转自:Spark下Yarn-Cluster和Yarn-Client的区别
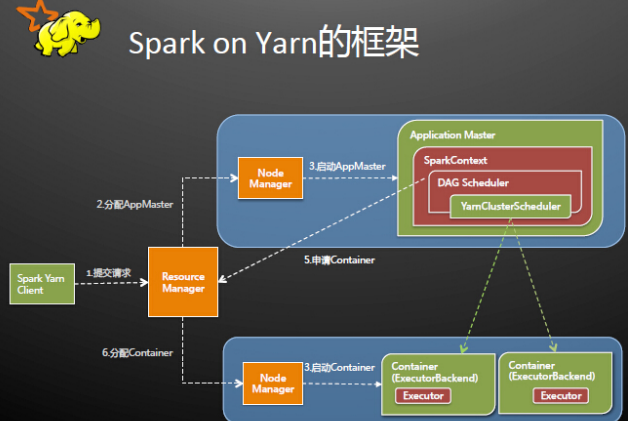
0 首先注意的概念
ResourceManager:是集群所有应用程序的资源管理器,能够管理集群的计算资源并为每个Application分配,它是一个纯粹的调度器。
NodeManager:是每一台slave机器的代理,执行应用程序,并监控应用程序的资源使用情况。
Application Master:每一个应用程序都会有一个Application Master,它的主要职责是向RM申请资源、在每个NodeManager上启动executors、监控和跟踪应用程序的进程等。
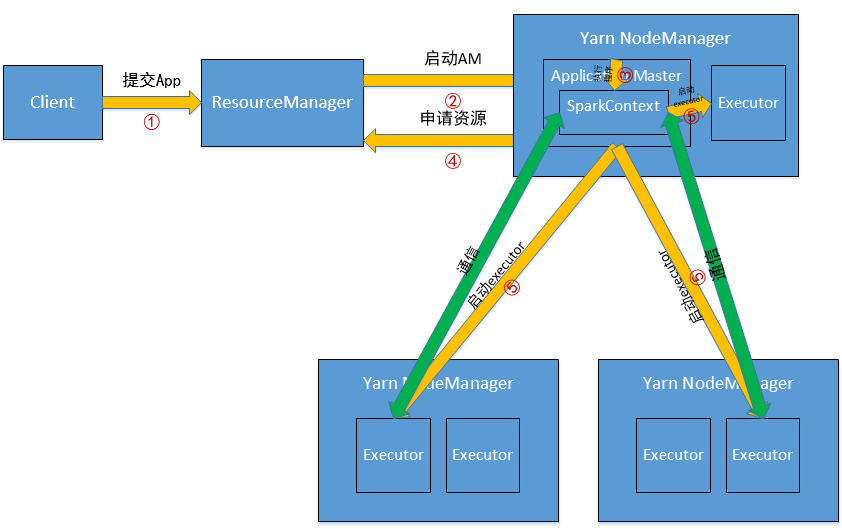
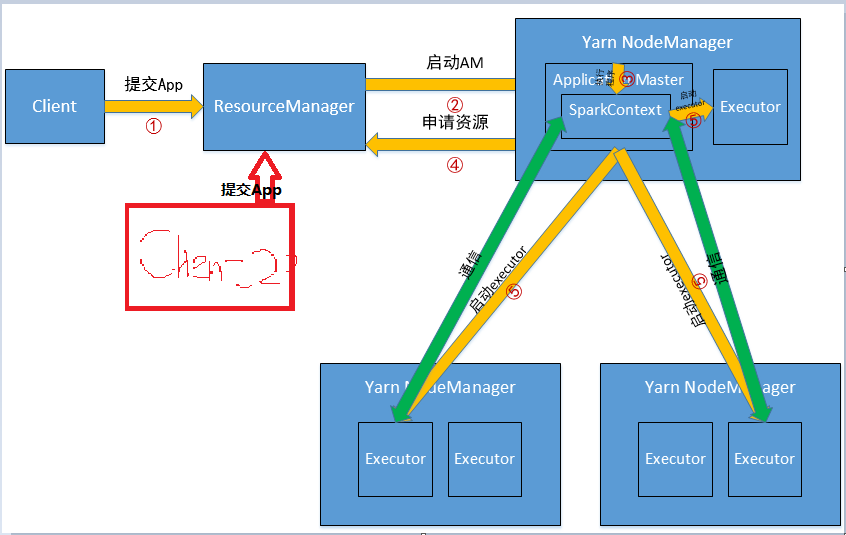
执行过程:
(1)客户端提交Application到RM,这个过程做的工作有判断集群资源是否满足需求、读取配置文件、设置环境变量、设置Application名字等等;
(2)RM在某一台NodeManager上启动Application Master,AM所在的机器是YARN分配的,事先是不知道的;
(3)AM初始化SparkContext,开始驱动程序,这个NodeManager便是Driver;
(4)AM向ResourceManager申请资源,并在每台NodeManager上启动相应的executors;
(5)初始化后的SparkContext中的通信模块可以通过AKKA与NodeManager上的容器进行通信。
比以前的更多的理解:
(1)Application Master所在的NodeManager是Yarn随机分配的,不是在主节点上,下图是实验室集群上跑得一个Spark程序,tseg0是主节点,tseg1~tseg4是workers,IP10.103.240.29指的是tseg3:
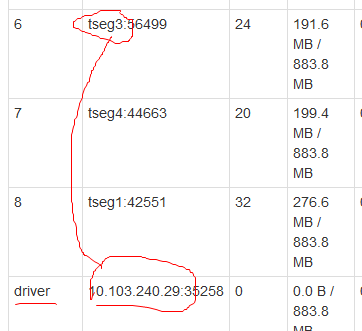
(2)在上图还可以看出,executor的容器和AM容器是可以共存的,它们的封装都是容器;
(3)AM是Yarn启动的第一个容器;
