1.卷积操作
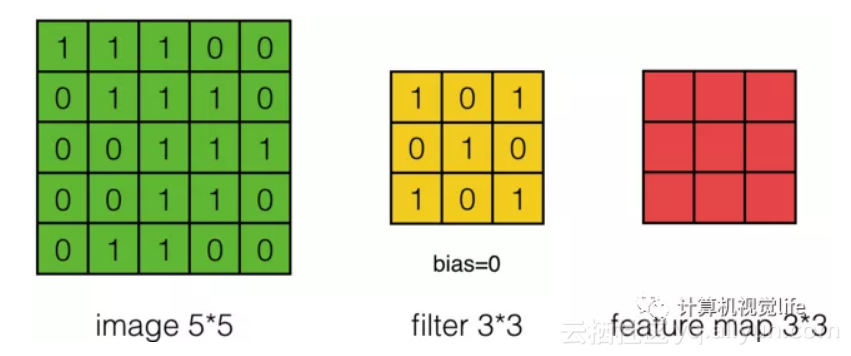
假设有一个5*5的图像,使用一个3*3的卷积核(filter)进行卷积,得到一个3*3的矩阵(其实是Feature Map,后面会讲),如下所示:
下面的动图清楚地展示了如何进行卷积操作(其实就是简单的点乘运算):
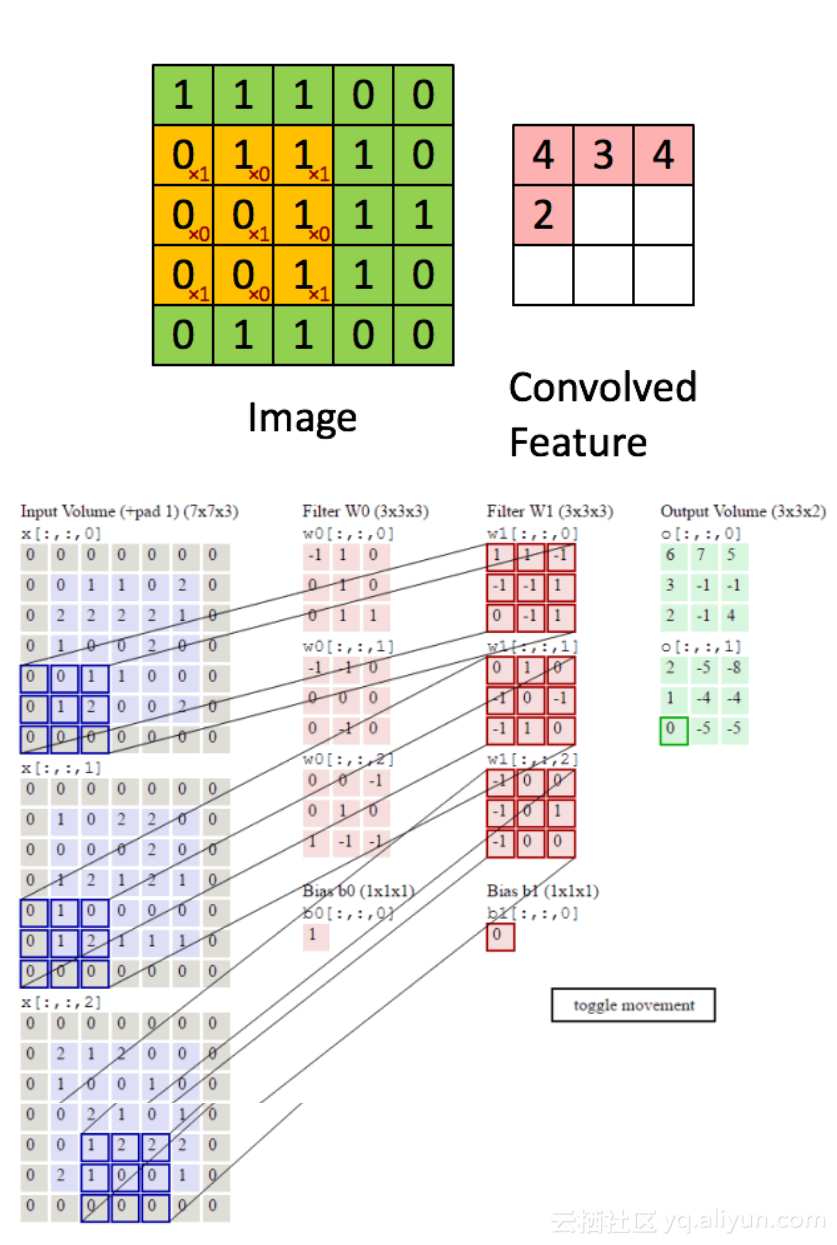
一个图像矩阵经过一个卷积核的卷积操作后,得到了另一个矩阵,这个矩阵叫做特征映射(feature map)。每一个卷积核都可以提取特定的特征,不同的卷积核提取不同的特征,举个例子,现在我们输入一张人脸的图像,使用某一卷积核提取到眼睛的特征,用另一个卷积核提取嘴巴的特征等等。而特征映射就是某张图像经过卷积运算得到的特征值矩阵。
讲到这里,可能大家还不清楚卷积核和特征映射到底是个什么东西,有什么用?没关系,毕竟理解了CNN 的卷积层如何运算,并不能自动给我们关于 CNN 卷积层原理的洞见。为了帮助指导你理解卷积神经网络的特征提取,我们将采用一个非常简化的例子。
