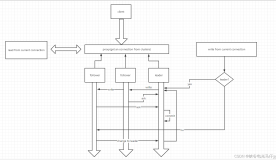
注册上下游存储操作步骤如下。
登录阿里云账号
注册上游存储
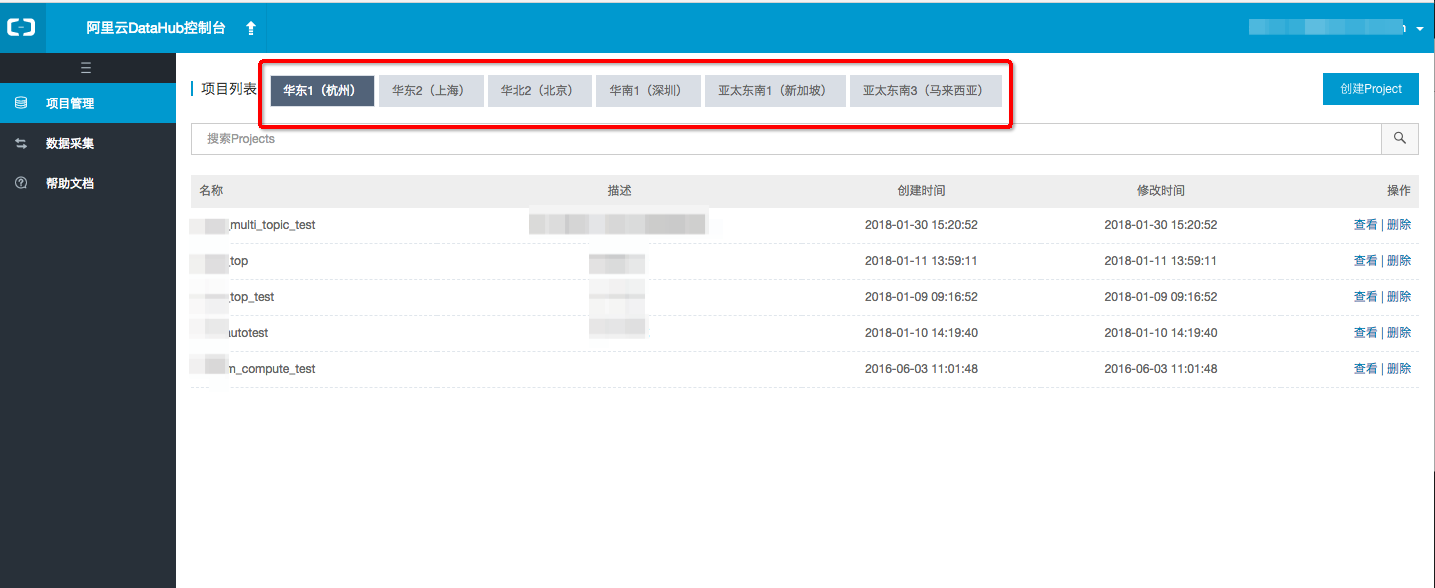
登录DataHub
登录DataHub控制台。
