因为有Scikit-Learn这样的库,现在用Python实现任何机器学习算法都非常容易。实际上,我们现在不需要任何潜在的知识来了解模型如何工作。虽然不需要了解所有细节,但了解模型如何训练和预测对工作仍有帮助。比如:如果性能不如预期,我们可以诊断模型或当我们想要说服其他人使用我们的模型时,我们可以向他们解释模型如何做出决策的。
在本文中,我们将介绍如何在Python中构建和使用Random Forest,而不是仅仅显示代码,我将尝试了解模型的工作原理。我将从一个简单的单一决策树开始,然后以解决现实世界数据科学问题的方式完成随机森林。本文的完整代码在GitHub上以Jupyter Notebook的形式提供。
理解决策树
决策树是随机森林的构建块,它本身就是个直观的模型。我们可以将决策树视为询问有关我们数据问题的流程图。这是一个可解释的模型,因为它决定了我们在现实生活中的做法:在最终得出决定之前,我们会询问有关数据的一系列问题。
决策树的主要技术细节是如何构建有关数据的问题,决策树是通过形成能够最大限度减少基尼系数的问题而建立的。稍后我会讨论Gini Impurity,但这意味着决策树试图形成尽可能纯的节点,其中包含来自单个类的高比例样本(数据点)的节点。
Gini Impurity和构建树可能有点难以理解,所以首先让我们构建一个决策树,以便可以更好的理解它。
关于最简单问题的决策树
我们从一个非常简单的二进制分类问题开始,如下所示:
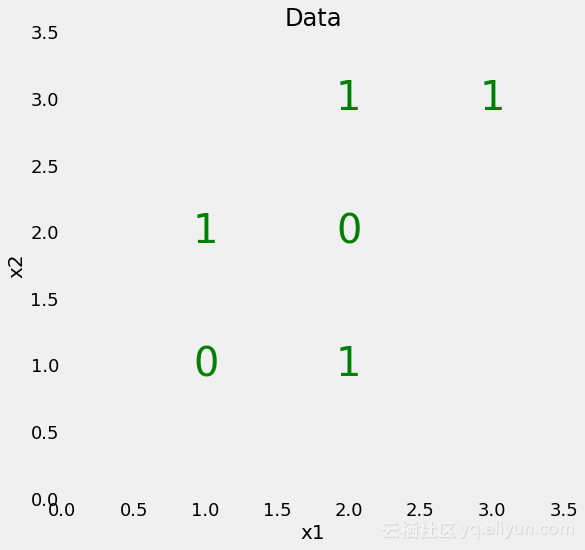
我们的数据只有两个特征(标签),且只有6个数据点。
虽然这个问题很简单,但它不是线性可分的,这意味着我们不能通过数据绘制一条直线来对点进行分类。然而,我们可以绘制一系列划分类的直线,这基本上是决策树在形成一系列问题时将要做的事情。
要创建决策树并在数据上训练,我们可以使用Scikit-Learn:
from sklearn.tree import DecisionTreeClassifier
# Make a decision tree and train
tree = DecisionTreeClassifier(random_state=RSEED)
tree.fit(X, y) 在训练过程中,我们为模型提供特征和标签,以便学习根据特征对点进行分类。我们没有针对这个简单问题的测试集,但是在测试时,我们只给模型提供功能并让它对标签做出预测。
我们可以在训练数据上测试我们模型的准确性:
print(f'Model Accuracy: {tree.score(X, y)}')
Model Accuracy: 1.0我们看到它100%正确,这是我们所期望的,因为我们给了它训练的答案。
可视化决策树
当我们训练决策树时,实际上会发生什么?我发现了解决策树的最有用的方法是通过可视化,我们可以使用Scikit-Learn的功能(详细信息请查看笔记本或本文)。
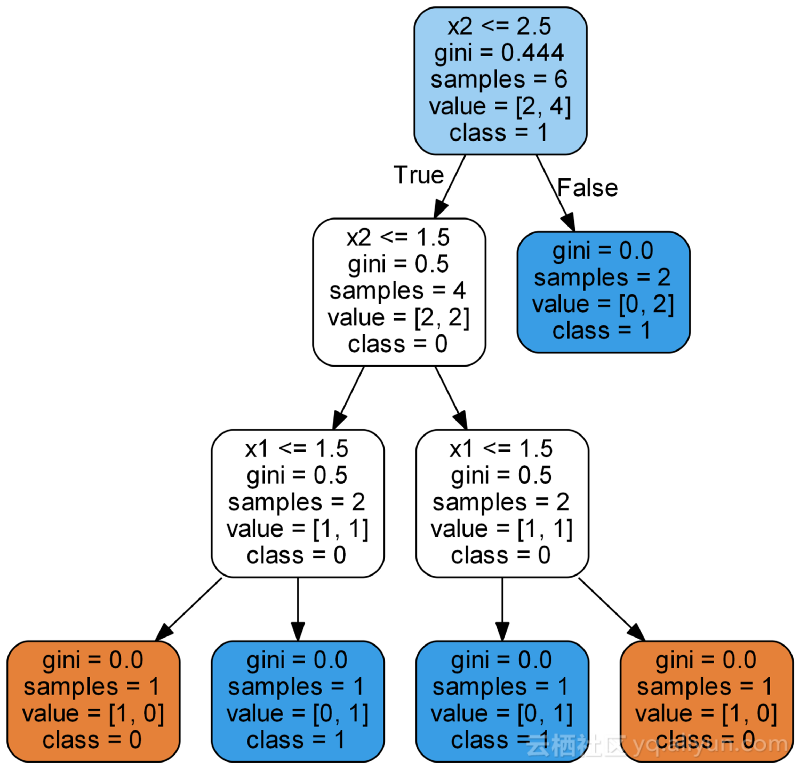
上图显示了决策树的整个结构,除叶节点(终端节点)外,所有节点都有5个部分:
- 问题基于特征值询问数据:每个问题都有对或错的答案。根据问题的答案,数据点在树中移动。
- Gini:节点的Gini杂质。当我们向下移动树时,平均加权基尼系数必须减少。
- samples:节点中的观察数。
- value:每个类的样本数量。例如,顶部节点在类0中有2个样本,在类1中有4个样本。
- class:节点中点的多数分类。在叶节点的情况下,这是对节点中所有样本的预测。
