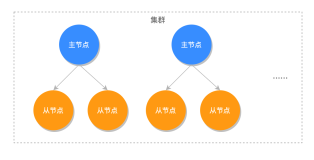
cluster 相关数据结构
在redis cluster的概念当中有一个槽(slot)的概念,也就是说在redis的cluster中存在2**14=16384个槽分布在集群当中,所以在宏定义当中REDIS_CLUSTER_SLOTS的值为16384.
// 槽数量
#define REDIS_CLUSTER_SLOTS 16384
// 集群在线
#define REDIS_CLUSTER_OK 0 /* Everything looks ok */
// 集群下线
#define REDIS_CLUSTER_FAIL 1 /* The cluster can't work */
// 节点名字的长度
#define REDIS_CLUSTER_NAMELEN 40 /* sha1 hex length */
// 集群的实际端口号 = 用户指定的端口号 + REDIS_CLUSTER_PORT_INCR
#define REDIS_CLUSTER_PORT_INCR 10000 /* Cluster port = baseport + PORT_INCR */
redis保存集群节点相关的数据结构说明如下:
- 在redisServer的数据结构当中,我们通过clusterState的数据结构来保存集群状态。
- 在clusterState的数据结构当中,我们通过dict *nodes保存集群的节点,其中key为节点名字,value为clusterNode对象。
- clusterNode保存该节点集群信息,包括slave信息,slots信息,clusterLink的连接信息。
- clusterLink保存是通过cluster meet命令指定的集群节点,从名字上可以理解为集群连接相关的信息,这个连接是通过cluster meet指定的。
struct redisServer {
struct clusterState *cluster;
}
-----------------------------------华丽分割线--------------------------------------------
// 集群状态,每个节点都保存着一个这样的状态,记录了它们眼中的集群的样子。
typedef struct clusterState {
// 指向当前节点的指针
clusterNode *myself; /* This node */
// 集群当前的配置纪元,用于实现故障转移
uint64_t currentEpoch;
// 集群当前的状态:是在线还是下线
int state; /* REDIS_CLUSTER_OK, REDIS_CLUSTER_FAIL, ... */
// 集群中至少处理着一个槽的节点的数量。
int size; /* Num of master nodes with at least one slot */
// 集群节点名单(包括 myself 节点)
// 字典的键为节点的名字,字典的值为 clusterNode 结构
dict *nodes; /* Hash table of name -> clusterNode structures */
// 节点黑名单,用于 CLUSTER FORGET 命令
// 防止被 FORGET 的命令重新被添加到集群里面
// (不过现在似乎没有在使用的样子,已废弃?还是尚未实现?)
dict *nodes_black_list; /* Nodes we don't re-add for a few seconds. */
// 记录要从当前节点迁移到目标节点的槽,以及迁移的目标节点
// migrating_slots_to[i] = NULL 表示槽 i 未被迁移
// migrating_slots_to[i] = clusterNode_A 表示槽 i 要从本节点迁移至节点 A
clusterNode *migrating_slots_to[REDIS_CLUSTER_SLOTS];
// 记录要从源节点迁移到本节点的槽,以及进行迁移的源节点
// importing_slots_from[i] = NULL 表示槽 i 未进行导入
// importing_slots_from[i] = clusterNode_A 表示正从节点 A 中导入槽 i
clusterNode *importing_slots_from[REDIS_CLUSTER_SLOTS];
// 负责处理各个槽的节点
// 例如 slots[i] = clusterNode_A 表示槽 i 由节点 A 处理
clusterNode *slots[REDIS_CLUSTER_SLOTS];
// 跳跃表,表中以槽作为分值,键作为成员,对槽进行有序排序
// 当需要对某些槽进行区间(range)操作时,这个跳跃表可以提供方便
// 具体操作定义在 db.c 里面
zskiplist *slots_to_keys;
/* The following fields are used to take the slave state on elections. */
// 以下这些域被用于进行故障转移选举
// 上次执行选举或者下次执行选举的时间
mstime_t failover_auth_time; /* Time of previous or next election. */
// 节点获得的投票数量
int failover_auth_count; /* Number of votes received so far. */
// 如果值为 1 ,表示本节点已经向其他节点发送了投票请求
int failover_auth_sent; /* True if we already asked for votes. */
int failover_auth_rank; /* This slave rank for current auth request. */
uint64_t failover_auth_epoch; /* Epoch of the current election. */
/* Manual failover state in common. */
/* 共用的手动故障转移状态 */
// 手动故障转移执行的时间限制
mstime_t mf_end; /* Manual failover time limit (ms unixtime).
It is zero if there is no MF in progress. */
/* Manual failover state of master. */
/* 主服务器的手动故障转移状态 */
clusterNode *mf_slave; /* Slave performing the manual failover. */
/* Manual failover state of slave. */
/* 从服务器的手动故障转移状态 */
long long mf_master_offset; /* Master offset the slave needs to start MF
or zero if stil not received. */
// 指示手动故障转移是否可以开始的标志值
// 值为非 0 时表示各个主服务器可以开始投票
int mf_can_start; /* If non-zero signal that the manual failover
can start requesting masters vote. */
/* The followign fields are uesd by masters to take state on elections. */
/* 以下这些域由主服务器使用,用于记录选举时的状态 */
// 集群最后一次进行投票的纪元
uint64_t lastVoteEpoch; /* Epoch of the last vote granted. */
// 在进入下个事件循环之前要做的事情,以各个 flag 来记录
int todo_before_sleep; /* Things to do in clusterBeforeSleep(). */
// 通过 cluster 连接发送的消息数量
long long stats_bus_messages_sent; /* Num of msg sent via cluster bus. */
// 通过 cluster 接收到的消息数量
long long stats_bus_messages_received; /* Num of msg rcvd via cluster bus.*/
} clusterState;
-----------------------------------华丽分割线--------------------------------------------
// 节点状态
struct clusterNode {
// 创建节点的时间
mstime_t ctime; /* Node object creation time. */
// 节点的名字,由 40 个十六进制字符组成
// 例如 68eef66df23420a5862208ef5b1a7005b806f2ff
char name[REDIS_CLUSTER_NAMELEN]; /* Node name, hex string, sha1-size */
// 节点标识
// 使用各种不同的标识值记录节点的角色(比如主节点或者从节点),
// 以及节点目前所处的状态(比如在线或者下线)。
int flags; /* REDIS_NODE_... */
// 节点当前的配置纪元,用于实现故障转移
uint64_t configEpoch; /* Last configEpoch observed for this node */
// 由这个节点负责处理的槽
// 一共有 REDIS_CLUSTER_SLOTS / 8 个字节长
// 每个字节的每个位记录了一个槽的保存状态
// 位的值为 1 表示槽正由本节点处理,值为 0 则表示槽并非本节点处理
// 比如 slots[0] 的第一个位保存了槽 0 的保存情况
// slots[0] 的第二个位保存了槽 1 的保存情况,以此类推
unsigned char slots[REDIS_CLUSTER_SLOTS/8]; /* slots handled by this node */
// 该节点负责处理的槽数量
int numslots; /* Number of slots handled by this node */
// 如果本节点是主节点,那么用这个属性记录从节点的数量
int numslaves; /* Number of slave nodes, if this is a master */
// 指针数组,指向各个从节点
struct clusterNode **slaves; /* pointers to slave nodes */
// 如果这是一个从节点,那么指向主节点
struct clusterNode *slaveof; /* pointer to the master node */
// 最后一次发送 PING 命令的时间
mstime_t ping_sent; /* Unix time we sent latest ping */
// 最后一次接收 PONG 回复的时间戳
mstime_t pong_received; /* Unix time we received the pong */
// 最后一次被设置为 FAIL 状态的时间
mstime_t fail_time; /* Unix time when FAIL flag was set */
// 最后一次给某个从节点投票的时间
mstime_t voted_time; /* Last time we voted for a slave of this master */
// 最后一次从这个节点接收到复制偏移量的时间
mstime_t repl_offset_time; /* Unix time we received offset for this node */
// 这个节点的复制偏移量
long long repl_offset; /* Last known repl offset for this node. */
// 节点的 IP 地址
char ip[REDIS_IP_STR_LEN]; /* Latest known IP address of this node */
// 节点的端口号
int port; /* Latest known port of this node */
// 保存连接节点所需的有关信息
clusterLink *link; /* TCP/IP link with this node */
// 一个链表,记录了所有其他节点对该节点的下线报告
list *fail_reports; /* List of nodes signaling this as failing */
}
-----------------------------------华丽分割线-------------------------------------------
// clusterLink 包含了与其他节点进行通讯所需的全部信息
typedef struct clusterLink {
// 连接的创建时间