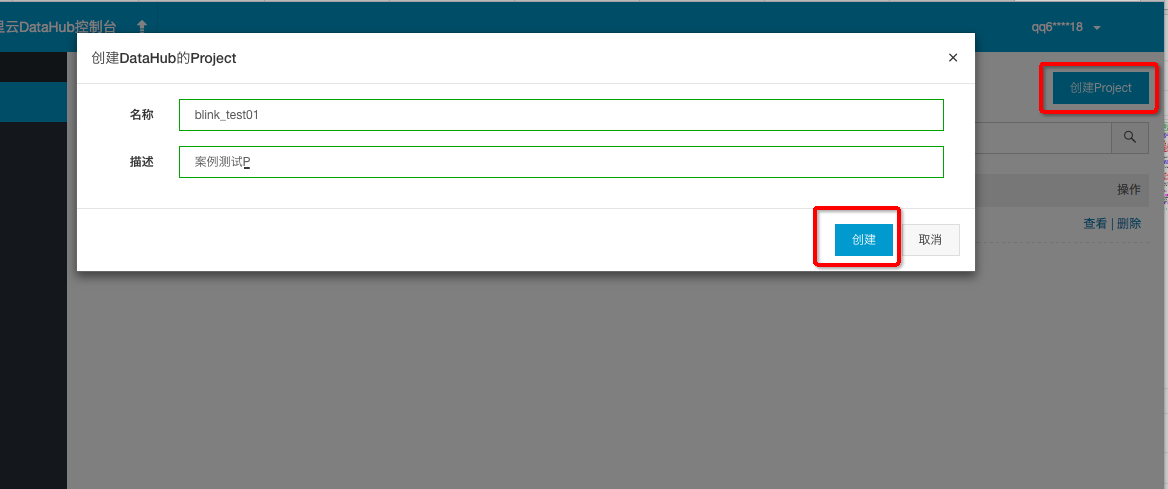
创建DataHub源表
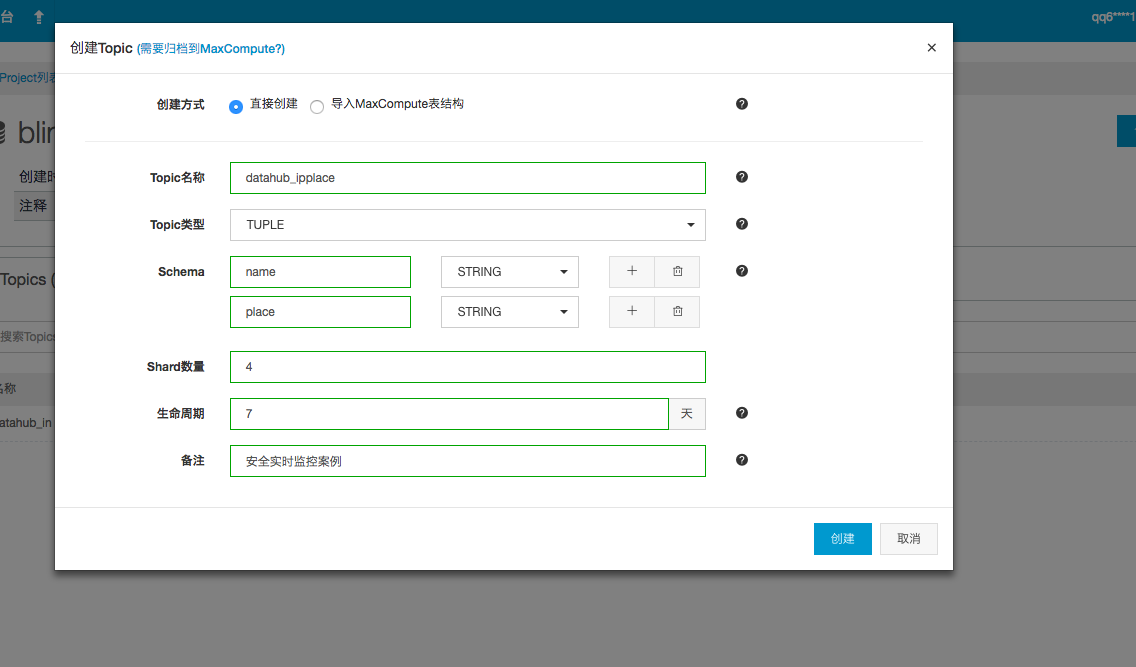
为简化问题,我们将源源不断的数据抽象简化为如下二维表。datahub_IpPlace
| 字段名 | 类型 | 注释 |
|---|---|---|
