LightKV是基于Java NIO的轻量级,高性能,高可靠的key-value存储组件。
一、起源
Android平台常见的本地存储方式, SDK内置的有SQLite,SharedPreference等,开源组件有ACache, DiskLruCahce等,有各自的特点和适用性。
SharedPreference以其天然的 key-value API,二级存储(内存HashMap, 磁盘xml文件)等特点,为广大开发者所青睐。
然而,任何工具都是有适用性的,参见文章《不要滥用SharedPreference》。
当然,其中一些缺点是其定位决定的,比如说不适合存储大的key-value, 这个无可厚非;
不过有一些地方可以改进,比如存储格式:xml解析速度慢,空间占用大,特殊字符需要转义等特点,对于高频变化的存储,实非良策。
故此,有必要写一个改良版的key-value存储组件。
二、LightKV原理
2.1、存储格式
我们希望文件可以流式解析,对于简单key-value形式,完全可以自定义格式。
例如,简单地依次保存key-value就好:
key|value|key|value|key|value……
value
关于value类型,我们需要支持一些常用的基础类型:boolean, int, long, float, double, 以及String 和 数组(byte[])。
尤其是后者,更多的复合类型(比如对象)都可以通过String和数组转化。
作为底层的组件,支持最基本的类型可以简化复杂度。
对于String和byte[], 存储时先存长度,再存内容。
key
我们观察到,在实际使用中key通常是预先定义好的;
故此,我们可以舍弃一定的通用性,用int来作为key, 而非用String。
有舍必有得,用int作为key,可以用更少的空间承载更多的信息。
public interface DataType {
int OFFSET = 16;
int MASK = 0xF0000;
int ENCODE = 1 << 20;
int BOOLEAN = 1 << OFFSET;
int INT = 2 << OFFSET;
int FLOAT = 3 << OFFSET;
int LONG = 4 << OFFSET;
int DOUBLE = 5 << OFFSET;
int STRING = 6 << OFFSET;
int ARRAY = 7 << OFFSET;
}int的低16位用来定义key,
17-19位用来定义类型,
20位预留,
21位标记是否编码(后面会讲到),
32位(最高位)标记是否有效:为1时为无效,读取时会跳过。
内存缓存
SharePreference相对于ACache,DiskLruCache等多了一层内存的存储,于是他们的定位也就泾渭分明了:
后者通常用于存储大对象或者文件等,他们只负责提供磁盘存储,至于读到内存之后如果使用和管理,则不是他们的职责了。
太大的对象会占用太多的内存,而SharePreference是长期持有引用,没有空间限制和淘汰机制的,因此SharePreference适用于“轻量级存储”, 而由此所带来的收益就是读取速度很快。
LightKV定位也是“轻量级存储”,所以也会在内存中存储key-value,只不过这里用SparseArray来存储。
2.2、 存储操作
上面提到, 存储格式是简单地key-value依次排列:
key|value|key|value|key|value……
这样存放,读取时可以流式地解析,甚至,写入时可以增量写入。
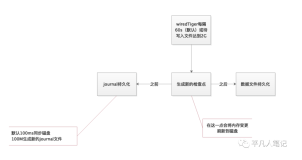
方案一、增量&异步
增量操作
新增:在尾部追加key|value即可;
删除:为了避免字节移动,可以用标记的方法——将key的最高位标记为1;
修改:如果value长度不变,寻址到对应的位置,写入value即可;否则,先“删除”,再“新增”;
GC: 解析文件内容时记录删除的内容的长度,大于设定阈值则清空文件,做一次全量写入。
mmap
要想增量修改文件,需要具备随机写入的能力:
Java NIO会是不错的选择,甚至,可以用mmap(内存映射文件)。
mmap还有一些优点:
1、直接操作内核空间:避免内核空间和用户空间之间的数据拷贝;
2、自动定时刷新:避免频繁的磁盘操作;
3、进程退出时刷新:系统层面的调用,不用担心进程退出导致数据丢失。
如果要说不足,就是在映射文件阶段比常规的IO的打开文件消耗更多。
所以API中建议大文件时采用mmap,小文件的读写用建议用常规IO;而网上介绍mmap也多是举例大文件的拷贝。
事实上如果小文件是高频写入的话,也是值得一试的,
比如腾讯的日志组件 xlog 和 存储组件 MMKV, 都用了mmap。
mmap的写入方式其实类似于异步写入,只是不需要自己开线程去刷数据到磁盘,而是由操作系统去调度。
这样的方式有利有弊:好处是写入快,减少磁盘损耗;
缺点就是,和SharePreference的apply一样,不具备原子性,没有入原子性,一致性就得不到保障。
比如,数据写入内存后,在数据刷新到磁盘之前,发生系统级错误(如系统崩溃)或设备异常(如断电,磁盘损坏等),此时会丢失数据;
如果写入内存后,刷入磁盘前,有别的代码读取了刚才写入的内存,就有可能导致数据不一致。
不过,通常情况下,发生系统级错误和设备异常的概率较低,所以还是比较可靠的。
方案二、全量&同步
对于一些核心数据,我们希望用更可靠的方式存储。
怎么定义可靠呢?