mstime_t ctime; /* Link creation time */
// TCP 套接字描述符
int fd; /* TCP socket file descriptor */
// 输出缓冲区,保存着等待发送给其他节点的消息(message)。
sds sndbuf; /* Packet send buffer */
// 输入缓冲区,保存着从其他节点接收到的消息。
sds rcvbuf; /* Packet reception buffer */
// 与这个连接相关联的节点,如果没有的话就为 NULL
struct clusterNode *node; /* Node related to this link if any, or NULL */
} clusterLink;
cluster启动过程
redis cluster启动过程中主要完成了一下几件事情:
- 创建server.cluster的信息(是个clusterState对象),变量值都为空。
- 如果有server.cluster_configfile就直接初始化clusterNode对象,如果没有就创建clusterNode对象并保存至server.cluster_configfile对象,server本身的clusterNode对象保存至server.cluster->nodes和server.cluster->myself当中。
- 监听cluster相关端口:cluster的监听端口=redis 监听端口+10000
- 绑定cluster端口的读事件到clusterAcceptHandler用于处理cluster的连接请求
- clusterAcceptHandler内部绑定accept的socket的读事件到clusterReadHandler
- clusterReadHandler内部读取数据后交由clusterProcessPacket继续后续处理
// 初始化集群
void clusterInit(void) {
int saveconf = 0;
// 初始化配置
server.cluster = zmalloc(sizeof(clusterState));
server.cluster->myself = NULL;
server.cluster->currentEpoch = 0;
server.cluster->state = REDIS_CLUSTER_FAIL;
server.cluster->size = 1;
server.cluster->todo_before_sleep = 0;
server.cluster->nodes = dictCreate(&clusterNodesDictType,NULL);
server.cluster->nodes_black_list =
dictCreate(&clusterNodesBlackListDictType,NULL);
server.cluster->failover_auth_time = 0;
server.cluster->failover_auth_count = 0;
server.cluster->failover_auth_rank = 0;
server.cluster->failover_auth_epoch = 0;
server.cluster->lastVoteEpoch = 0;
server.cluster->stats_bus_messages_sent = 0;
server.cluster->stats_bus_messages_received = 0;
memset(server.cluster->slots,0, sizeof(server.cluster->slots));
clusterCloseAllSlots();
if (clusterLockConfig(server.cluster_configfile) == REDIS_ERR)
exit(1);
if (clusterLoadConfig(server.cluster_configfile) == REDIS_ERR) {
/* No configuration found. We will just use the random name provided
* by the createClusterNode() function. */
myself = server.cluster->myself =
createClusterNode(NULL,REDIS_NODE_MYSELF|REDIS_NODE_MASTER);
redisLog(REDIS_NOTICE,"No cluster configuration found, I'm %.40s",
myself->name);
clusterAddNode(myself);
saveconf = 1;
}
// 保存 nodes.conf 文件
if (saveconf) clusterSaveConfigOrDie(1);
/* We need a listening TCP port for our cluster messaging needs. */
// 监听 TCP 端口
server.cfd_count = 0;
/* Port sanity check II
* The other handshake port check is triggered too late to stop
* us from trying to use a too-high cluster port number. */
if (server.port > (65535-REDIS_CLUSTER_PORT_INCR)) {
redisLog(REDIS_WARNING, "Redis port number too high. "
"Cluster communication port is 10,000 port "
"numbers higher than your Redis port. "
"Your Redis port number must be "
"lower than 55535.");
exit(1);
}
if (listenToPort(server.port+REDIS_CLUSTER_PORT_INCR,
server.cfd,&server.cfd_count) == REDIS_ERR)
{
exit(1);
} else {
int j;
for (j = 0; j < server.cfd_count; j++) {
// 关联监听事件处理器
if (aeCreateFileEvent(server.el, server.cfd[j], AE_READABLE,
clusterAcceptHandler, NULL) == AE_ERR)
redisPanic("Unrecoverable error creating Redis Cluster "
"file event.");
}
}
/* The slots -> keys map is a sorted set. Init it. */
// slots -> keys 映射是一个有序集合
server.cluster->slots_to_keys = zslCreate();
resetManualFailover();
}
redis cluster之间监听端口读事件对应的处理函数clusterAcceptHandler,负责处理集群连接事件的回调函数。
void clusterAcceptHandler(aeEventLoop *el, int fd, void *privdata, int mask) {
int cport, cfd;
int max = MAX_CLUSTER_ACCEPTS_PER_CALL;
char cip[REDIS_IP_STR_LEN];
clusterLink *link;
REDIS_NOTUSED(el);
REDIS_NOTUSED(mask);
REDIS_NOTUSED(privdata);
/* If the server is starting up, don't accept cluster connections:
* UPDATE messages may interact with the database content. */
if (server.masterhost == NULL && server.loading) return;
while(max--) {
cfd = anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport);
if (cfd == ANET_ERR) {
if (errno != EWOULDBLOCK)
redisLog(REDIS_VERBOSE,
"Accepting cluster node: %s", server.neterr);
return;
}
anetNonBlock(NULL,cfd);
anetEnableTcpNoDelay(NULL,cfd);
redisLog(REDIS_VERBOSE,"Accepted cluster node %s:%d", cip, cport);
link = createClusterLink(NULL);
link->fd = cfd;
aeCreateFileEvent(server.el,cfd,AE_READABLE,clusterReadHandler,link);
}
}
redis cluster之间处理socket通信报文的回调函数
// 读事件处理器
// 首先读入内容的头,以判断读入内容的长度
// 如果内容是一个 whole packet ,那么调用函数来处理这个 packet 。
void clusterReadHandler(aeEventLoop *el, int fd, void *privdata, int mask) {
char buf[sizeof(clusterMsg)];
ssize_t nread;
clusterMsg *hdr;
clusterLink *link = (clusterLink*) privdata;
int readlen, rcvbuflen;
REDIS_NOTUSED(el);
REDIS_NOTUSED(mask);
// 尽可能地多读数据
while(1) { /* Read as long as there is data to read. */
// 检查输入缓冲区的长度
rcvbuflen = sdslen(link->rcvbuf);
// 头信息(8 字节)未读入完
if (rcvbuflen < 8) {
/* First, obtain the first 8 bytes to get the full message
* length. */
readlen = 8 - rcvbuflen;
// 已读入完整的信息
} else {
/* Finally read the full message. */
hdr = (clusterMsg*) link->rcvbuf;
if (rcvbuflen == 8) {
/* Perform some sanity check on the message signature
* and length. */
if (memcmp(hdr->sig,"RCmb",4) != 0 ||
ntohl(hdr->totlen) < CLUSTERMSG_MIN_LEN)
{
redisLog(REDIS_WARNING,
"Bad message length or signature received "
"from Cluster bus.");
handleLinkIOError(link);
return;
}
}
// 记录已读入内容长度
readlen = ntohl(hdr->totlen) - rcvbuflen;
if (readlen > sizeof(buf)) readlen = sizeof(buf);
}
// 读入内容
nread = read(fd,buf,readlen);
// 没有内容可读
if (nread == -1 && errno == EAGAIN) return; /* No more data ready. */
// 处理读入错误
if (nread <= 0) {
/* I/O error... */
redisLog(REDIS_DEBUG,"I/O error reading from node link: %s",
(nread == 0) ? "connection closed" : strerror(errno));
handleLinkIOError(link);
return;
} else {
/* Read data and recast the pointer to the new buffer. */
// 将读入的内容追加进输入缓冲区里面
link->rcvbuf = sdscatlen(link->rcvbuf,buf,nread);
hdr = (clusterMsg*) link->rcvbuf;
rcvbuflen += nread;
}
/* Total length obtained? Process this packet. */
// 检查已读入内容的长度,看是否整条信息已经被读入了
