概述
好久没写概述了,之所以这里要增加一个概述是因为这个章节的内容我找不到一个很好形式来表达自己想表达的内容,因而只能增加一个概述来帮助自己梳理一下思路。
在这章节里面,我其实想表达清楚三个概念:
- 集群模式下读写过程
- 集群模式key和slot的关联
- 集群模式下的slot重分配过程
redis cluster读写过程
redis集群模式下的读写过程中,先对key进行hash找到slot进而找到clusterNode,如果clusterNode不是本节点就返回ASK或者MOVED错误码让客户端向新的节点ip:port发起连接。
getNodeByQuery的作用就是按照key->hash值->slot->clusterNode的顺序定位到key保存的clusterNode节点。
在完成clusterNode判断后如果确定是本节点后执行后续的读写操作即可。
int processCommand(redisClient *c) {
//处理key对应的slot,以及clusterNode节点位置
if (server.cluster_enabled &&
!(c->flags & REDIS_MASTER) &&
!(c->cmd->getkeys_proc == NULL && c->cmd->firstkey == 0))
{
int hashslot;
{
int error_code;
clusterNode *n = getNodeByQuery(c,c->cmd,c->argv,c->argc,&hashslot,&error_code);
// 不能执行多键处理命令
if (n == NULL) {
flagTransaction(c);
if (error_code == REDIS_CLUSTER_REDIR_CROSS_SLOT) {
addReplySds(c,sdsnew("-CROSSSLOT Keys in request don't hash to the same slot\r\n"));
} else if (error_code == REDIS_CLUSTER_REDIR_UNSTABLE) {
/* The request spawns mutliple keys in the same slot,
* but the slot is not "stable" currently as there is
* a migration or import in progress. */
addReplySds(c,sdsnew("-TRYAGAIN Multiple keys request during rehashing of slot\r\n"));
} else {
redisPanic("getNodeByQuery() unknown error.");
}
return REDIS_OK;
// 命令针对的槽和键不是本节点处理的,进行转向
} else if (n != server.cluster->myself) {
flagTransaction(c);
// -<ASK or MOVED> <slot> <ip>:<port>
// 例如 -ASK 10086 127.0.0.1:12345
addReplySds(c,sdscatprintf(sdsempty(),
"-%s %d %s:%d\r\n",
(error_code == REDIS_CLUSTER_REDIR_ASK) ? "ASK" : "MOVED",
hashslot,n->ip,n->port));
return REDIS_OK;
}
// 如果执行到这里,说明键 key 所在的槽由本节点处理
// 或者客户端执行的是无参数命令
}
}
//执行真正的读写过程
{
// 执行命令
call(c,REDIS_CALL_FULL);
}
return REDIS_OK;
}
getNodeByQuery内部通过keyHashSlot确定key对应的slot,进而确定clusterNode节点。
clusterNode *getNodeByQuery(redisClient *c, struct redisCommand *cmd, robj **argv, int argc, int *hashslot, int *error_code) {
// 初始化为 NULL ,
// 如果输入命令是无参数命令,那么 n 就会继续为 NULL
clusterNode *n = NULL;
robj *firstkey = NULL;
int multiple_keys = 0;
multiState *ms, _ms;
multiCmd mc;
int i, slot = 0, migrating_slot = 0, importing_slot = 0, missing_keys = 0;
if (error_code) *error_code = REDIS_CLUSTER_REDIR_NONE;
// 集群可以执行事务,
// 但必须确保事务中的所有命令都是针对某个相同的键进行的
// 这个 if 和接下来的 for 进行的就是这一合法性检测
if (cmd->proc == execCommand) {
if (!(c->flags & REDIS_MULTI)) return myself;
ms = &c->mstate;
} else {
ms = &_ms;
_ms.commands = &mc;
_ms.count = 1;
mc.argv = argv;
mc.argc = argc;
mc.cmd = cmd;
}
for (i = 0; i < ms->count; i++) {
struct redisCommand *mcmd;
