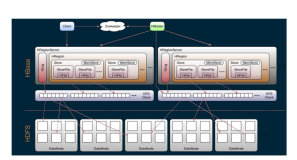
1.文档编写目的
HBase是一款基于Hadoop的Key-Value数据库,提供了对HDFS上数据的高效随机读写服务,填补了Hadoop MapReduce批处理的缺陷,但HBase作为列簇数据库无法轻易的建立“二级索引”、难以执行求和、计数、排序等操作。在HBase0.96版本后引入了协处理器(Coprocessor),用户可以编写运行在HBase Server端的代码。HBase支持两种类型的协处理器,Endpoint和Observer。
Endpoint协处理器类似传统数据库中的存储过程,客户端可以调用这些Endpoint协处理器执行一段Server端代码,并将Server端代码的结果返回给客户端处理。
Observer Coprocessor,这中协处理器类似于传统数据库中的触发器,当发生某些事件的时候,Observer协处理器会被Server端调用。
本篇文章先不介绍如何去开发协处理器,主要借助于HBase示例中自带的RowCount Endpoint协处理器来说明如何使用Java代码在客户端调用。在后面的文章Fayson会介绍如何去编写一个协处理器。
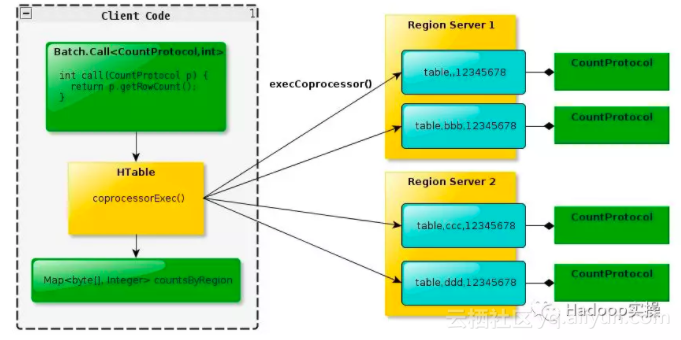
Endpoint Coprocessor客户端调用过程,如下图所示:
-
内容概述
1.环境准备
2.编写Java示例代码及运行
3.统计方式对比
-
测试环境
1.CM和CDH版本为5.14.3
2.环境准备
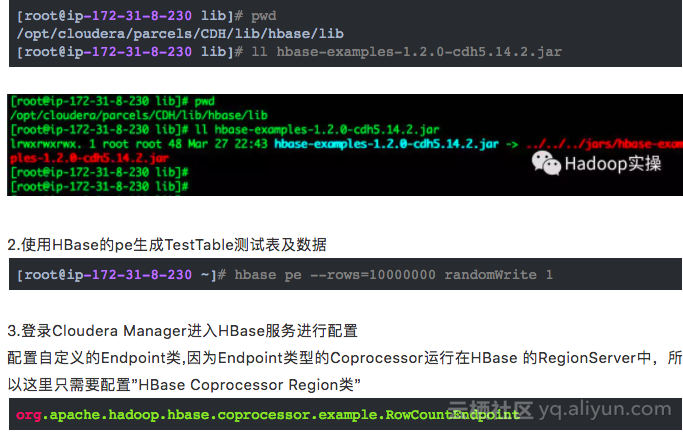
HBase中自带的Endpoint的协处理器,在hbase-examples.jar包中,在CDH的/opt/cloudera/parcels/CDH/lib/hbase/lib目录下,如下图所示:
1.确认hbase-examples-1.2.0-cdh5.14.2.jar是否在
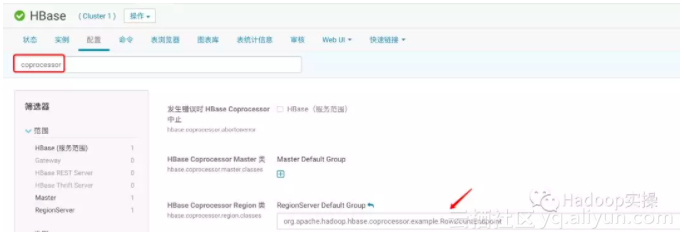
注意:在这里的配置为全局配置,协处理器有两种使用方式上图的方式是其中的一种,另外一种则是对单个表进行修改。
3.编写Java示例
1.创建HBase的Maven工程
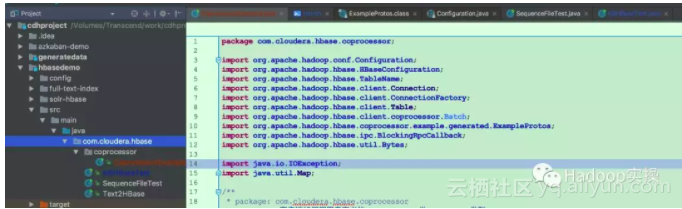
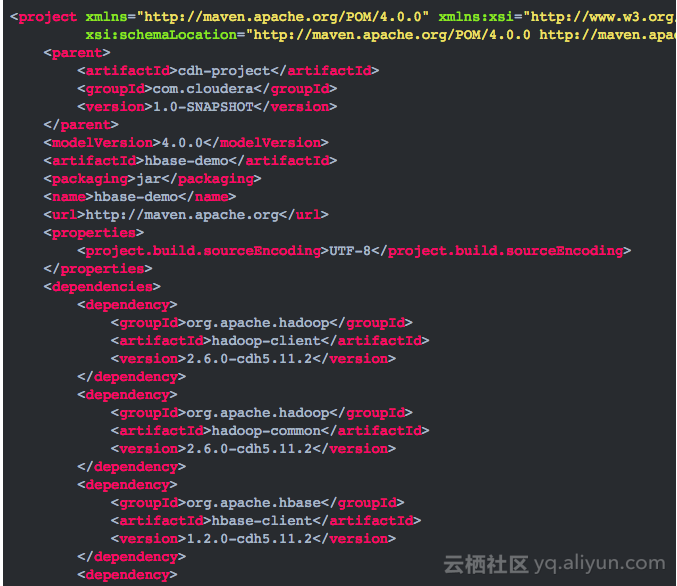