2.特征提取—"X" or "O"?
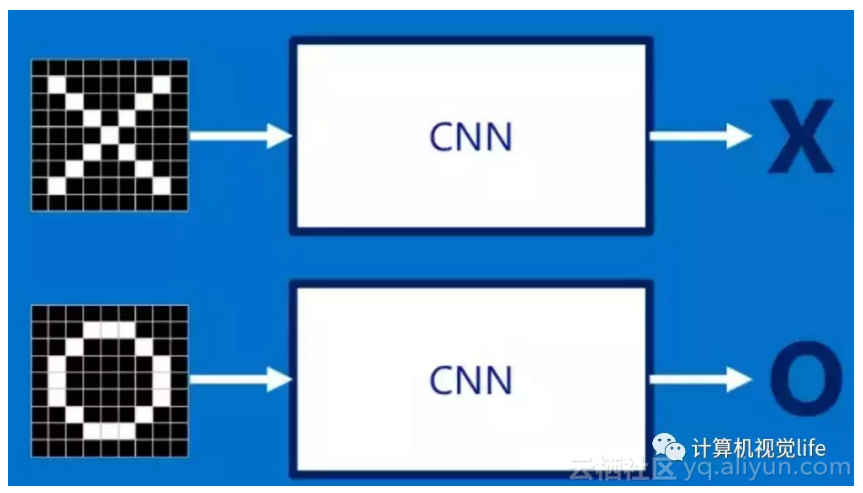
在CNN中有这样一个问题,就是每次给你一张图,你需要判断它是否含有"X"或者"O"。并且假设必须两者选其一,不是"X"就是"O"。理想的情况就像下面这个样子:
那么如果图像如果经过变形、旋转等简单操作后,如何识别呢?这就好比老师教你1+1等于2,让你独立计算1+2等于几是一个道理,就像下面这些情况,我们同样希望计算机依然能够很快并且很准的识别出来:
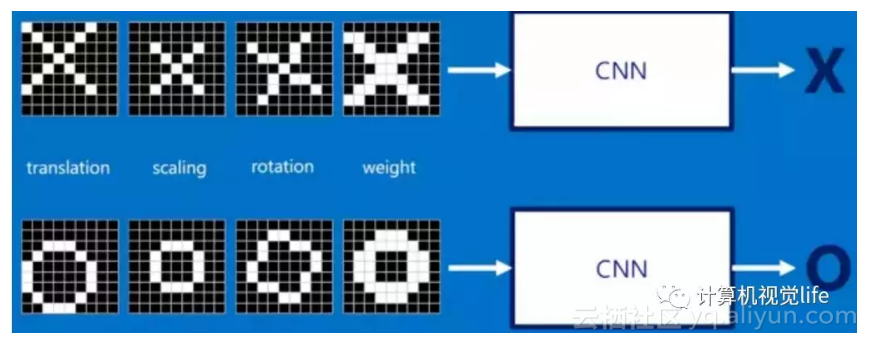
这也就是CNN出现所要解决的问题。
如下图所示,像素值"1"代表白色,像素值"-1"代表黑色。对于CNN来说,它是一块一块地来进行比对。它拿来比对的这个“小块”我们称之为Features(特征)。在两幅图中大致相同的位置找到一些粗糙的特征进行匹配,CNN能够更好的看到两幅图的相似性。