robj **margv;
int margc, *keyindex, numkeys, j;
mcmd = ms->commands[i].cmd;
margc = ms->commands[i].argc;
margv = ms->commands[i].argv;
// 定位命令的键位置
keyindex = getKeysFromCommand(mcmd,margv,margc,&numkeys);
// 遍历命令中的所有键
for (j = 0; j < numkeys; j++) {
robj *thiskey = margv[keyindex[j]];
int thisslot = keyHashSlot((char*)thiskey->ptr,
sdslen(thiskey->ptr));
if (firstkey == NULL) {
// 这是事务中第一个被处理的键
// 获取该键的槽和负责处理该槽的节点
/* This is the first key we see. Check what is the slot
* and node. */
firstkey = thiskey;
slot = thisslot;
n = server.cluster->slots[slot];
redisAssertWithInfo(c,firstkey,n != NULL);
if (n == myself &&
server.cluster->migrating_slots_to[slot] != NULL)
{
migrating_slot = 1;
} else if (server.cluster->importing_slots_from[slot] != NULL) {
importing_slot = 1;
}
} else {
if (!equalStringObjects(firstkey,thiskey)) {
if (slot != thisslot) {
/* Error: multiple keys from different slots. */
getKeysFreeResult(keyindex);
if (error_code)
*error_code = REDIS_CLUSTER_REDIR_CROSS_SLOT;
return NULL;
} else {
multiple_keys = 1;
}
}
}
if ((migrating_slot || importing_slot) &&
lookupKeyRead(&server.db[0],thiskey) == NULL)
{
missing_keys++;
}
}
getKeysFreeResult(keyindex);
}
if (n == NULL) return myself;
if (hashslot) *hashslot = slot;
if (migrating_slot && missing_keys) {
if (error_code) *error_code = REDIS_CLUSTER_REDIR_ASK;
return server.cluster->migrating_slots_to[slot];
}
if (importing_slot &&
(c->flags & REDIS_ASKING || cmd->flags & REDIS_CMD_ASKING))
{
if (multiple_keys && missing_keys) {
if (error_code) *error_code = REDIS_CLUSTER_REDIR_UNSTABLE;
return NULL;
} else {
return myself;
}
}
if (c->flags & REDIS_READONLY &&
cmd->flags & REDIS_CMD_READONLY &&
nodeIsSlave(myself) &&
myself->slaveof == n)
{
return myself;
}
if (n != myself && error_code) *error_code = REDIS_CLUSTER_REDIR_MOVED;
// 返回负责处理槽 slot 的节点 n
return n;
}
redis key和slot的关联
redis clusterNode数据结构
clusterState用以保存redis cluster集群的clusterNode和slot的映射关系,核心的字段如下:
- clusterNode *slots[REDIS_CLUSTER_SLOTS] //例如 slots[i] = clusterNode_A 表示槽 i 由节点 A 处理
- zskiplist *slots_to_keys //跳跃表,表中以槽作为分值,键作为成员,对槽进行有序排序
- clusterNode *migrating_slots_to[REDIS_CLUSTER_SLOTS]; //记录要从当前节点迁移到目标节点的槽,以及迁移的目标节点
- clusterNode *importing_slots_from[REDIS_CLUSTER_SLOTS]; //记录要从源节点迁移到本节点的槽,以及进行迁移的源节点
clusterNode用于保存该clusterNode下保存的slot信息,核心字段如下:
- unsigned char slots[REDIS_CLUSTER_SLOTS/8]; // 由这个节点负责处理的槽,一共有 REDIS_CLUSTER_SLOTS / 8 个字节长,每个字节的每个位记录了一个槽的保存状态
typedef struct clusterState {
