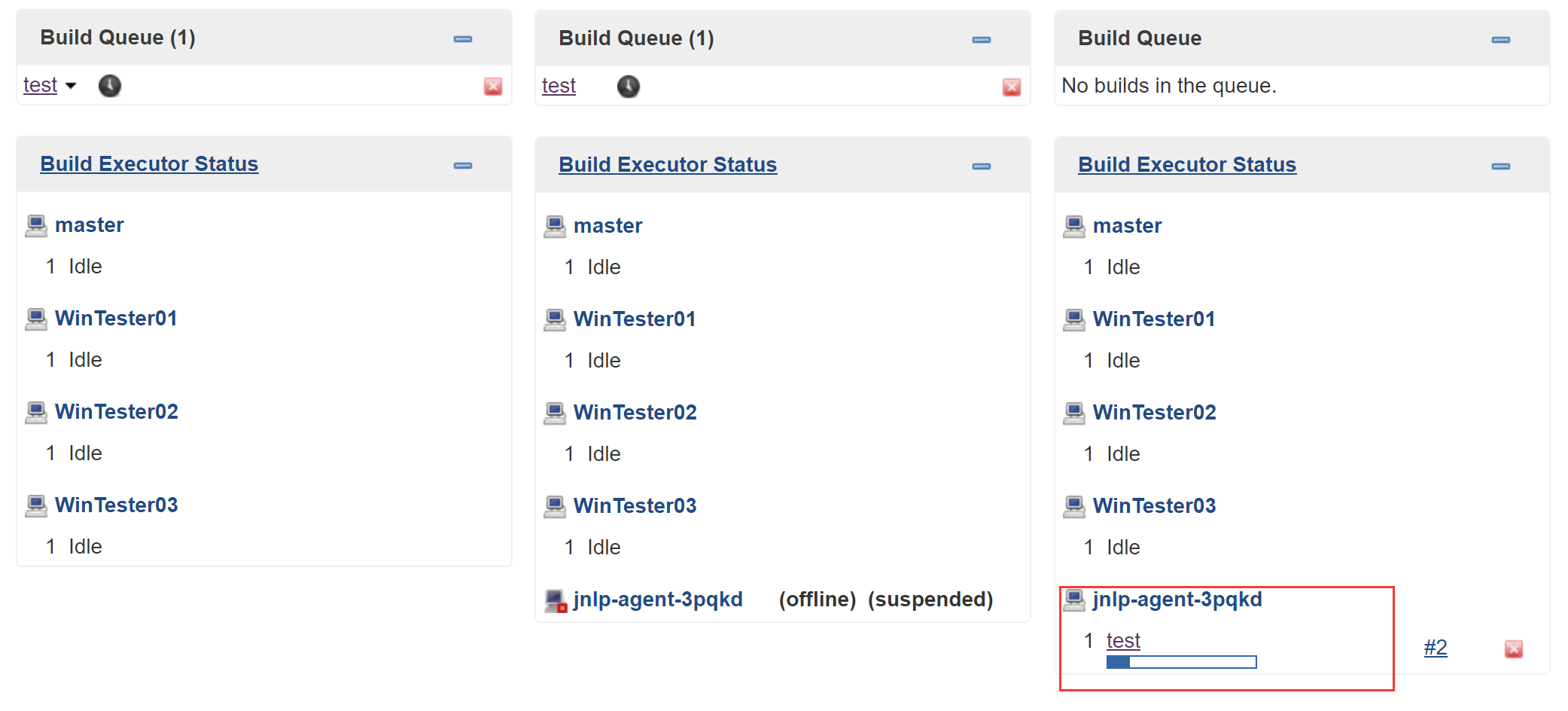
我们可以写一个FreeStyle Project的测试Job:
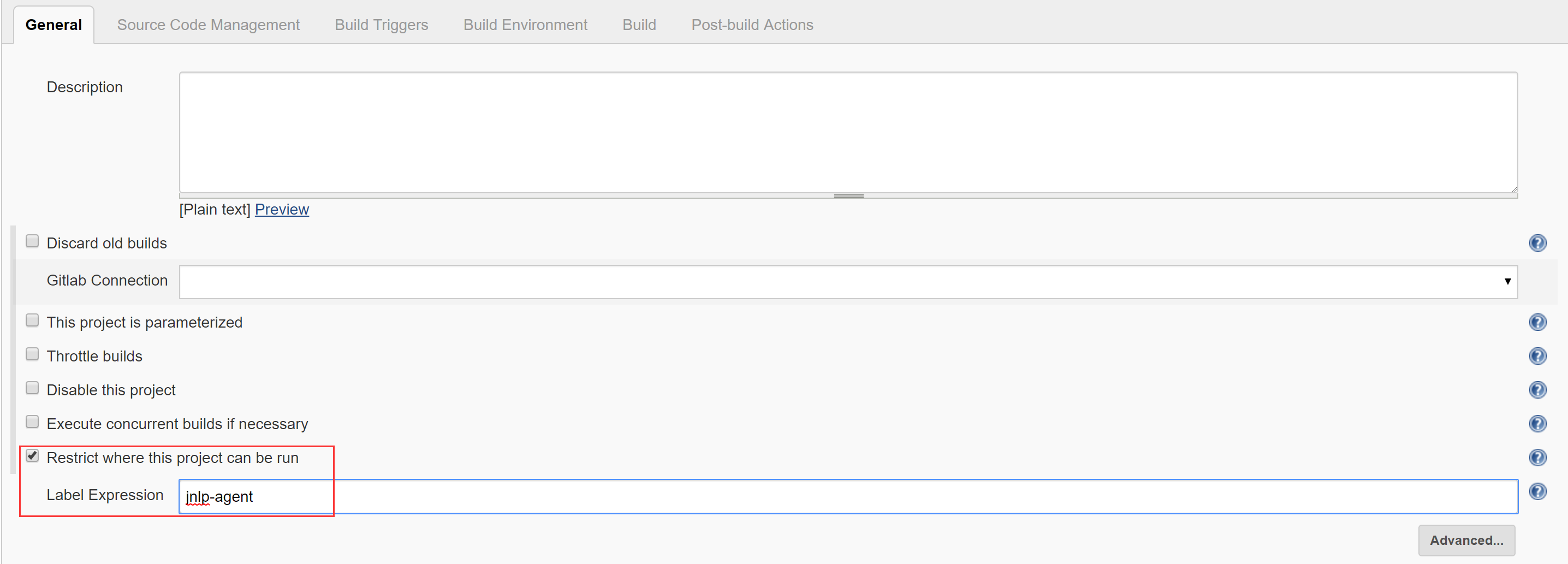
测试运行:
可以看到名为”jnlp-agent-xxxxx”的Jenkins Salve被创建,Job build完成后又消失,即为正确完成配置。

二、K8S资源管理
在第一章中,先后提到两次资源管理,一次是Jenkins Master的yaml,一次是Kubernetes Pod Template给Jenkins Slave 配置。Resource的控制是K8S的基础配置之一。但一般来说,用到最多的就是以下四个:
- Request CPU:意为某Node剩余CPU大于Request CPU,才会将Pod创建到该Node上
- Limit CPU:意为该Pod最多能使用的CPU为Limit CPU
- Request Memory:意为某Node剩余内存大于Request Memory,才会将Pod创建到该Node上
- Limit Memory:意为该Pod最多能使用的内存为Limit Memory
比如在我这个项目中,Gitlab至少需要配置Request Memory为3G,对于Elastic Search的Request Memory也至少为2.5 G.
其他服务需要根据K8S Dashboard中的监控插件结合长时间运行后给出一个合理的Resource控制范围。

三、Harbor
在K8S中跑CI,大致流程是Jenkins将Gitlab代码打包成Image,Push到Docker Registry中,随后Jenkins通过yaml文件部署应用,Pod的Image从Docker Registry中Pull.也就是说到目前为止,我们还缺一个Docker Registry才能准备好所有CI需要的基础软件。
利用阿里云的镜像仓库或者Docker HUB可以节省硬件成本,但考虑数据安全、传输效率和操作易用性,还是希望自建一个Docker Registry. 可选的方案并不多,官方提供的Docker Registry v2轻量简洁,vmware的Harbor功能更丰富。
Harbor提供了一个界面友好的UI,支持镜像同步,这对于DevOps尤为重要。Harbor官方提供了Helm方式在K8S中部署。但我考虑Harbor占用的资源较多,从节省硬件成本来说,把Harbor放到了K8S Master上(Master节点不会被调度用于部署Pod,所以大部分空间资源没有被利用)。当然这不是一个最好的方案,但它是最适合我们目前业务场景的方案。
在Master节点使用docker compose部署Harbor的步骤如下:
- 192.168.0.1安装docker-compose
pip install docker-compose - 192.168.0.1 data目录挂载NAS路径(harbor的volume默认映射到宿主机的/data目录,所以我们把宿主机的/data目录挂载为NAS即可实现用NAS作为harbor的volume)
mkdir /data mount -t nfs -o vers=4.0 xxx.xxx.com:/harbor /data
- 参考https://github.com/vmware/harbor/blob/master/docs/installation_guide.md 安装
- 根据需要下载指定版本的 Harbor offline installer
- 解压后配置harbor.cfg
# 域名 hostname = xx.xx.com # 协议,这里可以使用http可以免去配置ssl_cert,通过SLB暴露至集群外再加上ssh即可 ui_url_protocol = http # 邮箱配置 email_identity = rfc2595 email_server = xx email_server_port = xx email_username = xx email_password = xx email_from = xx email_ssl = xx email_insecure = xx # admin账号默认密码 harbor_admin_password = xx
- 修改docker-compose.yaml中的端口映射,这里将容器端口映射到宿主机的23280端口