叶节点没有问题,因为这些是最终预测的地方。要对新节点进行分类,只需向下移动树,使用点的特征来回答问题,直到到达class预测的叶节点。你可以使用上面的点进行尝试,或者进行不同的预测。
基尼系数
在这一点上,我们应该尝试了解基尼系数。简而言之,Gini Impurity是随机选择的样本被节点中的样本分布标记错误的概率。例如,在顶部(根)节点中,有44.4%错误的可能性根据节点中样本标签的分布对随机选择的数据点进行分类。我们可以使用下面这个等式得到这个值:
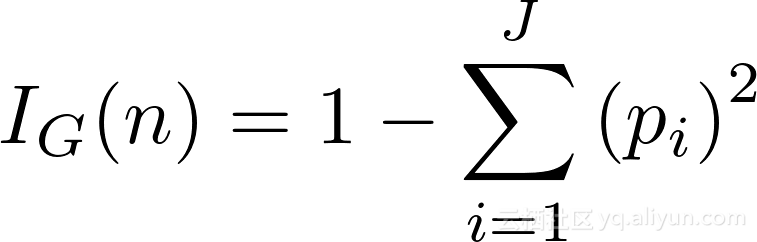
节点的Gini系数n是1减去每个J类的p_i平方的总和,让我们计算出根节点的基尼系数。
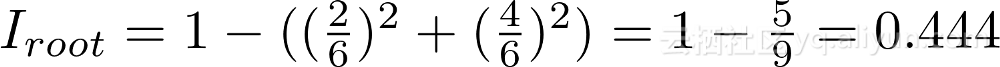
在每个节点处,决策树在要素中搜索要拆分的值,从而最大限度地减少基尼系数。(拆分节点的替代方法是使用信息增益)。
然后,它以递归过程重复此拆分过程,直到达到最大深度,或者每个节点仅包含来自一个类的样本。每层树的加权总基尼系数必须减少。在树的第二层,总加权基尼系数值为0.333:
![]()
最后一层的加权总Gini系数变为0意味着每个节点都是纯粹的,并且从该节点随机选择的点不会被错误分类。虽然这似乎是好结果,但这意味着模型可能过度拟合,因为节点仅使用是通过训练数据构建的。
过度拟合:为什么森林比一棵树更好
你可能会想问为什么不只使用一个决策树?它似乎是完美的分类器,因为它没有犯任何错误!记住这其中的关键点是树在训练数据上没有犯错。因为我们给树提供了答案。机器学习模型的要点是很好地概括测试数据。不幸的是,当我们不限制决策树的深度时,它往往会过度拟合。
当我们的模型具有高方差并且基本上记忆训练数据时,一定会发生过度拟合。这意味着它可以很好地在训练数据上,但由于测试数据不同,它将无法对测试数据做出准确的预测!我们想要的是一个能很好地学习训练数据的模型,并且可以在其他数据集上发挥作用。当我们不限制最大深度时,决策树容易过度拟合的原因是因为它具有无限的复杂性,这意味着它可以保持增长,直到它为每个单独的观察只有一个叶节点,完美地对所有这些进行分类。
要理解为什么决策树具有高差异,我们可以用一个人来考虑它。想象一下,你觉得明天苹果股票会上涨,你会问一些分析师。每一位分析师都可能会有很大差异并且会严重依赖他们可以访问的数据。一位分析师可能只阅读亲苹果新闻,因此她认为价格会上涨,而另一位分析师最近从她的朋友那里听到苹果产品的质量开始下降,她可能就认为价格会下降。这些个体分析师的差异很大,因为他们的答案极其依赖于他们所看到的数据。
因为每个分析师都可以访问不同的数据,所以预计个体差异会很大,但整个集合的总体方差应该减少。使用许多个体本质上是随机森林背后的想法:而不是一个决策树,使用数百或数千个树来形成一个强大的模型。(过度拟合的问题被称为偏差-方差权衡,它是机器学习中的一个基本主题)。
随机森林
随机森林是许多决策树组成的模型。这个模型不仅仅是一个森林,而且它还是随机的,因为有两个概念:
- 随机抽样的数据点;
- 基于要素子集拆分的节点;
随机抽样
随机森林背后的关键是每棵树在数据点的随机样本上训练。样本用替换(称为bootstrapping)绘制,这意味着一些样本将在一个树中多次训练。这个想法是通过对不同样本的每棵树进行训练,尽管每棵树相对于一组特定的训练数据可能有很大的差异,但总体而言,整个森林的方差都很小。每个学习者在数据的不同子集上学习,然后进行平均的过程被称为bagging,简称bootstrap aggregating。
