sklearn
就是因为有了像sklearn这样的黑箱库, 我们大部分时候做的是调试算法, 比较那个算法的性能好, 这就需要熟练算法的推导过程
preprocessing模块
1. 将特征缩放, 提到精度
scale()函数时对矩阵每一列进行操作, 使其均值为0, 方差为1
StandardScaler().fit(X\_train)返回一个StandardScale对象, 里面封装了对X_train的标准化操作, 当调用transform函数时, 就会返回和scale()函数一样的结果
fit(X_train)函数估算每个特征的平均值和标准差, 所以是按列的
2. 分类
sklearn.moudel.selection.train_test_split(X, y, test_size=0.3, random_state=0)
3. K-CV
KFold(划分的个数, shuffle=是否打乱数据, 一般为False, random_state=None)
其实就是一个随机的下标生成器之类的
4. 在逻辑回归中的predict函数时依赖于predict_proba函数, 其实这个predict_proba就是我们求出的目标函数, 该函数的结果是在0-1之间的, 因为sigmoid函数的值域, 我们称返回的结果为概率,
我们带入一个数, 返回的一个概率值, 而predict_proba函数还会使用1减去该值计算出另一个的概率, 对于我们来说, 我们只需要抓住一个值, 判断他与临界点的大小即可, 默认为0.5; 而对于线性回归,
就不需要那么麻烦了, 得出来的目标函数就是结果了
5. 在逻辑回归中, 混淆矩阵是我们常用的, 在confusion_matrix(y_true, y_test)中的y_test要么是我们求出的值, 要么是bool类型的矩阵, true表示肯定回答, false表示否定回答
6. SMOTE对象的fit_sample(X_train, y_train)函数中X与y是我们train_test_split之后剩下的所有数据, 没有进行KFold, 因为数据还没有处理好, 该函数会自动根据SMOTE算法生成和数量较多的标签值的一样的数量, 所以返回的结果比我们原始传进来的要多, 但是返回的一个矩阵
7. StratifiedKFold需要y标签, 根据y标签分类的比例进行划分
8. feature_selection模块中的SelectKBest类对象, 他的.fit_trainsform方法用来返回有用的特征, K表示特征放回的特征个数, SelectKBest(选择特征的算法(chi[卡方], f_classif[用于分类], f_regression[用于线性]), k=返回的特征的个数), 返回的是新的特征X, 而selector.pvalue_属性保存的矩阵是一开始传入的特征的score, 该对象就是通过该score选择特征的
pandas
1. df的iloc和loc属性, loc是相对于原始数据的下标, iloc是相对于当期的数据
2. pd.value_counts(df['col_name'])返回一个Series的总结结果
3. pandas也可以画图, series_obj.plot(kind='bar')
4. df.列名
5. df.describe()返回DataFrame对象, 描述了mean, max, min, count等实用的信息
机器学习知识点
recall与precision
- recall: 称之为查全率, 通过学习出来的算法已经得到的相关的TP的样本个数/实际上数据集中符合相关的数据的个数, 它的补数是漏查率
- precision: 称之为精度, 通过学习出来的算法已经得出的样本个数/所有样本个数, 它的补数是检错率
- p: 表示回答为肯定, n: 表示回答为否定, t:表示判断是正确的, f:表示判断是错误的, 在机器学习中, 我们一般规定符合我们的目标的为1, 不符合为0
- iris(鸢尾数据集)是一个非常有名的数据集, sklearn.datasets.load_iris()函数可以得到该数据集, 可以用于测试
- one-hot: 通常用于有字符串的数据, 将字符串转为数字, 如果一个特征只有几种的值, 可以为这些值进行排序和编号(1,2,3), 一个样本, 如果有则为0, 否则为以1, 最终[0,0,1,1,0]的形式
step1. 数据加载和预处理
step2. 定义分类器, 比如: lr_model = LogisticRegression()
step3. 使用训练集训练模型 : lr_model.fit(X,Y)
step4. 使用训练好的模型进行预测: y_pred = lr_model.predict(X_test)
step5. 对模型进行性能评估:lr_model.score(X_test, y_test)
注意点
