注册
DataHub作为一个流式数据总线,为阿里云数加平台提供了大数据的入口服务。结合阿里云众多云产品,可以构建一站式的数据处理平台。流计算通常使用DataHub作为流式数据存储头和输出目的端。
注意: DataHub在公有云使用需要用户授予实时计算代为用户访问DataHub权限,具体请参看流计算角色授权。否则可能出现报错“No Permission”的情况。
Endpoint
填写DataHub Endpoint
需要注意不同的地域下DataHub有不同的Project。当前DataHub仅支持杭州地域,为http://dh-cn-hangzhou.aliyun-inc.com。如需了解更多Endpoint相关信息,请您访问DataHub控制台。
注意:
http://dh-cn-hangzhou.aliyun-inc.com不要使用(/)结尾
VPC模式支持
当前DataHub不提供VPC模式,因此实时计算当前使用DataHub的经典网络地址(Endpoint)即可。
内外网选择
上述http://dh-cn-hangzhou.aliyun-inc.com是DataHub在阿里云内网地址。实时计算和DataHub实际上同处于阿里云内网,使用内网访问更加节省带宽。
有关专有云的Endpoint填写,请联系您的专有云系统管理员,咨询有关DataHub Endpoint地址。
Project填写
填写DataHub的Project。
注意:**跨属主的数据存储不能注册。例如A用户拥有DataHub的ProjectA,但B用户希望在流计算使用ProjectA,目前流计算暂不支持这类使用场景下注册,若需使用可使用明文方式,具体参考创建数据总线源表或创建数据总线结果表。
使用
由于DataHub本身是流数据存储,流计算只能将其作为流式数据输入和输出,无法作为维表引用。有关DataHub DDL定义,请参看具体章节。
常见问题
Q: 为什么我注册失败,失败原因提示XXX?
A: 实时计算的数据存储页面能够协助您完成数据管理,其本身就是使用相关存储SDK代为访问各类存储。因此很多情况下可能是您注册过程出现问题导致,请排查如下原因。
-
请确认是否已经开通并拥有DataHub的Project。请登录DataHub控制台,公有云客户可以访问DataHub控制台看您是否有权限访问您的Project。
-
请确认您是DataHub Project的属主。跨属主的数据存储不能注册。例如A用户拥有DataHub的ProjectA,但B用户希望在流计算使用ProjectA,目前流计算暂不支持这类使用场景下注册,若需使用可使用明文方式,具体参考创建数据总线源表或创建数据总线结果表。
-
请确认您填写的DataHub的Endpoint和Project完全正确。DataHub Endpoint必须以http开头,且不能以(/)结尾。例如,
http://dh-cn-hangzhou-internal.aliyuncs.com是正确的,但http://dh-cn-hangzhou-internal.aliyuncs.com/是错误的。 -
请确认您填写的DataHub Endpoint是经典网络地址,而非VPC地址。目前流计算暂不支持VPC内部地址。
-
请不要重复注册,实时计算提供注册检测机制,避免您重复注册。
Q: 为什么数据抽样仅仅针对时间抽样,不支持其他字段抽样?
A: DataHub定位是流数据存储,对外提供的接口也只有时间参数。因此,实时计算也只能提供基于时间的抽样。
附录
产品内网与公网选择
注意:本小节仅限于公共云场景,不包含专有云情况。
所谓的内网和公网是相对于阿里云集群来说。我们可以将阿里云计算视为一个跨地域的大型计算集群。集群内部之间的网络传输可以使用阿里云内网,这样可以有效地节省网络带宽成本。
例如,实时计算使用阿里云内部网络带宽访问RDS。
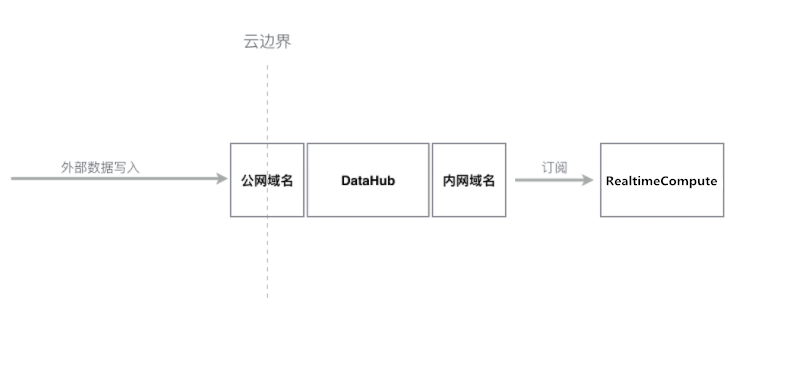
对于外部(例如Internet)网络请求阿里云服务,则需要使用公网地址。实时计算注册DataHub过程中,要求用户必须提供DataHub内网Endpoint地址。 但对于外部数据写入DataHub而言,则需要填写DataHub公网地址。如下图所示。
例如,在当前PC使用LogStash采集传输日志。
本文转自实时计算——大数据总线(DataHub)

