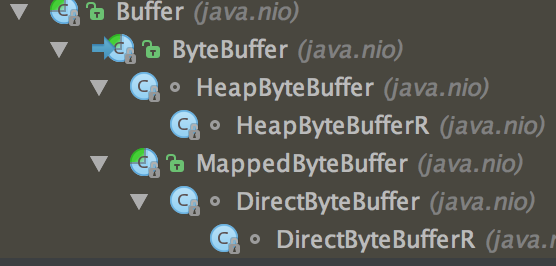
在进行数据传输的时候,往往需要使用到缓冲区,常用的缓冲区就是JDK NIO类库中提供的java.nio.Buffer,实现类如下:
在使用NIO编程时,最常用的是其中的ByteBuffer,本篇分析ByteBuffer内部的源码实现,顺序从父类Buffer入手,了解父类中基础API的实现,再到各个实现子类的实现。
Buffer
Bufferæ¯åæ¾ä¸ç§ç¹å®çãåå§çæ°æ®ç容å¨ãBufferæ¯ä¸ç§ç¹å®åå§ç±»åå ç´ ç线æ§çæéåºåéåï¼å ¶æ ¸å¿çå±æ§æcapacityãlimitãPositionã

capacity:Buffer的容量,表示可以容纳的元素数量
limit:表示第一个不可以被读取或者写入的元素的位置
position:表示下一个被读取或者写入的位置
三者之间的关系如下:0<=position<=limit<=capacity
Buffer只有一个构造方法:
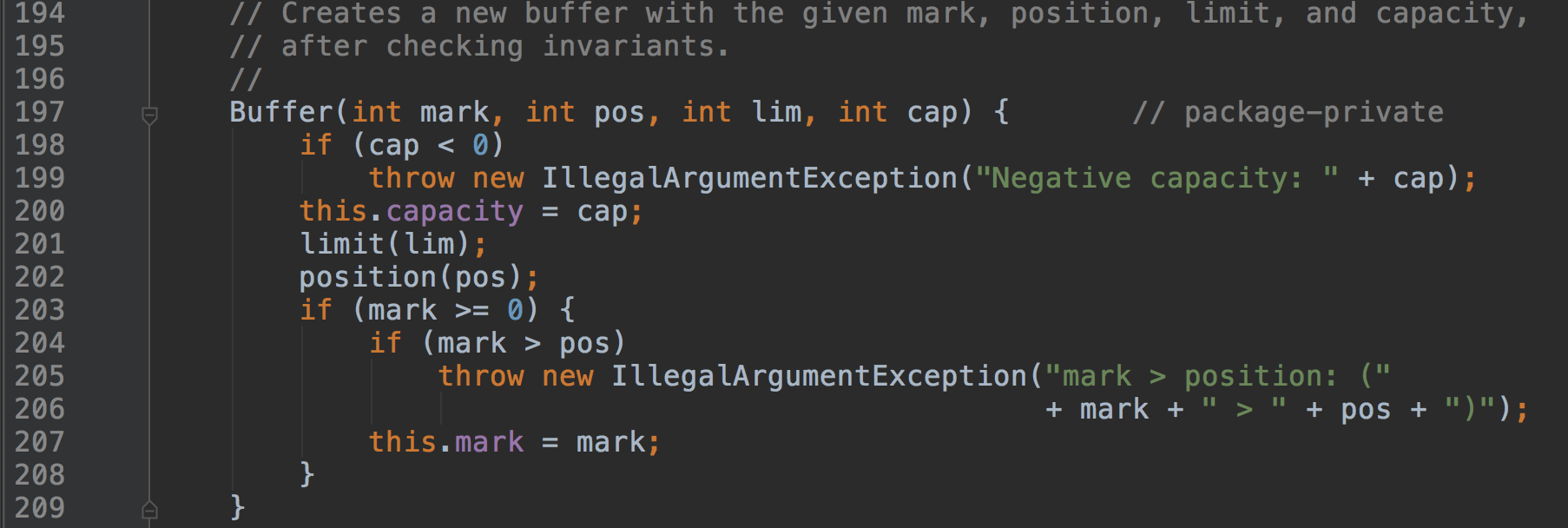
这个构造方式是protected的,也就是说只有在包内可以调用。构造方法中除了capacity、limit、position外还有一个mark参数,且校验了mark参数必须小于position。这个参数非常简单,用于标记position的当前位置,在进行读取写入之类的操作之后可以通过API重新将position重置到标记的位置,对应的API为:Buffer#mark()\Buffer#reset()
Buffer中一个比较重要的API是Buffer#flip
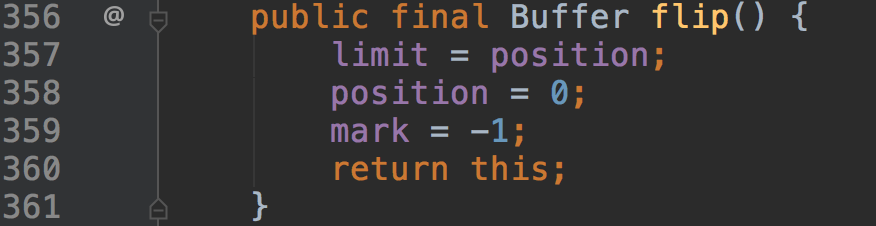
这个方法就是将limit设置到position位置,将position调整到0,将mark设置为-1。
为什么需要有这么一个方法调整位置呢?
这个主要和Buffer只有一个position作为游标相关,读写都是基于position的,所以在写操作完成之后需要进行读操作时,需要将limit设置为position标记有写到哪儿了,而将position 重新移到0,这样就可以读取到所有的写入数据。假设如果有两个游标分别表示读取和写入的位置,是否就可以不用这个API了呢?