- 对于下采样, 一般先获取各个的下标, 其中多的下标数中随机抽出和少的一样多的下标数, 接着调用result = np.concatenate([one, two])将下标合并, 在df.loc[result]得到我们的数据集
- 获取数据集, data.loc[:, data.columns != 'somevalue'], 这样就去掉了标签项, data[:, data.columns == 'somevalue']就得到了标签, 意思是, 每一行都要, 但是只要最后一列, 注意是loc
- 一定要查help, 因为Python不兼容的情况有很多, 不像Java一样
- python3 -m pydoc -p 8080 查看API
- Python中的函数一般都有很多的参数, 其实我们大部分只需要填写非默认参数即可, 只填写位置参数在很多使用就能满足我们的要求
- 很多函数要我们传入一个array-like参数, 表示我们可以使用np.array表示或者使用list表示, 返回就是长得像矩阵的, 他内部的实现应该是遵循了协议吧, 因该是slice协议里, 都支持切片
- 在sklearn中有一个正则化(regularize)惩罚的过程, 该过程就是可以查看一个泰勒公式的多项式展开的过程, 在调用LogisticRegression(C=c_param, penalty='l1')时, C表示我们添加的趋近于0的一个正则化参数, 防止得到的目标函数unfit(bias)或者overfit(variance), 就是我们的特征x^2 * c, 如果使用l1的话, l2是去绝对值, 这个不常用
- 我们知道sklearn中使用fit函数构建模型, predict函数进行应用, 在测试我们的目标函数是否有用时, 我们会调用predict函数, 这是多余的, 所以sklearn就有了一些score函数内部调用predict函数返回精度, 用于判断我们的目标函数是否好, 如果好的话, 我们就可以使用sklearn中的joblib函数的dump保存模型, 用到时, load进来调用predict函数即可
数据处理的步骤
- 下采样或者过采样
- 使用train_test_split(X, y, test_size=0.3, ramdom_state=0)将train dataset划分成train和test, 这里的test是不会动的, 因为他是用来当做最终测试用的
- 使用K-CV对得到的train进行划分
- 使用sklearn库测试出正则化的参数
- 调用sklearn等库函数得出目标函数
- 调用库的predict函数进行测试
- 测试阈值
- 如果是逻辑回归, 画出混淆矩阵
- 确认阈值, 得出精度
copy过来的
第一步、从原始数据里面做特征的抽取,形成宽表。比如日志信息。
第二步、噪音过滤,如果数据中存在缺失值(数据)或者异常值(数据)等要做噪声处理。
第三步、特征选择是要去除掉冗余的特征。你提取了很多你认为是可能影响点击的因素,选择比较合适的放进去
第四步、挖掘特征中潜在的信息可以做特征变换。挖掘特征里面的关系。
第五步、选择合适的算法,建立机器学习的模型。(简单算法包括线性回顾,复杂的用深度神经网络)
第六步、调整参数,使得模型的效果达到最优。
第七步、模型评估,评估指标如Accuracy,AUC等。
结果的好坏,需要有一个反馈机制,效果不好,重新进行特征选择。
在推荐案例方面,前百度资深科学家、创立智铀科技的夏粉博士在创业家的APP中提到:该APP面向的用户是创业者和相关投资人。在这个场景下,内容方面目标是用户个性化推荐。最关键的是用户和文章找到最好的匹配。用户侧的信息会有:使用习惯(苹果还是安卓系统)、消费属性(是否注册,绑定银行卡)、兴趣特征(喜欢哪一个类别的文章)、自然属性(性、年龄)、社会属性。文章是基本属性、内容属性、运营属性、用户参与。
决策树
- 决策树也是分类的有监督学习, 他与逻辑回归不同的是, 决策树的特征一般是散列的值, 不是连续的, 如果是连续的则使用二分法将其散列
- 策树与逻辑回归的分类区别也在于此,逻辑回归是将所有特征变换为概率后,通过大于某一概率阈值的划分为一类,小于某一概率阈值的为另一类;而决策树是对每一个特征做一个划分。另外逻辑回归只能找到线性分割(输入特征x与logit之间是线性的,除非对x进行多维映射),而决策树可以找到非线性分割。
- 遍历所有的特征计算出熵值最小的那个特征, 将该特征作为一个节点, 并且还有预剪枝, 函数为h(x) = pi * log(pi)就和, 函数图像类似一个倒过来的抛物线, 0和1为0, 0.5取最大值, 这里的有一个信息增益的概念, 就是新得到的熵值与原来的熵值的减小的量
- 决策树生成时用到的算法
ID3算法就是对各个feature信息计算信息增益,然后选择信息增益最大的feature作为决策点将数据分成两部分
Python代码实现思路:
这里这将tree的实现:
采用map的性质{"node": {}}表示, 一个的key表示一个node, 从左到右是信息增益由大到小, 树是在特征节点处理完才将数据样本填上的
说白了和数据结构学习的二叉树是一样的, left, right, data, 只不过这里的data是DataFrame对象罢了
- 遇到决策树, 一般我们需要考虑到预剪纸, 考虑到max_features(节点的个数), max_depth(决策树的深度)等构建决策树的参数, 选择最优的, 但是如果一个一个自己实现过于繁琐, sklearn.grid_search提供了GridSearchCV函数, 我们指明分类器(决策树), param_grids(就是需要对决策树优化的参数, 是dict和value为list), cv指明划分成几个, 返回一个封装了优化函数的GridSerachCV对象
- 对于随机森林, 多了一个需要优化的参数, 就是n_estimators(决策树的个数)
- cv_scores = cross_val_score(decision_tree_classifier, all_inputs, all_classes, cv=10)当我们自己知道max_depth等值时就可以函数, 返回每一个K-CV情况的精度
grid.fit():运行网格搜索
grid_scores_:给出不同参数情况下的评价结果
best_params_:描述了已取得最佳结果的参数的组合
best_score_:成员提供优化过程期间观察到的最好的评分
从别的地方copy过来的
1、sklearn基础介绍
1.1、估计器(Estimator)
估计器很多时候可以直接理解为分类器,主要包含两个函数:
fit():训练算法,接收训练集和类别两个输入参数。
predict():预测测试集类别,接收测试集作为输入。
大多数sklearn的输入和输出的数据格式均为numpy格式或类似格式。
1.2、转换器(Transformer)
用于数据的预处理和数据转换,主要包含3个函数:
fit():训练算法。
transform():用于数据转换。
fit_transform():合并fit()和transform()两个函数的功能
1.3、流水线(Pipeline)
流水线的功能主要有3个:
一是跟踪记录各步骤的操作,以便重现实现结果;
二是对各操作步骤进行封闭;
三是使代码的复杂程度不至于超出掌控的范围。
基本的使用方法:
流水线的输入为一连窜的数据挖掘步骤(装在列表中),前几步通过为转换器,但最后一步必须为估计器。输入的数据集经过转换器的处理后,其输出作为下一步的输入,最后经过估计器对数据进行分类。每一步都用元组(名称,函数)来表示。
下面来创建流水线。
scaling_pipeline=Pipeline([('scale',MinMaxScaler()),('predict',KNeighborsClassifier())])
1
上面的这个例子中包含两个步骤,每个步骤都放在元组内,元组的第一个元素即为该步骤的名称,随便取便于理解功能即可,第二个元素为sklearn中实现相应功能的函数,很多时候直接看函数名便可猜到大致的功能。
1.4、预处理(Preprocessing)
主要在sklearn.preprocessing包下。这里的预处理都是针对特征值来操作的。具体功能如下:
规范化:
MinMaxScaler():将特征值缩放至0~1之间,公式(xi−min(x))/(max(x)−min(x))
Normalizer():通过缩放使特征值的和为1,公式xi/sum(x)
StandScaler():通过缩放使特征值的均值为0,方差为1,即为通常意义上的标准化,公式(xi−mean(x))/std(xi−mean(x))
编码:是特征工程的一部分
LabelEncoder:将字符串类型的数据转换为整形
OneHotEncoder:用二进制数来表示特征
Binarizer:将数值型特征二值化
MultiLabelBinarizer:多标签二值化
1.5、特征
1.5.1特征抽取
通过包sklearn.feature_extraction来实现
特征抽取是数据挖掘非常重要的一环,对最终结果的影响要高过数据挖掘算法本身。只有将现实事件用合适的特征表示出来,才能借助数据挖掘的力量找到其他的规律。特征抽取也可以降低事情的复杂程度。
一般最常用的特征抽取技术都是高度针对特定领域的。如图像处理领域,提出了很多特征抽取技术,但是这些技术在其他领域的应用却非常有限。
DictVectorizer():将dict类型的list数据转换为numpy array
FeatureHasher():将特征哈希,将数据做哈希映射,同时能达到降维的效果
image():图像相关的特征抽取
text():文本相关的特征抽取
text.CountVectorizer():将文本转换为每个词出现个数的向量
text.TfidfVectorizer():将文本转换为逆文本词频向量