proxy imagevmware/nginx-photonv1.5.0 container_namenginx restartalways volumes ./common/config/nginx:/etc/nginx:z networks harbor ports 23280:80 #- 443:443 #- 4443:4443 depends_on mysql registry ui log logging driver"syslog" options syslog-address"tcp://127.0.0.1:1514" tag"proxy"
- 运行install.sh
- 修改 kubeasz的 roles/docker/files/daemon.json加入”insecure-registries”节点,如下所示
{ "registry-mirrors": ["https://kuamavit.mirror.aliyuncs.com", "https://registry.docker-cn.com", "https://docker.mirrors.ustc.edu.cn"], "insecure-registries": ["192.168.0.1:23280"], "max-concurrent-downloads": 10, "log-driver": "json-file", "log-level": "warn", "log-opts": { "max-size": "10m", "max-file": "3" } }
重新安装kubeasz的docker
ansible-playbook 03.docker.yml这样在集群内的任何一个节点就可以通过http协议192.168.0.1:23280 访问harbor
- 开机启动
vi /etc/rc.local # 加入如下内容 # mount -t nfs -o vers=4.0 xxxx.com:/harbor /data # cd /etc/ansible/heygears/harbor # sudo docker-compose up -d chmod +x /etc/rc.local
- 设置Secret(K8S部署应用时使用Secret拉取镜像,详见系列教程第三篇)在K8S集群任意一台机器使用命令
kubectl create secret docker-registry regcred --docker-server=192.168.0.1:23280 --docker-username=xxx --docker-password=xxx --docker-email=xxx - 设置SLB(如果仅在内网使用,不设置SLB和DNS也可以)
- 登陆Harbor管理页面
- 在集群内通过
docker login 192.168.0.1:23280验证Harbor是否创建成功
四、EFK
最后我们来给集群加上日志系统。
项目中常用的日志系统多数是Elastic家族的ELK,外加Redis或者Kafka作为缓冲队列。由于Logstash需要运行在java环境下,且占用空间大,配置相对复杂,随着Elastic家族的产品逐渐丰富,Logstash开始慢慢偏向日志解析、过滤、格式化等方面,所以并不太适合在容器环境下的日志收集。K8S官方给出的方案是EFK,其中F指的是Fluentd,一个用Ruby写的轻量级日志收集工具。对比Logstash来说,支持的插件少一些。
容器日志的收集方式不外乎以下四种:
- 容器外收集。将宿主机的目录挂载为容器的日志目录,然后在宿主机上收集。
- 容器内收集。在容器内运行一个后台日志收集服务。
- 单独运行日志容器。单独运行一个容器提供共享日志卷,在日志容器中收集日志。
- 网络收集。容器内应用将日志直接发送到日志中心,比如java程序可以使用log4j2转换日志格式并发送到远端。
- 通过修改docker的–log-driver。可以利用不同的driver把日志输出到不同地方,将log-driver设置为syslog、fluentd、splunk等日志收集服务,然后发送到远端。
docker默认的driver是json-driver,容器输出到控制台的日志,都会以 *-json.log 的命名方式保存在 /var/lib/docker/containers/ 目录下。所以EFK的日志策略就是在每个Node部署一个Fluentd,读取/var/lib/docker/containers/ 目录下的所有日志,传输到ES中。这样做有两个弊端,一方面不是所有的服务都会把log输出到控制台;另一方面不是所有的容器都需要收集日志。我们更想定制化的去实现一个轻量级的日志收集。所以综合各个方案,还是采取了网上推荐的以FileBeat作为日志收集的“EFK”架构方案。