Buffer中的代码都非常简单,主要就是自身属性信息的设置和返回,像返回position、返回limit信息等,展开细看。

ByteBuffer
ByteBuffer是Buffer的一个子类,是字节缓冲区。ByteBuffer在Buffer之上定义了6中操作:
- 通过当前位置和指定位置的方式读取和写入byte
- 通过get(byte[])的方式将ByteBuffer中的数据读取到byte[]中
- 通过put(byte[])的方式将连续大量的byte数据写入缓冲区
- 通过当前位置和指定位置的方式将其他类型的数据写入缓冲区或从缓冲区读取数据转换成特定类型
- 提供将ByteBuffer转换成其他类型的Buffer视图的方法,例如ByteBuffer#asCharBuffer
- 提供compact、duplicate、slice来执行一些对ByteBuffer的操作
ByteBuffer的构造方法如下:
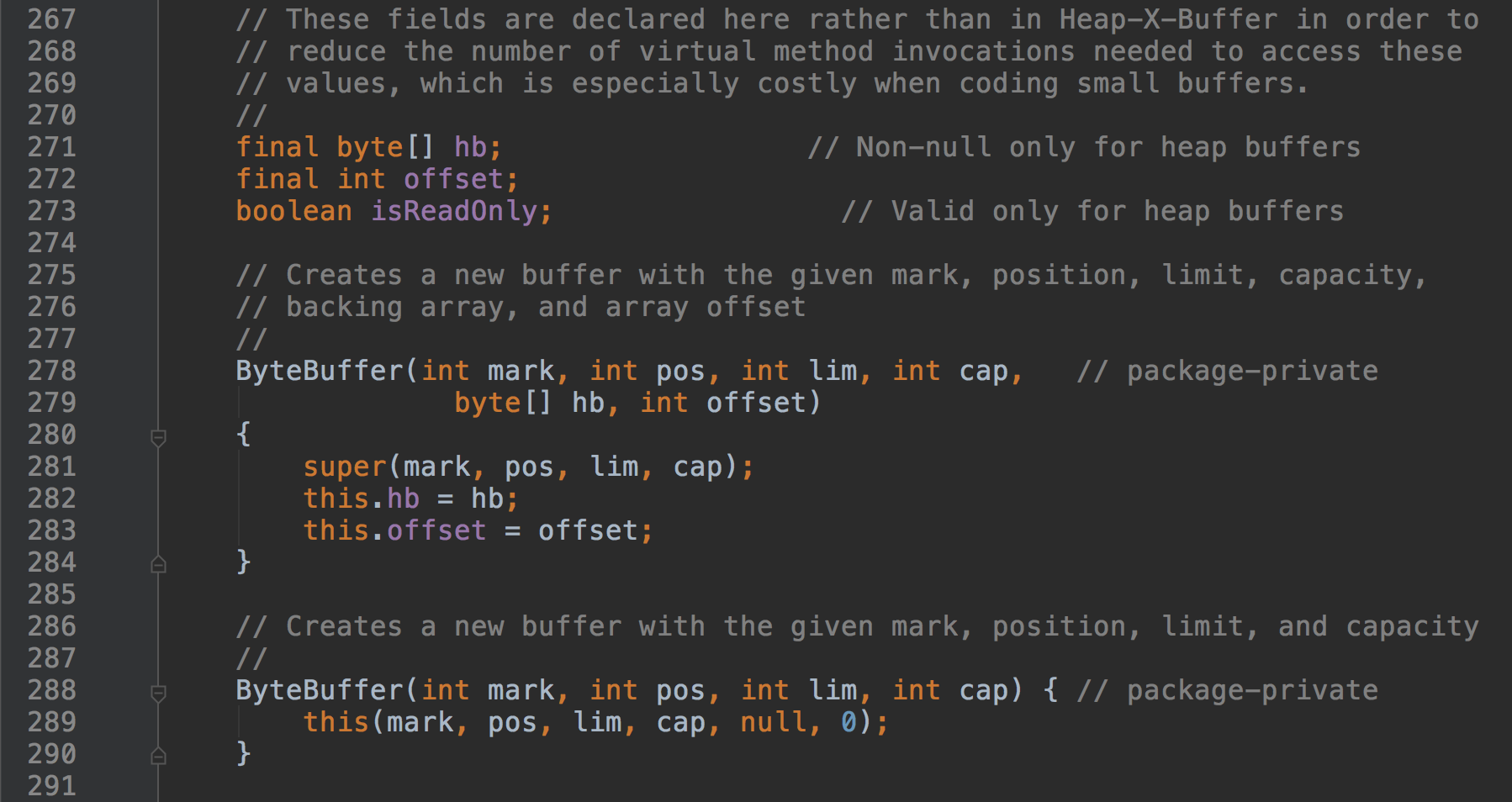
提供了两个构造方法,相对于Buffer增加了一个byte数组和一个offset。byte数组用于存储数据,offset表示ByteBuffer背后实际用于存储的byte数据的其实位置。即你可以使用一个byte数据,从它的任何一个下标开始存储数据,而不一定是0。
当然,这两个方法都是protected的,也就是说实际我们“不能”通过这两个方法去构造我们需要的缓冲区。
那么当我们需要使用缓冲区的时候我们如何去构造一个呢?ByteBuffer提供了两个API:ByteBuffer#allocateDirect、ByteBuffer#allocate
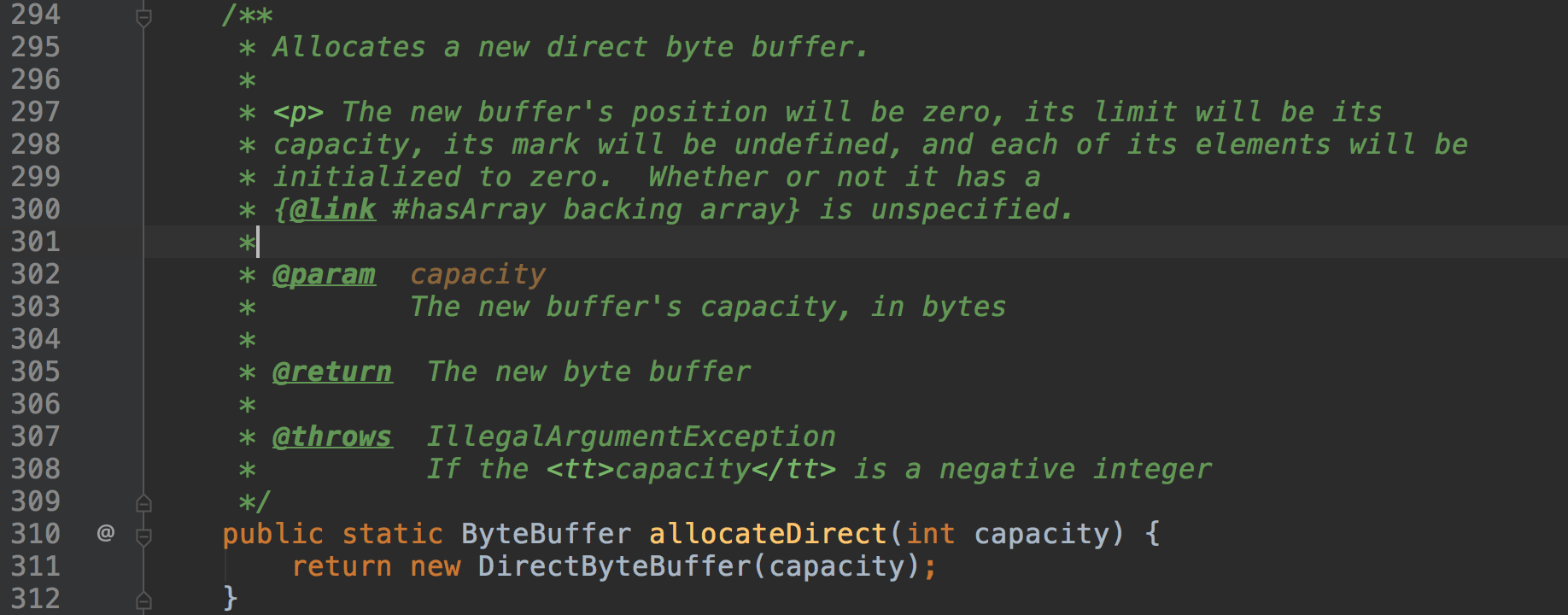
ByteBuffer#allocateDirectåé ä¸ä¸ªDirectByteBufferï¼å³è¿ä¸ªç¼å²åºæ¯ä½¿ç¨å å¤å åçã
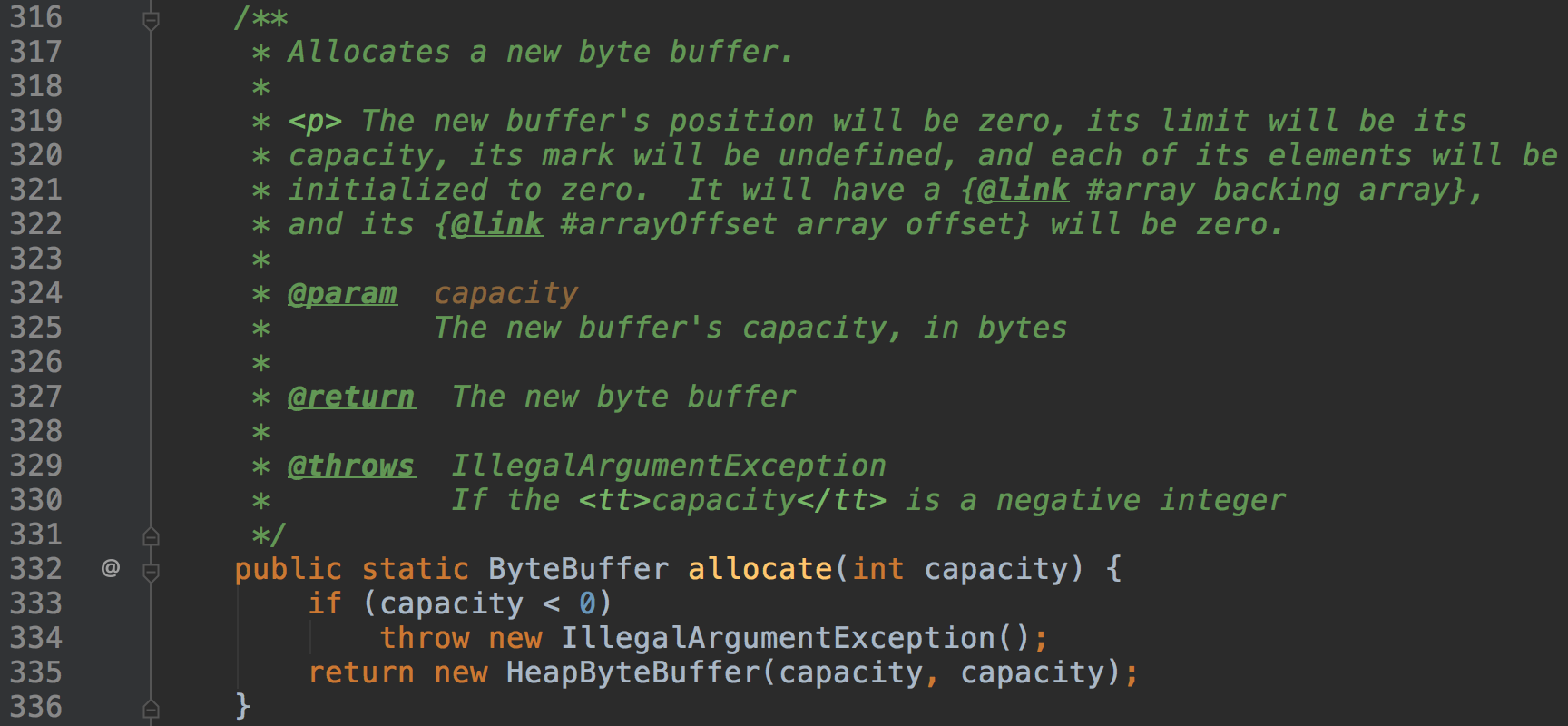
ByteBuffer#allocate在JVM堆上分配一块内存。