if (rcvbuflen >= 8 && rcvbuflen == ntohl(hdr->totlen)) {
// 如果是的话,执行处理信息的函数
if (clusterProcessPacket(link)) {
sdsfree(link->rcvbuf);
link->rcvbuf = sdsempty();
} else {
return; /* Link no longer valid. */
}
}
}
}
cluster加入集群过程
redis cluster节点之间的网络连接图如下图所示(假设总共有N个节点),主要特点是:
- 每个节点都与剩余的N-1个节点建立连接。
- 任意两个节点之间有两个网络连接,注意是两个网络连接。
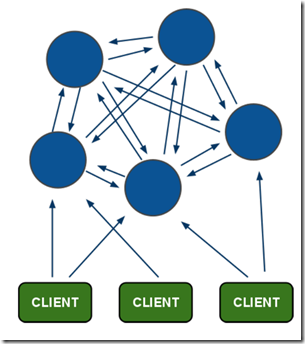
redis cluster集群节点之间建立连接过程如下,假设现在有ABCDE公5个几点:
- 在节点A依次执行 cluster meet B,cluster meet C,cluster meet D,cluster meet E。
- AB,AC,AD,AE之间建立了连接
- 节点BCDE在接收到A的连接请求后会获取节点A的信息,反向在BA,CA,DA,EA之间建立连接
- 节点AB通信过程中,节点A会携带CDE的信息给节点B,那么在BC, BD,BE之间建立连接
- 节点AC通信过程中,节点A会携带BDE的信息给节点C,那么在CB,CD,CE之间建立连接
- 节点AD通信过程中,节点A会携带BCE的信息给节点D,那么在DB,DC,DE之间建立连接
- 节点AE通信过程中,节点A会携带BCD的信息给节点E,那么在EB,EC,ED之间建立连接
至此节点ABCDE之间就建立了相互之间的连接了。
这里想说明的是两个节点之间通信的时候,发起者会携带它自身知道的其他节点给对方节点,通过这种方式实现整体网络的建立
cluster加入集群源码
cluster meet命令被用来连接不同的开启集群支持的 Redis 节点,以进入工作集群。
- 系统管理员发送一个cluster meet命令强制一个节点去会面另一个节点。
- 一个已知的节点发送一个保存在 gossip 部分的节点列表,包含着未知的节点。如果接收的节点已经将发送节点信任为已知节点,它会处理 gossip 部分并且发送一个握手消息给未知的节点。
clusterCommand方法内部有处理各种命令的逻辑,这里我只关注了处理meet命令的逻辑。
clusterCommand内部通过clusterStartHandshake执行cluster meet当中指定的地址去执行握手协议。
{"cluster",clusterCommand,-2,"ar",0,NULL,0,0,0,0,0},
// CLUSTER 命令的实现
void clusterCommand(redisClient *c) {
// 不能在非集群模式下使用该命令
if (server.cluster_enabled == 0) {
addReplyError(c,"This instance has cluster support disabled");
return;
}
if (!strcasecmp(c->argv[1]->ptr,"meet") && c->argc == 4) {
/* CLUSTER MEET <ip> <port> */
// 将给定地址的节点添加到当前节点所处的集群里面
long long port;
// 检查 port 参数的合法性
if (getLongLongFromObject(c->argv[3], &port) != REDIS_OK) {
addReplyErrorFormat(c,"Invalid TCP port specified: %s",
(char*)c->argv[3]->ptr);
return;
}
// 尝试与给定地址的节点进行连接
if (clusterStartHandshake(c->argv[2]->ptr,port) == 0 &&
errno == EINVAL)
{
// 连接失败
addReplyErrorFormat(c,"Invalid node address specified: %s:%s",
(char*)c->argv[2]->ptr, (char*)c->argv[3]->ptr);
} else {
// 连接成功
addReply(c,shared.ok);
}
}
}
redis cluster在执行握手的函数clusterStartHandshake当中,生成待连接的clusterNode对象并保存待连接的ip:port地址,并未真正执行连接而只是生成了待连接的对象,真正的连接是在serverCron当中完成的。
/*
* 如果还没有与指定的地址进行过握手,那么进行握手。
* 返回 1 表示握手已经开始,
* 返回 0 并将 errno 设置为以下值来表示意外情况:
*
* EAGAIN - There is already an handshake in progress for this address.
* 已经有握手在进行中了。
* EINVAL - IP or port are not valid.
* ip 或者 port 参数不合法。
*/
int clusterStartHandshake(char *ip, int port) {
clusterNode *n;
char norm_ip[REDIS_IP_STR_LEN];
struct sockaddr_storage sa;
// ip 合法性检查
if (inet_pton(AF_INET,ip,
&(((struct sockaddr_in *)&sa)->sin_addr)))
{
sa.ss_family = AF_INET;
} else if (inet_pton(AF_INET6,ip,
&(((struct sockaddr_in6 *)&sa)->sin6_addr)))
{
sa.ss_family = AF_INET6;
} else {
errno = EINVAL;
return 0;
}
// port 合法性检查
if (port <= 0 || port > (65535-REDIS_CLUSTER_PORT_INCR)) {
errno = EINVAL;
return 0;
}
if (sa.ss_family == AF_INET)
inet_ntop(AF_INET,
(void*)&(((struct sockaddr_in *)&sa)->sin_addr),
norm_ip,REDIS_IP_STR_LEN);
else
inet_ntop(AF_INET6,
(void*)&(((struct sockaddr_in6 *)&sa)->sin6_addr),
norm_ip,REDIS_IP_STR_LEN);
// 检查节点是否已经发送握手请求,如果是的话,那么直接返回,防止出现重复握手
if (clusterHandshakeInProgress(norm_ip,port)) {
errno = EAGAIN;
return 0;
}
// 对给定地址的节点设置一个随机名字
// 当 HANDSHAKE 完成时,当前节点会取得给定地址节点的真正名字
// 到时会用真名替换随机名,是在返回的pong报文当中带上真正的名字
n = createClusterNode(NULL,REDIS_NODE_HANDSHAKE|REDIS_NODE_MEET);
memcpy(n->ip,norm_ip,sizeof(n->ip));
n->port = port;
// 将节点添加到集群当中
clusterAddNode(n);
return 1;
}
// 将给定 node 添加到节点表里面
int clusterAddNode(clusterNode *node) {
int retval;
// 将 node 添加到当前节点的 nodes 表中
// 这样接下来当前节点就会创建连向 node 的节点
retval = dictAdd(server.cluster->nodes,
sdsnewlen(node->name,REDIS_CLUSTER_NAMELEN), node);
return (retval == DICT_OK) ? REDIS_OK : REDIS_ERR;
}
cluster集群发现过程
cluster集群发现过程-client端
在serverCron当中会调用clusterCron执行redis cluster发现的逻辑,整个逻辑如下:
- 遍历server.cluster->nodes发现待握手的节点进行连接。
- 针对未建立连接的node创建对应的ClusterLink,建立link和node之间的关联,link表示链接用于关联本端的fd和远端的node。
- 通过建立的socket连接发送meet报文即通过clusterSendPing去实现。
- 定期选择一个node发送ping报文交换gossip信息
- 清理已经下线的redis cluster node等等
// 集群常规操作函数,默认每秒执行 10 次(每间隔 100 毫秒执行一次)
void clusterCron(void) {
dictIterator *di;
dictEntry *de;
int update_state = 0;
int orphaned_masters; /* How many masters there are without ok slaves. */
int max_slaves; /* Max number of ok slaves for a single master. */
int this_slaves; /* Number of ok slaves for our master (if we are slave). */
mstime_t min_pong = 0, now = mstime();
clusterNode *min_pong_node = NULL;
// 迭代计数器,一个静态变量
static unsigned long long iteration = 0;
mstime_t handshake_timeout;
// 记录一次迭代
iteration++;
// 如果一个 handshake 节点没有在 handshake timeout 内
// 转换成普通节点(normal node),
// 那么节点会从 nodes 表中移除这个 handshake 节点
// 一般来说 handshake timeout 的值总是等于 NODE_TIMEOUT
// 不过如果 NODE_TIMEOUT 太少的话,程序会将值设为 1 秒钟
handshake_timeout = server.cluster_node_timeout;
if (handshake_timeout < 1000) handshake_timeout = 1000;
// 向集群中的所有断线或者未连接节点发送消息
di = dictGetSafeIterator(server.cluster->nodes);
while((de = dictNext(di)) != NULL) {
clusterNode *node = dictGetVal(de);
// 跳过当前节点以及没有地址的节点
if (node->flags & (REDIS_NODE_MYSELF|REDIS_NODE_NOADDR)) continue;
// 如果 handshake 节点已超时,释放它
if (nodeInHandshake(node) && now - node->ctime > handshake_timeout) {
freeClusterNode(node);
continue;
}
// 为未创建连接的节点创建连接
if (node->link == NULL) {
int fd;
mstime_t old_ping_sent;
clusterLink *link;
fd = anetTcpNonBlockBindConnect(server.neterr, node->ip,
node->port+REDIS_CLUSTER_PORT_INCR,
server.bindaddr_count ? server.bindaddr[0] : NULL);
if (fd == -1) {
redisLog(REDIS_DEBUG, "Unable to connect to "
"Cluster Node [%s]:%d -> %s", node->ip,
node->port+REDIS_CLUSTER_PORT_INCR,
server.neterr);
continue;
}
link = createClusterLink(node);
link->fd = fd;
node->link = link;
aeCreateFileEvent(server.el,link->fd,AE_READABLE,
clusterReadHandler,link);
// 向新连接的节点发送 PING 命令,防止节点被识进入下线
// 如果节点被标记为 MEET ,那么发送 MEET 命令,否则发送 PING 命令
old_ping_sent = node->ping_sent;
clusterSendPing(link, node->flags & REDIS_NODE_MEET ?