对于字母"X"的例子中,那些由对角线和交叉线组成的features基本上能够识别出大多数"X"所具有的重要特征。
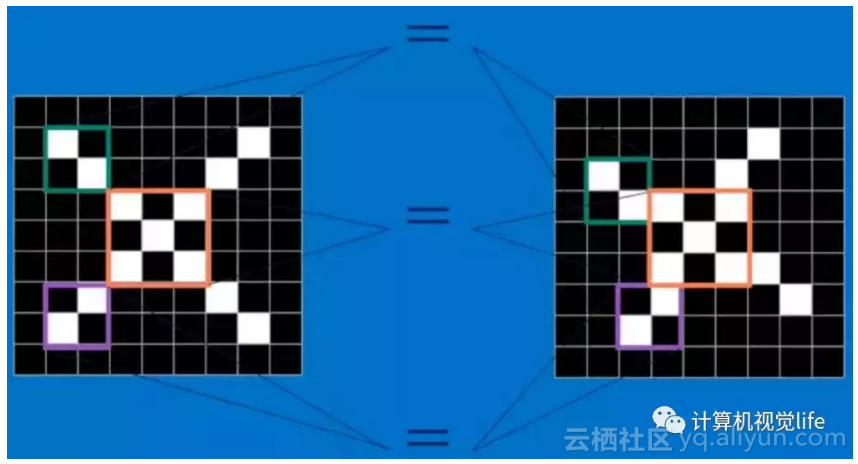
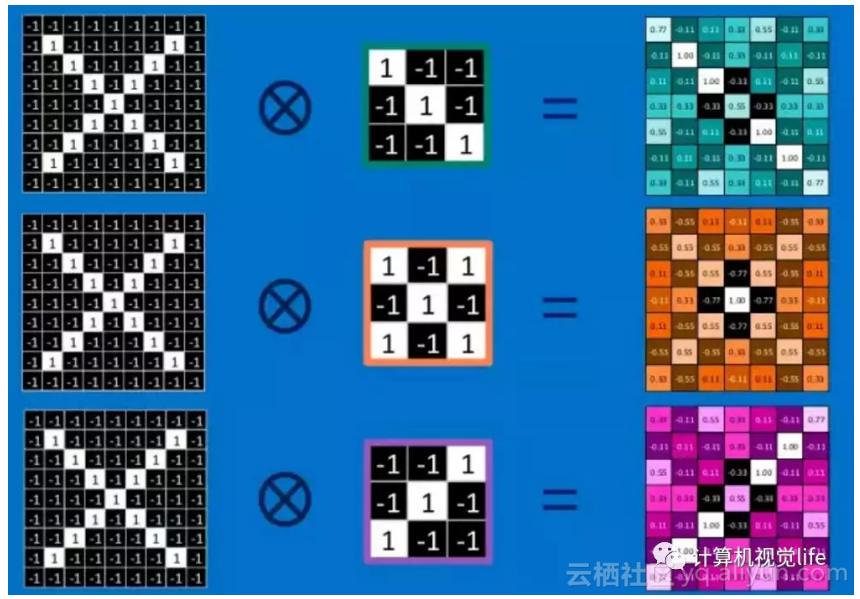
这些features很有可能就是匹配任何含有字母"X"的图中字母X的四个角和它的中心。那么具体到底是怎么匹配的呢?如下三个特征矩阵a,b,c:
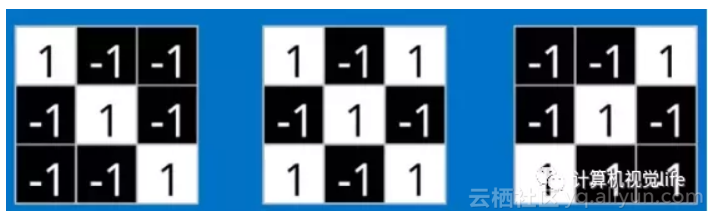
观察下面几张图,a可以匹配到“X”的左上角和右下角,b可以匹配到中间交叉部位,而c可以匹配到“X”的右上角和左上角。

把上面三个小矩阵作为卷积核,就如第一部分结尾介绍的,每一个卷积核可以提取特定的特征,现在给一张新的包含“X”的图像,CNN并不能准确地知道这些features到底要匹配原图的哪些部分,所以它会在原图中每一个可能的位置进行尝试,即使用该卷积核在图像上进行滑动,每滑动一次就进行一次卷积操作,得到一个特征值。仔细想想,是否有一点头目呢?
