我今天介绍一下我们PingCAP的设计理念进化和一些实践。
到现在为止TiDB已经开源有三年零两个月,我是TiDB CEO,打杂比较多,偶尔写写代码。

为什么做这个?我们被无数人问到这个问题。当初为什么我们要做一个分布式数据库?作为程序员我相信很多人很愿意花些时间写代码写自己的东西,然而一直没有非常理想的机会。
第二个不用关心容量规划,程序员不知道这个东西最终能增长多少倍。
第三个任意时候都能扩展,弹性伸缩。大家都有这个经历,凌晨三点做扩容经历。
第四个,已有成本迁移,这是没有办法去避免的问题,现在有大量的产品在已有数据库在跑着,我们希望得到更好的弹性。

在定这些目标之后我们开始做行动,作为数据库厂商,大家通常担心的第一件事情是产品的正确性,特别是算法的正确性证明。如果算法是错的,我们算下来100%是错的。所以我们对于每个算法,每个改进都先写证明,我们把所有证明过程也开源了。写证明会发现整个系统里有大量的并发问题。
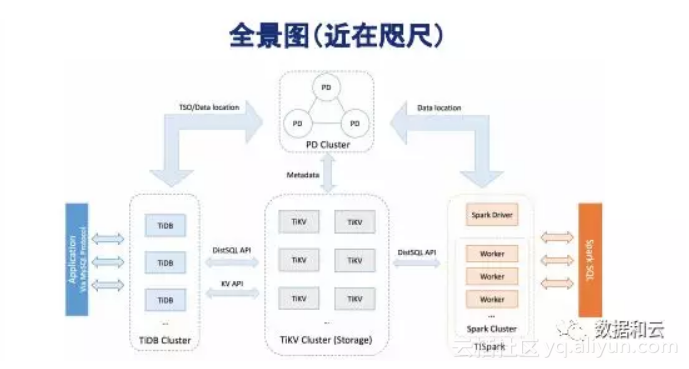
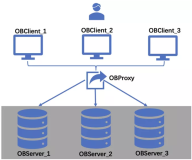
另外几点水平扩展、高可用。因为大家知道数据库情况很复杂,整个系统的复杂性,我们有点类似于像微服务的思维,把整个系统分成几层,存储层、计算层、调度层,彻底分开,分别变成不同的。产品总体看起来是这样的,大体上是MySQL协议支持,SQL layer、tiKV,调度器会动态把一些数据移动、分裂,让所有的数据在整个系统里都是动态的,这也是不同其他的地方。近距离看大概是这样的,时间关系不详细展开。
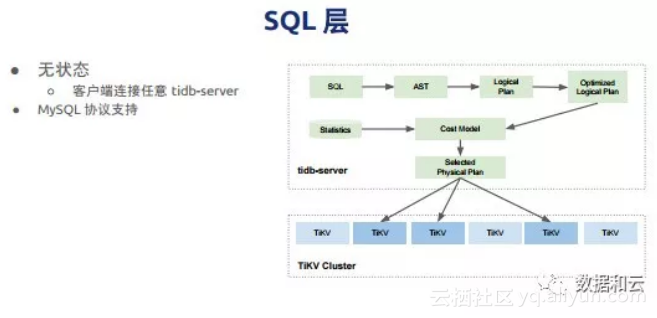
从SQL角度来看,我们有逻辑计划,逻辑计划做优化最后会变成物理的plan。下面整个底层是存储层。
从用户角度来讲,用户通常不关心说我到底是OLTP还是HTAP。Oracle从一开始设计,考虑新产品上线的时候大家觉得紧张,觉得数据库上去会不会是安全的。我线上已经做了库分表,或者线上已经有多个业务在跑,我现在需要有一个平台去查询已有的所有数据,于是他们就干了这样的一件事情,搭了一个大的TiDB咨询,把全公司所有业务全部导在这上面进行同步,这样TiDB就变成了很有意思的数据中台,全公司的数据都可以在毫秒级内去做查询。