// 指向当前节点的指针
clusterNode *myself; /* This node */
// 集群当前的配置纪元,用于实现故障转移
uint64_t currentEpoch;
// 集群当前的状态:是在线还是下线
int state; /* REDIS_CLUSTER_OK, REDIS_CLUSTER_FAIL, ... */
// 集群中至少处理着一个槽的节点的数量。
int size; /* Num of master nodes with at least one slot */
// 集群节点名单(包括 myself 节点)
// 字典的键为节点的名字,字典的值为 clusterNode 结构
dict *nodes; /* Hash table of name -> clusterNode structures */
// 记录要从当前节点迁移到目标节点的槽,以及迁移的目标节点
// migrating_slots_to[i] = NULL 表示槽 i 未被迁移
// migrating_slots_to[i] = clusterNode_A 表示槽 i 要从本节点迁移至节点 A
clusterNode *migrating_slots_to[REDIS_CLUSTER_SLOTS];
// 记录要从源节点迁移到本节点的槽,以及进行迁移的源节点
// importing_slots_from[i] = NULL 表示槽 i 未进行导入
// importing_slots_from[i] = clusterNode_A 表示正从节点 A 中导入槽 i
clusterNode *importing_slots_from[REDIS_CLUSTER_SLOTS];
// 负责处理各个槽的节点
// 例如 slots[i] = clusterNode_A 表示槽 i 由节点 A 处理
clusterNode *slots[REDIS_CLUSTER_SLOTS];
// 跳跃表,表中以槽作为分值,键作为成员,对槽进行有序排序
// 当需要对某些槽进行区间(range)操作时,这个跳跃表可以提供方便
// 具体操作定义在 db.c 里面
zskiplist *slots_to_keys;
} clusterState;
// 节点状态
struct clusterNode {
// 节点的名字,由 40 个十六进制字符组成
// 例如 68eef66df23420a5862208ef5b1a7005b806f2ff
char name[REDIS_CLUSTER_NAMELEN]; /* Node name, hex string, sha1-size */
// 由这个节点负责处理的槽
// 一共有 REDIS_CLUSTER_SLOTS / 8 个字节长
// 每个字节的每个位记录了一个槽的保存状态
// 位的值为 1 表示槽正由本节点处理,值为 0 则表示槽并非本节点处理
// 比如 slots[0] 的第一个位保存了槽 0 的保存情况
// slots[0] 的第二个位保存了槽 1 的保存情况,以此类推
unsigned char slots[REDIS_CLUSTER_SLOTS/8]; /* slots handled by this node */
// 该节点负责处理的槽数量
int numslots; /* Number of slots handled by this node */
};
redis key和slot关联过程
redis的key和slot关联的过程发生在我们保存key_value键值对的时候,通过slotToKeyAdd的函数去实现。
在存储数据结构方面,通过跳跃表zskiplist *slots_to_keys的数据结构进行存储。
对跳跃表slots_to_keys进一步分析,我们在zskiplist当中按照[slot,key]的顺序进行存储,譬如有slot1和key1,key2和slot2和key1,key2的数据场景下,zskiplist当中按照slot1_key1,slot1_key2,slot2_key1,slot2_key2的顺序有序保存着。
void dbAdd(redisDb *db, robj *key, robj *val) {
// 复制键名
sds copy = sdsdup(key->ptr);
// 尝试添加键值对
int retval = dictAdd(db->dict, copy, val);
// 如果键已经存在,那么停止
redisAssertWithInfo(NULL,key,retval == REDIS_OK);
// 如果开启了集群模式,那么将键保存到槽里面
if (server.cluster_enabled) slotToKeyAdd(key);
}
// 将给定键添加到槽里面,
// 节点的 slots_to_keys 用跳跃表记录了 slot -> key 之间的映射
// 这样可以快速地处理槽和键的关系,在 rehash 槽时很有用。
void slotToKeyAdd(robj *key) {
// 计算出键所属的槽
unsigned int hashslot = keyHashSlot(key->ptr,sdslen(key->ptr));
// 将槽 slot 作为分值,键作为成员,添加到 slots_to_keys 跳跃表里面
zslInsert(server.cluster->slots_to_keys,hashslot,key);
incrRefCount(key);
}
zskiplistNode *zslInsert(zskiplist *zsl, double score, robj *obj) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