(下图中求平均是为了让所有特征值回归到-1到1之间)
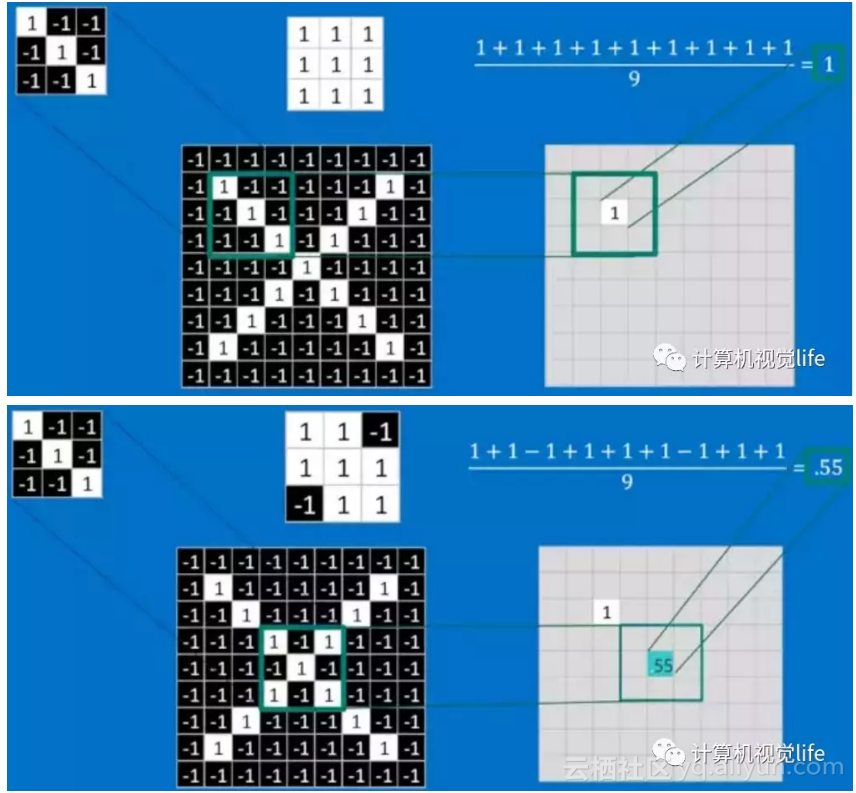
最后将整张图卷积过后,得到这样的特征矩阵:
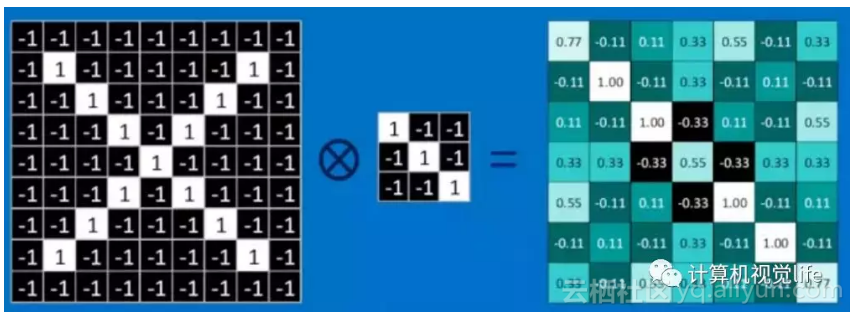
使用全部卷积核卷积过后,得到的结果是这样的:
仔细观察,可以发现,其中的值,越接近为1表示对应位置和卷积核代表的特征越接近,越是接近-1,表示对应位置和卷积核代表的反向特征越匹配,而值接近0的表示对应位置没有任何匹配或者说没有什么关联。
那么最后得到的特征矩阵就叫做feature map特征映射,通过特定的卷积核得到其对应的feature map。在CNN中,我们称之为卷积层(convolution layer),卷积核在图像上不断滑动运算,就是卷积层所要做的事情。同时,在内积结果上取每一局部块的最大值就是最大池化层的操作。CNN 用卷积层和池化层实现了图片特征提取方法。
3.反向传播算法BP
通过上面的学习,我们知道CNN是如何利用卷积层和池化层提取图片的特征,其中的关键是卷积核表示图片中的局部特征。
而在现实中,使用卷积神经网络进行多分类获目标检测的时候,图像构成要比上面的X和O要复杂得多,我们并不知道哪个局部特征是有效的,即使我们选定局部特征,也会因为太过具体而失去反泛化性。还以人脸为例,我们使用一个卷积核检测眼睛位置,但是不同的人,眼睛大小、状态是不同的,如果卷积核太过具体化,卷积核代表一个睁开的眼睛特征,那如果一个图像中的眼睛是闭合的,就很大可能检测不出来,那么我们怎么应对这中问题呢,即如何确定卷积核的值呢?