用于拆分节点的随机特征子集
随机森林背后的另一个关键点是,只考虑所有特征的子集来分割每个决策树中的每个节点。通常,这被设置为sqrt(n_features)意味着在每个节点处,决策树考虑在特征的样本上分割总计特征总数的平方根。考虑到每个节点的所有特征,也可以训练随机森林。
如果你掌握单个决策树、bagging决策树和随机特征子集,那么你就可以很好地理解随机森林的工作原理。随机森林结合了数百或数千个决策树,在略微不同的观察集上训练每个决策树,并且仅考虑有限数量的特征来分割每个树中的节点。随机森林做出的最终预测是通过平均每棵树的预测来做出的。
随机森林实践
与其他Scikit-Learn模型非常相似,在Python中使用随机森林只需要几行代码。我们将构建一个随机森林,但不是针对上面提到的简单问题。为了将随机森林与单个决策树的能力进行对比,我们将使用分为训练和测试的真实数据集。
数据集
我们要解决的问题是二进制分类任务。这些特征是个人的社会经济和生活方式特征,标签是健康状况不佳为0和身体健康为1。此数据集是由中心疾病控制和预防收集,可以在这里找到。这是一个不平衡的分类问题,因此准确性不是一个合适的指标。相反,我们将测量接收器工作特性区域曲线(ROC AUC),从0(最差)到1(最佳)的度量,随机猜测得分为0.5。我们还可以绘制ROC曲线以评估模型性能。
该笔记本包含了决策树和随机森林的实现,但在这里我们只专注于随机森林。在读取数据后,我们可以实现并训练随机森林如下:
from sklearn.ensemble import RandomForestClassifier
# Create the model with 100 trees
model = RandomForestClassifier(n_estimators=100,
bootstrap = True,
max_features = 'sqrt')
# Fit on training data
model.fit(train, train_labels)在训练几分钟后,准备好对测试数据进行如下预测:
# Actual class predictions
rf_predictions = model.predict(test)
# Probabilities for each class
rf_probs = model.predict_proba(test)[:, 1]我们进行类预测(predict)以及predict_proba计算ROC AUC所需的预测概率()。一旦我们进行了预测测试,我们就可以将它们与测试标签进行比较,以计算出ROC AUC。
from sklearn.metrics import roc_auc_score
# Calculate roc auc
roc_value = roc_auc_score(test_labels, rf_probs)结果
最终的ROC AUC是随机森林为0.87,而单一决策树是0.67。如果我们查看训练分数,我们注意到两个模型都达到了1.0 ROC AUC,因为我们给这些模型提供了训练答案,并没有限制最大深度。然而,尽管随机森林过度拟合,但它能够比单一决策树更好地推广测试数据。
如果我们检查模型,我们会看到单个决策树达到最大深度55,总共12327个节点。随机森林中的平均决策树的深度为46和13396个节点。即使平均节点数较多,随机森林也能更好地推广!