FileBeat用Golang编写,输出为二进制文件,不存在依赖。占用空间极小,吞吐率高。但它的功能相对单一,仅仅用来做日志收集。所以对于有需要的业务场景,可以用FileBeat收集日志,Logstash格式解析,ES存储,Kibana展示。
使用FileBeat收集容器日志的业务逻辑如下:
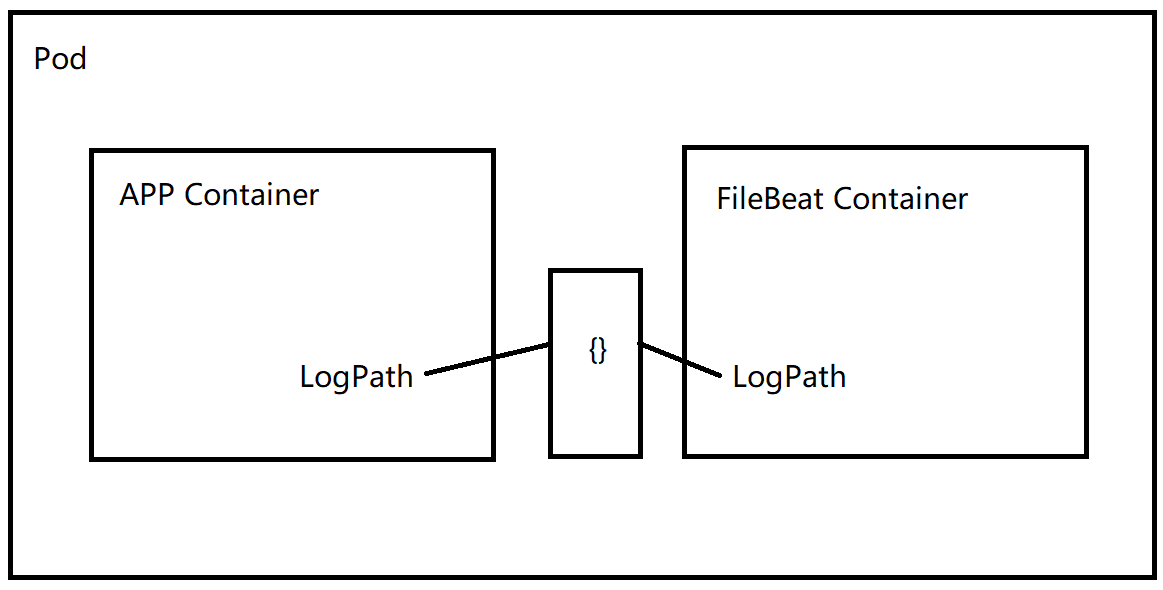
也就是说我们利用K8S的Pod的临时目录{}来实现Container的数据共享,举个例子:
apiVersionextensions/v1beta1 kindDeployment metadata nametest labels apptest spec replicas2 strategy typeRecreate template metadata labels apptest spec containers image#appImage nameapp volumeMounts namelog-volume mountPath/var/log/app/ #app log path image#filebeatImage namefilebeat args "-c" "/etc/filebeat.yml" securityContext runAsUser0 volumeMounts nameconfig mountPath/etc/filebeat.yml readOnlytrue subPathfilebeat.yml namelog-volume mountPath/var/log/container/ volumes nameconfig configMap defaultMode0600 namefilebeat-config namelog-volume emptyDir #利用{}实现数据交互 imagePullSecrets nameregcred --- apiVersionv1 kindConfigMap metadata namefilebeat-config namespacetest labels appfilebeat data filebeat.yml- filebeat.inputs typelog enabledtrue paths /var/log/container/*.log #FileBeat读取log的源 output.elasticsearch hosts"xx.xx.xx:9200" tags"test" #log tag
实现这种FileBeat作为日志收集的“EFK”系统,只需要在K8S集群中搭建好ES和Kibana即可,FileBeat是随着应用一起创建,无需提前部署。搭建ES和Kibana的方式可参考K8S官方文档,我也进行了一个简单整合:
ES:
# RBAC authn and authz apiVersionv1 kindServiceAccount metadata nameelasticsearch-logging namespacekube-system labels k8s-appelasticsearch-logging kubernetes.io/cluster-service"true" addonmanager.kubernetes.io/modeReconcile --- kindClusterRole apiVersionrbac.authorization.k8s.io/v1 metadata nameelasticsearch-logging labels k8s-appelasticsearch-logging kubernetes.io/cluster-service"true" addonmanager.kubernetes.io/modeReconcile rules apiGroups "" resources "services" "namespaces" "endpoints" verbs "get" --- kindClusterRoleBinding apiVersionrbac.authorization.k8s.io/v1 metadata namespacekube-system