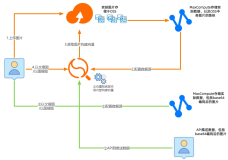
背景
阿里云开放搜索OpenSearch是一款阿里巴巴自主研发的大规模分布式搜索引擎平台,该平台承载了淘宝、天猫、1688、神马搜索、口碑、菜鸟等搜索业务,通过OpenSearch云服务的方式,将阿里巴巴成熟的搜索技术共享给广大开发者。随着近些年客户数量的增加,用户数据越来越多样化,对于搜索结果可定制化的需求也越来越高,在线干预服务就是针对该需求而设计的。
干预服务架构
以功能较全的违禁词干预为例,介绍搜索干预服务的整体框架:

- 干预数据系统前端,将干预数据推送到数据库中,同时触发干预数据推送服务。
- 干预数据推送进程把数据写入swift,在线服务从swift中拉取干预数据,Online生效。
- 干预数据推送服务进程查询数据的在线生效情况,同时将生效情况录入数据库中。
PS. 除了推送干预数据,管理前端还包括删除、修改、查询干预数据的功能。另外,在线生效API,干预历史操作记录的查看也是从此接入。
目前主流的干预服务架构,包括以下两条数据流
- 通过SyncService写入ODPS的全量流
- 通过api推送的实时流
上述方案的核心在于解决在线数据生效检查的问题,本文后续将介绍OpenSearch的解决方案。
现有干预服务架构存在的问题
上述干预服务架构不适合直接复用在OpenSearch现有的框架上,主要原因有以下几点:
- 不支持多租户干预数据管理,使用方自己存储干预数据
- 不支持按条件dump干预数据到odps表中,使用方自己从自己的维护的数据库中dump数据
- 针对违禁词干预,支持查询在线业务是否生效,其他干预类型不支持
- 不支持用户自定义的数据格式的校验
- 不支持保序
- 干预服务是一个独立服务,一个进程,单点运行,存在风险
- 没有部署在hippo上,不便于运维
整体架构

如上图所示,干预系统的整体框架主要包括三个模块:绿色标注的reception woker,主要面向前端推送、删除和查询干预数据。蓝色标注的ops woker,负责提供干预系统的运维服务,包括注册/删除干预类型,查询数据生效状态等等。紫色标注的sync worker,负责同步DB中的数据到在线服务,该woker是面向内部的服务,无法通过外部API访问。值得一提的是,考虑到某些业务有dump全量到ODPS的需求,干预系统在设计的时候预留了dump数据的API,可以通过接口操作ops worker实现dump,其中ODPS的access_key, secret均可以通过config文件配置。
OpsWorker
- 通过ops worker可以添加新的干预类型,包括定义干预数据的schema、对每个字段的检验规则、数据的发送目标(如: swift zk地址,swift topic)
- ops worker提供按条件dump数据的odps中的api
- ops worker会定期更新每个类型的类型的哨兵doc的时间戳,并检查对应的表数据是否生效;
服务重启恢复:
ops worker保证重启自动从断点恢复服务,以dump data为例,数据库中保存pending_task_table和history_task_table两张表,分别记录正在dump的任务和历史任务。用户提交dump请求时,ops worker利用dict type、dict id和ODPS信息生成signature,查找pending_task_table,如已经存在相同任务则返回其task_id。如果不存在,线程只需将相关信息写入数据库,ops worker另启一个线程扫描pending_task_table,执行dump任务,dump完成删除pending_task_table相关任务,同时修改history_task_table中任务状态。如果服务运行过程中宕机,重启之后依旧会启动线程从pending_task_table中读取待dump的任务,保证服务的正确运行。
ReceptionWorker
- 通过ops worker注册干预类型后,就可以发送干预数据。
- reception worker支持增、删、改、查。
- reception worker接受到干预数据后,根据注册好的校验规则,对数据进行验证。校验规则如:数据的字段类型、内容格式、总的干预数据条数、发送到swift中的格式等。
- 验证通过后将数据保存到db中,成功后api返回推送成功
除此之外,reception worker还具备保序功能:
- 用户请求中带上timestamp,如没有,reception worker按收到请求的时间作为请求的timestamp
- 数据库中存放数据记录表中有个字段用来保存该timestamp;
- worker在写数据时,比较请求的timestamp和数据库中该记录对应的timestamp大小,如:
- 请求中的timestamp较大,则更新数据库中的记录中的data,task_id, timestamp
- 请求中的timestamp较小,则不更新
SyncWorker

- 订阅drc消息,将数据库更新的记录同步到swift中
- 不同类型的干预数据可以在同一张db表中
- 对每种类型的干预数据启动一个线程,从drc订阅增量数据,过滤出需要的干预类型的数据,转换成相应的格式后发到swift中
在线生效验证

