1 浅谈数据科学
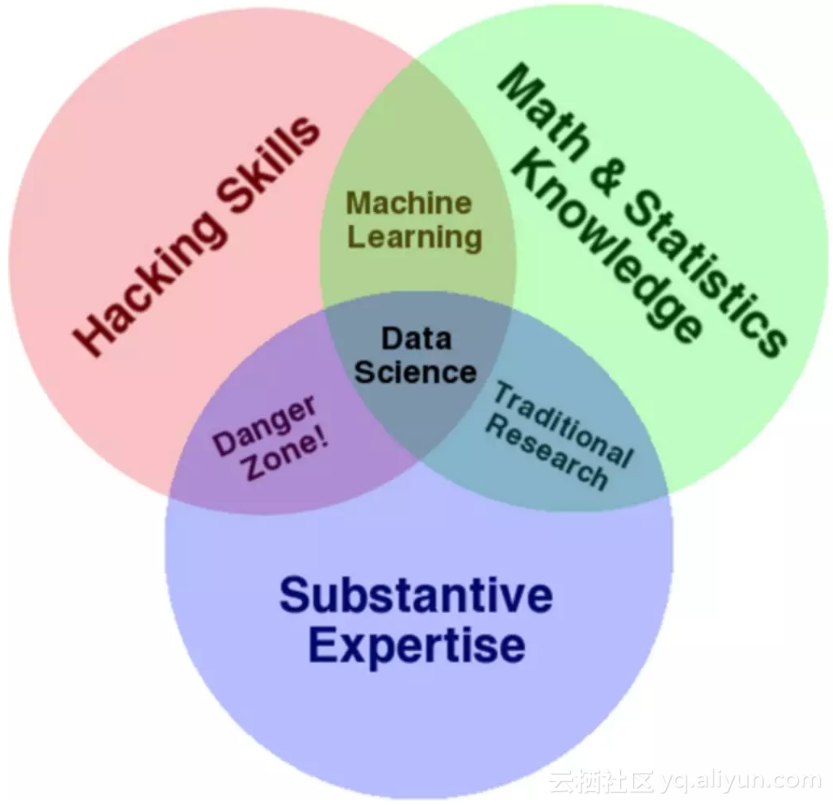
数据科学(Data Science)这一概念自大数据崛起也随之成为数据领域的讨论热点,从去年开始,“数据科学家”便成为了一个工作职位出现在各种招聘信息上。那么究竟什么是数据科学?大数据和数据科学又是什么关系?大数据在数据科学中起到怎样的作用?本文主要是想起到科普作用,使即将或正在从事数据工作的朋友对数据科学工作有一个全概貌了解,也使各有想法进入大数据领域的朋友在真正从事大数据工作之前对行业的情况有所知晓。数据科学是一个混合交叉学科(如下图所示),要完整的成为一个数据科学家,就需要具备较好的数学和计算机知识,以及某一个专业领域的知识。所做的工作都是围绕数据打转转,在数据量爆发之后,大数据被看做是数据科学中的一个分支。
2 浅谈大数据
大数据(Big Data)其实已经兴起好些年了,只是随着无处不在的传感器、无处不在的数据埋点,获取数据变得越来越容易、量越来越大、内容越来越多样化,于是原来传统的数据领域不得不思考重新换一个平台可以处理和使用逐渐庞大数据量的新平台。用以下两点进一步阐述:
● 吴军博士提出的一个观点:现有产业+新技术=新产业,大数据也符合这个原则,只是催生出来的不仅仅是一个新产业,而是一个完整的产业链:原有的数据领域+新的大数据技术=大数据产业链;● 数据使用的范围,原来的数据应用主要是从现有数据中的数据中进行采样,再做数据挖掘和分析,发掘出数据中的潜在规则用以预测或决策,然而采样始终会舍弃一部分数据,即会丢失一部分潜在规则和价值,随着数据量和内容的不断累积,企业越来越重视在数据应用时可以使用全量数据,可以尽可能的覆盖所有潜在规则从而发掘出可能想到或从未想到的价值。
在我学习和从事大数据相关工作的4年里,在我有限的知识海洋里,大数据是一个以数据流向为主的链条或管道,数据从何而来,又去往哪里,不仅是哲学上的一个问题,也可以在做数据工作的时候考虑这个问题。如下图所示,大数据领域可以分为以下几个主要方向,而这几个方向又可以分别对应一些工作职位:
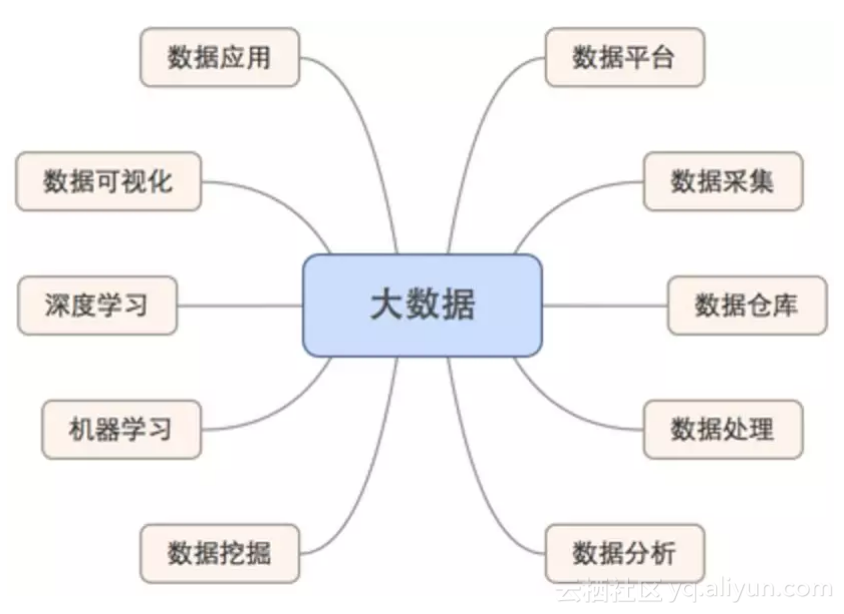
1 数据平台
Data Platform,构建、维护稳定、安全的大数据平台,按需设计大数据架构,调研选型大数据技术产品、方案,实施部署上线。对于大数据领域涉及到的大多数技术都需要求有所了解,并精通给一部分,具备分布式系统的只是背景……
对应职位:大数据架构师,数据平台工程师
2 数据采集
Data Collecting,从Web/Sensor/RDBMS等渠道获取数据,为大数据平台提供数据来源,如Apache Nutch是开源的分布式数据采集组件,大家熟知的Python爬虫框架ScraPy等。
对应职位:爬虫工程师,数据采集工程师
3 数据仓库
Data Warehouse,有点类似于传统的数据仓库工作内容:设计数仓层级结构、ETL、进行数据建模,但基于的平台不一样,在大数据时代,数据仓库大多基于大数据技术实现,例如Hive就是基于Hadoop的数据仓库。
对应职位:ETL工程师,数据仓库工程师
4 数据处理
