介绍
索引用于加快数据访问的速度。把计算机的磁盘比作一本字典,索引就是字段的目录,当我们想快速查到某个词语的时候只需要通过查询目录找到词语所在的页数,然后直接打开某页就可以。MySQL最常用的索引是B+树索引,为什么使用B+作为MySQL的索引,这是许多面试官必问的问题。
为什么B+树
硬件相关知识
计算机的磁盘是一个圆盘的接口,圆盘上有一个个的圆圈,数据就是记录在这些圆圈的扇区上。如下图所示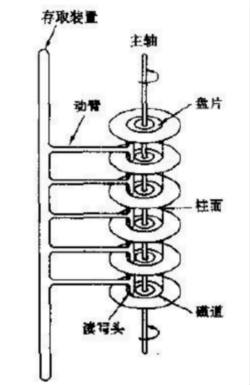
当计算机系统读取数据的时候要通过以下几个步骤:
1、首先移动臂根据柱面号使磁头移动到所需要的柱面上,这一过程被称为寻道。所耗费的时间叫寻道时间(ts)。
2、目标扇区旋转到磁头下,这个过程耗费的时间叫旋转时间。
因此访问磁盘的时间由三部分构成: 寻道时间+旋转时间+数据传输时间
第一部分寻道时间延迟最高,最大可达到100ms,旋转时间取决于磁盘的转速,转速在7200转/分钟的磁盘平均旋转时间在5ms左右。磁盘的读取是以block(盘块)为单位的,位于同一个盘块的数据可以一次性读取出来。在读写数据的时候尽量减少磁头来回移动的次数,避免过多的查找时间。如果每次从磁盘上读取数据的时候都要经历上面的几个过程那么效率上无疑是极低的。
为什么B+树
从上面可以看到,如果随机访问磁盘的速度是很慢的,因此需要设计一个合理的数据结构来减少随机访问磁盘的次数。B树就是这样一种数据结构。
B树、B+树介绍
B树
B树是为存储设备而设计的一种多叉平衡查找树。它与红黑树类似,但是在降低IO操作方面B树的表现要更好一些,B树与红黑树最大的区别在于B树可以有多个子节点,红黑树最多是有两个子节点,这就决定了大多数情况下B树的高度要比红黑树低很多,因此在查找的时候能够降低IO次数。下图是一棵B树: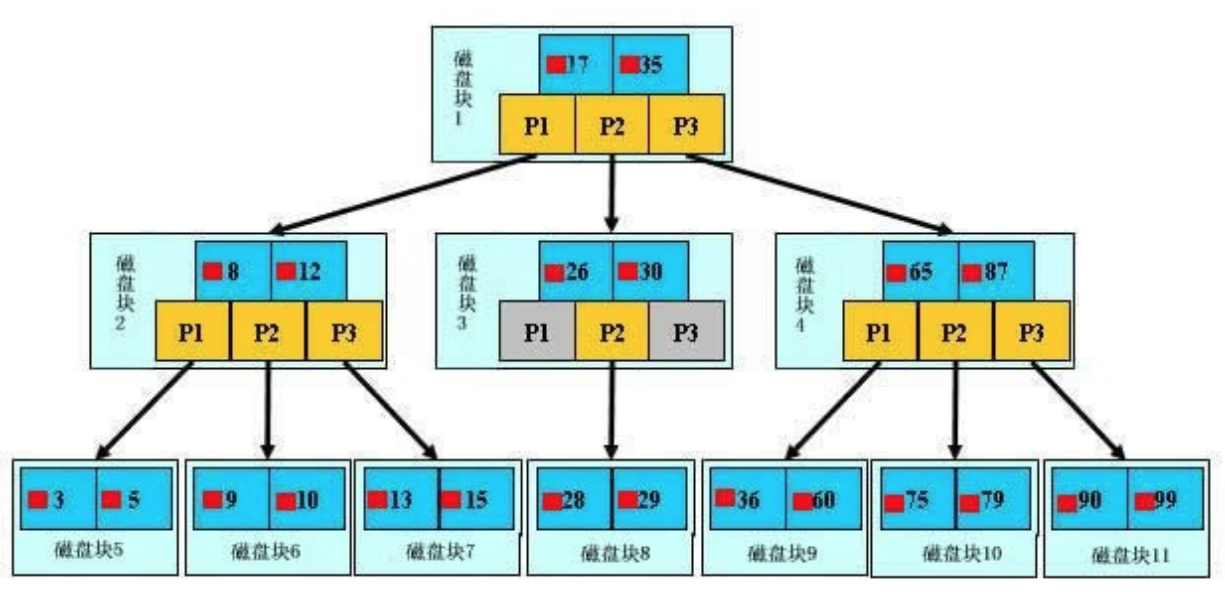
B 树又叫平衡多路查找树。一棵m阶的B树的特性如下:
a.树中每个结点最多含有m个孩子(m>=2);