CLUSTERMSG_TYPE_MEET : CLUSTERMSG_TYPE_PING);
// 这不是第一次发送 PING 信息,所以可以还原这个时间
// 等 clusterSendPing() 函数来更新它
if (old_ping_sent) {
node->ping_sent = old_ping_sent;
}
/*
* 在发送 MEET 信息之后,清除节点的 MEET 标识。
*
* 如果当前节点(发送者)没能收到 MEET 信息的回复,
* 那么它将不再向目标节点发送命令。
*
* 如果接收到回复的话,那么节点将不再处于 HANDSHAKE 状态,
* 并继续向目标节点发送普通 PING 命令。
*/
node->flags &= ~REDIS_NODE_MEET;
redisLog(REDIS_DEBUG,"Connecting with Node %.40s at %s:%d",
node->name, node->ip, node->port+REDIS_CLUSTER_PORT_INCR);
}
}
dictReleaseIterator(di);
// clusterCron() 每执行 10 次(至少间隔一秒钟),就向一个随机节点发送 gossip 信息
if (!(iteration % 10)) {
int j;
// 随机 5 个节点,选出其中一个
for (j = 0; j < 5; j++) {
// 随机在集群中挑选节点
de = dictGetRandomKey(server.cluster->nodes);
clusterNode *this = dictGetVal(de);
// 不要 PING 连接断开的节点,也不要 PING 最近已经 PING 过的节点
if (this->link == NULL || this->ping_sent != 0) continue;
if (this->flags & (REDIS_NODE_MYSELF|REDIS_NODE_HANDSHAKE))
continue;
// 选出 5 个随机节点中最近一次接收 PONG 回复距离现在最旧的节点
if (min_pong_node == NULL || min_pong > this->pong_received) {
min_pong_node = this;
min_pong = this->pong_received;
}
}
// 向最久没有收到 PONG 回复的节点发送 PING 命令
if (min_pong_node) {
redisLog(REDIS_DEBUG,"Pinging node %.40s", min_pong_node->name);
clusterSendPing(min_pong_node->link, CLUSTERMSG_TYPE_PING);
}
}
// 遍历所有节点,检查是否需要将某个节点标记为下线
orphaned_masters = 0;
max_slaves = 0;
this_slaves = 0;
di = dictGetSafeIterator(server.cluster->nodes);
while((de = dictNext(di)) != NULL) {
clusterNode *node = dictGetVal(de);
now = mstime(); /* Use an updated time at every iteration. */
mstime_t delay;
// 跳过节点本身、无地址节点、HANDSHAKE 状态的节点
if (node->flags &
(REDIS_NODE_MYSELF|REDIS_NODE_NOADDR|REDIS_NODE_HANDSHAKE))
continue;
if (nodeIsSlave(myself) && nodeIsMaster(node) && !nodeFailed(node)) {
int okslaves = clusterCountNonFailingSlaves(node);
if (okslaves == 0 && node->numslots > 0) orphaned_masters++;
if (okslaves > max_slaves) max_slaves = okslaves;
if (nodeIsSlave(myself) && myself->slaveof == node)
this_slaves = okslaves;
}
// 如果等到 PONG 到达的时间超过了 node timeout 一半的连接
// 因为尽管节点依然正常,但连接可能已经出问题了
if (node->link && /* is connected */
now - node->link->ctime >
server.cluster_node_timeout &&
node->ping_sent &&
node->pong_received < node->ping_sent &&
now - node->ping_sent > server.cluster_node_timeout/2)
{
/* Disconnect the link, it will be reconnected automatically. */
// 释放连接,下次 clusterCron() 会自动重连
freeClusterLink(node->link);
}
// 如果目前没有在 PING 节点
// 并且已经有 node timeout 一半的时间没有从节点那里收到 PONG 回复
// 那么向节点发送一个 PING ,确保节点的信息不会太旧
// (因为一部分节点可能一直没有被随机中)
if (node->link &&
node->ping_sent == 0 &&
(now - node->pong_received) > server.cluster_node_timeout/2)
{
clusterSendPing(node->link, CLUSTERMSG_TYPE_PING);
continue;
}
// 如果这是一个主节点,并且有一个从服务器请求进行手动故障转移
// 那么向从服务器发送 PING 。
if (server.cluster->mf_end &&
nodeIsMaster(myself) &&
server.cluster->mf_slave == node &&
node->link)
{
clusterSendPing(node->link, CLUSTERMSG_TYPE_PING);
continue;
}
// 以下代码只在节点发送了 PING 命令的情况下执行
if (node->ping_sent == 0) continue;
// 计算等待 PONG 回复的时长
delay = now - node->ping_sent;
// 等待 PONG 回复的时长超过了限制值,将目标节点标记为 PFAIL (疑似下线)
if (delay > server.cluster_node_timeout) {
if (!(node->flags & (REDIS_NODE_PFAIL|REDIS_NODE_FAIL))) {
redisLog(REDIS_DEBUG,"*** NODE %.40s possibly failing",
node->name);
// 打开疑似下线标记
node->flags |= REDIS_NODE_PFAIL;
update_state = 1;
}
}
}
dictReleaseIterator(di);
// 如果从节点没有在复制主节点,那么对从节点进行设置
if (nodeIsSlave(myself) &&
server.masterhost == NULL &&
myself->slaveof &&
nodeHasAddr(myself->slaveof))
{
replicationSetMaster(myself->slaveof->ip, myself->slaveof->port);
}
manualFailoverCheckTimeout();
if (nodeIsSlave(myself)) {
clusterHandleManualFailover();
clusterHandleSlaveFailover();
if (orphaned_masters && max_slaves >= 2 && this_slaves == max_slaves)
clusterHandleSlaveMigration(max_slaves);
}
// 更新集群状态
if (update_state || server.cluster->state == REDIS_CLUSTER_FAIL)
clusterUpdateState();
}
clusterSendPing的过程中最核心的就是在发送ping报文或者meet报文的时候,都会携带本节点已知的节点即gossip信息,这样就可以扩展本节点知道的节点信息给其他节点达到扩展的目的。
按照源码中的意思每次是携带至多3个已经节点,但是不知道为啥作者的注释当中写的是2。
// 向指定节点发送一条 MEET 、 PING 或者 PONG 消息
void clusterSendPing(clusterLink *link, int type) {
unsigned char buf[sizeof(clusterMsg)];
clusterMsg *hdr = (clusterMsg*) buf;
int gossipcount = 0, totlen;
// freshnodes 是用于发送 gossip 信息的计数器
// 每次发送一条信息时,程序将 freshnodes 的值减一
// 当 freshnodes 的数值小于等于 0 时,程序停止发送 gossip 信息
// freshnodes 的数量是节点目前的 nodes 表中的节点数量减去 2
// 这里的 2 指两个节点,一个是 myself 节点(也即是发送信息的这个节点)
// 另一个是接受 gossip 信息的节点
int freshnodes = dictSize(server.cluster->nodes)-2;
// 如果发送的信息是 PING ,那么更新最后一次发送 PING 命令的时间戳
if (link->node && type == CLUSTERMSG_TYPE_PING)
link->node->ping_sent = mstime();
// 将当前节点的信息(比如名字、地址、端口号、负责处理的槽)记录到消息里面
clusterBuildMessageHdr(hdr,type);
// 从当前节点已知的节点中随机选出两个节点
// 并通过这条消息捎带给目标节点,从而实现 gossip 协议
// 每个节点有 freshnodes 次发送 gossip 信息的机会
// 每次向目标节点发送 2 个被选中节点的 gossip 信息(gossipcount 计数)
while(freshnodes > 0 && gossipcount < 3) {
// 从 nodes 字典中随机选出一个节点(被选中节点)
dictEntry *de = dictGetRandomKey(server.cluster->nodes);
clusterNode *this = dictGetVal(de);
clusterMsgDataGossip *gossip;
int j;
/*
* 以下节点不能作为被选中节点:
* 1)节点本身。
* 2) 处于 HANDSHAKE 状态的节点。
* 3) 带有 NOADDR 标识的节点
* 4) 因为不处理任何槽而被断开连接的节点
*/
if (this == myself ||
this->flags & (REDIS_NODE_HANDSHAKE|REDIS_NODE_NOADDR) ||
(this->link == NULL && this->numslots == 0))
