1.文档编写目的
Fayson在前面的文章中介绍了《如何在CDH中使用Solr对HDFS中的JSON数据建立全文索引》和《如何使用Flume准实时建立Solr的全文索引》,假如我们有大量的文本文件,我们应该如何保存到Hadoop中,并实现文本文件的全文检索呢。为了介绍如何对文本文件进行全文检索,本文会先介绍如何使用HBase保存文本文件。虽然HDFS中也可以直接保存这种非结构化数据,但是我们知道像这种文本文件,一般都是10KB~1MB的小文件,因为HDFS并不擅长存储大量小文件,所以这里选择HBase来保存。
内容概述
1.文件处理流程
2.准备上传文件的Java代码
3.运行代码
4.Hue中查询验证
测试环境
1.RedHat7.4
2.CM5.14.3
3.CDH5.14.2
4.集群未启用Kerberos
2.文件处理流程
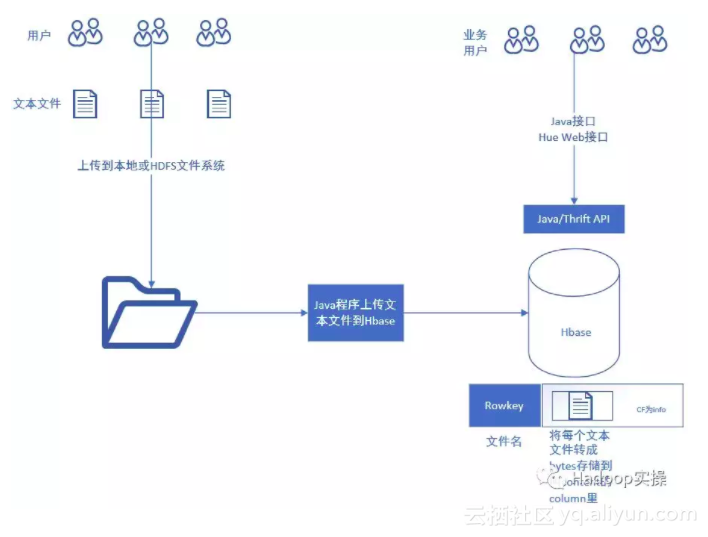
1.如上图所示,Fayson先在本地准备了一堆记事本文件,有中文内容的,英文内容的,有中文名的,也有英文名的。