首先原子性是要有的,所以只能同步写入了;
然后是可用性和完整性:
程序异常,系统异常,或者硬件故障等都可能导致数据丢失或者错误;
需添加一些机制确保异常和故障发生时数据仍然完整可用。
查看SharedPreference源码,其容错策略是,
写入前重命名主文件为备份文件的名字,成功写入则删除备份文件,
而打开文件阶段,如果发现有备份文件,将备份文件重命名为主文件的名字。
从而,假如写入数据时发生故障,再次重启APP时可以从备份文件中恢复数据。
这样的容错策略,总体来说是不错的方案,能保证大多数据情况下的数据可用性。
我们没有采用该方案,主要是考虑该方案操作相对复杂,以及其他一些顾虑。
我们采用的策略是:冗余备份+数据校验。
冗余备份
冗余备份来提高数据数据可用性的思想在很多地方有体现,比如 RAID 1 磁盘阵列。
同样,我们可以通过一份内存写两个文件,这样当一个文件失效,还有另外一个文件可用。
比方说一个文件失效的概率时十万分之一,则两个文件同时失效的概率是百亿分之一。
总之,冗余备份可以大大减少数据丢失的概率。
有得必有失,其代价就是双倍磁盘空间和写入时间。
不过我们的定位是“轻量级存储”,如果只存“核心数据”,数据量不会很大,所以总的来说收益大于代价。
就写入时间方面,相比SharedPreference而言,重命名和删除文件也是一种IO,其本质是更新文件的“元数据”。
写磁盘以页(page)为单位,一页通常为4K。


向文件写入1个字节和2497字节,在磁盘写入阶段是等价的(都需要占用4K的字节)。
数据量较少时,写入两份文件,相比于“重命名->写数据->删除文件”的操作,区别不大。
数据校验
数据校验的方法通常是对数据进行一些的运算,将运算结果放在数据后;读取时做同样运算,然后和之前的结果对比。
常见的方法有奇偶校验,CRC, MD5, SHA等。
奇偶校验多被应用于计算机硬件的错误检测中; 软件层面,通常是计算散列。
众多Hash算法中,我们选择 64bit 的 MurmurHash, 关于MurmurHash可查看笔者的另一篇文章《漫谈散列函数》。
在考虑分组写入还全量写入,分组校验还是全量校验时,
分组的话,细节多,代码复杂,还是选择全量的方式吧。
也就是,收集所有key|value到buffer, 然后计算hash, 放到数据后,一并写入次磁盘。
鱼和熊掌
不同的应用场景有不同的需求。
LightKV同时提供了快速写入的mmap方式,和更可靠写入的同步写入方式。
它们有相同的API,只是存储机制不一样。
public abstract class LightKV {
final SparseArray<Object> mData = new SparseArray<>();
//......
}
public class AsyncKV extends LightKV {
private FileChannel mChannel;
private MappedByteBuffer mBuffer;
//......
}
public class SyncKV extends LightKV {
private FileChannel mAChannel;
private FileChannel mBChannel;
private ByteBuffer mBuffer;
//......
}AsyncKV由于不具备一致性,所以也没有必要冗余备份了,写一份就好,以求更高的写入效率和更少磁盘写入。
SyncKV由于要做冗余备份,所以需要打开两个文件,不过一份用同一份buffer即可;
两者的特点在前面“方案一”和“方案二”中有所阐述了,根绝具体需求灵活使用即可。
2.3 内容混淆
对于用XML来存储的SharePreferences来说,打开其文件即可一览所有key-value, 即使开发者对value进行编码,key还是可以看到的。
SharePreferences的文件不是存在App下的目录,在沙盒之中吗?
