通过API操作之前要先了解几个基本知识
基本数据类型
Hadoop的基本数据类型和Java的基本数据类型是不一样的,但是都存在对应的关系
如下图

如果需要定义自己的数据类型,则必须实现Writable
hadoop的数据类型可以通过get方法获得对应的java数据类型
而java的数据类型可以通过hadoop数据类名的构造函数,或者set方法转换
关于Hadoop的Writable接口,详情请看Hadoop I/O中的序列化部分
MapReduce执行的基本步骤
Hadoop提交作业的的步骤分为八个,可以理解为天龙八步
Map端工作
- 1.1 读取要操作的文件–这步会将文件的内容格式化成键值对的形式,键为每一行的起始位置偏移,值为每一行的内容。
- 1.2 调用map进行处理–在这步使用自定义的Mapper类来实现自己的逻辑,输入的数据为1.1格式化的键值对,输入的数据也是键值对的形式。
- 1.3 对map的处理结果进行分区–map处理完毕之后可以根据自己的业务需求来对键值对进行分区处理,比如,将类型不同的结果保存在不同的文件中等。这里设置几个分区,后面就会有对应的几个Reducer来处理相应分区中的内容。
- 1.4 分区之后,对每个分区的数据进行排序,分组–排序按照从小到大进行排列,排序完毕之后,会将键值对中,key相同的选项 的value进行合并。如,所有的键值对中,可能存在
hello 1
hello 1
key都是hello,进行合并之后变成
hello 2
可以根据自己的业务需求对排序和合并的处理进行干涉和实现。- 1.5 归约(combiner)–简单的说就是在map端进行一次reduce处理,但是和真正的reduce处理不同之处在于:combiner只能处理本地数据,不能跨网络处理。通过map端的combiner处理可以减少输出的数据,因为数据都是通过网络传输的,其目的是为了减轻网络传输的压力和后边reduce的工作量。并不能取代reduce。
Reduce端工作
- 2.1 通过网络将数据copy到各个reduce。
- 2.2 调用reduce进行处理–reduce接收的数据是整个map端处理完毕之后的键值对,输出的也是键值对的集合,是最终的结果。
- 2.3 将结果输出到hdfs文件系统的路径中。
程序开发
开发流程
一般情况下我们不可能直接在生产环境中直接拿海量数据进行程序开发,不说程序有没有bug,能不能跑起来都是一个问题
所以通常步骤是:
1.本地程序开发测试:从海量数据中抽取小部分数据到本地,使用IDE等工具进行开发,并在测试数据集上进行程序运行、逻辑等测试
2.集群环境运行:本地测试通过后,就可以将代码运行在海量数据中,这时候90%的小bug已经得到修复了,剩余要解决的就是生产环境中的问题了
3.调优:程序能够在集群中运行起来并不代表成功,通过一些集群、程序调优方式可以让你的代码跑的更好、更快
导包
新建一个java项目,并导入hadoop包,在项目选项上右键,如图选择
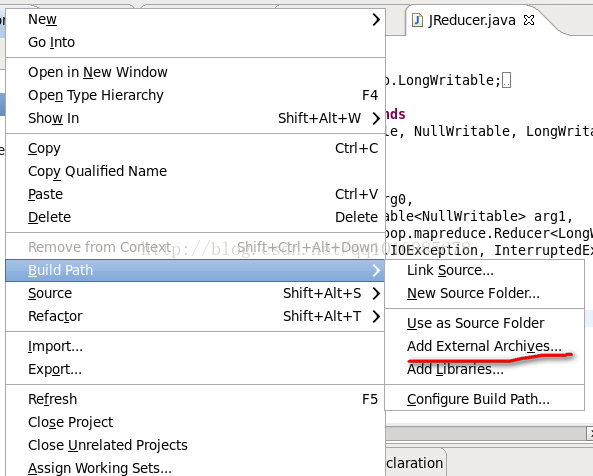
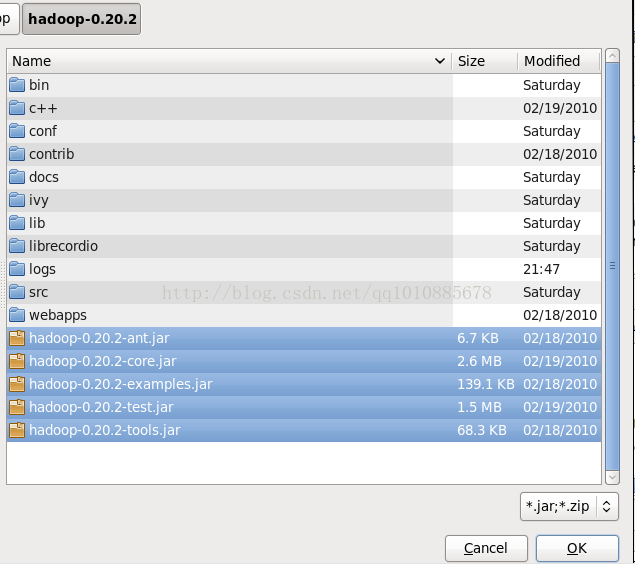
找到hadoop的安装目录,选择所有的包
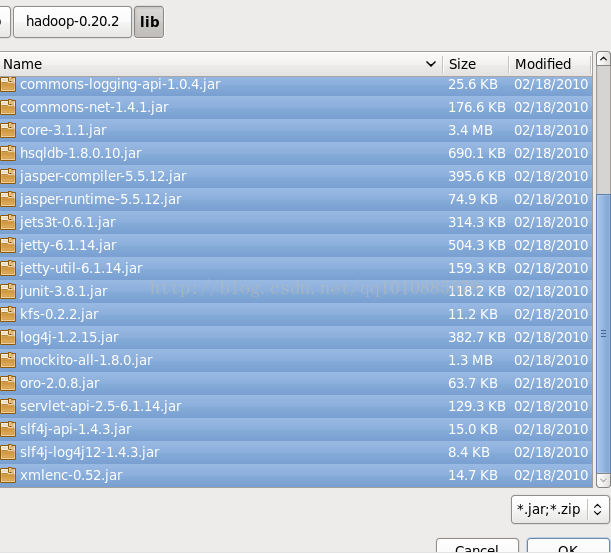
在找到hadoop安装目录下的lib,导入其中的所有包
代码
新建JMapper类为自定义的Mapper类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
//自定义的Mapper类必须继承Mapper类,并重写map方法实现自己的逻辑
public class JMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
//处理输入文件的每一行都会调用一次map方法,文件有多少行就会调用多少次
protected void map(
LongWritable key,
Text value,