text.HashingVectorizer():将文本作哈希向量化
1.5.2、特征选择
包:sklearn.feature_selection
特征选择的原因:
(1)降低数据复杂度
(2)降低噪声
(3)增强数据的可解释性
VarianceThreshold():删除方差达不到最低标准的特征
SelectKBest():返回K个最佳特征
SelectPercentile():返回表现最佳的前r%个特征
单个特征和某一类型特征之间相关性的计算方法有很多,如x2,其他的方法还有互信息和信息熵
**chi2():卡方检验
1.6、降维
包:sklearn.decomposition
算法的采用的是主成分降维(PCA)
1.7、组合
包:sklearn.ensemble
ensemble下的算法均为组合算法,组合技术也就是通过聚合多个分类器的结果来提高分类等预测的准确率。
常用的组合分类器有下面3种处理方式:
(1)通过随机抽取部分样本,组成多个训练集,得到多个模型,从而同一个样本有多个预测结果,从中得到最后的预测结果,从而提高预测准确性,如bagging和boosting。
(2)通过随机抽取部分特征,从而构成多个新的训练集,得到多个模型,从而可以对一个样本进行多次预测,采用少数服从多数的原则,得到最后的预测结果。随机森林则是综合了(1)、(2)两种处理方方法。
(3)通过对标签进行处理,适用于多分类的情况,将标号随机分成两个不相交的子集,把问题变成二分类问题,每一次都会得到一个预测结果,,重复构建多次模型,进行分类投票。
有以下的组合方法:
BaggingClassifier:
BaggingRegressor:
AdaBoostClassifier:
AdaBoostRegressor:
GradientBoostingClassifier:
GradientBoostingRegressor:
ExtraTreeClassifier:
ExtraTreeRegressor:
RandomTreeClassifier:
RandomTreeRegressor:
举例:
AdaBoostClassifier(DecisionTreeClassifier(max_depth=1),algorithm="SAMME",n_estimators=200)
1
从上例可以看到,AdaBoostClassifier是一种处理方式,但还需要指明与之配合的基础分类算法。
1.8、模型评估
包:sklearn.metrics
包含评分方法、性能度量、成对度量和距离计算
分类结果度量
输入大多为y_true,y_pred
具体评价指标如下:
accuracy_score:分类准确度
condution_matrix:分类混淆矩阵
classification_report:分类报告
precision_recall_fscore_support:计算精确度、召回率、f、支持度
jaccard_similarity_score:计算jaccard相似度
hamming_loss:计算汉明损失
zero_one_loss:计算0-1损失
hinge_loss:计算hinge损失
log_loss:计算log损失
回归结果度量
explained_variance_score:可解释方差的回归评分
mean_absolute_error:平均绝对误差
mean_squared_erro均方误差
聚类结果度量
adjusted_mutual_info_score:调整的互信息得分
silhouette_score:所有样本轮廓系数的平均值
silhouette_sample:所有样本轮廓系数
多标签的度量
coverage_error:涵盖误差
label_ranking_average_precision_score:基于排名的平均精度
1.9、交叉验证
包:sklearn.cross_validation
KFold():交叉验证迭代器,接收元素个数、fold数、是否清洗
LeaveOneOut():交叉验证迭代器
LeavePOut():交叉验证迭代器
LeaveOneLableOut():交叉验证迭代器
LeavePLableOut():交叉验证迭代器
交叉验证是利用训练集本身来测试模型精度,思路是将训练集分成n份,然后按一定比例取其中的几份(大头)作为真正的训练集来训练模型,其中的几份(少数)不参与训练来验证模型精度。然后循环这个过程,得到多组测试精度。所以在交叉验证器里就涉及到抽取测试集的比例问题。
LeaveOneOut()就是从n份里抽1份作为测试集,LeavePOut()就是从n份里抽p份作为测试集。
LeaveOneOut(n) 相当于 KFold(1, n_folds=n) 相当于LeavePOut(n, p=1)。
