思沃大讲堂培训,要求我们把自己学习的心得感悟输出在简书上,公司还会统计大家的文章,包括文章数量、评论量、被喜欢量等等。这么多人,人工统计起来自然很麻烦,当然程序员会把这么艰巨光荣繁琐的工作交给代码,于是他们就写了一个爬虫。适值极客人正在学习Ruby,所以就突发奇想写了一个Ruby爬虫统计简书用户的文章,带动自己的Ruby学习。
如果让我抓取一个网站的内容,我的第一想法可能会是抓取它的HTML,不过也会反过来问自己一句这个网站有没有Rss订阅源地址,RSS的订阅源的内容是xml,相比html更加简洁和高效,而且由于xml的结构稳定一点(html可能那天换一个css可能就会导致我的爬虫用不了啦),解析起来会更加方便一点。在考察完简书没有提供RSS后,我就决定选择html来暴力地抓取简书了。
分析简书网址
- 首页:http://www.jianshu.com/
- 用户主页:http://www.jianshu.com/users/用户ID(暂估计这么说)
我们可以获取用户的关注、粉丝、文章、字数、收获喜欢等信息
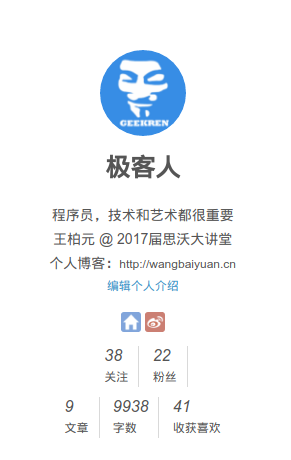
- 用户最新文章http://www.jianshu.com/users/用户ID(暂估计这么说)/latest_articles
我们可以获取用户文章列表,以此统计用户文章的评论量、阅读量等等,通过遍历文章列表将评论量、阅读量相加即可获取评论总量、阅读总量
需要指出的是,由于文章列表页不能把用户的文章全部列出来,而是列出10条,用户在浏览器中滚动到文章列表底部会自动加载,是用js向后台请求数据然后在前端多次拼接出来,所以想一次性地抓一次就把用户的评论总量、阅读总量是不行的,用户列表页分页的。所以我采取分页抓取的方式,那么怎么知道用户文章一共有多少页呢?我们从用户主页中获取了用户的文章总数,所以除以10加1可以获取页数
- 用户列表页分页的,10条/页,其中第 m 页URL:
http://www.jianshu.com/users/用户ID(暂估计这么说)/latest_articles?page=m
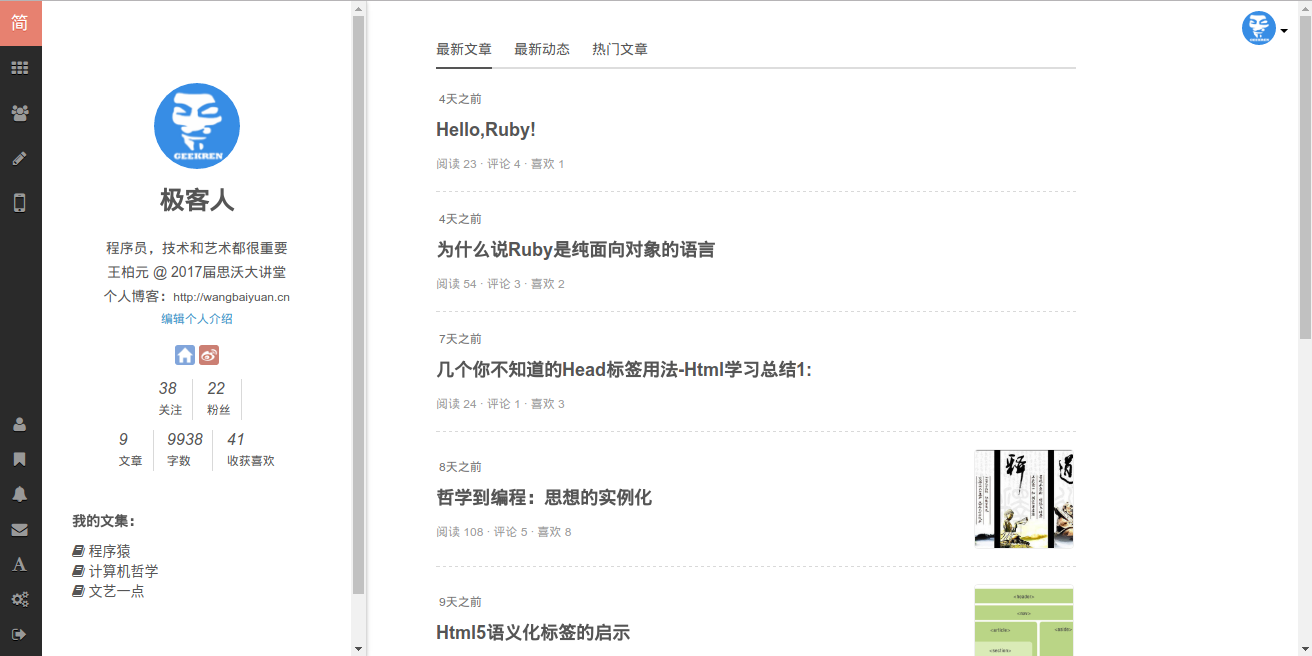
抓取网页,获取html
Ruby提供的HTTP访问方法十分简洁高效,当然方法不止一种,对其他方法感兴趣的同学我自行Google,在此我贴出自己的代码:
h = Net::HTTP.new("www.jianshu.com", 80)
resp = h.get "/users/#{authorInfo.id}/latest_articles"
latest_articles_html = resp.body.to_s
顾问生义,我想不需要解释代码的意思了吧
根据上面介绍的简书网址规则,就可以通过上述代码抓取到相应网页的HTML
分析抓取内容的结构
获取完相应网页的HTML内容后要做的就是分析HTML的内容和结构。我们用眼睛很容易看出网页上的内容,但是爬虫看到的只有html源代码。下面我从抓取的HTML中提取了下列有用的代码:
- 用于提取用户的关注量、粉丝量、文章数、字数、收获喜欢数
<div class="user-stats">
<ul class="clearfix">
<li>
<a href="/users/ef49e6b7ec1e/subscriptions"><b>38</b><span>关注</span></a>
</li>
<li>