b.除根结点和叶子结点外,其它每个结点至少有[ceil(m / 2)]个孩子(其中ceil(x)是一个取上限的函数);
c.若根结点不是叶子结点,则至少有2个孩子(特殊情况:没有孩子的根结点,即根结点为叶子结点,整棵树只有一个根节点);
d.所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息
e.每个非终端结点中包含有n个关键字信息: (n,P0,K1,P1,K2,P2,......,Kn,Pn)。其中:
a) Ki (i=1…n)为关键字,且关键字按顺序升序排序K(i-1)< Ki。
b) Pi为指向子树根的接点,且指针P(i-1)指向子树种所有结点的关键字均小于Ki,但都大于K(i-1)。
c) 关键字的个数n必须满足: [ceil(m / 2)-1]<= n <= m-1。
B树中的每个节点都尽可能存储多的关键字信息和分支信息,但是不会超过磁盘块的大小。这样在有效降低了树的高度,在查找的时候可以快速定位在指定的磁盘块。假如要从上图中找到79这个数字,首先从根节点开始扫描,79大于35所以选择P3指针,指向磁盘块4,在磁盘块4中79在65和87之间,因此选择P2指针,选择磁盘块10,这时候就可以从磁盘块10中找到79。整个过程只需要3次IO,如果这棵树被缓存在内存中,那么只需要一次IO就可以读到79这个数字。
B+树
B+树是B的变种,一颗m阶B+树和m阶B树的异同点在于:
1、有n棵子树的节点中有n-1个关键字(与B树n棵子树有n-1个关键字,保持一致)
2、所有的叶子节点中包含了全部的关键字的信息,以及指向含有这些关键字记录的指针,且叶子节点本身依关键字的大小而自小而大顺序链接(而B树的叶子节点并没有包含全部需要查找的信息)
3、所有的非终端节点可以看成索引部分,节点中仅含有其子树根节点中最大或者最小的关键字(而B树的非终节点也要包含需要查找的有效信息)
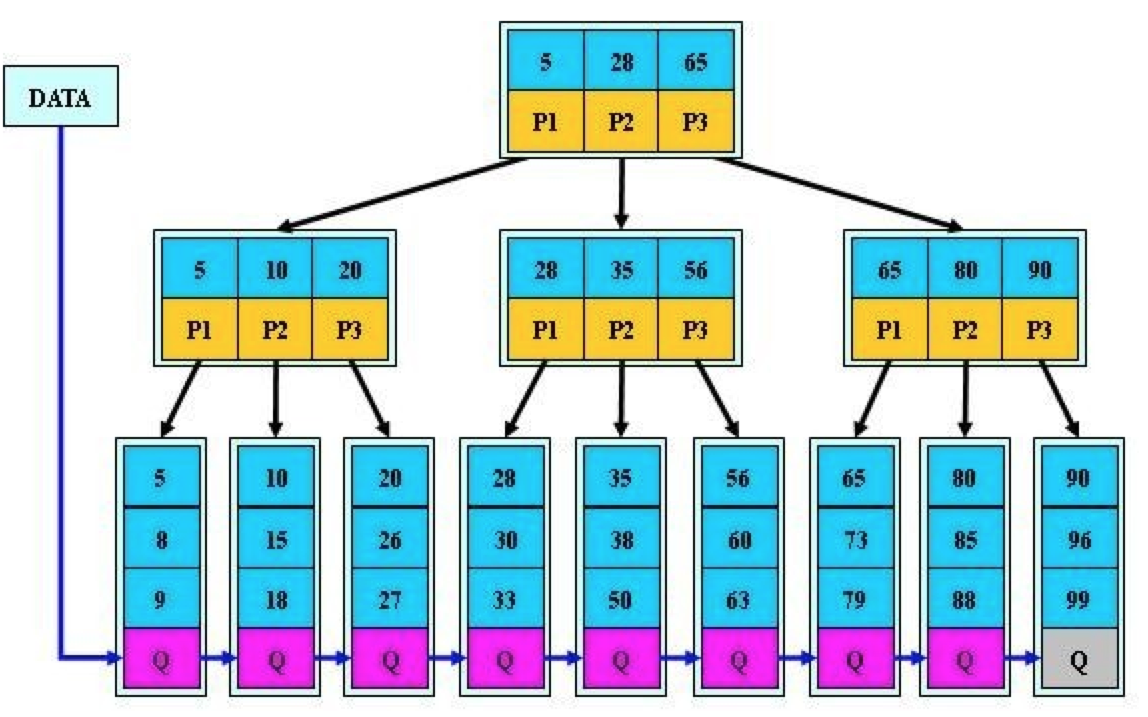