{
freshnodes--; /* otherwise we may loop forever. */
continue;
}
// 检查被选中节点是否已经在 hdr->data.ping.gossip 数组里面
// 如果是的话说明这个节点之前已经被选中了
// 不要再选中它(否则就会出现重复)
for (j = 0; j < gossipcount; j++) {
if (memcmp(hdr->data.ping.gossip[j].nodename,this->name,
REDIS_CLUSTER_NAMELEN) == 0) break;
}
if (j != gossipcount) continue;
// 这个被选中节点有效,计数器减一
freshnodes--;
// 指向 gossip 信息结构
gossip = &(hdr->data.ping.gossip[gossipcount]);
// 将被选中节点的名字记录到 gossip 信息
memcpy(gossip->nodename,this->name,REDIS_CLUSTER_NAMELEN);
// 将被选中节点的 PING 命令发送时间戳记录到 gossip 信息
gossip->ping_sent = htonl(this->ping_sent);
// 将被选中节点的 PING 命令回复的时间戳记录到 gossip 信息
gossip->pong_received = htonl(this->pong_received);
// 将被选中节点的 IP 记录到 gossip 信息
memcpy(gossip->ip,this->ip,sizeof(this->ip));
// 将被选中节点的端口号记录到 gossip 信息
gossip->port = htons(this->port);
// 将被选中节点的标识值记录到 gossip 信息
gossip->flags = htons(this->flags);
// 这个被选中节点有效,计数器增一
gossipcount++;
}
// 计算信息长度
totlen = sizeof(clusterMsg)-sizeof(union clusterMsgData);
totlen += (sizeof(clusterMsgDataGossip)*gossipcount);
// 将被选中节点的数量(gossip 信息中包含了多少个节点的信息)
// 记录在 count 属性里面
hdr->count = htons(gossipcount);
// 将信息的长度记录到信息里面
hdr->totlen = htonl(totlen);
// 发送信息
clusterSendMessage(link,buf,totlen);
}
cluster集群发现过程-server端
在redis 的server端主要做两个事情:
- 通过clusterAcceptHandler接受连接的socket并建立socket对应的ClusterLink便于接收ping或者meet报文时候可以回应报文。
- 注册fd的读事件到处理函数clusterReadHandler当中。
void clusterAcceptHandler(aeEventLoop *el, int fd, void *privdata, int mask) {
int cport, cfd;
int max = MAX_CLUSTER_ACCEPTS_PER_CALL;
char cip[REDIS_IP_STR_LEN];
clusterLink *link;
REDIS_NOTUSED(el);
REDIS_NOTUSED(mask);
REDIS_NOTUSED(privdata);
/* If the server is starting up, don't accept cluster connections:
* UPDATE messages may interact with the database content. */
if (server.masterhost == NULL && server.loading) return;
while(max--) {
cfd = anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport);
if (cfd == ANET_ERR) {
if (errno != EWOULDBLOCK)
redisLog(REDIS_VERBOSE,
"Accepting cluster node: %s", server.neterr);
return;
}
anetNonBlock(NULL,cfd);
anetEnableTcpNoDelay(NULL,cfd);
redisLog(REDIS_VERBOSE,"Accepted cluster node %s:%d", cip, cport);
link = createClusterLink(NULL);
link->fd = cfd;
aeCreateFileEvent(server.el,cfd,AE_READABLE,clusterReadHandler,link);
}
}
clusterReadHandler的内部主要读取报文的内容然后交由clusterProcessPacket去处理报文。
// 读事件处理器
// 首先读入内容的头,以判断读入内容的长度
// 如果内容是一个 whole packet ,那么调用函数来处理这个 packet 。
void clusterReadHandler(aeEventLoop *el, int fd, void *privdata, int mask) {
char buf[sizeof(clusterMsg)];
ssize_t nread;
clusterMsg *hdr;
clusterLink *link = (clusterLink*) privdata;
int readlen, rcvbuflen;
REDIS_NOTUSED(el);
REDIS_NOTUSED(mask);
// 尽可能地多读数据
while(1) { /* Read as long as there is data to read. */
// 检查输入缓冲区的长度
rcvbuflen = sdslen(link->rcvbuf);
// 头信息(8 字节)未读入完
if (rcvbuflen < 8) {
/* First, obtain the first 8 bytes to get the full message
* length. */
readlen = 8 - rcvbuflen;
// 已读入完整的信息
} else {
/* Finally read the full message. */
hdr = (clusterMsg*) link->rcvbuf;
if (rcvbuflen == 8) {
if (memcmp(hdr->sig,"RCmb",4) != 0 ||
ntohl(hdr->totlen) < CLUSTERMSG_MIN_LEN)
{
redisLog(REDIS_WARNING,
"Bad message length or signature received "
"from Cluster bus.");
handleLinkIOError(link);
return;
}
}
// 记录已读入内容长度
readlen = ntohl(hdr->totlen) - rcvbuflen;
if (readlen > sizeof(buf)) readlen = sizeof(buf);
}
// 读入内容
nread = read(fd,buf,readlen);
// 没有内容可读
if (nread == -1 && errno == EAGAIN) return; /* No more data ready. */
// 处理读入错误
if (nread <= 0) {
/* I/O error... */
redisLog(REDIS_DEBUG,"I/O error reading from node link: %s",
(nread == 0) ? "connection closed" : strerror(errno));
handleLinkIOError(link);
return;
} else {
/* Read data and recast the pointer to the new buffer. */
// 将读入的内容追加进输入缓冲区里面
link->rcvbuf = sdscatlen(link->rcvbuf,buf,nread);
hdr = (clusterMsg*) link->rcvbuf;
rcvbuflen += nread;
}
/* Total length obtained? Process this packet. */
// 检查已读入内容的长度,看是否整条信息已经被读入了
if (rcvbuflen >= 8 && rcvbuflen == ntohl(hdr->totlen)) {
// 如果是的话,执行处理信息的函数
if (clusterProcessPacket(link)) {
sdsfree(link->rcvbuf);
link->rcvbuf = sdsempty();
} else {
return; /* Link no longer valid. */
}
}
}
}
clusterProcessPacket内部针对第一次发起连接的节点主要做了下面事情:
- 针对发起连接的redis 节点发起createClusterNode操作并添加到待连接的节点当中。
- 针对携带的gossip信息,会解析里面的信息找到携带的redis 节点然后添加到待连接的节点当中。
- 发送响应报文,内部携带这个节点的关键信息即节点名称便于发起端redis节点维持正确的节点名和连接映射关系
- 整个内部处理过程中处理的所有情况,这里只针对建立连接的过程做了简单分析。
/*
* 当这个函数被调用时,说明 node->rcvbuf 中有一条待处理的信息。
* 信息处理完毕之后的释放工作由调用者处理,所以这个函数只需负责处理信息就可以了。
*
* 如果函数返回 1 ,那么说明处理信息时没有遇到问题,连接依然可用。
* 如果函数返回 0 ,那么说明信息处理时遇到了不一致问题
* (比如接收到的 PONG 是发送自不正确的发送者 ID 的),连接已经被释放。
*/
int clusterProcessPacket(clusterLink *link) {
// 指向消息头
clusterMsg *hdr = (clusterMsg*) link->rcvbuf;
// 消息的长度
uint32_t totlen = ntohl(hdr->totlen);
// 消息的类型
uint16_t type = ntohs(hdr->type);
// 消息发送者的标识
uint16_t flags = ntohs(hdr->flags);
uint64_t senderCurrentEpoch = 0, senderConfigEpoch = 0;
clusterNode *sender;
// 更新接受消息计数器
server.cluster->stats_bus_messages_received++;
redisLog(REDIS_DEBUG,"--- Processing packet of type %d, %lu bytes",
type, (unsigned long) totlen);
// 合法性检查
if (totlen < 16) return 1;
if (ntohs(hdr->ver) != 0) return 1;
if (totlen > sdslen(link->rcvbuf)) return 1;