我们当时看这个案例都惊呆了,觉得我们不是用来干这个事儿的,后来用户把TiDB用成认证SAP的场景,比较早期它一上来解决这样的痛苦,当时TiDB完全没有想到。后来我们慢慢想明白了当你把所有数据放在一个平台上的时候,你在这个平台上做查询你把原来分库分表写的很痛苦的问题,每天晚上做分析,这个已经不满足现在社会需要,大家希望在毫秒级对数据进行决策,比如说分控。
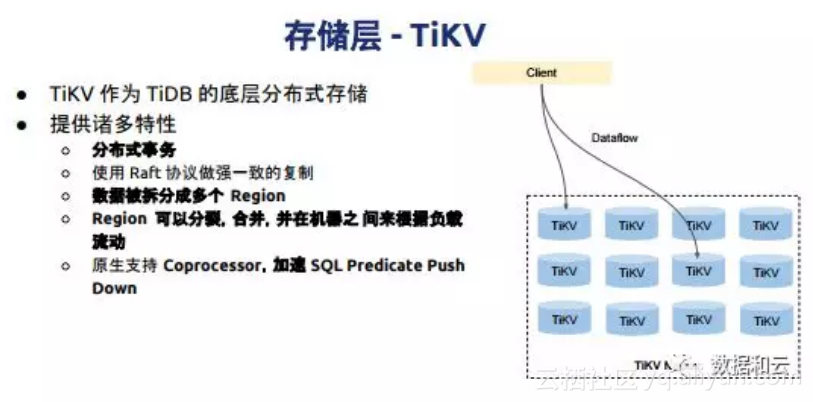
这是我们存储层整体的用户感受,存储层为SQL提供,一个是分布式事务,再也不用操心这个事务是分布式事务还是单机事务,我们只提供一种就是分布式事务,不管什么操作都是满足数据属性的。刚才我也提到数据被拆分很多层,它已经拆分可以合并,这个好处在于什么?
这时候分库表就会非常痛苦,它会自动把这个块切成多块再分布多个机器里,它会做自动的负载均衡。当我们有很多这样小块出现,这些小块平时可能有很少访问的时候,我们会尝试把它变成大块,可以对它进行分裂、合并。这块很明显看到,TiDB和其他数据库的理念差异,我们认为所有数据库都应该是动态的,而不应该是静态的。同时我们也会把SQL计算,把函数会推到存储节点,这样减少中间的环节。
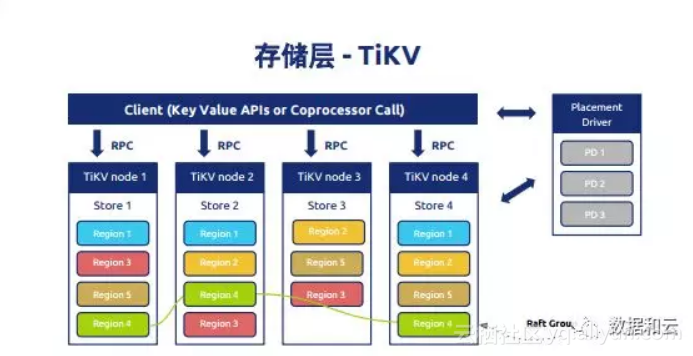
这是一个大图,TiDB怎么做到高数据中心的强一致,单数据中怎么挂节点,怎么确保数据可用。通常部署是这样的,通常有三个副本,用颜色标出来,然后是协议复制。这是通常的线上的部署的场景,对于金融环境,比如说像银行,我们一般推荐5个副本。这个也是符合google当初提到的,他们推荐的是7个副本。取决于数据库的重要性。
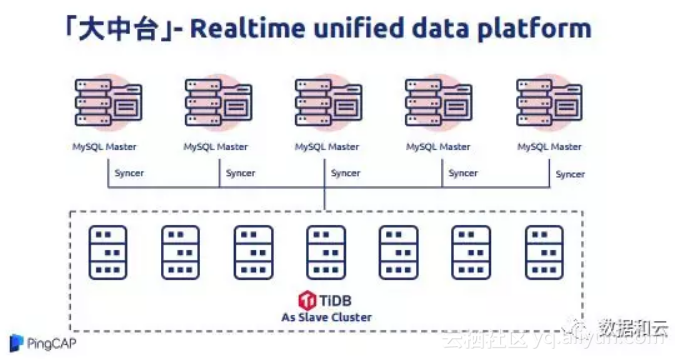