注:idx表示dict_idx, data表示干预数据,u_tx表示用户给数据打上的用于保序的时间戳,s_tx表示reception_worker收到数据给打的时间戳。
如图,我们采用时间戳的方式来验证数据生效,干预数据推送进入数据库时记录其时间,sync worker同步DB中的数据到Online Service。同时,数据库中保留哨兵(sentinel)时间戳,ops worker定期去更新数据库中的哨兵时间戳,DRC同步更新的数据到Online Service,ops worker定期检查未生效的数据,如果其时间戳小于Online中时间戳,表明数据已经生效。
以上图为例进一步说明:
- reception worker接收到干预数据推送请求,如图中:
- 请求1,包含了词典id1的数据,请求中有数据的timestamp;
- 请求2,包含了词典id2的数据,请求中有数据的timestamp;
- 请求3,包含了词典id2的数据,请求中无timestamp,此时reception worker会以接收到请求的时间点作为请求的timestamp
- reception worker会根据请求中的timestamp对数据做保序处理;
- reception worker会将请求中的数据做处理(包括数据验证、条数控制等),生成task_id, 将干预数据写入data table中,同时将task_id和写data table完成的时间戳(s_t:system_timestamp)写到task table中,如图中:
- 请求1,对应的task1,完成的时间为s_t1,status为未生效;
- 请求2,对应的task2,完成的时间为s_t2,status为未生效;
- 请求3,对应的task3,完成的时间为s_t3,status为未生效;
- 其中s_t1 < s_t2 < s_t3
- 写db完成后,reception worker返回响应,响应中包含了本次请求对应的task_id
- 在这个过程中,ops worker周期性的刷新哨兵doc: sentinel记录中的timestamp,如图中:
- 在reception worker完成请求2写数据库的时候,sentinel的timestamp被更新为s_t2;
- 在reception worker完成请求3写数据库的时候,sentinel的timestamp被更新为s_t3;
- sync worker通过drc订阅了data table的数据变化,并将变化的数据依次写入到swift中,写入swift中的数据序列如图中:
- id1,id2, sentinel, id3, sentinel
- 在线服务通过订阅swift获取对应的消息,每个表只订阅自己关心的数据,每个表都会订阅sentinel的数据,如图中:
- cluster1中的table1,订阅到的消息序列为id1, sentinel, sentinel
- cluster1中的table2,订阅到的消息序列为id2, sentinel, sentinel
- cluster1中的table3,订阅到的消息序列为sentinel, id3, sentinel
- cluster1中的table4,订阅到的消息序列为sentinel, sentinel
- 在线服务依次处理订阅过来的消息
- ops worker在周期性的获取task table中未生效的task,并通过dict_type和dict_id查询在线服务,获取其中加载的sentinel doc的最新时间戳,通过该值和表中task对应的timestamp做比较,如:
- 查询返回的值较小,则说明数据未生效;则继续检查;
- 查询返回的值较大,则说明数据已生效,将task table中对应记录中的status设置为已生效;
- 图中的task1,仅当sentinel doc的timestamp大于等于s_t2时,则已生效
- 图中的task2,仅当sentinel doc的timestamp大于等于s_t2时,则已生效
- 图中的task3,仅当sentinel doc的timestamp大于等于s_t3时,则已生效
产品设计
查询分析词典干预逻辑主要可以拆分为三个流程,
- 创建干预词典流程
- 管理干预词典流程
- 绑定/解绑到规则/模型流程

下面以停用词词典为例,介绍OpenSearch干预服务产品设计方案
查询分析干预词典创建和呈现
用户从主导航栏点击干预功能,选择查询分析子菜单,进入到查询分析干预功能首页。在首页,用户可以实现干预词典的创建、干预词典的列表呈现和简单的操作管理。
创建查询分析干预词典
用户在查询分析干预首页点击创建按钮,弹出创建词典弹框。
- 词典名称,可自定义名称,用来列表展示。
- 词典类型,可选同义词、停用词、拼写检查。
- 点击确定后,干预词典创建完成。
- 创建好的干预词典显示在字典列表。
- 创建完成的干预词典后续不支持词典名称和词典类型的修改。

干预词典列表
- 包含干预词典的名称、词典类型、使用该词典的查询分析规则名称、词典的更新时间以及操作栏。
-
在操作栏可以对词典进行编辑和删除。
a. 点击编辑后进入对应词典的编辑页面,用户可在词典编辑页面上传干预内容。
b. 点击删除后弹出删除提示弹框,确认删除后,该干预词典内的干预数据失效,干预词典也不再在列表内展现。 -
刷新列表: 用户配置使用干预词典的查询规则后如果列表内未显示最近的配置,点击刷新尝试重新获取配置结果。
停用词干预词典干预数据上传
核心逻辑描述,
干预对象:系统原生停用词词典
干预方式:手动输入、文件批量上传
干预行为类型:添加、屏蔽
手动输入方式上传干预数据
a. 添加操作:添加的内容只是具体的停用词。添加生效后,干预词条在查询中会按照停用词处理。
b. 屏蔽操作:填写格式同上。生效后,该干预词条在查询中不会按照停用词处理。
c. 每行只支持填写一个停用词,点击“新增”,用户可以继续增加新干预词条

批量导入方式上传干预数据
用户可上传文件添加干预数据,文件内容的格式待定。
词典干预内容列表。呈现内容包括干预行为类型,干预词条,干预生效时间,生效状态和操作栏。
- 生效状态只有两种,已生效和正在生效。
- 操作栏支持用户进行干预内容的删除操作,删除后该条干预失效,列表内也不再展现。