无root权限下,对于其他应用(非系统),沙盒确实是不可访问的;
但是对于APP逆向者(黑色产业?)来说,SharePreferences文件不过是囊中之物,或可从中一窥APP的关键,以助其破解APP。
故此,混淆内容文件,或可增加一点破解成本。
对于APP来说,没有绝对的安全,只是破解成本与收益之间的博弈,这里就不多作展开了。
LightKV由于采用流式存储,而且key是用int类型,所以不容易看出其文件内容;
但是如果value是明文字符串,还是可以看到部分内容的,如下图:
LightKV提供了混淆value(String和Array类型)的接口:
public interface Encoder {
byte[] encode(byte[] src);
byte[] decode(byte[] des);
}开发者可以按照自己的规则实现编码和解码。
通过该接口可以做很多扩展:
- 1、严格的加密;
- 2、数据压缩;
- 3、内容混淆(事实上前二者都有混淆的功能)
下面例子是简单的混淆,谨供参考:
public class ConfuseEncoder implements LightKV.Encoder {
private static final Random RANDOM = new Random();
private static final byte[] S_BOX = { ...... };
private static final byte[] INV_S_BOX = { ...... };
@Override
public byte[] encode(byte[] src) {
if (src == null || src.length == 0) {
return src;
}
int len = src.length;
byte[] des = new byte[len + 4];
int seed = RANDOM.nextInt();
des[0] = (byte) (seed >> 24);
des[1] = (byte) ((seed >> 16) & 0xFF);
des[2] = (byte) ((seed >> 8) & 0xFF);
des[3] = (byte) (seed & 0xFF);
for (int i = 0; i < len; i++) {
des[i + 4] = S_BOX[(des[i] ^ src[i]) & 0xFF];
}
return des;
}
@Override
public byte[] decode(byte[] des) {
if (des == null || des.length == 0) {
return des;
}
if (des.length <= 4) {
throw new IllegalArgumentException("invalid encoded bytes");
}
int len = des.length - 4;
byte[] src = new byte[len];
for (int i = 0; i < len; i++) {
src[i] = (byte) (INV_S_BOX[des[i + 4] & 0xFF] ^ des[i]);
}
return src;
}
}混淆方法是“随机数+S盒”,S盒运算是AES加密过程中重要的一环,是非线性运算,适合用来做混淆。
为什么不直接用AES?
1、AES运算复杂度较高,要经过很多轮运算,每一轮好几种置换,如果仅仅是混淆的目的,大材小用了;
2、对于APP而言,算法和密钥在终端都是可见的,可通过逆向,调试等方法破解,对于如上场景,简单混淆和AES加解密的效果是差不多的。
如果想要更加安全,APP防护(防逆向,防调试等)才是关键。
当然也不是说AES在终端就不安全了,只是通常在特定场景,结合非对称加密和散列算法(SHA,MD5)方能发挥其作用(如SSL)。
扯远了~
来看下混淆后的结果,打开文件看到的都是无关的乱码:

可能有人会说,这样的做法杀敌一千,自损八百啊!
没事,LightKV的toString方法可以查看文件的内容:

而且,这个“后门”通常在DEBUG时才有效,除非发布RELEASE时不混淆……
具体原理,我们后面细细道来,先说下使用方法。
三、使用方法
前面我们看到,SyncKV和AsyncKV都继承于LightKV, 二者在内存中的存储格式是一致的,都是SparseArray,
所以get方法封装在LightKV中,然后各自实现put方法。
方法列表如下图:
和SharePreferences类似,也有contains, remove, clear 和 commit 方法,甚至于,具体用法也很类似:
public class AppData {
private static final SharedPreferences sp = GlobalConfig.getAppContext().getSharedPreferences("app_data", Context.MODE_PRIVATE);
private static final SharedPreferences.Editor editor = sp.edit();
private static final String ACCOUNT = "account";
private static final String TOKEN = "token";
private static void putInt(String key, int value) {
editor.putInt(key, value);
editor.commit();
}
private static int getInt(String key) {
return sp.getInt(key, 0);
}
}public class AppData {
private static final SyncKV DATA =
new LightKV.Builder(GlobalConfig.getAppContext(), "app_data")
.logger(AppLogger.getInstance())
.executor(AsyncTask.THREAD_POOL_EXECUTOR)
.keys(Keys.class)
.encoder(new ConfuseEncoder())
.sync();
public interface Keys {
int SHOW_COUNT = 1 | DataType.INT;
int ACCOUNT = 1 | DataType.STRING | DataType.ENCODE;
int TOKEN = 2 | DataType.STRING | DataType.ENCODE;
}
public static SyncKV data() {
return DATA;
}
public static String getString(int key) {
return DATA.getString(key);
}
public static void putString(int key, String value) {
