在上一节Keras文本分类实战(上),讲述了关于NLP的基本知识。这部分,将学会以不同方式将单词表示为向量。
词嵌入(word embedding)是什么
文本也被视为一种序列化的数据形式,类似于天气数据或财务数据中的时间序列数据。在之前的BOW模型中,了解了如何将整个单词序列表示为单个特征向量。下面将看到如何将每个单词表示为向量。这里有多种方法可以对文本进行向量化,比如:
- 每个词语(word)表示的词语(words)作为向量
- 每个字符(character)表示的字符(characters)作为向量
- N-gram单词/字符表示为向量
在本教程中,将使用单热编码和单词嵌入将单词表示为向量,这是在神经网络中处理文本的常用方法。
独热码(one-hot encoding)
将单词表示为向量的第一种方式是创建独热码,这是通过将词汇长度的向量与语料库中的每个单词的条目组合一起来完成。
通过这种方式,对于每个单词,只要它在词汇表中存在,就会将该单词在相应的位置设置为1,而向量中其它的位置设置为0。但这种方式可能为每个单词创建相当大的向量,且不会提供任何其他信息,例如单词之间的关系。
假设有一个城市列表,如下例所示:
>>> cities = ['London', 'Berlin', 'Berlin', 'New York', 'London']
>>> cities
['London', 'Berlin', 'Berlin', 'New York', 'London']可以使用scikit-learn包中LabelEncoder对城市列表进行分类:
>>> from sklearn.preprocessing import LabelEncoder
>>> encoder = LabelEncoder()
>>> city_labels = encoder.fit_transform(cities)
>>> city_labels
array([1, 0, 0, 2, 1])之后就可以使用scikit-learn包中OneHotEncoder对城市列表进行编码:
>>> from sklearn.preprocessing import OneHotEncoder
>>> encoder = OneHotEncoder(sparse=False)
>>> city_labels = city_labels.reshape((5, 1))
>>> encoder.fit_transform(city_labels)
array([[0., 1., 0.],
[1., 0., 0.],
[1., 0., 0.],
[0., 0., 1.],
[0., 1., 0.]])使用这种表示,可以看到分类整数值表示数组的位置,1表示出现,0表示不出现。这种编码常用于分类之中,这些类别可以是例如城市、部门或其他类别。
词嵌入|word embeddings
该方法将字表示为密集字向量(也称为字嵌入),其训练方式不像独热码那样,这意味着词嵌入将更多的信息收集到更少的维度中。
嵌入词并不像人类那样理解文本,而是映射语料库中使用的语言的统计结构,其目标是将语义意义映射到几何空间,该几何空间也被称为嵌入空间(embedding space)。这个研究领域的一个著名例子是能够映射King - Man + Woman = Queen。
怎么能获得这样的词嵌入呢?这里有两种方法,其中一种是在训练神经网络时训练词嵌入(word embeddings )层。另一种方法是使用预训练好的词嵌入。
现在,需要将数据标记为可以由词嵌入使用的格式。Keras为文本预处理和序列预处理提供了几种便捷方法,我们可以使用这些方法来处理文本。
首先,可以从使用Tokenizer类开始,该类可以将文本语料库向量化为整数列表。每个整数映射到字典中的一个值,该字典对整个语料库进行编码,字典中的键是词汇表本身。此外,可以添加参数num_words,该参数负责设置词汇表的大小。num_words保留最常见的单词。对前面的例子准备测试和训练数据:
>>> from keras.preprocessing.text import Tokenizer
>>> tokenizer = Tokenizer(num_words=5000)
>>> tokenizer.fit_on_texts(sentences_train)
>>> X_train = tokenizer.texts_to_sequences(sentences_train)
>>> X_test = tokenizer.texts_to_sequences(sentences_test)
>>> vocab_size = len(tokenizer.word_index) + 1 # Adding 1 because of reserved 0 index
>>> print(sentences_train[2])
>>> print(X_train[2])
Of all the dishes, the salmon was the best, but all were great.