Data Processing,完成某些特定需求中的处理或数据清洗,在小团队中是结合在数据仓库中一起做的,以前做ETL或许是利用工具直接配置处理一些过滤项,写代码部分会比较少,如今在大数据平台上做数据处理可以利用更多的代码方式做更多样化的处理,所需技术有Hive、Hadoop、Spark等。BTW,千万不要小看数据处理,后续的数据分析、数据挖掘等工作都是基于数据处理的质量,可以说数据处理在整个流程中有特别重要的位置。
对应职位:Hadoop工程师,Spark工程师
5 数据分析
Data Analysis,基于统计分析方法做数据分析:例如回归分析、方差分析等,天善也有很多数据分析课程。大数据分析例如Ad-Hoc交互式分析、SQL on Hadoop的技术有:Hive 、Impala、Presto、Spark SQL,支持OLAP的技术有:Kylin。
对应职位:数据分析师
6 数据挖掘
Data Mining,是一个比较宽泛的概念,可以直接理解为从大量数据中发现有用的信息。大数据中的数据挖掘,主要是设计并在大数据平台上实现数据挖掘算法:分类算法、聚类算法、关联分析等。
对应职位:数据挖掘工程师
7 机器学习
Machine Learning,与数据挖掘经常一起讨论,甚至被认为是同一事物。机器学习是一个计算机与统计学交叉的学科,基本目标是学习一个x->y的函数(映射),来做分类或者回归的工作。之所以经常和数据挖掘合在一起讲是因为现在好多数据挖掘的工作是通过机器学习提供的算法工具实现的,例如个性化推荐,是通过机器学习的一些算法分析平台上的各种购买,浏览和收藏日志,得到一个推荐模型,来预测你喜欢的商品。
对应职位:算法工程师,研究员
8 深度学习
Deep Learning,是机器学习里面的一个topic(非常火的Topic),从深度学习的内容来看其本身是神经网络算法的衍生,在图像、语音、自然语言等分类和识别上取得了非常好的效果,大部分的工作是在调参。不知道大家有否发现现在的Google 翻译比以前的要准确很多,因为Google在去年底将其Google 翻译的核心从原来基于统计的方法换成了基于神经网络的方法~So~
对应职位:算法工程师,研究员
9 数据可视化
Data Visualization,将分析、挖掘后的高价值数据用比较优美、灵活的方式展现在老板、客户、用户面前,更多的是一些前端的东西,maybe要求一定的美学知识。结合使用者的喜好,以最恰当的方式呈现数据价值。
对应职位:数据工程师,BI工程师
10 数据应用
Data Application,从以上的每个部分可以衍生出的应用,例如广告精准投放、个性化推荐、用户画像等。
对应职位:数据工程师
建议:想进入大数据领域的朋友可以选一个与自己现有技术背景相匹配的方向作为入门,然后将你的魔爪延伸到其他感兴趣的方向,这是最快进入这个领域的一个方法。这里所列的每一个方向都需要耗费大量的时间、脑力、体力,都是这个智能时代继续发展的过程中不可或缺的一部分。
原文发布时间为:2018-11-12
本文作者:Mars
本文来自云栖社区合作伙伴“Python爱好者社区”,了解相关信息可以关注“Python爱好者社区”。