nameelasticsearch-logging labels k8s-appelasticsearch-logging kubernetes.io/cluster-service"true" addonmanager.kubernetes.io/modeReconcile subjects kindServiceAccount nameelasticsearch-logging namespacekube-system apiGroup"" roleRef kindClusterRole nameelasticsearch-logging apiGroup"" --- apiVersionv1 kindPersistentVolume metadata namees-pv-0 labels releasees-pv namespacekube-system spec capacity storage20Gi accessModes ReadWriteMany volumeModeFilesystem persistentVolumeReclaimPolicyRecycle storageClassName"es-storage-class" nfs path/es/0 serverxxx.nas.aliyuncs.com # 用NAS来作为ES的数据存储,需要提前在NAS创建目录/es/0 --- apiVersionv1 kindPersistentVolume metadata namees-pv-1 labels releasees-pv namespacekube-system spec capacity storage20Gi accessModes ReadWriteMany volumeModeFilesystem persistentVolumeReclaimPolicyRecycle storageClassName"es-storage-class" nfs path/es/1 serverxxx.nas.aliyuncs.com # 用NAS来作为ES的数据存储,需要提前在NAS创建目录/es/1 --- # Elasticsearch deployment itself apiVersionapps/v1 kindStatefulSet metadata nameelasticsearch-logging namespacekube-system labels k8s-appelasticsearch-logging versionv5.6.4 kubernetes.io/cluster-service"true" addonmanager.kubernetes.io/modeReconcile spec serviceNameelasticsearch-logging replicas2 selector matchLabels k8s-appelasticsearch-logging versionv5.6.4 template metadata labels k8s-appelasticsearch-logging versionv5.6.4 kubernetes.io/cluster-service"true" spec serviceAccountNameelasticsearch-logging containers imageregistry-vpc.cn-shenzhen.aliyuncs.com/heygears/elasticsearch5.6.4 # 可替换成私有仓库 nameelasticsearch-logging resources # need more cpu upon initialization, therefore burstable class limits cpu1 memory2.5Gi requests cpu0.8 memory2Gi ports containerPort9200 namedb protocolTCP containerPort9300 nametransport protocolTCP volumeMounts nameelasticsearch-logging mountPath/data env name"NAMESPACE" valueFrom fieldRef fieldPathmetadata.namespace # Elasticsearch requires vm.max_map_count