redisAssert(!isnan(score));
// 在各个层查找节点的插入位置
// T_wrost = O(N^2), T_avg = O(N log N)
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
// 如果 i 不是 zsl->level-1 层
// 那么 i 层的起始 rank 值为 i+1 层的 rank 值
// 各个层的 rank 值一层层累积
// 最终 rank[0] 的值加一就是新节点的前置节点的排位
// rank[0] 会在后面成为计算 span 值和 rank 值的基础
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
// 沿着前进指针遍历跳跃表
// T_wrost = O(N^2), T_avg = O(N log N)
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
// 比对分值
(x->level[i].forward->score == score &&
// 比对成员, T = O(N)
compareStringObjects(x->level[i].forward->obj,obj) < 0))) {
// 记录沿途跨越了多少个节点
rank[i] += x->level[i].span;
// 移动至下一指针
x = x->level[i].forward;
}
// 记录将要和新节点相连接的节点
update[i] = x;
}
// 获取一个随机值作为新节点的层数
// T = O(N)
level = zslRandomLevel();
// 如果新节点的层数比表中其他节点的层数都要大
// 那么初始化表头节点中未使用的层,并将它们记录到 update 数组中
// 将来也指向新节点
if (level > zsl->level) {
// 初始化未使用层
// T = O(1)
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
// 更新表中节点最大层数
zsl->level = level;
}
// 创建新节点
x = zslCreateNode(level,score,obj);
// 将前面记录的指针指向新节点,并做相应的设置
// T = O(1)
for (i = 0; i < level; i++) {
// 设置新节点的 forward 指针
x->level[i].forward = update[i]->level[i].forward;
// 将沿途记录的各个节点的 forward 指针指向新节点
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
// 计算新节点跨越的节点数量
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
// 更新新节点插入之后,沿途节点的 span 值
// 其中的 +1 计算的是新节点
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
// 未接触的节点的 span 值也需要增一,这些节点直接从表头指向新节点
// T = O(1)
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
// 设置新节点的后退指针
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
// 跳跃表的节点计数增一
zsl->length++;
return x;
}
redis cluster reshard过程
redis 数据迁移过程
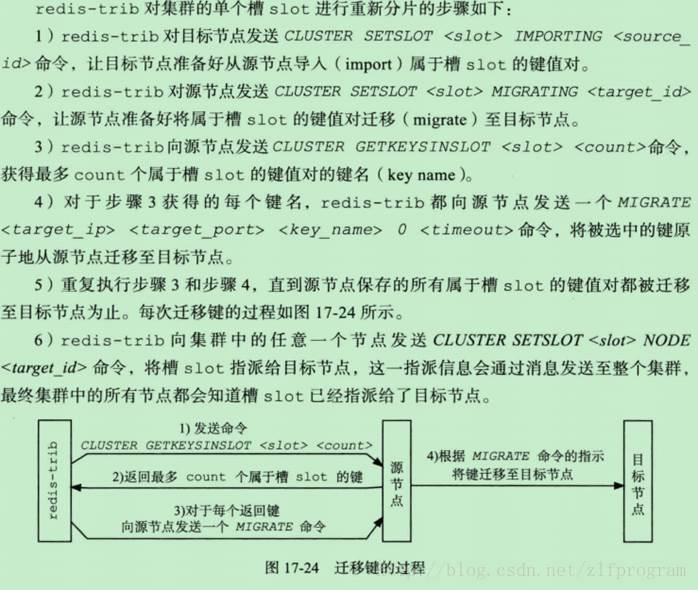
redis cluster reshard我们通过redis-trib脚本来进行操作,其实内部通过一些cluster slot相关的命令完成操作。整个过程如下图所示:
- CLUSTER SETSLOT <slot> IMPORTING <node_id>
- CLUSTER SETSLOT <slot> MIGRATING <node_id>
- CLUSTER GETKEYSINSLOT slot count
- MIGRATE host port key destination-db timeout [COPY] [REPLACE]
- CLUSTER SETSLOT <slot> NODE <node_id>
slot的操作命令
//槽(slot)
CLUSTER ADDSLOTS <slot> [slot ...] 将一个或多个槽(slot)指派(assign)给当前节点。
CLUSTER DELSLOTS <slot> [slot ...] 移除一个或多个槽对当前节点的指派。
CLUSTER FLUSHSLOTS 移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。
CLUSTER SETSLOT <slot> NODE <node_id> 将槽 slot 指派给 node_id 指定的节点,如果槽已经指派给另一个节点,那么先让另一个节点删除该槽>,然后再进行指派。
CLUSTER SETSLOT <slot> MIGRATING <node_id> 将本节点的槽 slot 迁移到 node_id 指定的节点中。
CLUSTER SETSLOT <slot> IMPORTING <node_id> 从 node_id 指定的节点中导入槽 slot 到本节点。