[11, 43, 1, 171, 1, 283, 3, 1, 47, 26, 43, 24, 22]索引是按文本中最常用的单词排序,这里索引0是保留的,并不会分配给任何单词,0索引用于填。
未知单词(不在词汇表中的单词)在Keras中用word_count + 1表示,因为它们也可以保存一些信息。
>>> for word in ['the', 'all', 'happy', 'sad']:
... print('{}: {}'.format(word, tokenizer.word_index[word]))
the: 1
all: 43
happy: 320
sad: 450注意:密切注意这种技术与scikit-learn的
CountVectorizer产生的X_train二者之间的区别。
使用CountVectorizer,每个向量的长度相同(总语料库的大小)。使用Tokenizer,每个向量等于每个文本的长度,其数值并不表示计数,而是对应于字典tokenizer.word_index中的单词值。
为了解决每个文本序列在大多数情况下具有不同长度的单词的问题,可以使用pad_sequence()简单地用零填充单词序列。此外,还需要添加maxlen参数来指定序列的长度。以下代码展示如何使用Keras填充序列:
>>> from keras.preprocessing.sequence import pad_sequences
>>> maxlen = 100
>>> X_train = pad_sequences(X_train, padding='post', maxlen=maxlen)
>>> X_test = pad_sequences(X_test, padding='post', maxlen=maxlen)
>>> print(X_train[0, :])
[ 1 10 3 282 739 25 8 208 30 64 459 230 13 1 124 5 231 8
58 5 67 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]第一个值表示从前面的示例中学到的词汇表中的索引,可以看到生成的特征向量主要包含0值元素,这是因为句子比较短。
Keras嵌入层|Embedding Layer
此时,采用的数据仍然是硬编码(hardcode),且没有告诉Keras通过后续任务学习新的嵌入空间。这种情况下,就可以使用Keras 的嵌入层,它采用先前计算的整数并将它们映射到嵌入的密集向量,需要设定以下参数:
- input_dim:词汇量的大小
- output_dim:密集向量的大小
- input_length:序列的长度
使用该嵌入层有两种方法,一种方法是获取嵌入层的输出并将其插入一个全连接层(dense layer)。为此,必须在其中间添加一个flatten layer:
from keras.models import Sequential
from keras import layers
embedding_dim = 50
model = Sequential()
model.add(layers.Embedding(input_dim=vocab_size,
output_dim=embedding_dim,
input_length=maxlen))
model.add(layers.Flatten())
model.add(layers.Dense(10, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()结果如下
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_8 (Embedding) (None, 100, 50) 87350
_________________________________________________________________
flatten_3 (Flatten) (None, 5000) 0
_________________________________________________________________
dense_13 (Dense) (None, 10) 50010
_________________________________________________________________
dense_14 (Dense) (None, 1) 11
=================================================================
Total params: 137,371
Trainable params: 137,371
Non-trainable params: 0
_________________________________________________________________可以看到,有87350个新参数需要训练,嵌入层的这些权重初始化使用随机权重初始化,并在训练期间通过反向传播进行调整,该模型将单词按照句子的顺序作为输入向量。可以使用以下方法进行训练:
history = model.fit(X_train, y_train,
epochs=20,
verbose=False,
validation_data=(X_test, y_test),
batch_size=10)
loss, accuracy = model.evaluate(X_train, y_train, verbose=False)
print("Training Accuracy: {:.4f}".format(accuracy))
loss, accuracy = model.evaluate(X_test, y_test, verbose=False)
print("Testing Accuracy: {:.4f}".format(accuracy))
plot_history(history)结果如下
Training Accuracy: 0.5100
Testing Accuracy: 0.4600
第一个模型的准确性和损失
从图中可以看到,这用来处理顺序数据时通常是一种不太可靠的方法。当处理顺序数据时,希望关注查看本地和顺序信息的方法,而不是绝对的位置信息。
使用嵌入的另一种方法是在嵌入后使用
MaxPooling1D/AveragePooling1D或
GlobalMaxPooling1D/ GlobalAveragePooling1D层。在最大池化的情况下,可以为每个要素维度获取池中所有要素的最大值。在平均池化的情况下取得平均值。一般在神经网络中,最大池化更常用,且效果要优于平均池化。
使用Keras可以在顺序模型中添加各类池化层:
from keras.models import Sequential
from keras import layers
embedding_dim = 50
model = Sequential()
model.add(layers.Embedding(input_dim=vocab_size,
output_dim=embedding_dim,
input_length=maxlen))
model.add(layers.GlobalMaxPool1D())