DATA.putString(key, value);
DATA.commit();
}
public static int getInt(int key) {
return DATA.getInt(key);
}
public static void putInt(int key, int value) {
DATA.putInt(key, value);
DATA.commit();
}
}当然,以上只是众多封装方法中的一种,具体使用中,不同的开发者有不同的偏好。
对于LightKV而言,key的定义方法如下:
1、最好一个文件对应一个统一定义key的类,如上面的“Keys”;
2、key的赋值,按类型从1到65534都可以定义,然后和对应的DataType做“|”运算(解析的时候需要据此判断类型);
3、String和byte[]类型,如果需要混淆的话,再与DataType.ENCODE做“|”运算。
相对于SharePreferences,LightKV有更多的初始化选项,故而用构造者模式来构建对象。
下面逐一分析各个参数和对应的特性:
3.1 错误日志
public interface Logger {
void e(String tag, Throwable e);
}大多数组件都不能保证运行期不发生异常,发生异常时,开发者通常会把异常信息打印到日志文件(有的还会上传云端)。
故此,LightKV提供了打印日志接口,传入实现类即可。
3.2 异步加载
SharePreferences的加载在新创建的的线程中加载的, 在完成加载之前阻塞读和写:
private void startLoadFromDisk() {
synchronized (mLock) {
mLoaded = false;
}
new Thread("SharedPreferencesImpl-load") {
public void run() {
loadFromDisk();
}
}.start();
}
private void awaitLoadedLocked() {
if (!mLoaded) {
// Raise an explicit StrictMode onReadFromDisk for this
// thread, since the real read will be in a different
// thread and otherwise ignored by StrictMode.
BlockGuard.getThreadPolicy().onReadFromDisk();
}
while (!mLoaded) {
try {
mLock.wait();
} catch (InterruptedException unused) {
}
}
}
@Nullable
public String getString(String key, @Nullable String defValue) {
synchronized (mLock) {
awaitLoadedLocked();
String v = (String)mMap.get(key);
return v != null ? v : defValue;
}
}LightKV同样是利用wait-noifty机制,但是实现相对简单(至少笔者是这么认为的-_-),
还有就是,使用者可以使用自己的线程池,也可以选择不异步加载(不传Executor即可)。
private final Object mWaiter = new Object();
LightKV(Executor executor, /*省略其他参数*/) {
if (executor == null) {
getData(path, keyDefineClass);
} else {
synchronized (mWaiter) {
executor.execute(new Runnable() {
@Override
public void run() {
getData(path, keyDefineClass);
}
});
try {
// wait util loadData() get the object lock(lock of LightKV)
mWaiter.wait();
} catch (InterruptedException ignore) {
}
}
}
}
private synchronized void getData(String path, Class keyDefineClass) {
// we got the object lock, notify waiter to continue the procedure on that thread
synchronized (mWaiter) {
mWaiter.notify();
}
// loading data
}
public synchronized String getString(int key) {
// return value
}值得提醒的是,虽然提供了异步加载,但是有时候没有异步加载的效果,
比如对象初始化的同时立即调用get或者put方法(会阻塞当前线程直到加载完成)。
建议写法:
fun inti(context: Context) {
// 仅初始化对象,以触发加载,不做get和put
AppData.data()
// 其他初始化工作
}3.3 混淆配置
上一章最后一节讲到内容混淆,最后提到DEBUG时可以通过toString方法查看文件内容。
其实漏讲了一些,比如说,构建LightKV时如果不传入 Keys.class , 则无法查看。
其原理为,构建LightKV时,如果传入Keys.class, 可以通过反射获取各个key的定义值以及名字,
这样toString时就可以据此打印文件内容了。
private SparseArray<String> mKeyArray;
private void getKeyArray(Class keyDefineClass) {
if (keyDefineClass == null) {
return;
}
Field[] fields = keyDefineClass.getDeclaredFields();
mKeyArray = new SparseArray<>(fields.length);
for (Field field : fields) {
if (field.getType() == int.class
&& Modifier.isPublic(field.getModifiers())
&& Modifier.isFinal(field.getModifiers())) {
mKeyArray.put(field.getInt(keyDefineClass), field.getName());
}
}
}在RELEASE版本,开发者通常会做代码混淆。
通常情况下,如果不做特别的混淆配置,常量会内联到调用处,定义的地方会被“优化”掉。
public class a
{
// ......