if (type == CLUSTERMSG_TYPE_PING || type == CLUSTERMSG_TYPE_PONG ||
type == CLUSTERMSG_TYPE_MEET)
{
uint16_t count = ntohs(hdr->count);
uint32_t explen; /* expected length of this packet */
explen = sizeof(clusterMsg)-sizeof(union clusterMsgData);
explen += (sizeof(clusterMsgDataGossip)*count);
if (totlen != explen) return 1;
} else if (type == CLUSTERMSG_TYPE_FAIL) {
uint32_t explen = sizeof(clusterMsg)-sizeof(union clusterMsgData);
explen += sizeof(clusterMsgDataFail);
if (totlen != explen) return 1;
} else if (type == CLUSTERMSG_TYPE_PUBLISH) {
uint32_t explen = sizeof(clusterMsg)-sizeof(union clusterMsgData);
explen += sizeof(clusterMsgDataPublish) +
ntohl(hdr->data.publish.msg.channel_len) +
ntohl(hdr->data.publish.msg.message_len);
if (totlen != explen) return 1;
} else if (type == CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST ||
type == CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK ||
type == CLUSTERMSG_TYPE_MFSTART)
{
uint32_t explen = sizeof(clusterMsg)-sizeof(union clusterMsgData);
if (totlen != explen) return 1;
} else if (type == CLUSTERMSG_TYPE_UPDATE) {
uint32_t explen = sizeof(clusterMsg)-sizeof(union clusterMsgData);
explen += sizeof(clusterMsgDataUpdate);
if (totlen != explen) return 1;
}
// 查找发送者节点
sender = clusterLookupNode(hdr->sender);
// 节点存在,并且不是 HANDSHAKE 节点
// 那么个更新节点的配置纪元信息
if (sender && !nodeInHandshake(sender)) {
/* Update our curretEpoch if we see a newer epoch in the cluster. */
senderCurrentEpoch = ntohu64(hdr->currentEpoch);
senderConfigEpoch = ntohu64(hdr->configEpoch);
if (senderCurrentEpoch > server.cluster->currentEpoch)
server.cluster->currentEpoch = senderCurrentEpoch;
/* Update the sender configEpoch if it is publishing a newer one. */
if (senderConfigEpoch > sender->configEpoch) {
sender->configEpoch = senderConfigEpoch;
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG|
CLUSTER_TODO_FSYNC_CONFIG);
}
sender->repl_offset = ntohu64(hdr->offset);
sender->repl_offset_time = mstime();
if (server.cluster->mf_end &&
nodeIsSlave(myself) &&
myself->slaveof == sender &&
hdr->mflags[0] & CLUSTERMSG_FLAG0_PAUSED &&
server.cluster->mf_master_offset == 0)
{
server.cluster->mf_master_offset = sender->repl_offset;
redisLog(REDIS_WARNING,
"Received replication offset for paused "
"master manual failover: %lld",
server.cluster->mf_master_offset);
}
}
// 根据消息的类型,处理节点
// 这是一条 PING 消息或者 MEET 消息
if (type == CLUSTERMSG_TYPE_PING || type == CLUSTERMSG_TYPE_MEET) {
redisLog(REDIS_DEBUG,"Ping packet received: %p", (void*)link->node);
/*
* 如果当前节点是第一次遇见这个节点,并且对方发来的是 MEET 信息,
* 那么将这个节点添加到集群的节点列表里面。
*
* 节点目前的 flag 、 slaveof 等属性的值都是未设置的,
* 等当前节点向对方发送 PING 命令之后,
* 这些信息可以从对方回复的 PONG 信息中取得。
*/
if (!sender && type == CLUSTERMSG_TYPE_MEET) {
clusterNode *node;
// 创建 HANDSHAKE 状态的新节点
node = createClusterNode(NULL,REDIS_NODE_HANDSHAKE);
// 设置 IP 和端口
nodeIp2String(node->ip,link);
node->port = ntohs(hdr->port);
// 将新节点添加到集群
clusterAddNode(node);
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG);
}
// 分析并取出消息中的 gossip 节点信息
clusterProcessGossipSection(hdr,link);
// 向目标节点返回一个 PONG
clusterSendPing(link,CLUSTERMSG_TYPE_PONG);
}
// 这是一条 PING 、 PONG 或者 MEET 消息
if (type == CLUSTERMSG_TYPE_PING || type == CLUSTERMSG_TYPE_PONG ||
type == CLUSTERMSG_TYPE_MEET)
{
redisLog(REDIS_DEBUG,"%s packet received: %p",
type == CLUSTERMSG_TYPE_PING ? "ping" : "pong",
(void*)link->node);
// 连接的 clusterNode 结构存在
if (link->node) {
// 节点处于 HANDSHAKE 状态
if (nodeInHandshake(link->node)) {
if (sender) {
redisLog(REDIS_VERBOSE,
"Handshake: we already know node %.40s, "
"updating the address if needed.", sender->name);
// 如果有需要的话,更新节点的地址
if (nodeUpdateAddressIfNeeded(sender,link,ntohs(hdr->port)))
{
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG|
CLUSTER_TODO_UPDATE_STATE);
}
// 释放节点
freeClusterNode(link->node);
return 0;
}
// 用节点的真名替换在 HANDSHAKE 时创建的随机名字
clusterRenameNode(link->node, hdr->sender);
redisLog(REDIS_DEBUG,"Handshake with node %.40s completed.",
link->node->name);
// 关闭 HANDSHAKE 状态
link->node->flags &= ~REDIS_NODE_HANDSHAKE;
// 设置节点的角色
link->node->flags |= flags&(REDIS_NODE_MASTER|REDIS_NODE_SLAVE);
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG);
// 节点已存在,但它的 id 和当前节点保存的 id 不同
} else if (memcmp(link->node->name,hdr->sender,
REDIS_CLUSTER_NAMELEN) != 0)
{
// 那么将这个节点设为 NOADDR
// 并断开连接
redisLog(REDIS_DEBUG,"PONG contains mismatching sender ID");
link->node->flags |= REDIS_NODE_NOADDR;
link->node->ip[0] = '\0';
link->node->port = 0;
// 断开连接
freeClusterLink(link);
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG);
return 0;
}
}
// 如果发送的消息为 PING
// 并且发送者不在 HANDSHAKE 状态
// 那么更新发送者的信息
if (sender && type == CLUSTERMSG_TYPE_PING &&
!nodeInHandshake(sender) &&
nodeUpdateAddressIfNeeded(sender,link,ntohs(hdr->port)))
{
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG|
CLUSTER_TODO_UPDATE_STATE);
}
/* Update our info about the node */
// 如果这是一条 PONG 消息,那么更新我们关于 node 节点的认识
if (link->node && type == CLUSTERMSG_TYPE_PONG) {
// 最后一次接到该节点的 PONG 的时间
link->node->pong_received = mstime();
// 清零最近一次等待 PING 命令的时间
link->node->ping_sent = 0;
/* The PFAIL condition can be reversed without external
* help if it is momentary (that is, if it does not
* turn into a FAIL state).