新分配的内存position都是0,limit为容量,初始内部填充的数据都为0。
除了通过allocate去创建ByteBuffer,还有一种方式是通过wrap来包装一个byte数组,这样就可以使用ByteBuffer的API来对byte数据进行操作。

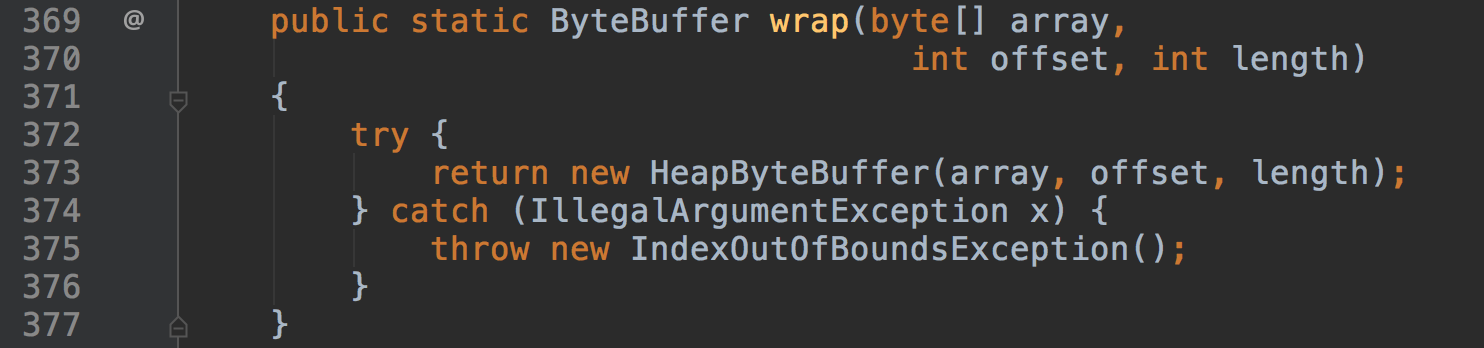
因为byte数据本身在堆内,所以wrap的ByteBuffer也就是HeapByteBuffer。
offset和length将被作为ByteBuffer初始的position和limit。
allocate和wrap都是创建了“新”的ByteBuffer,这里新的含义是他们背后都有自己独立的byte数组用于存储数据。还有一类API,他们也创建ByteBuffer,但是它只是个视图,拥有自己的position、limit等属性,但是存储的byte数组是共享的:
- ByteBuffer#slice:创建一个的ByteBuffer,内容是当前ByteBuffer的一个子序列,共享一个byte数组;两个ByteBuffer的position、limit、mark是独立的;新ByteBuffer的起始位置是原ByteBuffer的position位置
- ByteBuffer#duplicate:“复制”一个ByteBuffer,共享存储的byte数据,拥有独立的capacity、limit、position、mark属性;如果当前ByteBuffer是DirectByteBuffer,那么新Buffer也是DirectByteBuffer,如果当前是HeapByteBuffer,那么新分配的也是HeapByteBuffer
ByteBuffer提供另外一类API来将自己转换成另一个类型的缓冲区:
- ByteBuffer#asXXXBuffer:比如asLongBuffer创建一个新的LongBuffer,底层的存储还是共享当前的byte数组,同时拥有自己的position、limit、mark属性,新Buffer的position为0,limit和capacity为原Buffer除8,因为一个long类型占用8个byte;其他asXXXBuffer方法都类似
ByteBuffer中还有一类API是提供基于当前位置或者指定位置来读写数据的:
- byte getByte()
- byte getByte(int index)
- int getInt()
- int getInt(int index)
- ...
这两种API的差异是没有参数的API会从当前position开始读取数据,之后会修改position位置。而通过传入index,会从index开始读取数据,不会变更position信息。所以如果只是要读取数据,并不希望更改Buffer本身的信息(position),应该使用带有参数的方法。
ByteBuffer的内容只有这么多,接着看它的子类实现,主要是HeapByteBuffer和DirectByteBuffer。
HeapByteBuffer
HeapByteBuffer顾名思义就是JVM堆上的字节缓冲区,他用于缓存数据的byte数组就是直接在堆内申请的。默认的构造方法直接就是new一个byte数组作为数据存储的缓冲区。