// 原来的 Keys
public static abstract interface a {}
}因此,RELEASE版本调用toString看不到文件的内容。
不过,如果APP被调试了,还是可以从SparseArray中看到内容的……
传入Keys.class还有另一个用途:
随着代码的演进,有的key-value或许再也用不到了,但数据还是存在文件中的。
有没有什么办法在不用的时候从文件中也一并移除呢?
LightKV支持这种操作。
其原理是,在读取文件之前获取Keys的key的定义值(前面有说到),读取文件的key|value时,有对应的key定义则存如SparseArray, 否则忽略。
等下一次刷新数据,没有定义的数据也就被刷掉了。
不过这个操作的前提是Keys的定义没有被“优化”掉-_-
如果需要该特性,可以配置“允许混淆”,但是保持成员:
-keepclassmembers,allowobfuscation interface **.Keys {*;}
-keepclassmembers,allowobfuscation interface **$Keys {*;}如此,最终生成没有被“优化”但被混淆的“Keys”:
public static abstract interface a
{
public static final int a = 131073;
public static final int b = 1441793;
public static final int c = 1441794;
public static final int d = 1507329;
}如果你不需要查看全部内容,也不在意空间占用,可以不传Keys.class,也无需额外的混淆配置。
四、评测
仓促之间,准备的测试用例可能不是很科学,仅供参考-_-
测试用例中,对支持的7种类型各配置5个key, 共35对key|value。
测试机器:小米 note 1, 16G存储
存储空间
| 存储方式 | 文件大小(kb) |
|---|---|
| AsyncKV | 4 |
| SyncKV | 1.7 |
| SharePreferences | 3.3 |
AsyncKV由于采用mmap的打开方式,需要映射一块磁盘空间到内存,为了减少碎片,故而一次映射一页(4K)。
SyncKV由于存储格式比较紧凑,所以文件大小相比SharePreferences要小;
但是由于SyncKV采用双备份,所以总大小和SharePreferences差不多。
数据量都少于4K时,其实三者相差无几;
当存储内容变多时,AsyncKV反而会更少占用,因为其存储格式和SyncKV一样,但是只用存一份。
加载性能
| 存储方式 | 加载耗时(毫秒) |
|---|---|
| AsyncKV | 10.46 |
| SyncKV | 1.56 |
| SharePreferences | 4.99 |
前面也提到,mmap在打开文件比常规打开文件消耗更多,故而API文档中建议大文件时才用mmap。
测试结果确实显示mmap在读取阶段确实比较耗时,但是,如果打开后频繁写入,那就体现出mmap的优势了。
写入性能
理想中的写入是各组key|value全写到内存,然后统一调用一次commit, 这样写入是最快的。
然而实际使用中,各组key|value的写入通常是随机的,所以下面测试结果,都是每次put后立即提交。
AsyncKV例外,因为其定位就是减少IO,让系统内核自己去提交更新。
| 存储方式 | 写入耗时(毫秒) |
|---|---|
| AsyncKV | 2.25 |
| SyncKV | 75.34 |
| SharePreferences-apply | 6.90 |
| SharePreferences-commit | 279.14 |
AsyncKV 和 SharePreferences-apply 这两种方式,提交到内存后立即返回,所以耗时较少;
SyncKV 和 SharePreferences-commit,都是在当前线程提交内存和磁盘,故而耗时较长。
无论是同步写入还是异步写入,LightKV都要比SharePreferences快。
五、总结
SharePreferences是Android平台轻量且方便的key-value存储组件,然而不少可以改进的地方。
LightKV 以 SharePreferences 为参考,从效率,安全和细节方面,提供更好的存储方式。
六、下载
repositories {
jcenter()
}
dependencies {
implementation 'com.horizon.lightkv:lightkv:1.0.7'
}项目地址:
https://github.com/No89757/LightKV
七、属性委托
通过属性委托,可使LightKV简单易用。
具体参考笔者下一篇文章: Kotlin委托属性-简化数据访问
参考文章:
http://www.cnblogs.com/mingfeng002/p/5970221.html
https://blog.csdn.net/u010335298/article/details/72884644
https://cloud.tencent.com/developer/article/1066229
https://segmentfault.com/r/1250000007474916?shareId=1210000007474917
https://zhuanlan.zhihu.com/p/26697193
https://sites.google.com/site/murmurhash