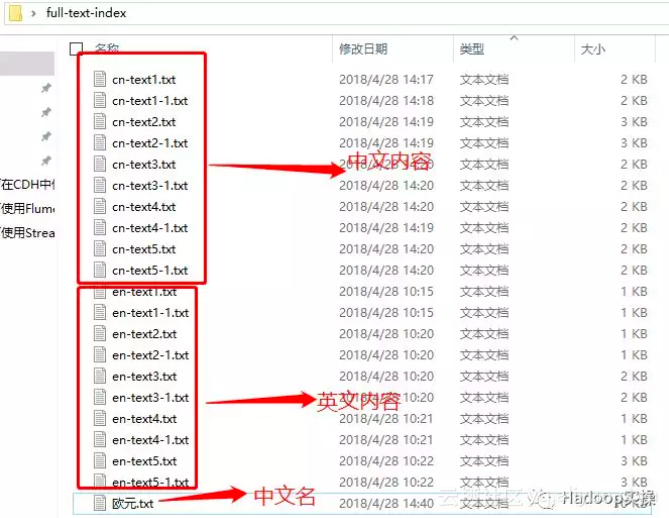
中文内容示例


2.然后通过Java程序遍历本地的文件夹所有文本文件入库到HBase,在入库过程中,我们读取文本文件的文件名作为Rowkey,另外将整个文本内容转为bytes存储在HBase表的一个column里。
3.最后可以通过Hue来进行查看文本文件的内容,当然你也可以考虑对接到你自己的查询系统。
3.准备上传文件的Java代码
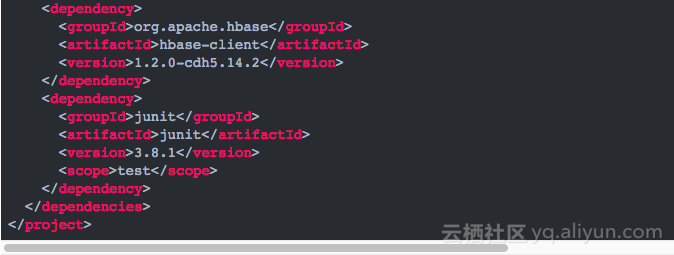
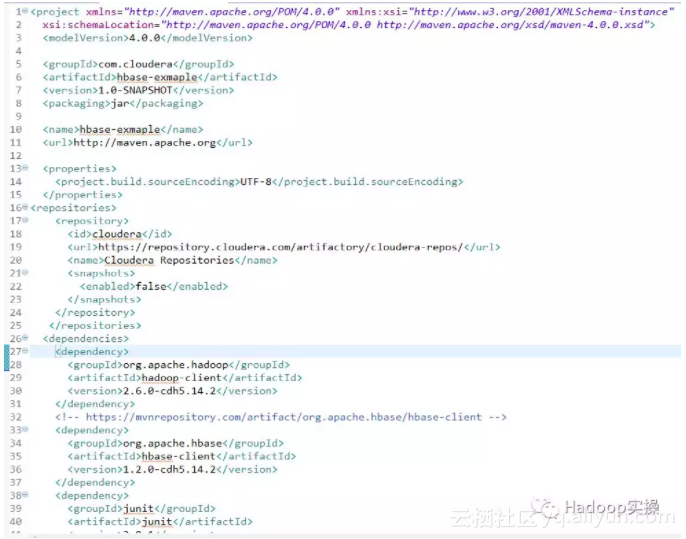
1.首先是准备Maven文件
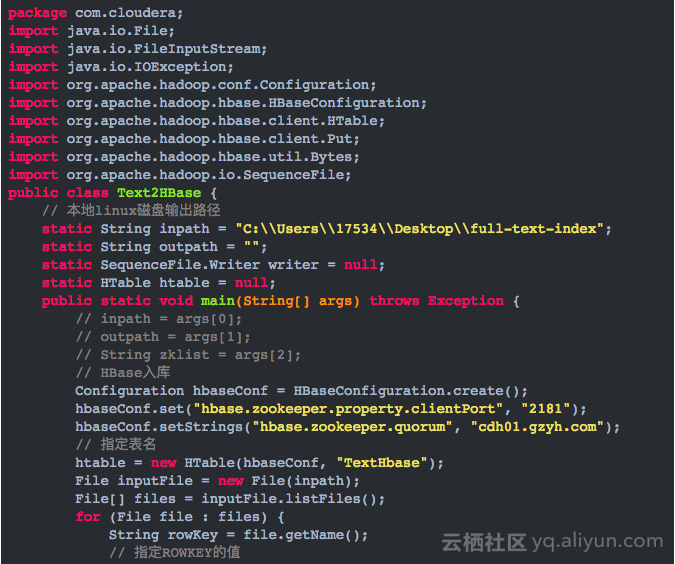
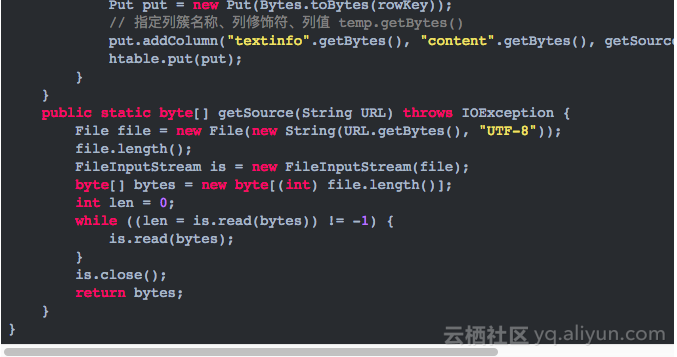
2.准备上传文件到HBase的Java代码
2.准备上传文件到HBase的Java代码
2.准备上传文件到HBase的Java代码
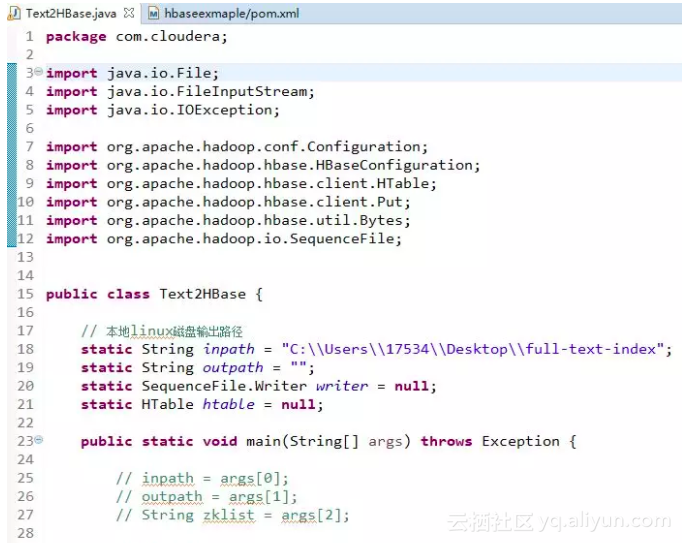