| name | varchar | 名字 |
| place | varchar | 地址 |
创建的schema示意图如下。
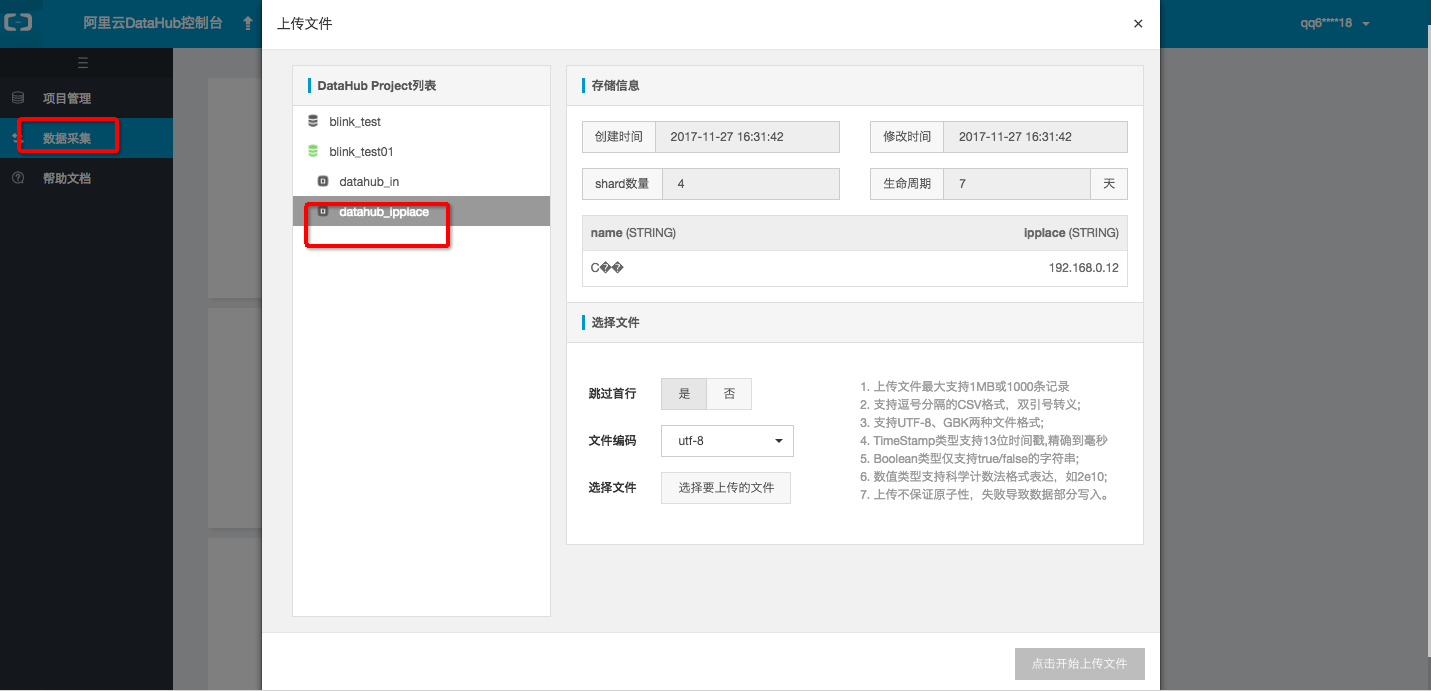
上传DataHub测试数据
为了方便用户测试作业我们提供测试数据,点击下载后利用DataHub的文件上传工具即可完成数据采集。