由于B+树的叶子节点是连接在一起的,因此相对于使用B树作为索引,对于MySQL的范围查询更加优化。同时由于叶子节点包含所有关键字信息,因此有的查询语句就不需要回表,只需要查询索引就可以查到需要的数据。
索引类型
B树索引
虽然是叫B树索引,但是数据库实际上使用的是B+树来组织数据。B树索引意味着所有值都是按照顺序存储的,并且每个叶子节点到根节点的距离是相同的。
假如有如下数据表:
CREATE TABLE `people` (
`last_name` varchar(50) DEFAULT NULL,
`first_name` varchar(50) DEFAULT NULL,
`dob` date DEFAULT NULL,
`gender` enum('m','f') DEFAULT NULL,
KEY `last_name` (`last_name`,`first_name`,`dob`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
该表对last_name,first_name,dob三列建立了索引,索引的组织方式如下: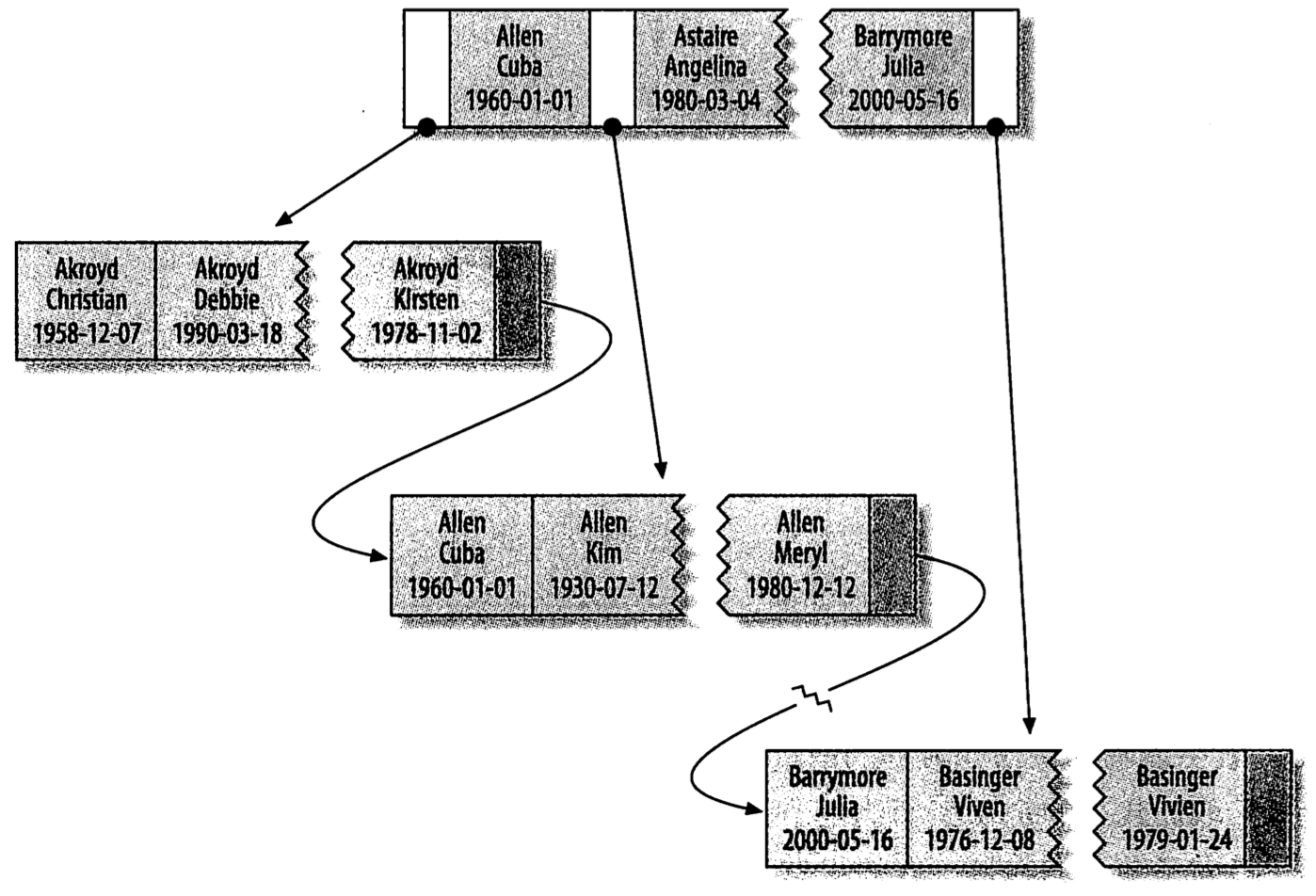
当同时对多列进行索引的时候,索引的顺序是非常重要的,上面的索引首先是按照last_name进行索引,在last_name相同的情况下在对first_name进行排序,最后是dob字段。
B树索引适用于全键值、键值范围和最左前缀查找:
全键值
查找名字为Allen Kim,出生日期为1930-07-12的人,这样的查找方式匹配了索引中的所有字段,依次扫描索引中的last_name、first_name和dob字段,找到对应的数据。
键值范围
查找姓名在Allen和Barrymore之间的人,这种查找方式也会使用到索引。需要注意的是这里只能是索引中的第一列,也就是last_name的范围查找。
前缀匹配