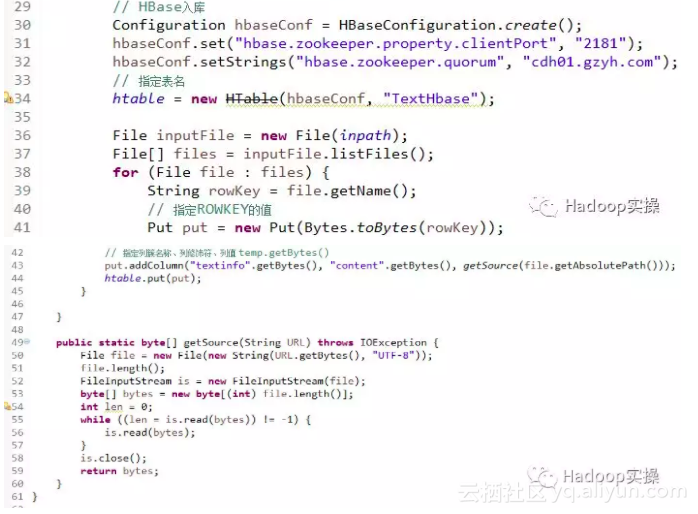
4.运行代码
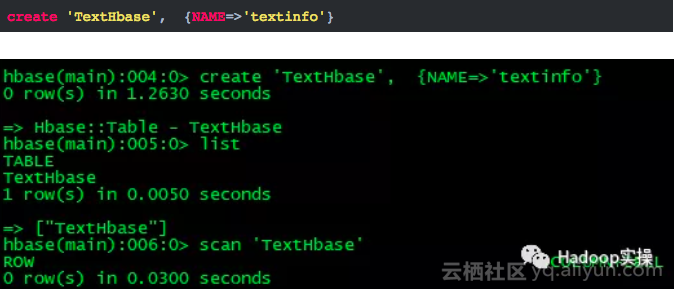
1.首先我们在HBase中建一张表用来保存文本文件
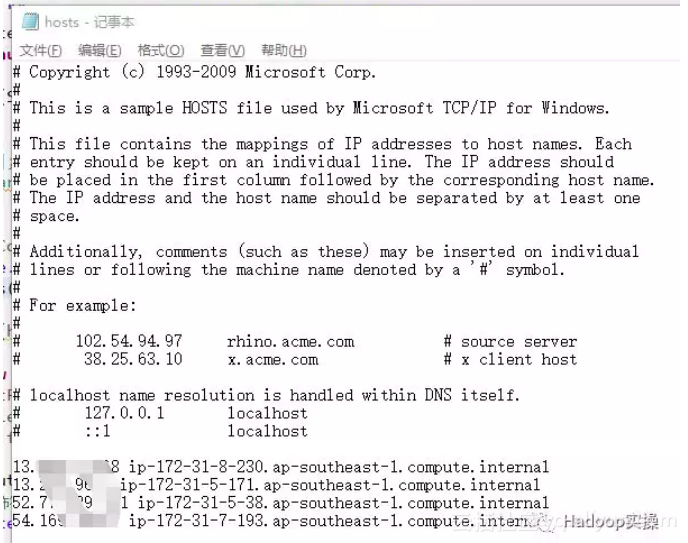
2.配置客户端Windows机器的hosts文件
3.注意修改代码中的配置项,如文本文件所在的目录,集群的Zookeeper地址等。Fayson这里为了使用方便,就不打成jar包到集群运行,直接在Eclipse里运行代码。
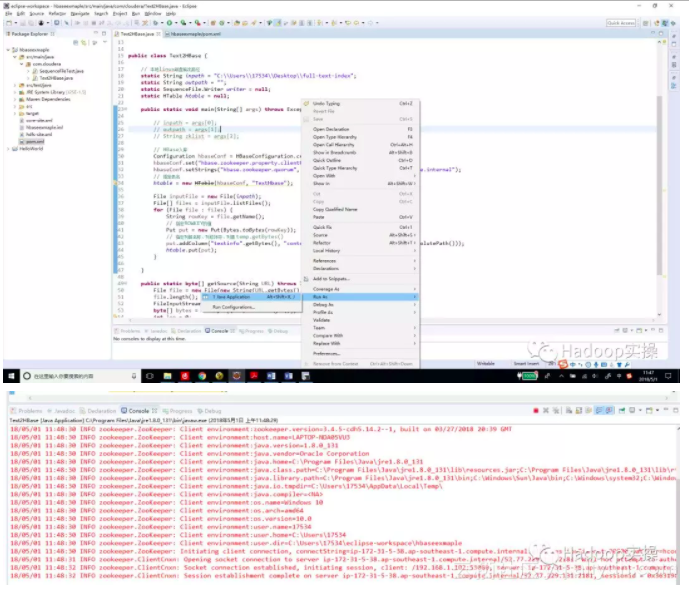
4.到HBase中进行查询确认
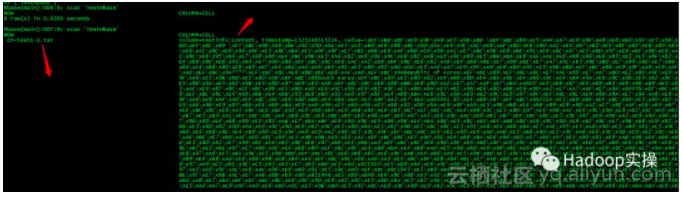
一共21条,表明全部入库成功
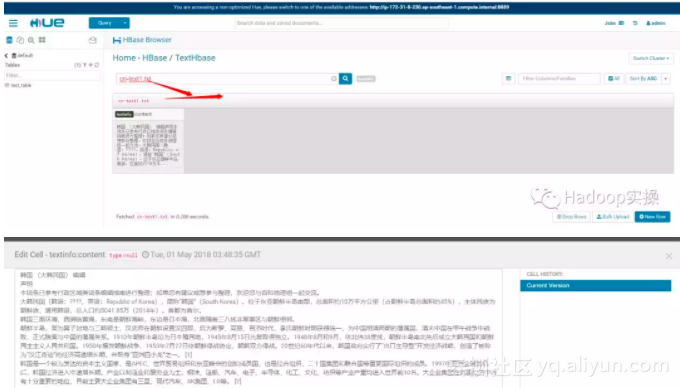
5.Hue中查询验证
1.从Hue中进入HBase的模块