上传DATAHUB源表的数据。
注册下游存储
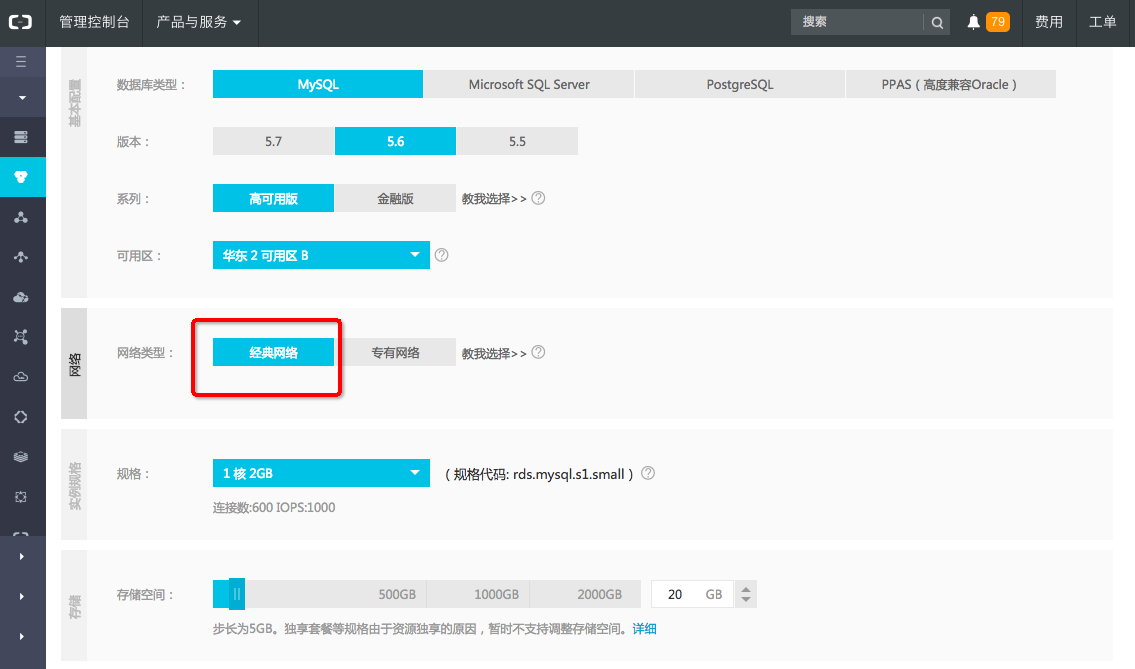
注册RDS
如果还没有RDS实例,请参阅RDS购买流程。
注意: 请选择经典网络进行测试。
创建数据库账号。
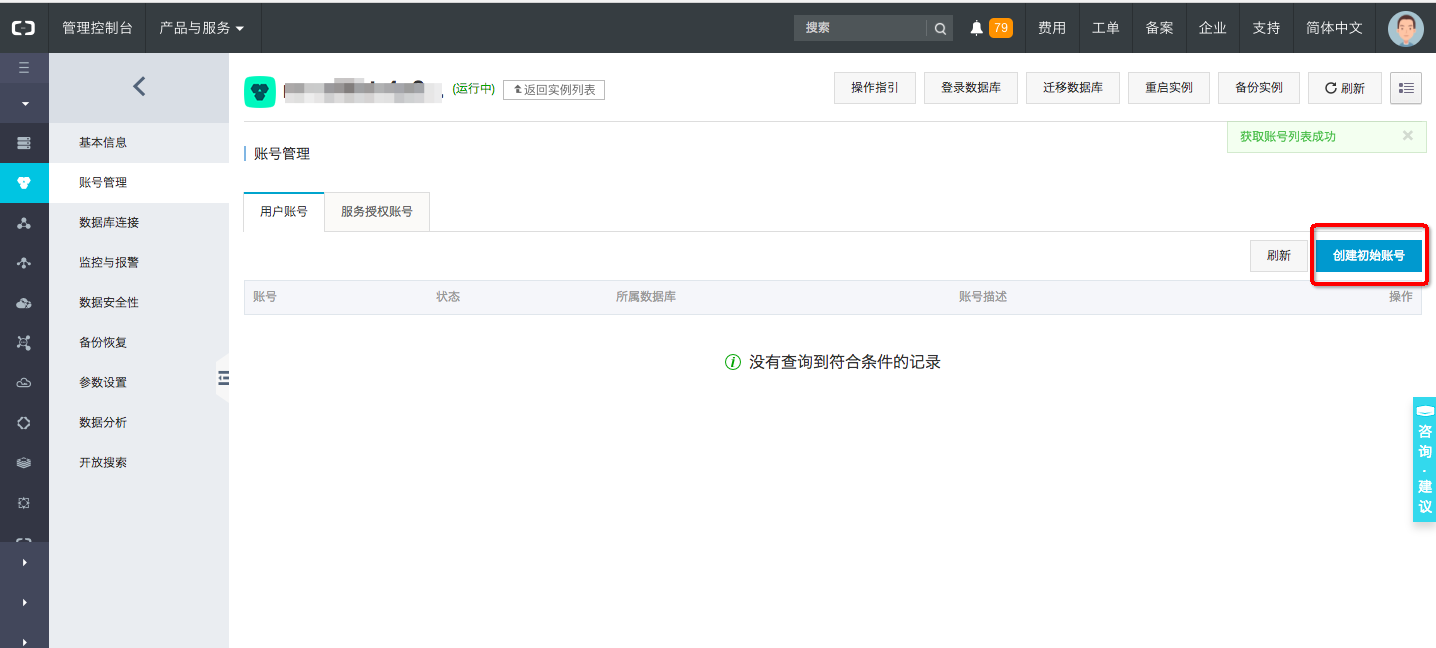

