在当今信息爆炸的时代,伴随着社会事件和自然活动的大量产生(数据的海量增长),人类正面临着“被信息所淹没,但却饥渴于知识”的困境。随着计算机软硬件技术的快速发展、企业信息化水平的不断提高和数据库技术的日臻完善,人类积累的数据量正以指数方式增长 。面对海量的、杂乱无序的数据,人们迫切需要一种将传统的数据分析方法与处理海量数据的复杂算法有机结合的技术。
数据的广泛存在性使得数据越来越多地散布于不同的数据管理系统中,为了便于进行数据分析需要进行数据的集成.数据集成看起来并不是一个新的问题,但是大数据时代的数据集成却有了新的需求,因此也面临着新的挑战.
1) 广泛的异构性.传统的数据集成中也会面对数据异构的问题,但是在大数据时代这种异构性出现了新的变化.主要体现在:①数据类型从以结构化数据为主转向结构化、半结构化、非结构化三者的融合.②数据产生方式的多样性带来的数据源变化.传统的电子数据主要产生于服务器或者是个人电脑,这些设备位置相对固定.随着移动终端的快速发展,手机、平板电脑、UPS等产生的数据量呈现爆炸式增长,且产生的数据带有很明显的时空特性.③数据存储方式的变化.传统数据主要存储在关系数据库中,但越来越多的数据开始采用新的数据存储方式来应对数据爆炸.这就必然要求在集成的过程中进行数据转换,而这种转换的过程是非常复杂和难以管理的.
2)数据质量.数据量大不一定就代表信息量或者数据价值的增大,相反很多时候意味着信息垃圾的泛滥.一方面很难有单个系统能够容纳下从不同数据源集成的海量数据;另一方面如果在集成的过程中仅仅简单地将所有数据聚集在一起而不作任何数据清洗,会使得过多的无用数据干扰后续的数据分析过程.大数据时代数据清洗过程必须更加谨慎,因为相对细微的有用信息混杂在庞大的数据量中.如果信息清洗的粒度过细,很容易将有用的信息过滤掉.清洗粒度过粗又无法达到真正的清洗效果,因此在质与量之间需要进行仔细的考量和权衡.
北京理工大学大数据搜索与挖掘实验室张华平主任研发的NLPIR大数据语义智能分析技术是对语法、词法和语义的综合应用。NLPIR大数据语义智能分析平台平台是根据中文数据挖掘的综合需求,融合了网络精准采集、自然语言理解、文本挖掘和语义搜索的研究成果,并针对互联网内容处理的全技术链条的共享开发平台。
其中KGB(Knowledge Graph Builder)知识图谱引擎是我们自主研发的知识图谱构建与推理引擎,基于汉语词法分析的基础上,采用KGB语法实现了实时高效的知识生成,可以从非结构化文本中抽取各类知识,并实现了从表格中抽取指定的内容等。KGB同时可以定义不同的动作,如抽取动作,并能自定义各类后处理程序。利用KGB知识图谱引擎可以抽取到产品的详细报价信息,方便进行下一步的数据挖掘与图谱构建。
大数据挖掘技术是一个充满希望的研究领域,商业利益的强大驱动力将会不停地促进它的发展。每年都有新的数据挖掘方法和模型问世,人们对它的研究正日益广泛和深入。对海量文本信息进行有效的数据挖掘已经是自然语言处理、信息检索、信息分类、信息过滤、语义挖掘、文本的机器学习等诸多应用领域基础且关键的研究问题,它影响着上层信息服务与信息共享的质量和水平。NLPIR大数据语义智能技术将对中文数据挖掘技术进行深入研究,必将提供出高质量、多功能的中文数据挖掘算法并促进自然语言理解系统的广泛应用。
NLPIR-KGB知识图谱引擎突破传统数据挖掘束缚
2018-10-31
2352
版权
版权声明:
本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《
阿里云开发者社区用户服务协议》和
《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写
侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
简介:
KGB(Knowledge Graph Builder)知识图谱引擎是我们自主研发的知识图谱构建与推理引擎,基于汉语词法分析的基础上,采用KGB语法实现了实时高效的知识生成,可以从非结构化文本中抽取各类知识,并实现了从表格中抽取指定的内容等。
相关实践学习
SaaS 模式云数据仓库必修课