*
* 接到节点的 PONG 回复,我们可以移除节点的 PFAIL 状态。
*
* The FAIL condition is also reversible under specific
* conditions detected by clearNodeFailureIfNeeded().
*
* 如果节点的状态为 FAIL ,
* 那么是否撤销该状态要根据 clearNodeFailureIfNeeded() 函数来决定。
*/
if (nodeTimedOut(link->node)) {
// 撤销 PFAIL
link->node->flags &= ~REDIS_NODE_PFAIL;
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG|
CLUSTER_TODO_UPDATE_STATE);
} else if (nodeFailed(link->node)) {
// 看是否可以撤销 FAIL
clearNodeFailureIfNeeded(link->node);
}
}
/* Check for role switch: slave -> master or master -> slave. */
// 检测节点的身份信息,并在需要时进行更新
if (sender) {
// 发送消息的节点的 slaveof 为 REDIS_NODE_NULL_NAME
// 那么 sender 就是一个主节点
if (!memcmp(hdr->slaveof,REDIS_NODE_NULL_NAME,
sizeof(hdr->slaveof)))
{
/* Node is a master. */
// 设置 sender 为主节点
clusterSetNodeAsMaster(sender);
// sender 的 slaveof 不为空,那么这是一个从节点
} else {
/* Node is a slave. */
// 取出 sender 的主节点
clusterNode *master = clusterLookupNode(hdr->slaveof);
// sender 由主节点变成了从节点,重新配置 sender
if (nodeIsMaster(sender)) {
/* Master turned into a slave! Reconfigure the node. */
// 删除所有由该节点负责的槽
clusterDelNodeSlots(sender);
// 更新标识
sender->flags &= ~REDIS_NODE_MASTER;
sender->flags |= REDIS_NODE_SLAVE;
/* Remove the list of slaves from the node. */
// 移除 sender 的从节点名单
if (sender->numslaves) clusterNodeResetSlaves(sender);
/* Update config and state. */
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG|
CLUSTER_TODO_UPDATE_STATE);
}
/* Master node changed for this slave? */
// 检查 sender 的主节点是否变更
if (master && sender->slaveof != master) {
// 如果 sender 之前的主节点不是现在的主节点
// 那么在旧主节点的从节点列表中移除 sender
if (sender->slaveof)
clusterNodeRemoveSlave(sender->slaveof,sender);
// 并在新主节点的从节点列表中添加 sender
clusterNodeAddSlave(master,sender);
// 更新 sender 的主节点
sender->slaveof = master;
/* Update config. */
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG);
}
}
}
/*
* 更新当前节点对 sender 所处理槽的认识。
*
* 这部分的更新 *必须* 在更新 sender 的主/从节点信息之后,
* 因为这里需要用到 REDIS_NODE_MASTER 标识。
*/
clusterNode *sender_master = NULL; /* Sender or its master if slave. */
int dirty_slots = 0; /* Sender claimed slots don't match my view? */
if (sender) {
sender_master = nodeIsMaster(sender) ? sender : sender->slaveof;
if (sender_master) {
dirty_slots = memcmp(sender_master->slots,
hdr->myslots,sizeof(hdr->myslots)) != 0;
}
}
/* 1)
* 如果 sender 是主节点,并且 sender 的槽布局出现了变动
* 那么检查当前节点对 sender 的槽布局设置,看是否需要进行更新
*/
if (sender && nodeIsMaster(sender) && dirty_slots)
clusterUpdateSlotsConfigWith(sender,senderConfigEpoch,hdr->myslots);
/* 2)
* 检测和条件 1 的相反条件,也即是,
* sender 处理的槽的配置纪元比当前节点已知的某个节点的配置纪元要低,
* 如果是这样的话,通知 sender 。
*
* 这种情况可能会出现在网络分裂中,
* 一个重新上线的主节点可能会带有已经过时的槽布局。
*
* 比如说:
*
* A 负责槽 1 、 2 、 3 ,而 B 是 A 的从节点。
*
* A 从网络中分裂出去,B 被提升为主节点。
*
* B 从网络中分裂出去, A 重新上线(但是它所使用的槽布局是旧的)。
*
* 在正常情况下, B 应该向 A 发送 PING 消息,告知 A ,自己(B)已经接替了
* 槽 1、 2、 3 ,并且带有更更的配置纪元,但因为网络分裂的缘故,
* 节点 B 没办法通知节点 A ,
* 所以通知节点 A 它带有的槽布局已经更新的工作就交给其他知道 B 带有更高配置纪元的节点来做。
* 当 A 接到其他节点关于节点 B 的消息时,
* 节点 A 就会停止自己的主节点工作,又或者重新进行故障转移。
*/
if (sender && dirty_slots) {
int j;
for (j = 0; j < REDIS_CLUSTER_SLOTS; j++) {
// 检测 slots 中的槽 j 是否已经被指派
if (bitmapTestBit(hdr->myslots,j)) {
// 当前节点认为槽 j 由 sender 负责处理,
// 或者当前节点认为该槽未指派,那么跳过该槽
if (server.cluster->slots[j] == sender ||
server.cluster->slots[j] == NULL) continue;
// 当前节点槽 j 的配置纪元比 sender 的配置纪元要大
if (server.cluster->slots[j]->configEpoch >
senderConfigEpoch)
{
redisLog(REDIS_VERBOSE,
"Node %.40s has old slots configuration, sending "
"an UPDATE message about %.40s",
sender->name, server.cluster->slots[j]->name);
// 向 sender 发送关于槽 j 的更新信息
clusterSendUpdate(sender->link,
server.cluster->slots[j]);
/* TODO: instead of exiting the loop send every other
* UPDATE packet for other nodes that are the new owner
* of sender's slots. */
break;
}
}
}
}
if (sender &&
nodeIsMaster(myself) && nodeIsMaster(sender) &&
senderConfigEpoch == myself->configEpoch)
{
clusterHandleConfigEpochCollision(sender);
}
// 分析并提取出消息 gossip 协议部分的信息
clusterProcessGossipSection(hdr,link);
// 这是一条 FAIL 消息: sender 告知当前节点,某个节点已经进入 FAIL 状态。
} else if (type == CLUSTERMSG_TYPE_FAIL) {
clusterNode *failing;
if (sender) {
// 获取下线节点的消息
failing = clusterLookupNode(hdr->data.fail.about.nodename);
// 下线的节点既不是当前节点,也没有处于 FAIL 状态
if (failing &&
!(failing->flags & (REDIS_NODE_FAIL|REDIS_NODE_MYSELF)))
{
redisLog(REDIS_NOTICE,
"FAIL message received from %.40s about %.40s",
hdr->sender, hdr->data.fail.about.nodename);
// 打开 FAIL 状态
failing->flags |= REDIS_NODE_FAIL;
failing->fail_time = mstime();
// 关闭 PFAIL 状态
failing->flags &= ~REDIS_NODE_PFAIL;
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG|
CLUSTER_TODO_UPDATE_STATE);
}
} else {
redisLog(REDIS_NOTICE,
"Ignoring FAIL message from unknonw node %.40s about %.40s",
hdr->sender, hdr->data.fail.about.nodename);
}
// 这是一条 PUBLISH 消息
} else if (type == CLUSTERMSG_TYPE_PUBLISH) {
robj *channel, *message;
uint32_t channel_len, message_len;
/* Don't bother creating useless objects if there are no
* Pub/Sub subscribers. */
// 只在有订阅者时创建消息对象
if (dictSize(server.pubsub_channels) ||
listLength(server.pubsub_patterns))