CLUSTER SETSLOT <slot> STABLE 取消对槽 slot 的导入(import)或者迁移(migrate)。
addslots和delslots命令
addslots和delslots主要是把slot指定到clusterNode上,内部做的事情主要是修改两个数据结构,分别是 server.cluster->slots和ClusterNode的slots数据结构,前者表示全局标明slot和对应clusterNode映射关系,后者是clusterNode和负责的slot映射关系。
// CLUSTER 命令的实现
void clusterCommand(redisClient *c) {
if ((!strcasecmp(c->argv[1]->ptr,"addslots") ||
!strcasecmp(c->argv[1]->ptr,"delslots")) && c->argc >= 3)
{
int j, slot;
// 一个数组,记录所有要添加或者删除的槽
unsigned char *slots = zmalloc(REDIS_CLUSTER_SLOTS);
// 检查这是 delslots 还是 addslots
int del = !strcasecmp(c->argv[1]->ptr,"delslots");
// 将 slots 数组的所有值设置为 0
memset(slots,0,REDIS_CLUSTER_SLOTS);
// 处理所有输入 slot 参数
for (j = 2; j < c->argc; j++) {
// 获取 slot 数字
if ((slot = getSlotOrReply(c,c->argv[j])) == -1) {
zfree(slots);
return;
}
// 如果这是 delslots 命令,并且指定槽为未指定,那么返回一个错误
if (del && server.cluster->slots[slot] == NULL) {
addReplyErrorFormat(c,"Slot %d is already unassigned", slot);
zfree(slots);
return;
// 如果这是 addslots 命令,并且槽已经有节点在负责,那么返回一个错误
} else if (!del && server.cluster->slots[slot]) {
addReplyErrorFormat(c,"Slot %d is already busy", slot);
zfree(slots);
return;
}
// 如果某个槽指定了一次以上,那么返回一个错误
if (slots[slot]++ == 1) {
addReplyErrorFormat(c,"Slot %d specified multiple times",
(int)slot);
zfree(slots);
return;
}
}
// 处理所有输入 slot
for (j = 0; j < REDIS_CLUSTER_SLOTS; j++) {
if (slots[j]) {
int retval;
// 如果指定 slot 之前的状态为载入状态,那么现在可以清除这一状态
// 因为当前节点现在已经是 slot 的负责人了
if (server.cluster->importing_slots_from[j])
server.cluster->importing_slots_from[j] = NULL;
// 添加或者删除指定 slot
retval = del ? clusterDelSlot(j) :
clusterAddSlot(myself,j);
redisAssertWithInfo(c,NULL,retval == REDIS_OK);
}
}
zfree(slots);
clusterDoBeforeSleep(CLUSTER_TODO_UPDATE_STATE|CLUSTER_TODO_SAVE_CONFIG);
addReply(c,shared.ok);
}
}
// 将槽 slot 添加到节点 n 需要处理的槽的列表中
// 添加成功返回 REDIS_OK ,如果槽已经由这个节点处理了
// 那么返回 REDIS_ERR 。
int clusterAddSlot(clusterNode *n, int slot) {
// 槽 slot 已经是节点 n 处理的了
if (server.cluster->slots[slot]) return REDIS_ERR;
// 设置 bitmap
clusterNodeSetSlotBit(n,slot);
// 更新集群状态
server.cluster->slots[slot] = n;
return REDIS_OK;
}
// 为槽二进制位设置新值,并返回旧值
int clusterNodeSetSlotBit(clusterNode *n, int slot) {
int old = bitmapTestBit(n->slots,slot);
bitmapSetBit(n->slots,slot);
if (!old) n->numslots++;
return old;
}
// 设置位图 bitmap 在 pos 位置的值
void bitmapSetBit(unsigned char *bitmap, int pos) {
off_t byte = pos/8;
int bit = pos&7;
bitmap[byte] |= 1<<bit;
}
SETSLOT命令
在redis cluster reshard过程中我们依赖的核心命令是setslot命令,内部主要关注以下三个命令:
- migrating设置到处node节点信息,server.cluster->migrating_slots_to[slot]
- importing设置导入node节点信息,server.cluster->importing_slots_from[slot]
- getkeysinslot获取slot上指定个数的key信息用于迁移
void clusterCommand(redisClient *c) {
//省略其他非关联的代码
else if (!strcasecmp(c->argv[1]->ptr,"setslot") && c->argc >= 4) {
int slot;
clusterNode *n;
// 取出 slot 值
if ((slot = getSlotOrReply(c,c->argv[2])) == -1) return;
// 将本节点的槽 slot 迁移至 node id 所指定的节点
if (!strcasecmp(c->argv[3]->ptr,"migrating") && c->argc == 5) {
// 被迁移的槽必须属于本节点
if (server.cluster->slots[slot] != myself) {
addReplyErrorFormat(c,"I'm not the owner of hash slot %u",slot);
return;
}
// 迁移的目标节点必须是本节点已知的
if ((n = clusterLookupNode(c->argv[4]->ptr)) == NULL) {
addReplyErrorFormat(c,"I don't know about node %s",
(char*)c->argv[4]->ptr);
return;
}
// 为槽设置迁移目标节点
server.cluster->migrating_slots_to[slot] = n;
// 从节点 node id 中导入槽 slot 到本节点
} else if (!strcasecmp(c->argv[3]->ptr,"importing") && c->argc == 5) {
// 如果 slot 槽本身已经由本节点处理,那么无须进行导入
if (server.cluster->slots[slot] == myself) {
addReplyErrorFormat(c,
"I'm already the owner of hash slot %u",slot);
return;
}
// node id 指定的节点必须是本节点已知的,这样才能从目标节点导入槽
if ((n = clusterLookupNode(c->argv[4]->ptr)) == NULL) {
addReplyErrorFormat(c,"I don't know about node %s",
(char*)c->argv[3]->ptr);
return;
}
// 为槽设置导入目标节点
server.cluster->importing_slots_from[slot] = n;
}
} else if (!strcasecmp(c->argv[1]->ptr,"getkeysinslot") && c->argc == 4) {
/* CLUSTER GETKEYSINSLOT <slot> <count> */
// 打印 count 个属于 slot 槽的键
long long maxkeys, slot;
unsigned int numkeys, j;
robj **keys;
// 取出 slot 参数
if (getLongLongFromObjectOrReply(c,c->argv[2],&slot,NULL) != REDIS_OK)
return;
// 取出 count 参数
if (getLongLongFromObjectOrReply(c,c->argv[3],&maxkeys,NULL)
!= REDIS_OK)
return;
// 检查参数的合法性
if (slot < 0 || slot >= REDIS_CLUSTER_SLOTS || maxkeys < 0) {
addReplyError(c,"Invalid slot or number of keys");
return;
}
// 分配一个保存键的数组
keys = zmalloc(sizeof(robj*)*maxkeys);
// 将键记录到 keys 数组
numkeys = getKeysInSlot(slot, keys, maxkeys);
// 打印获得的键
addReplyMultiBulkLen(c,numkeys);
for (j = 0; j < numkeys; j++) addReplyBulk(c,keys[j]);
zfree(keys);
}
}
getKeysInSlot是从指定的slot获取指定个数的redis key用于数据迁移, zslFirstInRange根据slot去zskiplist当中获取key,因为保存slot和key映射关系的zskiplist是按照slot有序的,所以查找过程也不算太复杂。
unsigned int getKeysInSlot(unsigned int hashslot, robj **keys, unsigned int count) {
zskiplistNode *n;
zrangespec range;
int j = 0;
range.min = range.max = hashslot;
range.minex = range.maxex = 0;
// 定位到第一个属于指定 slot 的键上面