org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws java.io.IOException, InterruptedException {
//key为每一行的起始偏移量
//value为每一行的内容
//每一行的内容分割,如hello world,分割成一个String数组有两个数据,分别是hello,world
String[] ss = value.toString().toString().split("\t");
//循环数组,将其中的每个数据当做输出的键,值为1,表示这个键出现一次
for (String s : ss) {
//context.write方法可以将map得到的键值对输出
context.write(new Text(s), new LongWritable(1));
}
};
} 新建JReducer类为自定义的Reducer
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
//自定义的Reducer类必须继承Reducer,并重写reduce方法实现自己的逻辑,泛型参数分别为输入的键类型,值类型;输出的键类型,值类型;之后的reduce类似
public class JReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
//处理每一个键值对都会调用一次reduce方法,有多少个键值对就调用多少次
protected void reduce(
Text key,
java.lang.Iterable<LongWritable> value,
org.apache.hadoop.mapreduce.Reducer<Text, LongWritable, Text, LongWritable>.Context context)
throws java.io.IOException, InterruptedException {
//key为每一个单独的单词,如:hello,world,you,me等
//value为这个单词在文本中出现的次数集合,如{1,1,1},表示总共出现了三次
long sum = 0;
//循环value,将其中的值相加,得到总次数
for (LongWritable v : value) {
sum += v.get();
}
//context.write输入新的键值对(结果)
context.write(key, new LongWritable(sum));
};
} 新建执行提交作业的类,取名JSubmit
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class JSubmit {
public static void main(String[] args) throws IOException,
URISyntaxException, InterruptedException, ClassNotFoundException {
//Path类为hadoop API定义,创建两个Path对象,一个输入文件的路径,一个输入结果的路径
Path outPath = new Path("hdfs://localhost:9000/out");
//输入文件的路径为本地linux系统的文件路径
Path inPath = new Path("/home/hadoop/word");
//创建默认的Configuration对象
Configuration conf = new Configuration();
//根据地址和conf得到hadoop的文件系统独享
//如果输入路径已经存在则删除
FileSystem fs = FileSystem.get(new URI("hdfs://localhost:9000"), conf);
if (fs.exists(outPath)) {
fs.delete(outPath, true);
}