{
// 频道长度
channel_len = ntohl(hdr->data.publish.msg.channel_len);
// 消息长度
message_len = ntohl(hdr->data.publish.msg.message_len);
// 频道
channel = createStringObject(
(char*)hdr->data.publish.msg.bulk_data,channel_len);
// 消息
message = createStringObject(
(char*)hdr->data.publish.msg.bulk_data+channel_len,
message_len);
// 发送消息
pubsubPublishMessage(channel,message);
decrRefCount(channel);
decrRefCount(message);
}
// 这是一条请求获得故障迁移授权的消息: sender 请求当前节点为它进行故障转移投票
} else if (type == CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST) {
if (!sender) return 1; /* We don't know that node. */
// 如果条件允许的话,向 sender 投票,支持它进行故障转移
clusterSendFailoverAuthIfNeeded(sender,hdr);
// 这是一条故障迁移投票信息: sender 支持当前节点执行故障转移操作
} else if (type == CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK) {
if (!sender) return 1; /* We don't know that node. */
// 只有正在处理至少一个槽的主节点的投票会被视为是有效投票
// 只有符合以下条件, sender 的投票才算有效:
// 1) sender 是主节点
// 2) sender 正在处理至少一个槽
// 3) sender 的配置纪元大于等于当前节点的配置纪元
if (nodeIsMaster(sender) && sender->numslots > 0 &&
senderCurrentEpoch >= server.cluster->failover_auth_epoch)
{
// 增加支持票数
server.cluster->failover_auth_count++;
/* Maybe we reached a quorum here, set a flag to make sure
* we check ASAP. */
clusterDoBeforeSleep(CLUSTER_TODO_HANDLE_FAILOVER);
}
} else if (type == CLUSTERMSG_TYPE_MFSTART) {
if (!sender || sender->slaveof != myself) return 1;
resetManualFailover();
server.cluster->mf_end = mstime() + REDIS_CLUSTER_MF_TIMEOUT;
server.cluster->mf_slave = sender;
pauseClients(mstime()+(REDIS_CLUSTER_MF_TIMEOUT*2));
redisLog(REDIS_WARNING,"Manual failover requested by slave %.40s.",
sender->name);
} else if (type == CLUSTERMSG_TYPE_UPDATE) {
clusterNode *n; /* The node the update is about. */
uint64_t reportedConfigEpoch =
ntohu64(hdr->data.update.nodecfg.configEpoch);
if (!sender) return 1;
// 获取需要更新的节点
n = clusterLookupNode(hdr->data.update.nodecfg.nodename);
if (!n) return 1; /* We don't know the reported node. */
// 消息的纪元并不大于节点 n 所处的配置纪元
// 无须更新
if (n->configEpoch >= reportedConfigEpoch) return 1; /* Nothing new. */
// 如果节点 n 为从节点,但它的槽配置更新了
// 那么说明这个节点已经变为主节点,将它设置为主节点
if (nodeIsSlave(n)) clusterSetNodeAsMaster(n);
n->configEpoch = reportedConfigEpoch;
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG|
CLUSTER_TODO_FSYNC_CONFIG);
// 将消息中对 n 的槽布局与当前节点对 n 的槽布局进行对比
// 在有需要时更新当前节点对 n 的槽布局的认识
clusterUpdateSlotsConfigWith(n,reportedConfigEpoch,
hdr->data.update.nodecfg.slots);
} else {
redisLog(REDIS_WARNING,"Received unknown packet type: %d", type);
}
return 1;
}
clusterProcessGossipSection在建立连接的过程中主要是解析携带的gossip信息并添加到待连接节点当中。
/*
* 解释 MEET 、 PING 或 PONG 消息中和 gossip 协议有关的信息。
*
* 注意,这个函数假设调用者已经根据消息的长度,对消息进行过合法性检查。
*/
void clusterProcessGossipSection(clusterMsg *hdr, clusterLink *link) {
// 记录这条消息中包含了多少个节点的信息
uint16_t count = ntohs(hdr->count);
// 指向第一个节点的信息
clusterMsgDataGossip *g = (clusterMsgDataGossip*) hdr->data.ping.gossip;
// 取出发送者
clusterNode *sender = link->node ? link->node : clusterLookupNode(hdr->sender);
// 遍历所有节点的信息
while(count--) {
sds ci = sdsempty();
// 分析节点的 flag
uint16_t flags = ntohs(g->flags);
// 信息节点
clusterNode *node;
// 取出节点的 flag
if (flags == 0) ci = sdscat(ci,"noflags,");
if (flags & REDIS_NODE_MYSELF) ci = sdscat(ci,"myself,");
if (flags & REDIS_NODE_MASTER) ci = sdscat(ci,"master,");
if (flags & REDIS_NODE_SLAVE) ci = sdscat(ci,"slave,");
if (flags & REDIS_NODE_PFAIL) ci = sdscat(ci,"fail?,");
if (flags & REDIS_NODE_FAIL) ci = sdscat(ci,"fail,");
if (flags & REDIS_NODE_HANDSHAKE) ci = sdscat(ci,"handshake,");
if (flags & REDIS_NODE_NOADDR) ci = sdscat(ci,"noaddr,");
if (ci[sdslen(ci)-1] == ',') ci[sdslen(ci)-1] = ' ';
redisLog(REDIS_DEBUG,"GOSSIP %.40s %s:%d %s",
g->nodename,
g->ip,
ntohs(g->port),
ci);
sdsfree(ci);
// 使用消息中的信息对节点进行更新
node = clusterLookupNode(g->nodename);
// 节点已经存在于当前节点
if (node) {
// 如果 sender 是一个主节点,那么我们需要处理下线报告
if (sender && nodeIsMaster(sender) && node != myself) {
// 节点处于 FAIL 或者 PFAIL 状态
if (flags & (REDIS_NODE_FAIL|REDIS_NODE_PFAIL)) {
// 添加 sender 对 node 的下线报告
if (clusterNodeAddFailureReport(node,sender)) {
redisLog(REDIS_VERBOSE,
"Node %.40s reported node %.40s as not reachable.",
sender->name, node->name);
}
// 尝试将 node 标记为 FAIL
markNodeAsFailingIfNeeded(node);
// 节点处于正常状态
} else {
// 如果 sender 曾经发送过对 node 的下线报告
// 那么清除该报告
if (clusterNodeDelFailureReport(node,sender)) {
redisLog(REDIS_VERBOSE,
"Node %.40s reported node %.40s is back online.",
sender->name, node->name);
}
}
}
// 如果节点之前处于 PFAIL 或者 FAIL 状态
// 并且该节点的 IP 或者端口号已经发生变化
// 那么可能是节点换了新地址,尝试对它进行握手
if (node->flags & (REDIS_NODE_FAIL|REDIS_NODE_PFAIL) &&
(strcasecmp(node->ip,g->ip) || node->port != ntohs(g->port)))
{
clusterStartHandshake(g->ip,ntohs(g->port));
}
// 当前节点不认识 node
} else {
/*
* 如果 node 不在 NOADDR 状态,并且当前节点不认识 node
* 那么向 node 发送 HANDSHAKE 消息。
*
* 注意,当前节点必须保证 sender 是本集群的节点,
* 否则我们将有加入了另一个集群的风险。
*/
if (sender &&
!(flags & REDIS_NODE_NOADDR) &&
!clusterBlacklistExists(g->nodename))
{
clusterStartHandshake(g->ip,ntohs(g->port));
}
}
/* Next node */
// 处理下个节点的信息
g++;
}
}