model.add(layers.Dense(10, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()结果如下
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_9 (Embedding) (None, 100, 50) 87350
_________________________________________________________________
global_max_pooling1d_5 (Glob (None, 50) 0
_________________________________________________________________
dense_15 (Dense) (None, 10) 510
_________________________________________________________________
dense_16 (Dense) (None, 1) 11
=================================================================
Total params: 87,871
Trainable params: 87,871
Non-trainable params: 0
_________________________________________________________________训练步骤不变:
history
format(accuracy))
loss, accuracy = model.evaluate(X_test, y_test, verbose=False)
print("Testing Accuracy: {:.4f}".format(accuracy))
plot_history(history)结果如下
Training Accuracy: 1.0000
Testing Accuracy: 0.8050
最大池模型的准确性和损失
可以看到,模型有一些改进。接下来,将学习如何使用预训练的词嵌入,以及是否对我们的模型有所帮助。
使用预训练的词嵌入
对于机器学习而言,迁移学习比较火热。在NLP中,也可以使用预先计算好的嵌入空间,且该嵌入空间可以使用更大的语料库。最流行的方法是由谷歌开发的Word2Vec和由斯坦福NLP组开发的Glove,其中Word2Vec是通过神经网络来实现,而GloVe通过共生矩阵和使用矩阵分解来实现。在这两种情况下,都是进行降维处理。但比较而言,Word2Vec更准确,GloVe的计算速度更快。
下面将了解如何使用斯坦福NLP组的GloVe词嵌入,从这里下载6B大小的词嵌入(822 MB),还可以在GloVe主页面上找到其他的词嵌入,另外预训练好的Word2Vec的嵌入词可以在此下载。如果你想训练自己的词嵌入,也可以使Python的gensim包有效地完成,更多实现内容可以在此查看。
下面将使用一个示例展示如何加载嵌入矩阵。示例中的文件的每一行都以单词开头,后面跟着特定单词的嵌入向量。该文件包含400000行,每行代表一个单词,后跟其向量作为浮点数流。例如,以下是第一行的前50个字符:
$ head -n 1 data/glove_word_embeddings/glove.6B.50d.txt | cut -c-50
the 0.418 0.24968 -0.41242 0.1217 0.34527 -0.04445由于不需要涵盖所有的单词,只需关注词汇中的单词。由于词汇量有限,因此可以在预训练词嵌入时略过绝大部分单词:
import numpy as np
def create_embedding_matrix(filepath, word_index, embedding_dim):
vocab_size = len(word_index) + 1 # Adding again 1 because of reserved 0 index
embedding_matrix = np.zeros((vocab_size, embedding_dim))
with open(filepath) as f:
for line in f:
word, *vector =
return embedding_matrix可以使用下面函数检索嵌入矩阵:
>>> embedding_dim = 50
>>> embedding_matrix = create_embedding_matrix(
... 'data/glove_word_embeddings/glove.6B.50d.txt',
... tokenizer.word_index, embedding_dim)下面将在训练中使用嵌入矩阵,当使用预训练词嵌入时,我们可以选择在训练期间对嵌入进行更新,或者只按照原样使用这两种方式。
首先,快速查看有多少嵌入向量是非零的:
>>> nonzero_elements = np.count_nonzero(np.count_nonzero(embedding_matrix, axis=1))
>>> nonzero_elements / vocab_size
0.9507727532913566从上可以看到,95.1%的词汇被预先训练的模型所覆盖,这是一个很好的词汇覆盖范围。下面看看使用全局池化层时的性能:
model = Sequential()
model.add(layers.Embedding(vocab_size, embedding_dim,
weights=[
'relu'))结果如下:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_10 (Embedding) (None, 100, 50) 87350
_________________________________________________________________
global_max_pooling1d_6 (Glob (None, 50) 0
_________________________________________________________________
dense_17 (Dense) (None, 10) 510
_________________________________________________________________
dense_18 (Dense) (None, 1) 11
=================================================================
Total params: 87,871
Trainable params: 521
Non-trainable params: 87,350
_________________________________________________________________结果如下:
Training Accuracy: 0.7500
Testing Accuracy: 0.6950

未经训练的词嵌入模型的准确性和损失
由于词嵌入没有经过额外训练,因此预计精度会降低。但是,如果通过使用
trainable=True这种方式训练词嵌入,其执行效果又会是怎样呢?