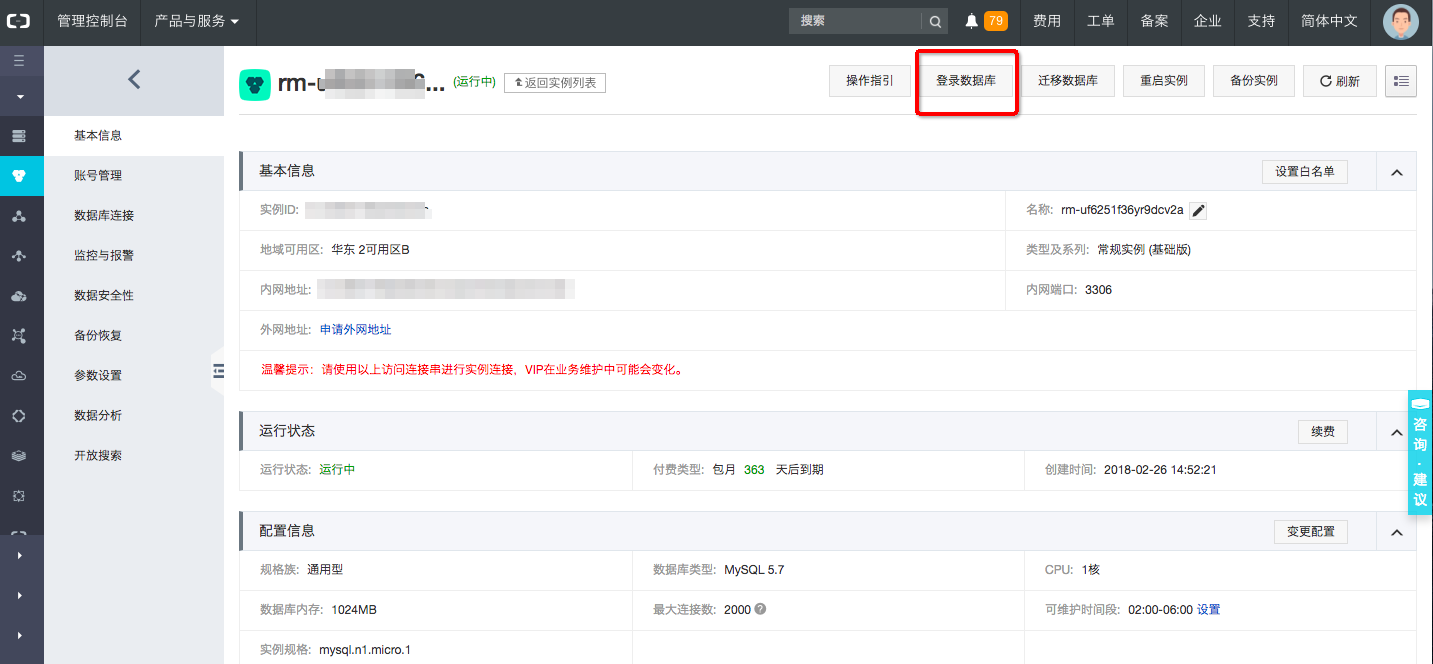
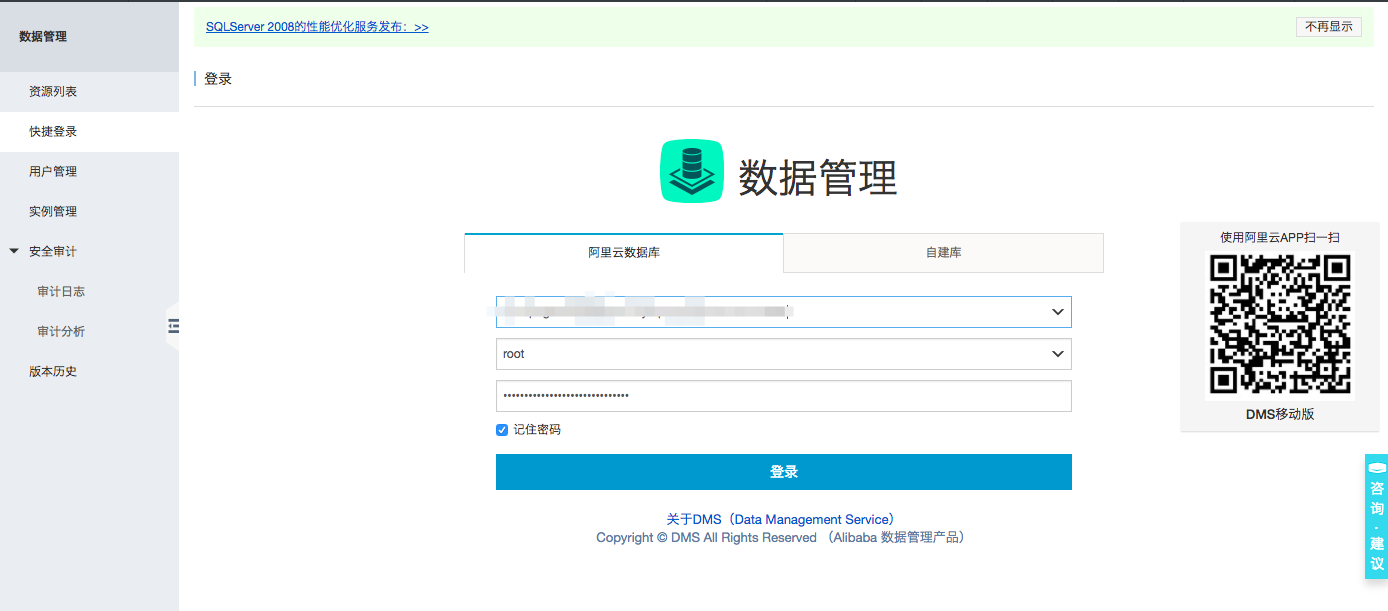
登录数据库。
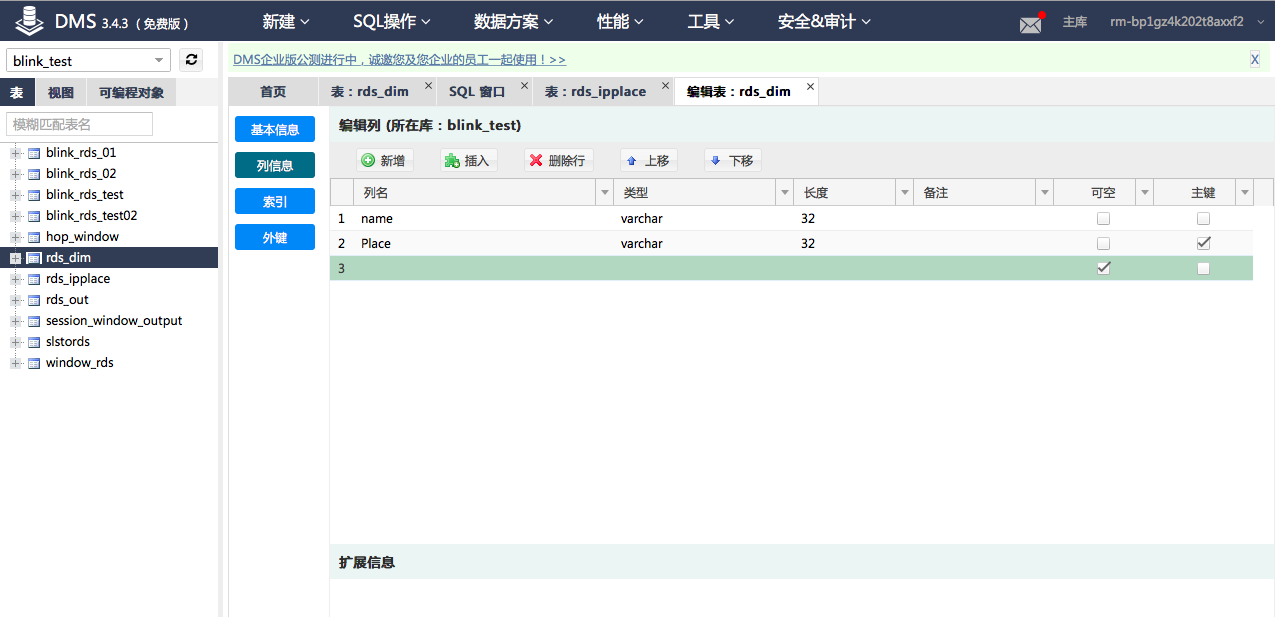