查找last_name是以Al开头的人,这种查询会以此扫描索引中的节点,然后选出来对应的复合条件的行。也是只能使用第一列的前缀查询。如果是说想查first_name的前缀匹配,那么是无法使用到索引的,意味着要进行全表扫描。
精确匹配某一列,范围批量另外一列
精确匹配的列必须是所以中的第一列,范围匹配的列是第二列,这样才能使用到上面的索引。
B树索引的使用限制:
1、不是按照最左列开始查询的,无法使用索引。
2、不能跳过索引的列进行查询。
3、如果使用到了范围匹配,那么范围匹配右边的列都无法使用索引查询。
哈希索引
哈希索引使用哈希表来实现,只有是精确匹配的时候才会生效。存储引擎会对索引列计算出一个哈希值,然后保存一个哈希值到行数据的指针。哈希索引由于其特殊的组织方式,限制了其使用场景。哈希索引只适合值比较少的情况,例如枚举类型。在以下几种方式中是不适合使用哈希索引的:
1、哈希索引只包含哈希值和指针,不存储字段值,因此使用哈希索引避免不了要进行回表查询。
2、哈希索引数据并不是按照值的顺序进行排序的,因此哈希索引无法用来排序
3、哈希索引不支持部分索引列匹配。比如说在(A,B)两列上简历哈希索引,那么只有在同时使用A、B两列查询的时候才会使用哈希索引,只使用A列查询无法使用哈希索引。
4、哈希索引只支持等值比较,不支持像between and这种范围查询。
5、使用哈希索引的时候应该尽量避免哈希冲突。
后记
数据库的索引机制解决的问题是在访问内存数据与磁盘数据的速度差别很大的情况下,如何快速访问数据的问题。只有了解了索引的原理才可以更好的设计表的索引字段以及写出性能更优的查询语句。在我们写SQL语句的时候头脑中应该大体上能规划出查询数据以及如何使用索引的过程。下一篇会介绍一下高性能索引的策略,带你设计出更优的索引。
----------------------------------------------------------------
欢迎关注我的微信公众号:yunxi-talk,分享Java干货,进阶Java程序员必备。

![]()