model = Sequential()
model.add(layers.Embedding(vocab_size, embedding_dim,
weights=[embedding_matrix],
input_length=maxlen,
trainable=True))
'relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()结果如下
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_11 (Embedding) (None, 100, 50) 87350
_________________________________________________________________
global_max_pooling1d_7 (Glob (None, 50) 0
_________________________________________________________________
dense_19 (Dense) (None, 10) 510
_________________________________________________________________
dense_20 (Dense) (None, 1) 11
=================================================================
Total params: 87,871
Trainable params: 87,871
Non-trainable params: 0
_________________________________________________________________history = model.fit(X_train, y_train,
epochs=50,
verbose=False,
validation_data=(X_test, y_test),
batch_size=10)
loss, accuracy = model.evaluate(X_train, y_train, verbose=False)
print("Training Accuracy: {:.4f}".format(accuracy))
loss, accuracy = model.evaluate(X_test, y_test, verbose=False)
print("Testing Accuracy: {:.4f}".format(accuracy))
plot_history(history)结果如下
Training Accuracy: 1.0000
Testing Accuracy: 0.8250
预训练词嵌入模型的准确性和损失
从上可以看到,使用预训练词嵌入是最有效的。在处理大型训练集时,可以加快训练过程。
下面,是时候关注更先进的神经网络模型,看看是否有可能提升模型及其性能优势。
卷积神经网络(CNN)
卷积神经网络或是近年来机器学习领域中最令人振奋的发展成果之一,尤其是在计算机视觉领域里表现优异。关于CNN详细介绍可以看这篇文章《一文入门卷积神经网络:CNN通俗解析》,这里只做简单介绍。
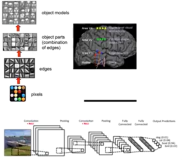
在下图中,可以看到卷积是如何工作的。它首先是从一个具有过滤器内核大小的输入特征开始的,且一维卷积对于平移是不变的,这意味着可以在不同位置识别某些序列,这对文本中的某些模式是很有帮助:

一维卷积
下面演示如何在Keras中使用这个网络,Keras提供了各种卷积层:
embedding_dim
model = Sequential()
model.add(layers.Embedding(vocab_size, embedding_dim, input_length=maxlen))
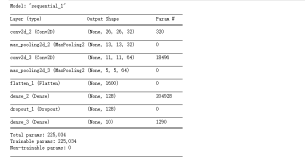
model.add(layers.Conv1D(128, 5, activation='relu'))
model.add(layers.GlobalMaxPooling1D())
model.Dense(10, 结果如下
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_13 (Embedding) (None, 100, 100) 174700
_________________________________________________________________
conv1d_2 (Conv1D) (None, 96, 128) 64128
_________________________________________________________________
global_max_pooling1d_9 (Glob (None, 128) 0
_________________________________________________________________
dense_23 (Dense) (None, 10) 1290
_________________________________________________________________
Total params: 240,129
Trainable params: 240,129
Non-trainable params: 0history = model.fit(X_train, y_train,
epochs=10,
verbose=False,
validation_data=(X_test, y_test),
batch_size=10)
loss, accuracy = model.evaluate(X_train, y_train, verbose=False)
print("Training Accuracy: format(accuracy))
loss, accuracy = model.evaluate(X_test, y_test, verbose=False)
print("Testing Accuracy: {:.4f}".format(accuracy))
plot_history(history)结果如下
Training Accuracy: 1.0000
Testing Accuracy: 0.7700
卷积神经网络的准确度和损失
从上可以看到,其准确率最高为80%,表现并不是很理想,造成这样的原因可能是:
- 没有足够的训练样本
- 拥有的数据并不能很好地概括现实
- 缺乏对调整超参数的关注
CNN网络一般适合在大型训练集上使用,在这些训练集中,CNN能够找到像逻辑回归这样的简单模型无法实现的概括。
超参数优化|Hyperparameters Optimization
深度学习和使用神经网络的一个关键步骤是超参数优化。
正如在目前使用的模型中看到的那样,即使是更简单的模型,也有大量的参数可供调整和选择,这些参数被称为超参数,也是机器学习中最为耗时的部分,依赖于实验和个人经验。
Kaggle上的比赛常用的方法有:一种流行的超参数优化方法是网格搜索(grid search)。这个方法的作用是获取参数列表,并使用它找到每个参数组合运行模型。简单粗暴,但计算量最大;另一种常见的方法是随机搜索(random search),只需采用随机的参数组合。
为了使用Keras应用随机搜索,需要使用KerasClassifier作为scikit-learn API的包装器。使用这个包装器,可以使用scikit提供的各种工具——像交叉验证一样学习。需要的类是RandomizedSearchCV,使用交叉验证实现随机搜索。交叉验证是一种验证模型并获取整个数据集并将其分成多个测试和训练数据集的方法。
常用的方法有k折交叉验证(k-fold cross-validation)和嵌套交叉验证( nested cross-validation ),这里实现k折交叉验证法。在该方法中,数据集被划分为k个相等大小的集合,其中一个集合用于测试,其余的分区用于训练。这使得我们可以运行k个不同的运行仿真,其中每个分区都曾被用作测试集。因此,k越高,模型评估越准确,而每个测试集也越小。