这就引出了反向传播算法。什么是反向传播,以猜数字为例,B手中有一张数字牌让A猜,首先A将随意给出一个数字,B反馈给A是大了还是小了,然后A经过修改,再次给出一个数字,B再反馈给A是否正确以及大小关系,经过数次猜测和反馈,最后得到正确答案(当然,在实际的CNN中不可能存在百分之百的正确,只能是最大可能正确)。
所以反向传播,就是对比预测值和真实值,继而返回去修改网络参数的过程,一开始我们随机初始化卷积核的参数,然后以误差为指导通过反向传播算法,自适应地调整卷积核的值,从而最小化模型预测值和真实值之间的误差。
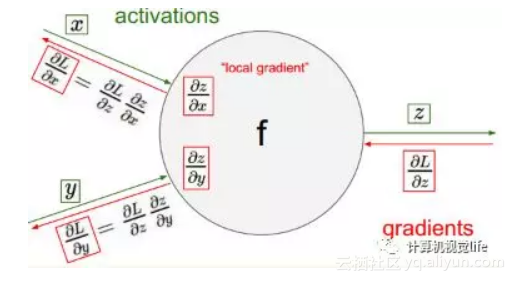
举一个简单例子。绿色箭头代表前向传播,红色代表为反向传播过程,x、y是权重参数,L为误差,L对x、y的导数表示误差L的变化对x、y的影响程度,得到偏导数delta(x)后,x* = x-η*delta(x),其中η为学习率,从而实现权重的更新。
在此放一个简单的反向传播代码,python版本,结合代码理解BP思想。
链接: https://pan.baidu.com/s/1WNm-rKO1exYKu2IiGtfBKw 提取码: hwsu
4.总结
本文主要讲解基本CNN的原理过程,卷积层和池化层可以提取图像特征,经过反向传播最终确定卷积核参数,得到最终的特征,这就是一个大致的CNN提取特征的过程。考虑到反向传播计算的复杂性,在本文中不做重点讲解,先作为了解思路,日后专门再讲解反向传播的方法原理。
原文发布时间为:2018-11-23
本文作者:Echo