我们还可以绘制单个决策树(顶部)和随机森林(底部)的ROC曲线。顶部和左侧的曲线是更好的模型:
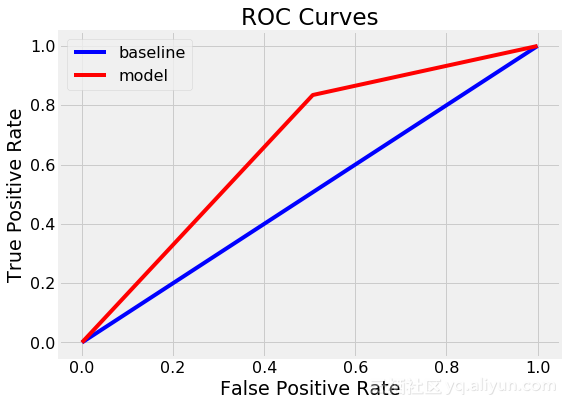
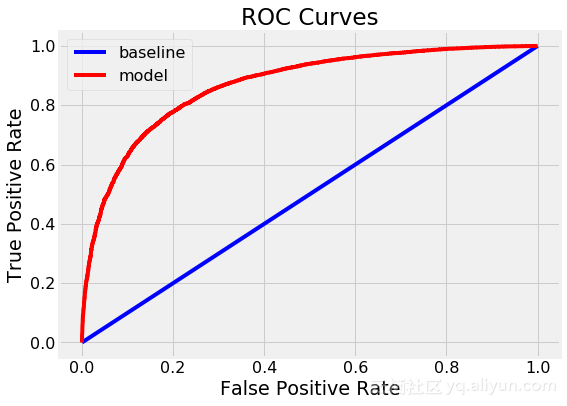
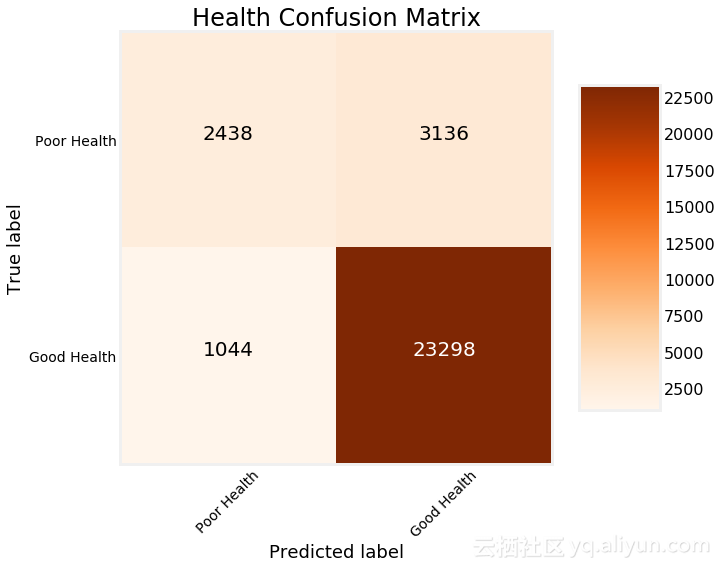
我们看到随机森林明显优于单一决策树。我们可以采用模型的另一个诊断措施是绘制测试预测的混淆矩阵:
特征重要性(Feature Importances)
随机森林中的特征重要性表示在该特征上拆分的所有节点上Gini系数减少的总和。我们可以使用这些来尝试找出随机森林最重要的预测变量,同时也可以从训练有素的随机森林中提取特征重要性,并将其放入Pandas数据框中,如下所示:
import pandas as pd
# Extract feature importances
fi = pd.DataFrame({'feature': list(train.columns),
'importance': model.feature_importances_}).\
sort_values('importance', ascending = False)
# Display
fi.head()
feature importance
DIFFWALK 0.036200
QLACTLM2 0.030694
EMPLOY1 0.024156
DIFFALON 0.022699
USEEQUIP 0.016922我们还可以通过删除具有0或低重要性的特征来使用特征重要性来选择特征。
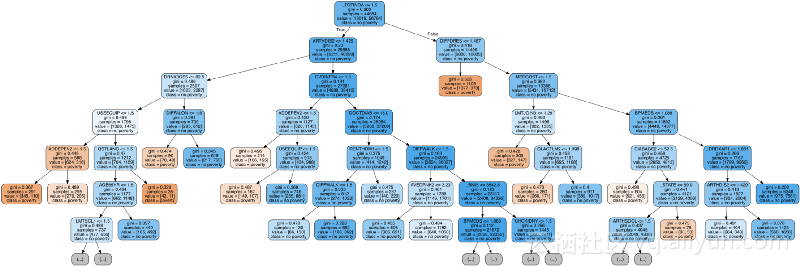
在森林中可视化树
最后,我们可以在森林中可视化单个决策树。这次,我们必须限制树的深度,否则它将太大而无法转换为图像。为了制作我将最大深度限制为6,这仍然导致我们无法完全解析的大树!
优化决策树
下一步可能是通过随机搜索和Scikit-Learn中的RandomizedSearchCV来优化随机森林。