第一步KerasClassifier创建一个创建Keras模型的函数:
def create_model(num_filters, kernel_size, vocab_size, embedding_dim, maxlen):
model = Sequential()
model.add(layers.Embedding(vocab_size, embedding_dim, input_length=maxlen))
model.add(layers.Conv1D(num_filters, kernel_size, activation=))
model.add(layers.GlobalMaxPooling1D())
model.add(layers.Dense(10, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics'accuracy'])
return model接下来,定义在训练中使用的参数。它由一个字典组成,每个参数都在上一个函数中命名。网格上的空格数是3 * 3 * 1 * 1 * 1,其中每个数字是给定参数的不同选择的数量。
使用以下字典初始化参数网格:
param_grid = dict(num_filters=[32, 64, 128],
kernel_size=[3, 5, 7],
vocab_size=[5000],
embedding_dim=[50],
maxlen=[100])接下来运行随机搜索:
from keras.wrappers.scikit_learn import KerasClassifier
from sklearn.model_selection import RandomizedSearchCV
# Main settings
epochs = 20
embedding_dim = 50
maxlen = 100
output_file = 'data/output.txt'
# Run grid search for each source (yelp, amazon, imdb)
for source, frame in df.groupby('source'):
print('Running grid search for data set :', source)
sentences = df['sentence'].values
y = df['label'].values
# Train-test split
sentences_train, sentences_test, y_train, y_test = train_test_split(
sentences, y, test_size=0.25, random_state=1000)
# Tokenize words
tokenizer = Tokenizer(num_words=5000)
tokenizer.fit_on_texts(sentences_train)
X_train = tokenizer.texts_to_sequences(sentences_train)
X_test = tokenizer.texts_to_sequences(sentences_test)
# Adding 1 because of reserved 0 index
vocab_size = len(tokenizer.word_index) + 1
# Pad sequences with zeros
X_train = pad_sequences(X_train, padding='post', maxlen=maxlen)
X_test = pad_sequences(X_test, padding='post', maxlen=maxlen)
# Parameter grid for grid search
param_grid = dict(num_filters=[32, 64, 128],
kernel_size=[3, 5, 7],
vocab_size=[vocab_size],
embedding_dim=[embedding_dim],
maxlen=[maxlen])
model = KerasClassifier(build_fn=create_model,
epochs=, batch_size=10,
verbose=False)
grid = RandomizedSearchCV(estimator=model, param_distributions=param_grid,
cv=4, verbose=1, n_iter=5)
grid_result = grid.fit(X_train, y_train)
# Evaluate testing set
test_accuracy = grid.score(X_test, y_test)
# Save and evaluate results
prompt = input(f'finished {source}; write to file and proceed? [y/n]')
if prompt.lower() not in {'y', 'true', 'yes'}:
break
with open(output_file, 'a') as f:
s = ('Running {} data set\nBest Accuracy : '
'{:.4f}\n{}Test Accuracy : {:.4f}\n\n')
output_string = s.format(
source,
grid_result.best_score_,
grid_result.best_params_,
test_accuracy)
print(output_string)
f.write(output_string)运行需要一段时间,最后结果输出如下:
Running amazon data set
Best Accuracy : 0.8122
{'vocab_size': 4603, 'num_filters': 64, 'maxlen': 100, 'kernel_size': 5, 'embedding_dim': 50}
Test Accuracy : 0.8457
Running imdb data set
Best Accuracy : 0.8161
{'vocab_size': 4603, 'num_filters': 128, 'maxlen': 100, 'kernel_size': 5, 'embedding_dim': 50}
Test Accuracy : 0.8210
Running yelp data set
Best Accuracy : 0.8127
{'vocab_size': 4603, 'num_filters': 64, 'maxlen': 100, 'kernel_size': 7, 'embedding_dim': 50}
Test Accuracy : 0.8384由于某种原因,测试精度高于训练精度,这可能是因为在交叉验证期间得分存在很大差异。可以看到,使用卷积神经网络表现最佳。
结论
本文讲述如何使用Keras进行文本分类,从一个使用逻辑回归的词袋模型变成了越来越先进的卷积神经网络方法。本文没有涉及的另一个重要主题是循环神经网络RNN,更具体地说是LSTM和GRU。这些是处理文本或时间序列等顺序数据的强大且流行的工具。当了解上述内容后,就可以将其用于各种文本分类中,例如:电子邮件中的垃圾邮件检测、自动标记文本或使用预定义主题对新闻文章进行分类等,快动手尝试吧。
作者信息
Nikolai Janakiev ,机器学习和数据科学
本文由阿里云云栖社区组织翻译。
文章原标题《Practical Text Classification With Python and Keras》,译者:海棠,审校:Uncle_LLD。
文章为简译,更为详细的内容,请查看原文。