接下来说一下我们的实战经验,刚才我提到大中台业务,实时把公司数据会聚在一起,因为它是很自然的需求,也是一个完美的替代方案。这是历史上很有意思的使用逻辑,刚开始把数据同步,可靠性都能达到要求的时候,就把前面分库表撤下去直接把它打到集群里,这时候整个系统就高度一致了。这是一个更加好理解的图,中间所有的数据都可以通过Syncer,进行数据同步。目前我们数据量特别大的场景里,这种场景用的比较多。
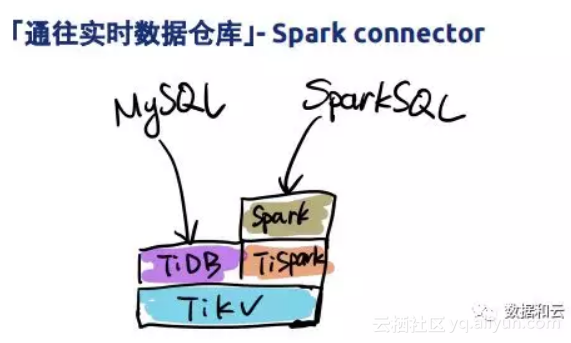
考虑到实时性和Spark生态,我们提供Spark connector,它会绕过TiDB层直接跟Tikv层,期间减少转换开销。
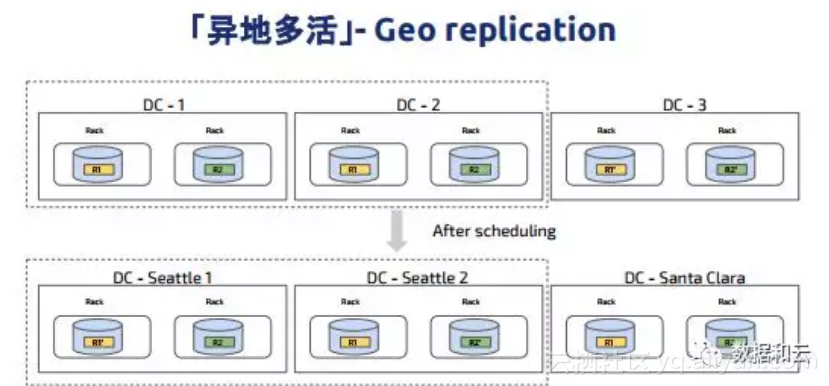
这是非常典型的异地多活架构图,也是目前我们在银行里实施的整体架构。目前一部分核心电子交易系统也使的这样的架构,通常使用5个副本,大体上是这样的,在整个系统里代表数据块,可以看到对于同样的一块数据,我们会让它复制在多个数据中心,同时通过调度器会将相同的数据块leader调度到离业务比较近的一块地方,这样一来业务去访问的时候延迟就会比较低,这就是有一个很好的调度器带来的好处,它可以控制数据,按照需要去做分布。比如说如果这时候我们要维护一个数据中心,假设我们要维护这边的IDC,这时可以把数据录入到其他地方,等它恢复之后再挪过来。
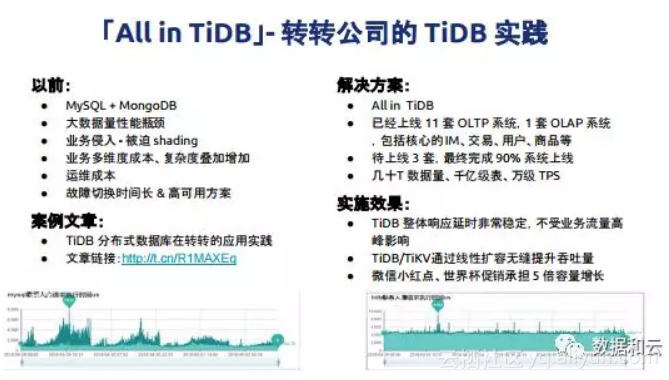
这是转转前一阵分享的案例,转转All in TiDB,把以前的很多业务都迁到TiDB上面,当时微信支持转转,他们当时增长约五倍,有一篇非常详细的文章,分享时间会比较长。我这边稍微小结一下,他们目前的上线情况,上线11套OLTP系统,1套OLAP系统,完成90%的数据迁移,TiDB数据千亿级表,万级TPS。这个地方他们分享了一个截图,在他们放量期间,整个TiDB响应时间非常的短。

美团昨天刚刚发了一篇文章讲他们自己的使用经验,目前上线了大概200台物理机,上了10多个业务,以前的时候美团主要数据库用的MySQL、NoSQL,同时他们有一个自己的研发。当然融合起来都非常的痛苦,同时美团用了很强的研发能力,也在参与TiDB的开发。当时他们选择新一代数据库的定义几个重要目标,一个支撑未来几十倍数据增长目标,数据库其中是很重要的一个组件,所以在数据库选型花了大量的时间,应该是以几个月时间对数据库做各种的测试,对于数据库原理的理解,对于数据库阅读,最终对比之后他们选择了TiDB。