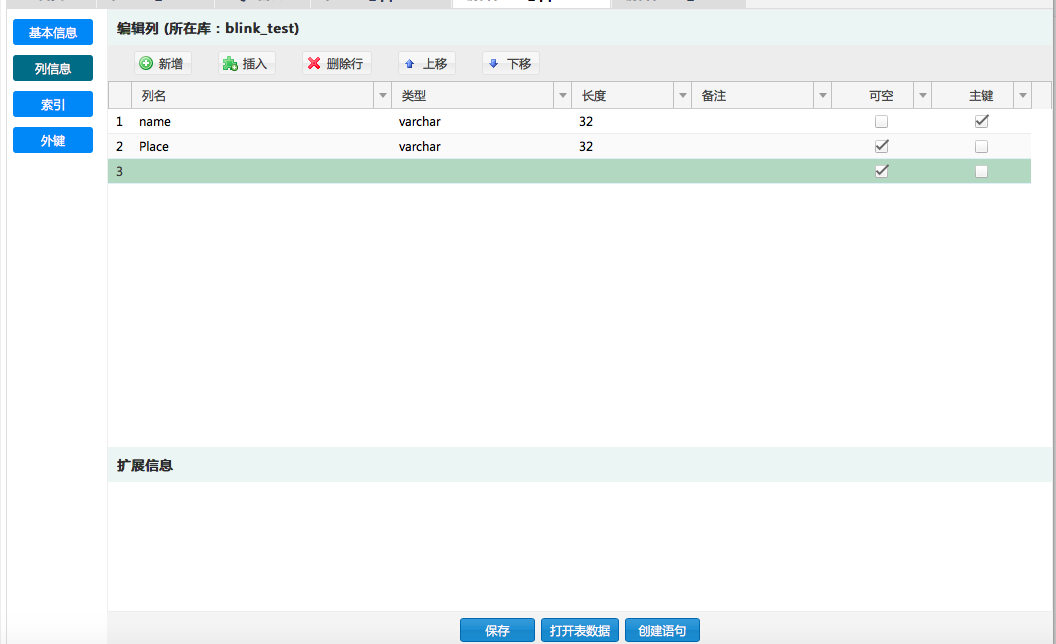
RDS维表创建
测试维表名称:rds_dim
| 字段名 | 类型 | 注释 |
|---|---|---|
| name | varchar | 名字 |
| Place | varchar | 地址 |
创建的维表schema示意图如下:
上传dim表测试数据。