n = zslFirstInRange(server.cluster->slots_to_keys, &range);
// 遍历跳跃表,并保存属于指定 slot 的键
// n && n->score 检查当前键是否属于指定 slot
// && count-- 用来计数
while(n && n->score == hashslot && count--) {
// 记录键
keys[j++] = n->obj;
n = n->level[0].forward;
}
return j;
}
zskiplistNode *zslFirstInRange(zskiplist *zsl, zrangespec *range) {
zskiplistNode *x;
int i;
/* If everything is out of range, return early. */
if (!zslIsInRange(zsl,range)) return NULL;
// 遍历跳跃表,查找符合范围 min 项的节点
// T_wrost = O(N), T_avg = O(log N)
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
/* Go forward while *OUT* of range. */
while (x->level[i].forward &&
!zslValueGteMin(x->level[i].forward->score,range))
x = x->level[i].forward;
}
/* This is an inner range, so the next node cannot be NULL. */
x = x->level[0].forward;
redisAssert(x != NULL);
/* Check if score <= max. */
// 检查节点是否符合范围的 max 项
// T = O(1)
if (!zslValueLteMax(x->score,range)) return NULL;
return x;
}
redis 执行数据迁移
通过MIGRATE host port key destination-db将数据迁移至指定的host:port的clusterNode,key来自于getkeysinslot命令获取的,有了key之后我们直接在当前节点的db当中找到对应的value,然后封装RESTORE-ASKING报文将数据发送至指定节点即可。
数据通信直接通过socket通信来实现的。
void migrateCommand(redisClient *c) {
int fd, copy, replace, j;
long timeout;
long dbid;
long long ttl, expireat;
robj *o;
rio cmd, payload;
int retry_num = 0;
try_again:
/* Initialization */
copy = 0;
replace = 0;
ttl = 0;
// 读入 COPY 或者 REPLACE 选项
for (j = 6; j < c->argc; j++) {
if (!strcasecmp(c->argv[j]->ptr,"copy")) {
copy = 1;
} else if (!strcasecmp(c->argv[j]->ptr,"replace")) {
replace = 1;
} else {
addReply(c,shared.syntaxerr);
return;
}
}
// 检查输入参数的正确性
if (getLongFromObjectOrReply(c,c->argv[5],&timeout,NULL) != REDIS_OK)
return;
if (getLongFromObjectOrReply(c,c->argv[4],&dbid,NULL) != REDIS_OK)
return;
if (timeout <= 0) timeout = 1000;
// 取出键的值对象
if ((o = lookupKeyRead(c->db,c->argv[3])) == NULL) {
addReplySds(c,sdsnew("+NOKEY\r\n"));
return;
}
// 获取套接字连接
fd = migrateGetSocket(c,c->argv[1],c->argv[2],timeout);
if (fd == -1) return; /* error sent to the client by migrateGetSocket() */
// 创建用于指定数据库的 SELECT 命令,以免键值对被还原到了错误的地方
rioInitWithBuffer(&cmd,sdsempty());
redisAssertWithInfo(c,NULL,rioWriteBulkCount(&cmd,'*',2));
redisAssertWithInfo(c,NULL,rioWriteBulkString(&cmd,"SELECT",6));
redisAssertWithInfo(c,NULL,rioWriteBulkLongLong(&cmd,dbid));
// 取出键的过期时间戳
expireat = getExpire(c->db,c->argv[3]);
if (expireat != -1) {
ttl = expireat-mstime();
if (ttl < 1) ttl = 1;
}
redisAssertWithInfo(c,NULL,rioWriteBulkCount(&cmd,'*',replace ? 5 : 4));