本课程由阿里云开发者社区和阿里云大数据团队共同出品,是SaaS模式云原生数据仓库领导者MaxCompute核心课程。本课程由阿里云资深产品和技术专家们从概念到方法,从场景到实践,体系化的将阿里巴巴飞天大数据平台10多年的经过验证的方法与实践深入浅出的讲给开发者们。帮助大数据开发者快速了解并掌握SaaS模式的云原生的数据仓库,助力开发者学习了解先进的技术栈,并能在实际业务中敏捷的进行大数据分析,赋能企业业务。 通过本课程可以了解SaaS模式云原生数据仓库领导者MaxCompute核心功能及典型适用场景,可应用MaxCompute实现数仓搭建,快速进行大数据分析。适合大数据工程师、大数据分析师 大量数据需要处理、存储和管理,需要搭建数据仓库?学它! 没有足够人员和经验来运维大数据平台,不想自建IDC买机器,需要免运维的大数据平台?会SQL就等于会大数据?学它! 想知道大数据用得对不对,想用更少的钱得到持续演进的数仓能力?获得极致弹性的计算资源和更好的性能,以及持续保护数据安全的生产环境?学它! 想要获得灵活的分析能力,快速洞察数据规律特征?想要兼得数据湖的灵活性与数据仓库的成长性?学它! 出品人:阿里云大数据产品及研发团队专家 产品 MaxCompute 官网 https://www.aliyun.com/product/odps

目录
相关文章
|
7月前
|
SQL
存储
物联网
基于 LLM 的知识图谱另类实践
大语言模型时代,我们有了 few-shot 和 zero-shot 的能力。借助这些 LLM 能力,如何更便捷地实现知识图谱的知识抽取,用知识图谱来解决相关问题。
436
1
2
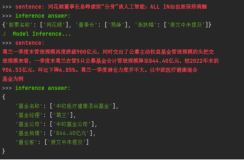
|
21天前
|
机器学习/深度学习
人工智能
算法
机器学习:智能时代的核心引擎
机器学习是人工智能的一个分支,它主要基于计算机科学,旨在使计算机系统能够自动地从经验和数据中进行学习并改进,而无需进行明确的编程。机器学习算法通过构建模型来处理和分析大量数据,以便能够识别模式、进行预测、做出决策或进行其他类型的分析。
8
2
2
|
9月前
|
存储
机器学习/深度学习
人工智能
|
7月前
|
机器学习/深度学习
人工智能
自然语言处理
|
7月前
|
机器学习/深度学习
人工智能
算法
|
9月前
|
存储
自然语言处理
搜索推荐
|
机器学习/深度学习
人工智能
自然语言处理
AI:几张图理清人工智能与机器学习、知识发现、数据挖掘、统计学、模式识别、神经计算学、数据库之间的暧昧关系
AI:几张图理清人工智能与机器学习、知识发现、数据挖掘、统计学、模式识别、神经计算学、数据库之间的暧昧关系
347
0
0
|
机器学习/深度学习
传感器
人工智能
除了视频分析,人工智能和机器学习还有什么好处?
人工智能(AI)和机器学习(ML)在物理安全市场上引起了轰动,将视频分析提升到了新的准确性水平。实际上,这些术语已成为整个行业的通用流行语。但是,人工智能和机器学习对物理安全行业产生影响的潜力远远超出了他们改善视频分析的能力。
517
0
0

|
机器学习/深度学习
人工智能
算法
数据分析,机器学习,深度学习,人工智能的关系我画了这张图
891
0
0
|
存储
算法
大数据
NLPIR智能语义技术让大数据挖掘更简单
NLPIR大数据语义智能分析平台主要有精准采集、文档转化、新词发现、批量分词、语言统计、文本聚类、文本分类、摘要实体、智能过滤、情感分析、文档去重、全文检索、编码转换等十余项功能模块,平台提供了客户端工具,云服务与二次开发接口等多种产品使用形式。
2210
0
0
热门文章
最新文章
1
Google Colab免费GPU大揭晓:超详细使用攻略
2
fdisk、parted无损调整普通分区大小
3
二十款漂亮的CSS字体样式
4
随机生成UserAgent的python库(fake-useragent库)
5
使用zxing识别一幅包含多个二维码的图片
6
leetCode 169. Majority Element 数组
7
图解揭秘Oracle Buffer Header数据结构
8
《CCNP ROUTE 300-101认证考试指南》——8.6节复习所有考试要点
9
iOS (ProjectName-info.plist) (ProjectName-Prefix.pch) 解析
10
经典排序之 堆排序
1
R语言中使用RCPP并行计算指数加权波动率
51
2
R语言用Rshiny探索lme4广义线性混合模型(GLMM)和线性混合模型(LMM)
52
3
Python计算股票投资组合的风险价值(VaR)
48
4
用excel来构建柯布-道格拉斯Cobb-Douglas生产函数的可视化
63
5
R语言使用马尔可夫链Markov Chain, MC来模拟抵押违约
47
6
R语言使用Bass模型进行手机市场产品周期预测
56
7
R语言k-Shape时间序列聚类方法对股票价格时间序列聚类
78
8
R语言基于ARMA-GARCH-VaR模型拟合和预
56
9
R语言检验独立性:卡方检验(Chi-square test)
60
10
MATLAB中的马尔可夫区制转换(Markov regime switching)模型
57