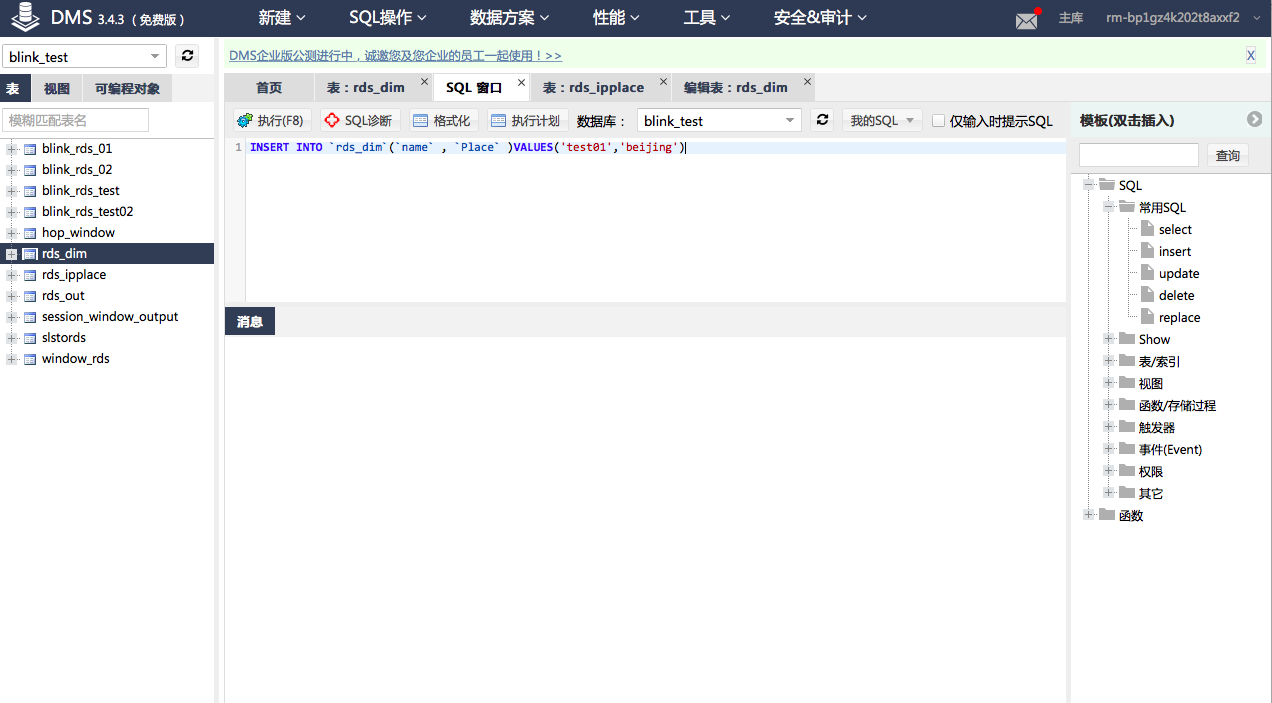
INSERT INTO `rds_dim`(`name` ,`Place` )VALUES('test01','beijing')
说明:实际生产应用中,我们很少有机会利用文件上传工具进行数据采集工作。更多数据采集工具的使用请参数据采集。
RDS结果表创建
测试结果表名称:rds_IpPlace
| 字段名 | 类型 | 注释 |
|---|---|---|
| name | varchar | 名字 |
| Place | varchar | 地址 |
创建的结果表schema示意图如下。
本文转自实时计算——步骤二:注册上下游存储