关联规则挖掘算法在生活中的应用处处可见,几乎在各个电子商务网站上都可以看到其应用
举个简单的例子
如当当网,在你浏览一本书的时候,可以在页面中看到一些套餐推荐,本书+有关系的书1+有关系的书2+...+其他物品=多少¥
而这些套餐就很有可能符合你的胃口,原本只想买一本书的你可能会因为这个推荐而买了整个套餐
这与userCF和itemCF不同的是,前两种是推荐类似的,或者你可能喜欢的商品列表
而关联规则挖掘的是n个商品是不是经常一起被购买,如果是,那个n个商品之中,有一个商品正在被浏览(有被购买的意向),那么这时候系统是不是就能适当的将其他n-1个商品推荐给这个用户,因为其他很多用户在购买这个商品的时候会一起购买其他n-1的商品,将这n个商品做成一个套餐优惠,是不是能促进消费呢
这n个商品之间的关系(经常被用户一起购买)就是一个关联规则
下面介绍一个比较简单的关联规则算法---apriori
首先介绍几个专业名词
挖掘数据集:就是待挖掘的数据集合。这个好理解
频繁模式:频繁的出现在挖掘数据集中的模式,例如项集,子结构,子序列等。这个怎么理解呢,简单的说就是挖掘数据集中,频繁出现的一些子集数据
关联规则:例如,牛奶=>鸡蛋{支持度=2%,置信度=60%}。关联规则表示了a物品和b物品之间的关系,通过支持度和置信度来表示(当然不只是两个物品之间,也有可能是n个物品之间的关系),支持度和置信度定义的值的大小会影响到整个算法的性能
支持度:如上例子中,支持度表示,在所有用户中,一起购买了牛奶和鸡蛋的用户所占的比例是多少。支持度有一个预定义的初值(如上例中的2%),如果最终的支持度小于这个初值,那么这个牛奶和鸡蛋就不能成为一个频繁模式
置信度:如上例子中,置信度表示,在所有购买了牛奶的用户中,同时购买了鸡蛋的用户所占的比例是多少。和支持度一样,置信度也会有一个初值(上例中的60%,表示购买了牛奶的用户中60%还购买了鸡蛋),如果最终的置信度小于这个初值,那么牛奶和鸡蛋也不能成为一个频繁模式
支持度和置信度也可以用具体的数据来表示,而不一定是一个百分比
apriori算法的基本思想就是:在一个有n项的频繁模式中,它的所有子集也是频繁模式
下面来看一个购物车数据的例子
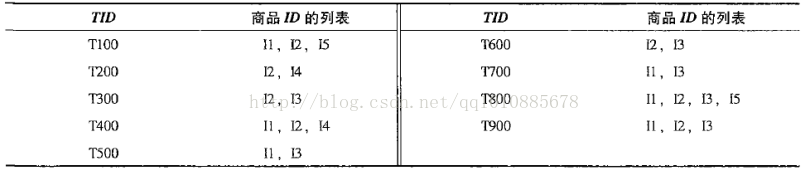
TID表示购物车的编号,每行表示购物车中对应的商品列表,商品为i1,i2,i3,i4,i5,D代表整个数据表
apriori算法的工作过程如下图:
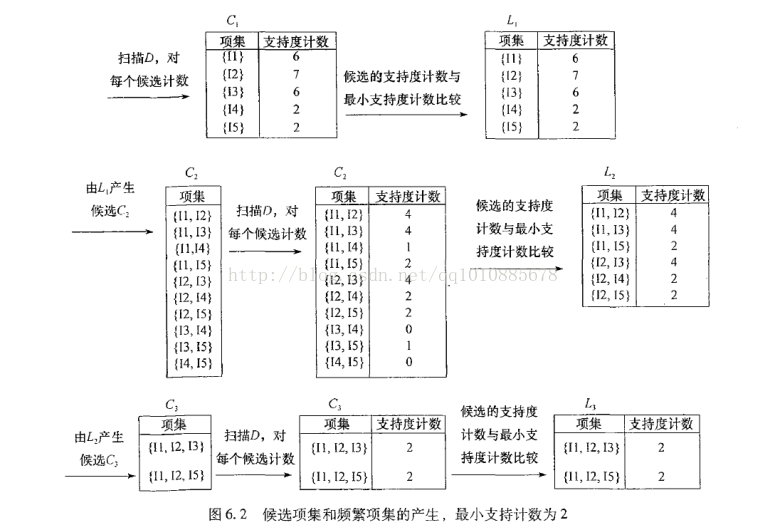
(1)首先扫描整个数据表D,计算每个商品的支持度(出现的次数),得到候选C1表。这里将每个独立的商品都看成一个频繁模式来处理,计算它的支持度
(2)将每个商品的支持度和最小支持度作对比(最小支持度为2),小于2的商品将被过滤,得到L1。这里每个商品的支持度都大于2,所以全部保留