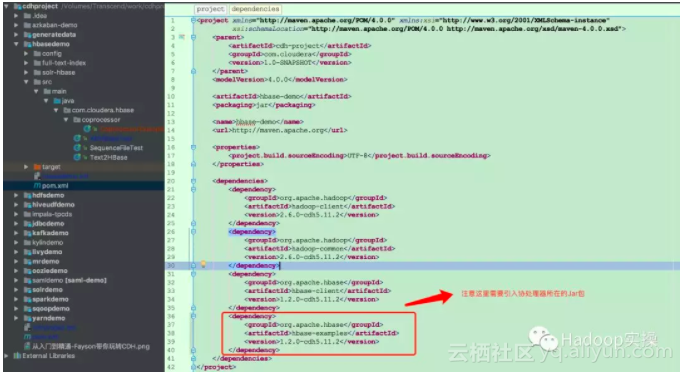
2.工程的pom.xml文件内容如下

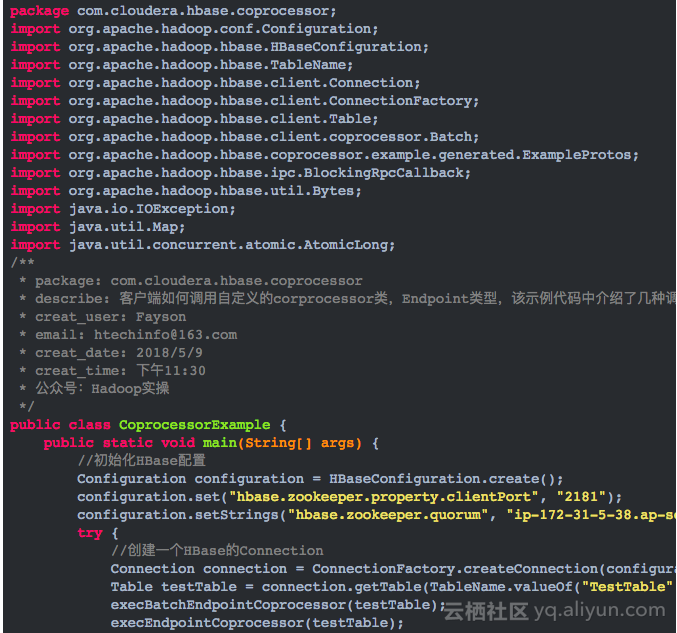
3.编写CoprocessorExample.java类,内容如下
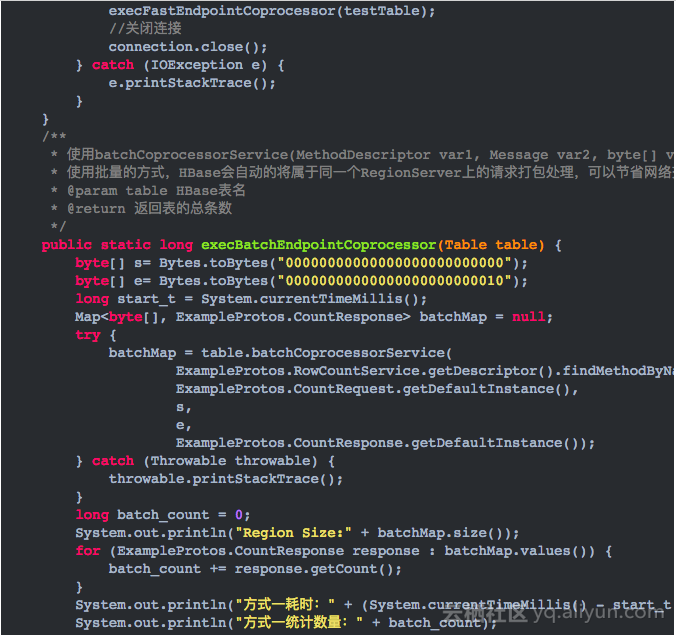
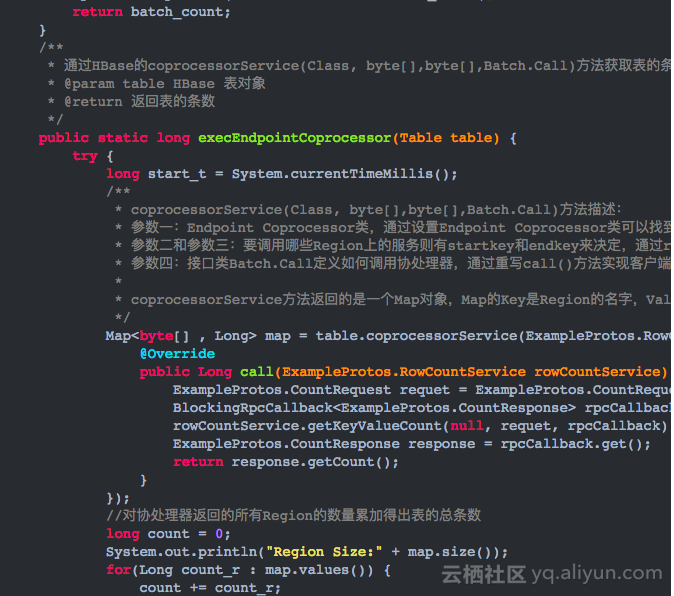
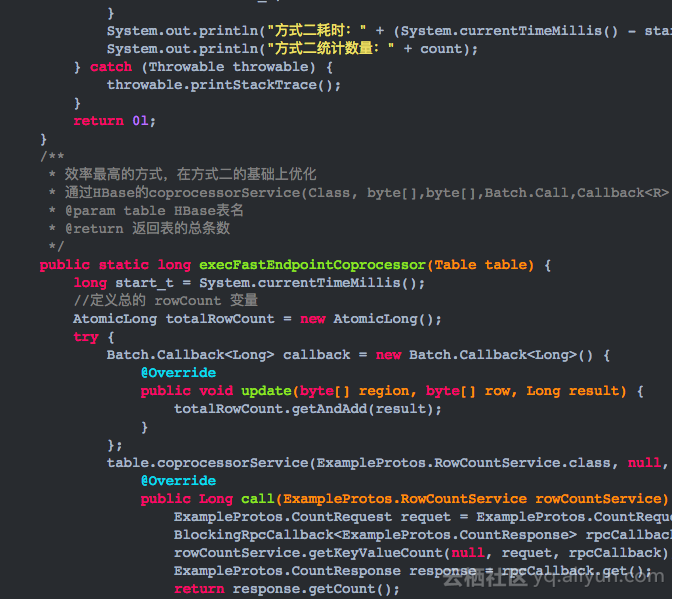
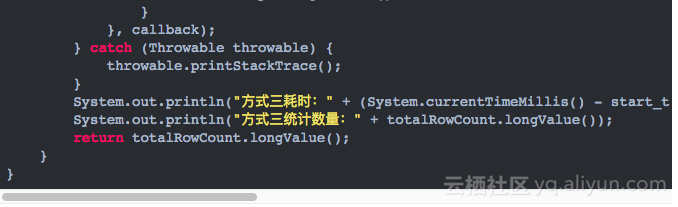
4.示例代码运行
4.HBase表统计效率对比
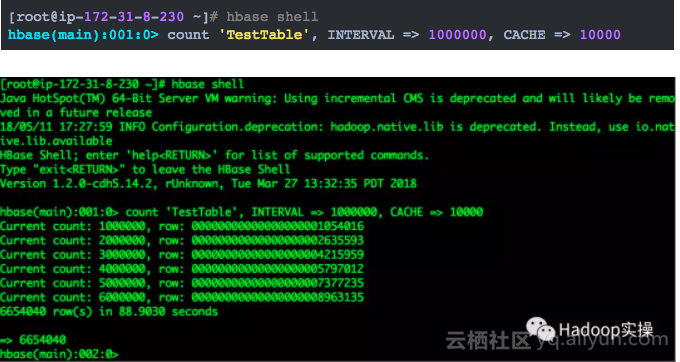
1.使用HBase的count来统计测试表的总条数
2.使用HBase提供的MapReduce方式统计测试表的总条数
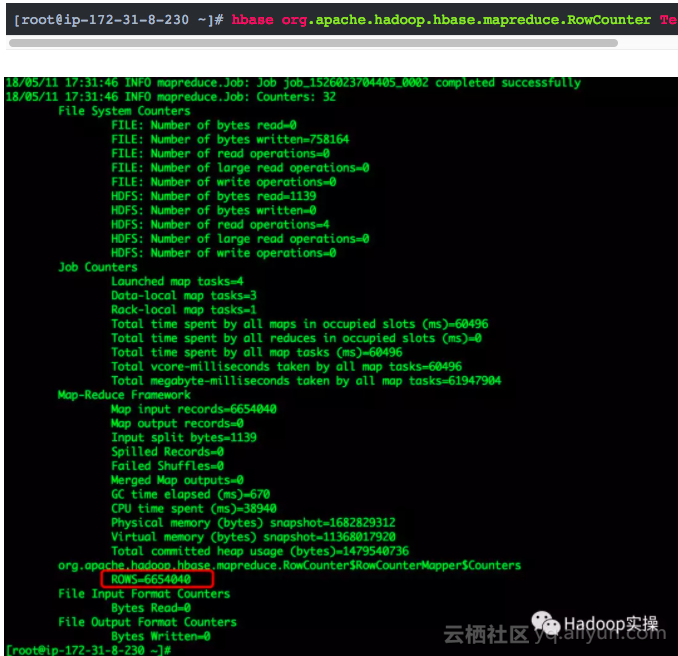
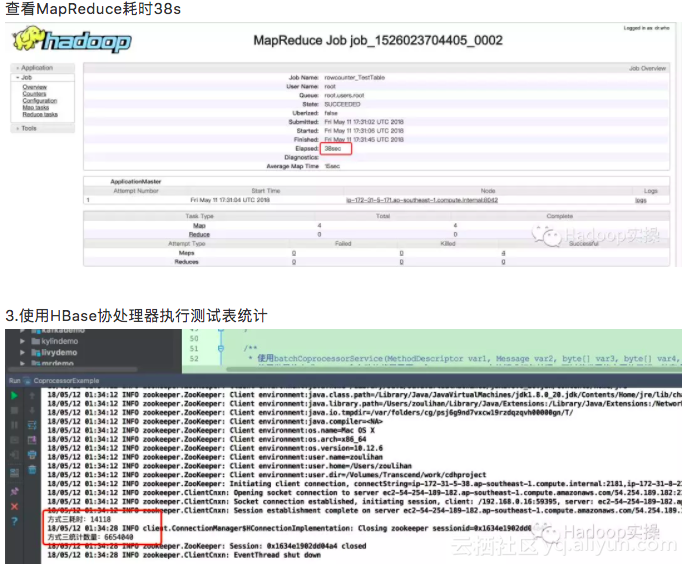
执行耗时:14.12s
耗时统计:

5.总结
-
在使用HBase的coprocessor方法是如果传入startkey和endkey是会根据rowkey的访问检索出符合条件的region并统计每个region上数据量。
-
HBase的Endpoint Coprocessor协处理器可以通过CM的方式配置全局的也可以通过客户端或hbase shell的方式来指定某一个表使用比较灵活,在后面的文章Fayson会介绍如何指定单个表的方式。
GitHub地址:
https://github.com/fayson/cdhproject/blob/master/hbasedemo/src/main/java/com/cloudera/hbase/coprocessor/CoprocessorExample.java
![]()
大家工作学习遇到HBase技术问题,把问题发布到HBase技术社区论坛http://hbase.group,欢迎大家论坛上面提问留言讨论。想了解更多HBase技术关注HBase技术社区公众号(微信号:hbasegroup),非常欢迎大家积极投稿。

HBase技术交流社区 - 阿里官方“HBase生态+Spark社区大群”点击加入:https://dwz.cn/Fvqv066s