(4)AM所在的NodeManager就是平常说的Driver端,因为这个AM启动了SparkContext,之前实验室说的“谁初始化的SparkContext谁就是Driver端”一直理解错了,以为这句话是相对于机器说的,但其实是相对于Cluster和Client的集群模式来说的(不知道其他模式Mesos、standalone是不是也是这样)。
(5)在Application提交到RM上之后,Client就可以关闭了,集群会继续运行提交的程序,在实际使用时,有时候会看到这样一种现象,关闭Client会导致程序终止,其实这个Application还没有提交上去,关闭Client打断了提交的过程,Application当然不会运行。
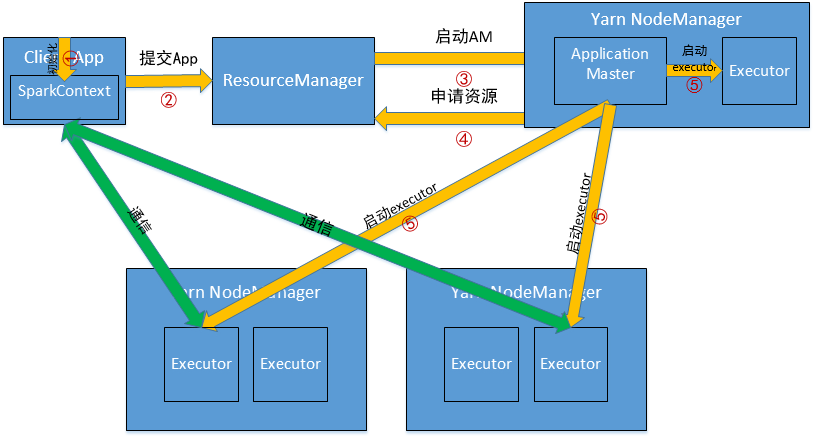
(1)Client Application会初始化SparkContext,这是Driver端;
(2)提交Application到RM;
(3)应该是在RM所在的机器上启动AM(?不确定);
(4)AM向RM申请资源,并启动NodeManager上的Executors;
(5)Executors与SparkContext初始化后的通信模块保持通信,因为是与Client端通信,所以Client不能关闭。
(1)SparkContext初始化不同,这也导致了Driver所在位置的不同,YarnCluster的Driver是在集群的某一台NM上,但是Yarn-Client就是在RM在机器上;
(2)而Driver会和Executors进行通信,这也导致了Yarn_cluster在提交App之后可以关闭Client,而Yarn-Client不可以;
(3)最后再来说应用场景,Yarn-Cluster适合生产环境,Yarn-Client适合交互和调试。
之前实验室配过Hadoop多用户,最近因为培训Spark,又得在这个基础上再能够运行Spark。做的工作很简单,就是把Spark以及Spark依赖的环境scp过去,然后再改一下相应的配置就可以了。猜想的不同用户运行Spark On Yarn Cluster如下图所示,无非就是多增加了一个用户Client,因为ResourceManager是唯一的,所以不同用户CLient提交的Spark Application在集群上运行都是一样的。
《Spark技术内幕-深入解析Spark内核、架构设计与实现原理》