<a href="/users/ef49e6b7ec1e/followers"><b>22</b><span>粉丝</span></a>
</li>
<br>
<li>
<a href="/users/ef49e6b7ec1e"><b>9</b><span>文章</span></a>
</li>
<li>
<a><b>9938</b><span>字数</span></a>
</li>
<li>
<a><b>41</b><span>收获喜欢</span></a>
</li>
</ul>
</div>
- 用于提取用户文章评论总量、阅读总量
<ul class="article-list latest-notes"><li>
<div>
<p class="list-top">
<a class="author-name blue-link" target="_blank" href="/users/ef49e6b7ec1e">极客人</a>
<em>·</em>
<span class="time" data-shared-at="2016-12-12T15:39:07+08:00">4天之前</span>
</p>
<h4 class="title"><a target="_blank" href="/p/f11d1fca16c6">Hello,Ruby!</a></h4>
<div class="list-footer">
<a target="_blank" href="/p/f11d1fca16c6">
阅读 23
</a> <a target="_blank" href="/p/f11d1fca16c6#comments">
· 评论 4
</a> <span> · 喜欢 1</span>
</div>
</div>
</li>
<li class="have-img">
<a class="wrap-img" href="/p/3d43727e04a5"><img src="http://upload-images.jianshu.io/upload_images/2154287-86190de5fd3071f7.png?imageMogr2/auto-orient/strip%7CimageView2/1/w/300/h/300" alt="300"></a>
<div>
<p class="list-top">
<a class="author-name blue-link" target="_blank" href="/users/ef49e6b7ec1e">极客人</a>
<em>·</em>
<span class="time" data-shared-at="2016-12-08T00:02:08+08:00">9天之前</span>
</p>
<h4 class="title"><a target="_blank" href="/p/3d43727e04a5">Html5语义化标签的启示</a></h4>
<div class="list-footer">
<a target="_blank" href="/p/3d43727e04a5">
阅读 182
</a> <a target="_blank" href="/p/3d43727e04a5#comments">
· 评论 1
</a> <span> · 喜欢 10</span>
</div>
</div>
</li>
.....