这是目前在美团上线10套系统里分布的范围,分到6个事业群和平台。刚才我也提到,在线上层开启Region,整个系统会自动把小的数据块合成大的数据块,永远有调度源根据负载做调度,这是加快删除数据后的空间回收速度。

美团推广速度非常快,大概只用三个月时间就上线这么多系统,后来我们也去找美团同学请教经验,为什么推广这么快?他们有专门的地推小组,第二有专门的研发同学和我们有直接的合作,直接是代码级别的合作,也会发布他们自己对于TiDB的改进经验,还有一些从研发层面的源码改进。这是HTAP的案例,这是易果生鲜,他们非常符合刚才我们提到的大中台的结构,就会数据同步。
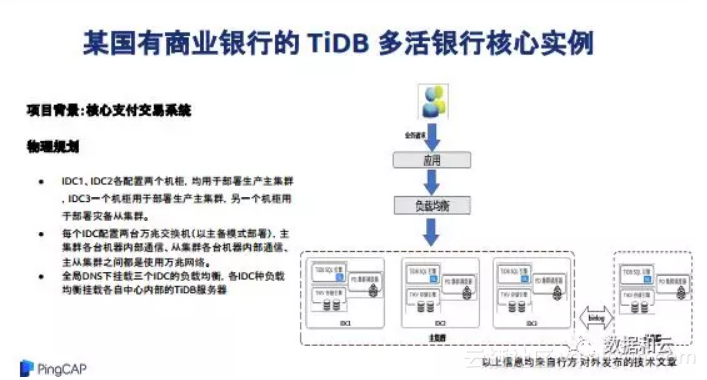
讲商业银行之前,我想说一句,根据我们自己的统计,目前30亿美金以上的互联网公司已经有8成用了TiDB,我当时看了也觉得特别的震惊,我相信明年会更多,这是国内的一个商业银行的多活的交易系统里面的部署结构。这部署结构相对来说,看起来很顺畅,按照一个TiDB的标准结构,同时为了数据的绝对安全,我们后来又加了集群,它主要做备份,它有3个副本,所以我们搭建了备份系统。
前一段时间我们看到他们支撑双十一的过程,非常让人过程,双十一是很神奇的节日,可以把一天的流量聚集到那么两分钟。有一篇文章写的很详细,网上有发表,他们怎么用,怎么测试,怎么选型以及怎么上线和上线的经验。
我重点说一下,当一个数据库产品从开始的到用户去用到场景越来越多的时候,需要产品有更好的适应性。在这种情况下产品需要不断的进化,在进化里有很有意思的过程,就像我们人一样,我们一步步往外的。通常情况下,一个MySQL大家觉得合理,大家觉得一行在50列以内是合理的举手?200列以内合理的举下手?400列以内合理的举下手?在很多行业几百列是常态。咱们互联网一般在这些场景见的不多,现在觉得500列已经不够用了,大家需要更多的怎么办?