(3)将L1和自身进行自然连接操作,得到候选C2表。也就是进行L1*L1操作,将L1进行全排列,去掉重复的行得到候选C2(如,{i1,i1},{i2,i2}等),C2中的每个项都是由两个商品组成的
(4)再次扫描整个表D, 计算C2中每行的支持度。这里将C2中的每行(两个商品)都当做一个频繁模式计算支持度
(5)将C2中的每项支持度和最小支持度2作比较,过滤,得到L2。
(6)在将L2和自身做自然连接得到候选C3。L2*L2的结果为:{i1,i2,i3},{i1,i2,i5}{i1.i3,i5}{i2,i3,i4}{i2,i3,i5}{i2,i4,i5},{i1,i2}和{i1,i3}的结果为{i1,i2,i3},计算方式为:前n-1个项必须是一致的(就是i1),结果就是前n-1项+各自的第n项(i2,i3)。那么为什么产生的C3中只有{i1,i2,i3},{i1,i2,i5}呢,回头看看apriori算法的基本思想,如果第三个{i1,i3,i5}也是频繁模式的话,那么它的所有子集也应该是频繁模式,而在L2中无法找到{i3,i5}这个项,所以{i1.i3,i5}不是一个频繁模式,过滤。最终结果就是C3
(7)再次扫描整个表D,计算C3中每行的支持度。这里将C3中的每行(三个商品)都当做一个频繁模式计算支持度
(8)将C3中的每项支持度和最小支持度2作比较,过滤,得到L3
由于整个表D最多的项是4,而且只出现一次,所以它不可能是频繁模式,故计算到三项的频繁模式就可以结束了
算法的输出结果应该是;1,L2,L3集合,其中每个项都是一个频繁模式
例如我们得到一个频繁模式{i1,i2,i3},能够提取哪些关联规则?
{i1,i2}=>i3,表示购买了i1,i2的用户中还购买了i3的用户所占的比例。{i1,i2,i3}的出现次数为2,{i1,i2}的出现次数为4,故置信度为2/4=50%
类似的可以算出
{i1,i3}=>i2,confidence=50%
{i2,i3}=>i1,confidence=50%
i1=>{i2,i3},confidence=33%
i2=>{i1,i3},confidence=28%
i3=>{i1,i2},confidence=33%
也就是说,当一个用户购买了i1,i3的时候系统可以将i2一起当做一个套餐推荐给用户,因为这三个商品频繁的被一起购买
但是,通过对算法整个过程的描述,我们可以看到,apriori算法在计算上面的简单例子中,进行了3次全表扫描,而且在进行L1自然连接的时候,如果购物车项的数据是很大(比如100),这时候进行自然连接操作的计算量是巨大的,内存无法加载如此巨大的数据
所以apriori算法现在已经很少使用了,但是通过了解apriori算法可以让我们对关联规则挖掘进一步了解,并且可以作为一个比较基础,和其他关联规则算法做对比,从而得知哪个算法性能好,好在哪里
本文参考书:《数据挖掘概念与技术》