// 如果运行在集群模式下,那么发送的命令为 RESTORE-ASKING
// 如果运行在非集群模式下,那么发送的命令为 RESTORE
if (server.cluster_enabled)
redisAssertWithInfo(c,NULL,
rioWriteBulkString(&cmd,"RESTORE-ASKING",14));
else
redisAssertWithInfo(c,NULL,rioWriteBulkString(&cmd,"RESTORE",7));
// 写入键名和过期时间
redisAssertWithInfo(c,NULL,sdsEncodedObject(c->argv[3]));
redisAssertWithInfo(c,NULL,rioWriteBulkString(&cmd,c->argv[3]->ptr,
sdslen(c->argv[3]->ptr)));
redisAssertWithInfo(c,NULL,rioWriteBulkLongLong(&cmd,ttl));
// 将值对象进行序列化
createDumpPayload(&payload,o);
// 写入序列化对象
redisAssertWithInfo(c,NULL,rioWriteBulkString(&cmd,payload.io.buffer.ptr,
sdslen(payload.io.buffer.ptr)));
sdsfree(payload.io.buffer.ptr);
// 是否设置了 REPLACE 命令?
if (replace)
// 写入 REPLACE 参数
redisAssertWithInfo(c,NULL,rioWriteBulkString(&cmd,"REPLACE",7));
// 以 64 kb 每次的大小向对方发送数据
errno = 0;
{
sds buf = cmd.io.buffer.ptr;
size_t pos = 0, towrite;
int nwritten = 0;
while ((towrite = sdslen(buf)-pos) > 0) {
towrite = (towrite > (64*1024) ? (64*1024) : towrite);
nwritten = syncWrite(fd,buf+pos,towrite,timeout);
if (nwritten != (signed)towrite) goto socket_wr_err;
pos += nwritten;
}
}
// 读取命令的回复
{
char buf1[1024];
char buf2[1024];
/* Read the two replies */
if (syncReadLine(fd, buf1, sizeof(buf1), timeout) <= 0)
goto socket_rd_err;
if (syncReadLine(fd, buf2, sizeof(buf2), timeout) <= 0)
goto socket_rd_err;
// 检查 RESTORE 命令执行是否成功
if (buf1[0] == '-' || buf2[0] == '-') {
// 执行出错。。。
addReplyErrorFormat(c,"Target instance replied with error: %s",
(buf1[0] == '-') ? buf1+1 : buf2+1);
} else {
// 执行成功。。。
robj *aux;
// 如果没有指定 COPY 选项,那么删除本机数据库中的键
if (!copy) {
/* No COPY option: remove the local key, signal the change. */
dbDelete(c->db,c->argv[3]);
signalModifiedKey(c->db,c->argv[3]);
}
addReply(c,shared.ok);
server.dirty++;
/* Translate MIGRATE as DEL for replication/AOF. */
// 如果键被删除了的话,向 AOF 文件和从服务器/节点发送一个 DEL 命令
aux = createStringObject("DEL",3);
rewriteClientCommandVector(c,2,aux,c->argv[3]);
decrRefCount(aux);
}
}
sdsfree(cmd.io.buffer.ptr);
return;
socket_wr_err:
sdsfree(cmd.io.buffer.ptr);
migrateCloseSocket(c->argv[1],c->argv[2]);
if (errno != ETIMEDOUT && retry_num++ == 0) goto try_again;
addReplySds(c,
sdsnew("-IOERR error or timeout writing to target instance\r\n"));
return;
socket_rd_err:
sdsfree(cmd.io.buffer.ptr);
migrateCloseSocket(c->argv[1],c->argv[2]);
if (errno != ETIMEDOUT && retry_num++ == 0) goto try_again;
addReplySds(c,
sdsnew("-IOERR error or timeout reading from target node\r\n"));
return;
}