//根据conf创建一个新的Job对象,代表要提交的作业,作业名为JSubmit.class.getSimpleName()
Job job = new Job(conf, JSubmit.class.getSimpleName());
//1.1
//FileInputFormat类设置要读取的文件路径
FileInputFormat.setInputPaths(job, inPath);
//setInputFormatClass设置读取文件时使用的格式化类
job.setInputFormatClass(TextInputFormat.class);
//1.2调用自定义的Mapper类的map方法进行操作
//设置处理的Mapper类
job.setMapperClass(JMapper.class);
//设置Mapper类处理完毕之后输出的键值对 的 数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//1.3分区,下面的两行代码写和没写都一样,默认的设置
job.setPartitionerClass(HashPartitioner.class);
job.setNumReduceTasks(1);
//1.4排序,分组
//1.5归约,这三步都有默认的设置,如果没有特殊的需求可以不管
//2.1将数据传输到对应的Reducer
//2.2使用自定义的Reducer类操作
//设置Reducer类
job.setReducerClass(JReducer.class);
//设置Reducer处理完之后 输出的键值对 的数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//2.3将结果输出
//FileOutputFormat设置输出的路径
FileOutputFormat.setOutputPath(job, outPath);
//setOutputFormatClass设置输出时的格式化类
job.setOutputFormatClass(TextOutputFormat.class);
//将当前的job对象提交
job.waitForCompletion(true);
} 运行
运行java程序,可以再控制台看到提交作业的提示
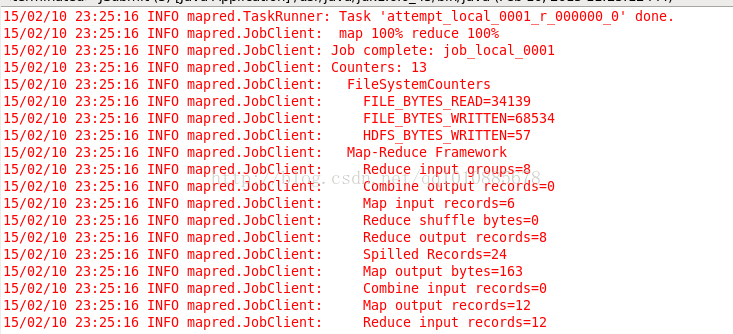
在hdfs中查看输出的文件
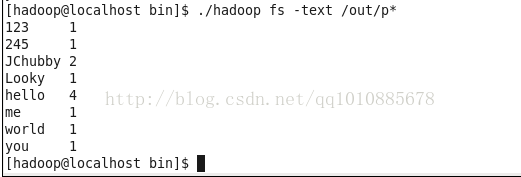
程序调试
在集群上调试程序是十分困难的,就算采用最常见的println打印信息你也不知道该信息会在集群上哪个节点打印出来
在MapReduce中,可以使用系统错误信息+计数器的组合来进行调试,在map或者reduce函数中,我们可以这样做:
System.out.println("一些错误信息");
context.setStatus("关于错误的一些提示")
context.getCounter(计数器组名一般为枚举类型).increment(1);在CLI中可以通过以下命令查看计数器:
mapred job -counter jobId counterGroup counterNamecounterGroup:计数器组名,一般为枚举类型的全类名
counterName:计数器名,一般为枚举类型的值
性能调优
JobControl
开发MapReduce程序的时候,我们需要考虑如何把需求转换为MapReduce模型来解决问题
对于一些复杂的场景,我们通常是使用多个Job来完成任务,而不是一个非常复杂的单一Job
所以一个完成的任务就可能会有多个Job,一个Job有可能有多个Mapper的情况,参考:
多个Mapper和Reducer处理多个输入
开发技巧
更多应用场景
下面是自己在学习过程中收集整理的一些MapReduce场景Demo,可以提供参考和帮助:
GitHub - chubbyjiang/MapReduce: MapReduce Demo
作者:@小黑