而LeaveOneLableOut()和LeavePLableOut()与上面的区别在于,这里可以直接加入第三方的标签作为数据集的区分,也就是第三方标签已经把数据分成n份了。们的数据是一些季度的数据。那么很自然的一个想法就是把1,2,3个季度的数据当做训练集,第4个季度的数据当做测试集。这个时候只要输入每个样本对应的季度Label,就可以实现这样的功能。
常用方法:
train_test_split:分离训练集和测试集,这一步一般是在交叉验证前做的,与KFold()不同
cross_val_score:交叉验证得分即精度,为一组数据,存放于列表中
cross_val_predict:交叉验证的预测结果
1.10、网络搜索
包:sklearn.grid_search
网络搜索是用来寻找最佳参数的。
GridSearchCV:搜索指定参数网格中的最佳参数
ParameterGrid:参数网络
ParameterSampler:用给定分布生成参数的生成器
RandomizedSearchCV:超参的随机搜索
通过best_estimator_get_params()方法获取最佳参数
1.11、多分类、多标签分类
包:sklearn.multiclass
OneVsRestClassifier: 1-rest多分类(多标签)策略
OneVsOneClassifier: 1-1多分类策略
OutputCodeClassifier: 1个类用一个二进制码表示
在多标签的情况下,输入必须是二值化的。所以需要MultiLabelBinarizer()先处理。
2、scikit-learn扩展
2.1 概览
具体的扩展,通常要继承sklearn.base包下的类。
BaseEstimator: 估计器的基类
ClassifierMixin :分类器的混合类
ClusterMixin:聚类器的混合类
RegressorMixin :回归器的混合类
TransformerMixin :转换器的混合类
2.2 创建自己的转换器
在特征抽取的时候,经常会发现自己的一些数据预处理的方法,sklearn里可能没有实现,但若直接在数据上改,又容易将代码弄得混乱,难以重现实验。这个时候最好自己创建一个转换器,在后面将这个转换器放到pipeline里,统一管理。
例如《Python数据挖掘入门与实战》书中的例子,我们想接收一个numpy数组,根据其均值将其离散化,任何高于均值的特征值替换为1,小于或等于均值的替换为0。
from sklearn.base import TransformerMixin
from sklearn.utils import as_float_array
class MeanDiscrete(TransformerMixin):
#计算出数据集的均值,用内部变量保存该值。
def fit(self, X, y=None):
X = as_float_array(X)
self.mean = np.mean(X, axis=0)
#返回self,确保在转换器中能够进行链式调用(例如调用transformer.fit(X).transform(X))
return self
def transform(self, X):
X = as_float_array(X)
assert X.shape[1] == self.mean.shape[0]
return X > self.mean
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
3、使用sklearn数据挖掘一般流程
3.1、加载数据
sklearn的实现使用了numpy的arrays,所以需要使用numpy来读入数据。
# -*- coding: utf-8 -*-
import numpy as np
import urllib.request
#直接从网络上读取数据,该数据有767个样本,每个样本有9列,最后一列为标签列
url="http://archive.ics.uci.edu/ml/machine-learning-databases/pima-indians-diabetes/pima-indians-diabetes.data"
rawdata=urllib.request.urlopen(url)
#利用numpy.loadtxt从网络地址上读数据
dataset=np.loadtxt(rawdata,delimiter=',')#也可以先将数据下载到本地,然后从本地路径上下载数据,只要将rawdata换成本地路径就可以了
X=dataset[:,0:8]
y=dataset[:,8]
1
2
3
4
5
6
7
8
9
10
11
3.2、数据预处理
大多数机器学习算法中的梯度方法对于数据的缩放和尺度都是很敏感的,在开始跑算法之前,我们应该进行归一化或者标准化的过程,这使得特征数据缩放到0-1范围中,归一化的方法,具体解释参考。
归一化(Normalization)
针对样本,例如
from sklearn import preprocessing
normalized_X=preprocessing.normalize(X)