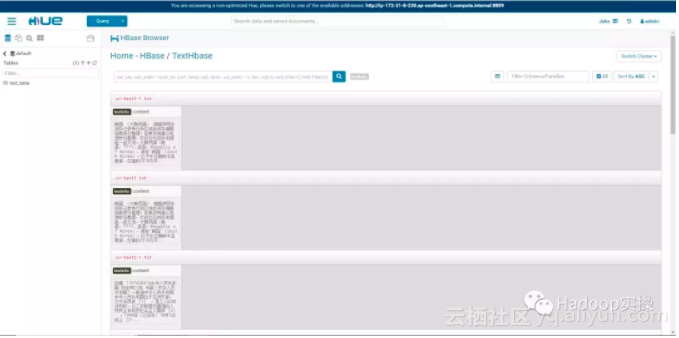
单击某个column,可以查看整个文本内容

2.查询某一个Rowkey进行测试
本文所使用的代码源码GitHub地址:
https://github.com/fayson/cdhproject/blob/master/hbasedemo/src/main/java/com/cloudera/hbase/Text2HBase.java
https://github.com/fayson/cdhproject/tree/master/hbasedemo/full-text-index
![]()
大家工作学习遇到HBase技术问题,把问题发布到HBase技术社区论坛http://hbase.group,欢迎大家论坛上面提问留言讨论。想了解更多HBase技术关注HBase技术社区公众号(微信号:hbasegroup),非常欢迎大家积极投稿。

HBase技术交流社区 - 阿里官方“HBase生态+Spark社区大群”点击加入:https://dwz.cn/Fvqv066s