to be at least 262144. # If your OS already sets up this number to a higher value, feel free # to remove this init container. initContainers imagealpine3.6 command"/sbin/sysctl" "-w" "vm.max_map_count=262144" nameelasticsearch-logging-init securityContext privilegedtrue volumeClaimTemplates metadata nameelasticsearch-logging spec accessModes "ReadWriteMany" storageClassName"es-storage-class" resources requests storage20Gi --- apiVersionv1 kindService metadata nameelasticsearch-logging namespacekube-system labels k8s-appelasticsearch-logging kubernetes.io/cluster-service"true" addonmanager.kubernetes.io/modeReconcile kubernetes.io/name"Elasticsearch" spec typeNodePort ports port9200 protocolTCP targetPortdb nodePortxxx # 以NodePort方式暴露端口,供集群外访问ES selector k8s-appelasticsearch-logging
Kibana:
apiVersionapps/v1 kindDeployment metadata namekibana-logging namespacekube-system labels k8s-appkibana-logging kubernetes.io/cluster-service"true" addonmanager.kubernetes.io/modeReconcile spec replicas1 selector matchLabels k8s-appkibana-logging template metadata labels k8s-appkibana-logging spec containers namekibana-logging imageregistry-vpc.cn-shenzhen.aliyuncs.com/heygears/kibana5.6.4 # 也可替换成自己的私有仓库 resources # need more cpu upon initialization, therefore burstable class limits cpu1 memory1.5Gi requests cpu0.8 memory1.5Gi env nameELASTICSEARCH_URL valuehttp//elasticsearch-logging9200 nameSERVER_BASEPATH value/api/v1/namespaces/kube-system/services/kibana-logging/proxy nameXPACK_MONITORING_ENABLED value"false" nameXPACK_SECURITY_ENABLED value"false" ports containerPort5601 nameui protocolTCP --- apiVersionv1 kindService metadata namekibana-logging namespacekube-system labels k8s-appkibana-logging kubernetes.io/cluster-service"true" addonmanager.kubernetes.io/modeReconcile kubernetes.io/name"Kibana" spec ports port5601 protocolTCP targetPortui selector k8s-appkibana-logging
本文转自中文社区-阿里云Kubernetes实战2–搭建基础服务