1
2
尺度缩放(Scaling)
针对变量,如
scaled_X=preprocessing.scale(X)
1
标准化(Standardization)
standardized_X=preprocessing.StandardScaler(X)
1
3.3、特征工程
3.4、模型训练
以逻辑回归为例
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
model=LogisticRegression()
model.fit(X,y)
print("模型:")
print(model)
expected=y
predicted=model.predict(X)
print("结果报告 :")
print(metrics.classification_report(expected,predicted))
print("混淆矩阵:")
print(metrics.confusion_matrix(expected,predicted))
1
2
3
4
5
6
7
8
9
10
11
12
结果如下:
模型:
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)
结果报告 :
precision recall f1-score support
0.0 0.79 0.90 0.84 500
1.0 0.74 0.55 0.63 268
avg / total 0.77 0.77 0.77 768
混淆矩阵:
[[448 52]
[121 147]]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
3.5、算法参数优化
具体参考官方文档
整体思路是,将需要搜索最优参数的一系列候选值赋给一个数组,然后用参数搜索接口如GridSearchCV去训练,而不是直接用算法去训练,这些搜索接口接受具体的算法和候选参数作为输入。返回的结果中就包含了最佳得分和最佳参数。
不同的算法涉及的参数是不一样的,以后有时间再慢慢写。
集成算法
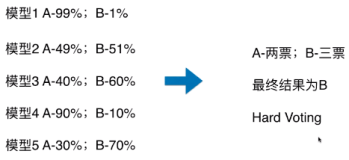
- 目的: 让机器学习效果更好, 单个不行, 并行
- Bagging: 训练多个分类器取平均值, 并行的, 随机的有放回的拿样本
- Boosting(依赖于前一个, 通过加权(随机权重)进行训练): 串行的, AdaBoost: 根据前一次的分类效果调整数据权重, 如果分类错了, 增大权重, train了在test了都, 根据分类器(Adaboost有多个分类器组成)的权重向得出结果, 为什么是串行的? 首先Boosting算法是针对所有的样本的, 一次训练得出一个分类器, 评估时得出精度和误差, 从而确定该分类器在最终结果的权重, 样本在第一次有初始权重, 在训练时和评估时会根据误差更新权重, 这两个权重是后面分类器的前提, 所以是串行的
- Xgboost:
- Stacking: 将各种分类器用上, 分两个阶段, 对于一组特征, 对数据进行划分, 有各个分类器分别得出结果, 第二阶段, 将各个分类器的结果当做特征再放到另一个分类器中
数据预处理
通过特征提取,我们能得到未经处理的特征,这时的特征可能有以下问题:
不属于同一量纲:即特征的规格不一样,不能够放在一起比较。无量纲化可以解决这一问题。
信息冗余:对于某些定量特征,其包含的有效信息为区间划分,例如学习成绩,假若只关心“及格”或不“及格”,那么需要将定量的考分,转换成“1”和“0”表示及格和未及格。二值化可以解决这一问题。
定性特征不能直接使用:某些机器学习算法和模型只能接受定量特征的输入,那么需要将定性特征转换为定量特征。最简单的方式是为每一种定性值指定一个定量值,但是这种方式过于灵活,增加了调参的工作。通常使用哑编码的方式将定性特征转换为定量特征:假设有N种定性值,则将这一个特征扩展为N种特征,当原始特征值为第i种定性值时,第i个扩展特征赋值为1,其他扩展特征赋值为0。哑编码的方式相比直接指定的方式,不用增加调参的工作,对于线性模型来说,使用哑编码后的特征可达到非线性的效果。
存在缺失值:缺失值需要补充。
信息利用率低:不同的机器学习算法和模型对数据中信息的利用是不同的,之前提到在线性模型中,使用对定性特征哑编码可以达到非线性的效果。类似地,对定量变量多项式化,或者进行其他的转换,都能达到非线性的效果。
贝叶斯算法
数据降维(LDA(有监督)与PDA(无监督))
LDA
PDA
- 就是找基坐标和方差
- 为了防止两个特征线性无关, 采用协方差, 让协方差为0(cos(theta) == 0)
- 第一个基轴为方差最大的, 其他后来添加的基坐标要保证与已经存在的基坐标的协方差为0(就是垂直)并且方差尽可能大
过程
- 对每一个样本进行均值=0
- 协方差矩阵
- 特征值
- 对角化
- 降维