<li>
<div>
<p class="list-top">
<a class="author-name blue-link" target="_blank" href="/users/ef49e6b7ec1e">极客人</a>
<em>·</em>
<span class="time" data-shared-at="2016-11-28T19:35:45+08:00">18天之前</span>
</p>
<h4 class="title"><a target="_blank" href="/p/114c27b6456c">网站自动跳转到Cjb.Net的惊险之旅</a></h4>
<div class="list-footer">
<a target="_blank" href="/p/114c27b6456c">
阅读 21
</a> <a target="_blank" href="/p/114c27b6456c#comments">
· 评论 3
</a> <span> · 喜欢 3</span>
</div>
</div>
</li>
</ul>
正则匹配,抠出关键信息
上面我已经提取出有用的关键的HTML,现在要做的是让爬虫做同样的事情。所以我用到啦正则匹配。
- 正则匹配出粉丝", "关注", "文章", "字数", "收获喜欢"
#从html中加载基本用户信息
def loadAuthorBaseInfoFromHtml(authorInfo, latest_articles_html)
infoKeys=["粉丝", "关注", "文章", "字数", "收获喜欢"]
infoValues = Array.new(infoKeys.length)
if /<ul class=\"clearfix\">([\s\S]*?)<\/ul>/ =~ latest_articles_html then authorInfoHtml= $1.force_encoding("UTF-8")
for i in 0 .. infoKeys.length-1
if /#{"<b>([0-9]*)</b><span>#{infoKeys[i]}</span>".force_encoding("UTF-8")}/=~ authorInfoHtml
infoValues[i]= $1
end
end
end
authorInfo.setBaseInfo(infoValues[0], infoValues[1], infoValues[2], infoValues[3], infoValues[4])
end
其他匹配代码请参看源代码
整合信息,多样化地输出成果物
当统计出用户的文章信息后,就是把统计信息输出来。为了让输出的产物更加丰富和自定义程度更高,所以我采取了渲染模板的方式,将数据和界面分离。
模板文件:
<body>
<section>
<header>
<h1>@{title}</h1>
<section>统计时间:@{time}</section>
</header>
<section id="content">
<table>
<thead>
<tr>
<th>序号</th>
<th>姓名</th>
<th>文章数</th>
<th>字数</th>
<th>阅读量</th>
<th>收到评论</th>
<th>收到喜欢</th>
<th>小buddy姓名</th>
</tr>
</thead>
<tbody>
@{content}
</tbody>
</table>
</section>
<footer>@{footer}</footer>
</section>
</body>
然后在Ruby代码中加载模板文件,并将@{title}、@{time}、 @{content}、 @{content}替换真实的统计信息
def out2Html(title)
tplFile = open @tpl
tplContent = tplFile.read
tplFile.close
content =""
for i in 0 .. @authorList.length-1
author = @authorList[i]
content+=format(" <tr>
<td>%s</td>
<td><a target= \"_blank\" href=\"http://jianshu.com/users/%s\">%s</a></td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
</tr>", i, author.id, author.name, author.post_count, author.word_count, author.read_count, author.comment_count, author.liked_count, author.buddy)
end
today = Time.new;
timeStr= today.strftime("(%Y-%m-%d %H:%M:%S)");
footer="Powered By <a target=\"_blank\" href=\"http://wangbaiyuan.cn\">BrainWang@ThoughtWorks</a>"
out = tplContent.gsub(/@\{title\}/, title)
out = out.gsub(/@\{content\}/, content)
out = out.gsub(/@\{footer\}/, footer)
out = out.gsub(/@\{time\}/, timeStr)
timeStr= today.strftime("(%Y-%m-%d)");
file=open("output/#{title+timeStr}.html","w")
file.write out
print "\n输出文件位于", Pathname.new(File.dirname(__FILE__)).realpath,"/",file.path
file.close
end
当然,那天只要加一个out2json就可轻松做一个API,实现更高的定制化效果啦
项目主页
https://github.com/geekeren/jianshu_spider
使用方法
- 下载项目代码并运行
cd jianshu_spider/
ruby main.rb
更详细的项目介绍请移步Github项目主页