优化是指在给定数据集上找到模型的最佳超参数。最佳超参数将在数据集之间变化,因此我们必须在每个数据集上单独执行优化(也称为模型调整)。我喜欢将模型调整视为寻找机器学习算法的最佳设置。有关随机森林模型优化的随机搜索的实现,请参阅Jupyter Notebook。
结论
在本文中,我们不仅在Python中构建和使用了随机森林,而且还对模型的进行了分析。
我们首先查看了一个单独的决策树,一个随机森林的基本构建块,然后我们看到了如何在一个集合模型中组合数百个决策树。当与bagging特征一起使用和随机抽样时,该集合模型被称为随机森林。从这篇文章中理解的关键概念是:
- 决策树:直观模型,根据询问有关特征值的问题流程图做出决策,通过过度拟合训练数据表示方差高。
- Gini Impurity:衡量决策树在拆分每个节点时尝试最小化的度量。表示根据节点中样本的分布对来自节点的随机选择的样本进行分类的概率。
- Bootstrapping:用替换的方式随机观察组进行采样。随机森林用于训练每个决策树的方法。
- 随机的特征子集:在考虑如何在决策树中分割每个节点时选择一组随机特征。
- 随机森林:由数百或数千个决策树组成的集合模型,使用自举,随机特征子集和平均投票来进行预测。这是一个bagging整体的例子。
- 偏差-方差权衡:机器学习中的基本问题,描述了高复杂度模型之间的权衡,以采用最好的方式学习训练数据,代价是无法推广到测试数据以及简单的模型(高偏见)甚至无法学习训练数据。随机森林减少了单个决策树的方差,同时还准确地学习了训练数据,从而更好地预测了测试数据。
希望本文为你提供了开始在项目中使用随机森林所需的信心和理解。随机森林是一种强大的机器学习模型,但这不应该阻止我们知道它是如何工作的!
本文由阿里云云栖社区组织翻译。
文章原标题《an-implementation-and-explanation-of-the-random-forest-in-python》
作者:William Koehrsen 译者:虎说八道,审校:。
文章为简译,更为详细的内容,请查看原文。