那好,我就什么都能存,这时就面临一个问题。SQL有一个问题,当我们把实际减少字段挪出去只处理它的源数据在哪一个位置,它长度多少,我们只需要几十个字节就搞定了。所以我们就把value从LSM tree中分离出来。
Serverless是去年和今年都比较火的话题,TiDB目前已经在上面提供了服务,目前在google GKE和AWS EKS都已经上线,大家可以在这两个平台一键搭建TiDB,目前这两个平台API和 K8S上线非常舒适,我们很好的在线上给大家提供服务。同时正在做的事情,根据负载自动添加计算节点,让大家无感,让大家不用计算,我到底要部署多少个存储节点,这些东西不需要关心,后台自动会帮你做,它会根据负载自动添加或伸缩。
TiDB对于存储要求,我们要求使用SSAD。这时候就会带来大家担心的成本问题,我知道虽然现在MME(音)已经是新的采购标配,不是所有数据都需要在数据库里,需要在内存里有索引,但是对于数据变冷之后,系统应该自动识别冷数据,并且把冷数据自动搬出去,同时保持相对可以接受的延迟,需要时按需做加载做计算,当一个集群到几百T时需要算几百T的成本,这时就需要有一套方式能够把数据的冷热进行分离出来。分离的过程,完全不需要人操作,因为系统可以根据访问数据热度上线时间来决定。简化数据管理最重要,当然存储成本现在已经很便宜,这个也会进一步降低存储的成本。
刚才我也提到用户根本不关心所谓的OLTP、OSTP,能不能搞定,和很好的做隔离。所以在TiDB下一代迭代里会出现全新的结构,在TiDB的三个副本里有三个副本使用列存,它会根据查询特点,这时候根本不进到行存会直接在列存出现结果。同时在扫大范围表里会自动到列存,会把行存列存数据统一出来,这时会有非常震撼的效果,它会像列存行存跑得快,最重要一点不用关心它是列存还是行存,同时访问的时间没有延迟。
如果大家先用现在的版本,会发现现在的版本没有很好的做到在CPU,在内存上的隔离。现在按照队列优先级来的,接下来的版本会看到完全不一样的,同时对优化器产生非常高的要求,以前大家见到所有的优化器都考虑我是行存或者列存优化器,现在
它是智能优化器,它会根据你的特点到底选择行存还是列存去存,还是一部分到列存里,比如ID会印什么,印的这里会在行存里存,其他在列存里,最后折合在一起,这将让我们非常兴奋,我们预期1月份放出第一个可以体验的版本。
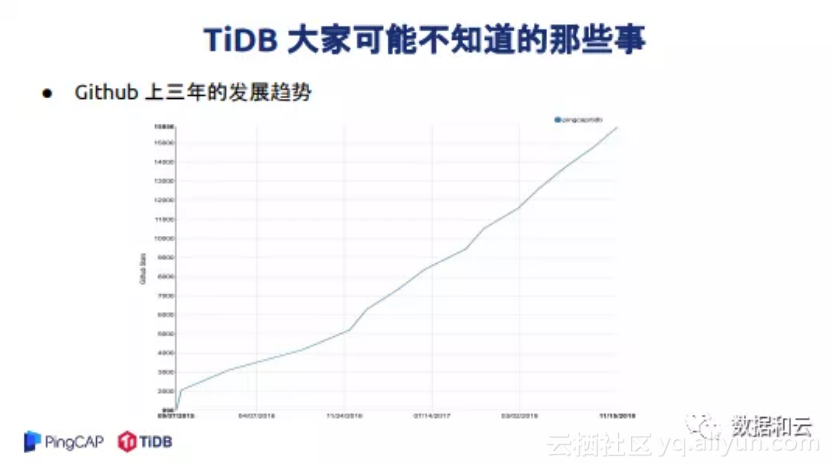
很多人知道TiDB,知道TiDB很多事情,也有很多事情可能大家不知道。我说一下大家可能不知道TiDB的一些事情,我们知道TiDB今年拿了最佳的开源软件奖,我印象中历史上好像是第一个国内厂商拿到这个奖,欢迎大家纠正我。

TiDB也是进了CNCF database landscape,如果没记错,国内厂商第一个进到这里。我非常欣慰,这么多年终于可以为国争光了。同时我们也做了一些事情,我们把TiKV给了CNCF,在前两天大会上也是被大家认出来了。作为一个低调厂商,可能这些东西都不知道,我们从来没有做过融资发布会,从来没有做过产品发布会,和大家印象中的很多公司都不一样,我们一直低调做事情,最终还是能看到大家以前看不到的那些东西。我们也进了Big data landscape,好像也是唯一的国内厂商,大家可以看一下这个图,非常的欣慰。

大家可能不知道TiDB的用户早就分布了全球,大家通常只能看到身边,美团好在用,Oracle在用。大家可能不知道新加坡的也在用,可能也不知道印度在用,台湾也用上了。
谢谢大家!
原文发布时间为:2018-11-22
本文作者:刘奇