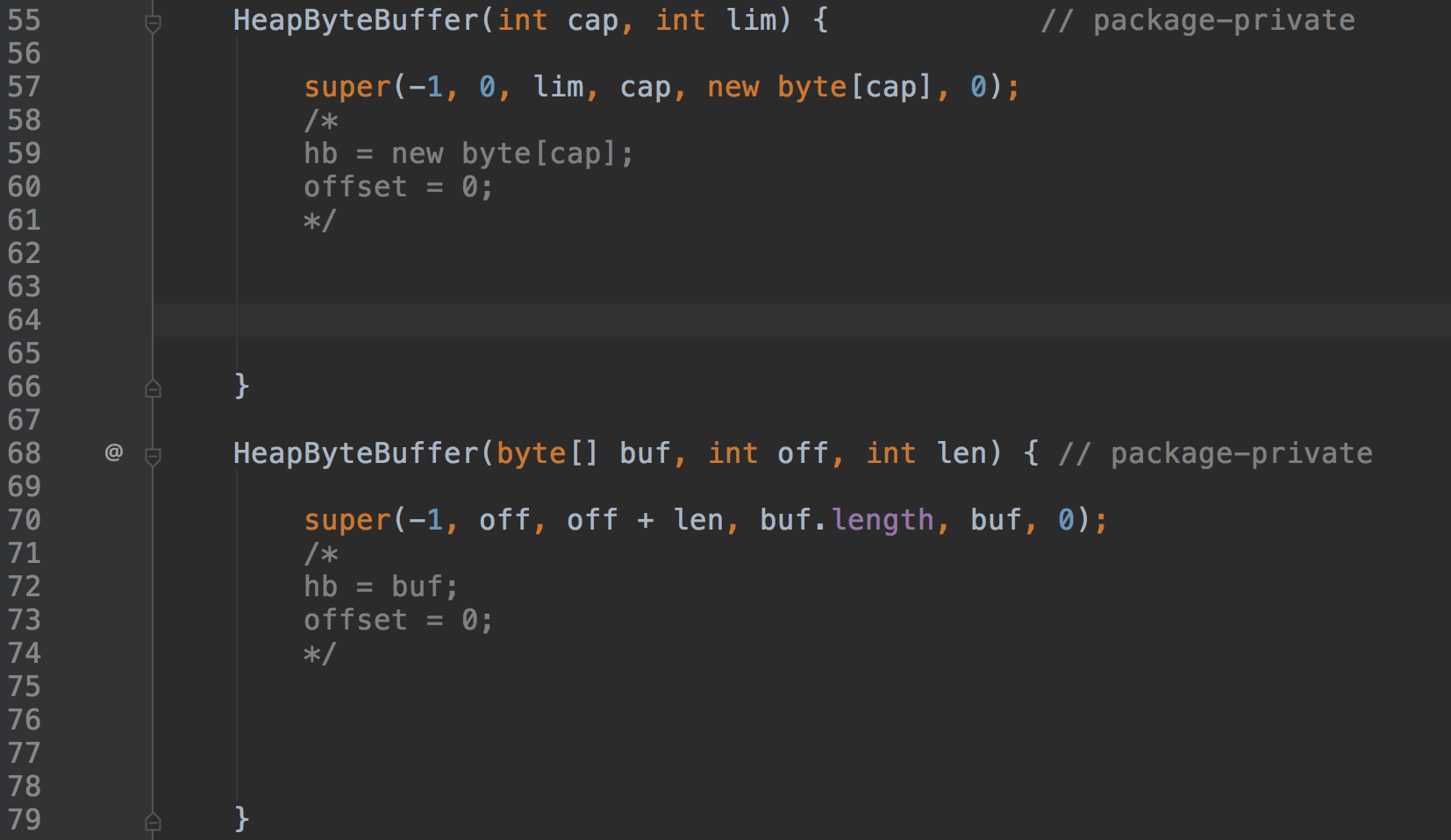
HeapByteBufferé常ç®åï¼å°±æ¯å®ç°äºByteBufferå®ä¹çåç§putågetæ¹æ³ï¼æ²¡æä»ä¹å¥½åæçã
DirectByteBuffer
DirectByteBuffer翻译过来就是直接的字节缓冲区,它是使用直接内存的,即不从JVM的堆上分配内存。
首先看DirectByteBuffer的一个内部类:Deallocator。从类名可以看出这个类应该是做“回收的”。
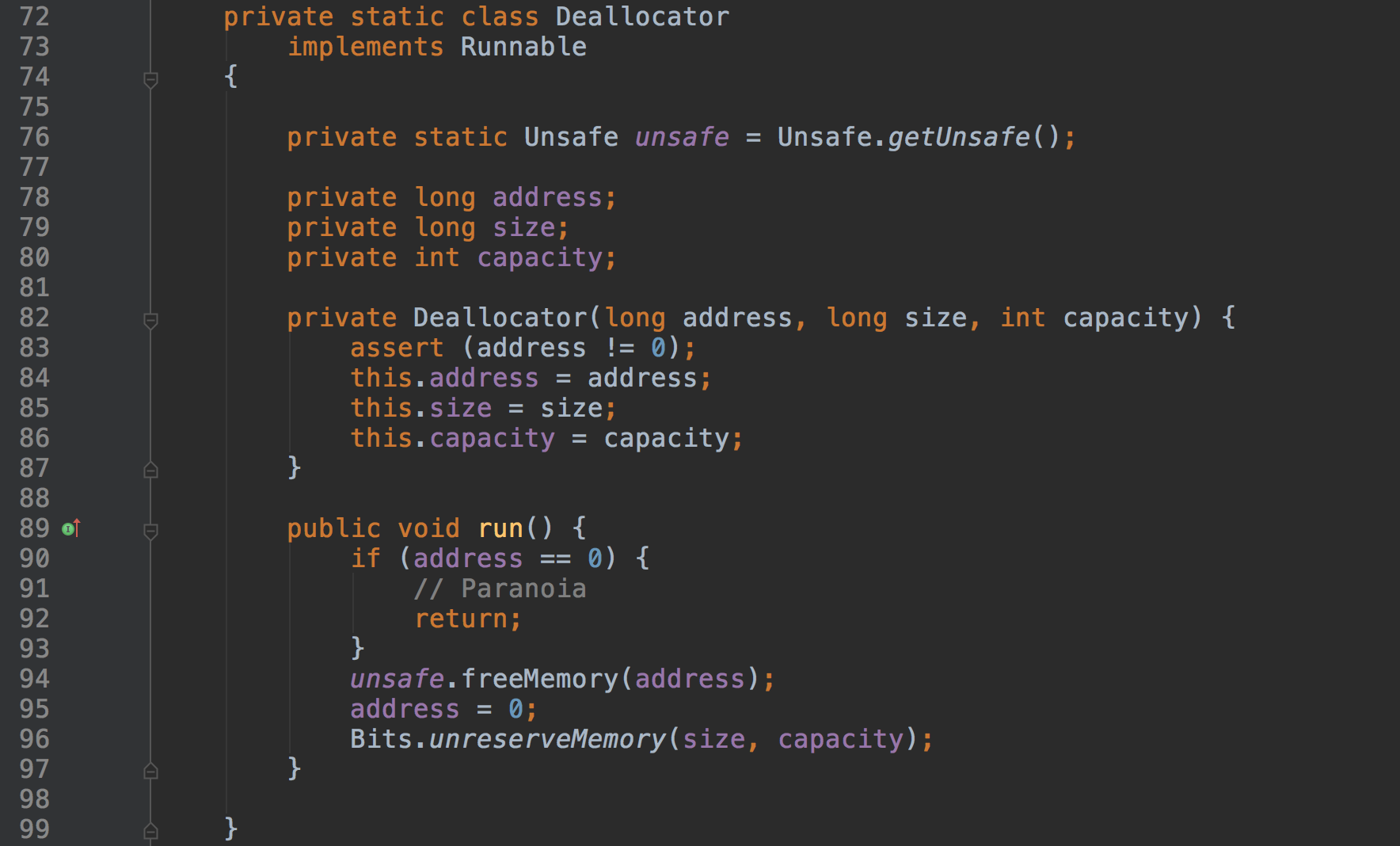
ä»ä»£ç çï¼Deallocatorå®ç°äºRunnableæ¥å£ï¼runæ¹æ³å çå®ç°å°±æ¯éè¿unsafeéæ¾å åã


ç»åCleanerå°±è½æç½Cleaneræ¯ç»ä¸çæ¥å£ï¼è¿åCleaneræ¥æ§è¡æ¸ æ¥æä½ï¼èçæ£çå ååæ¶å¨Deallocatorä¸æ§è¡ã
æ¥ççDirectByteBufferçæé æ¹æ³ï¼
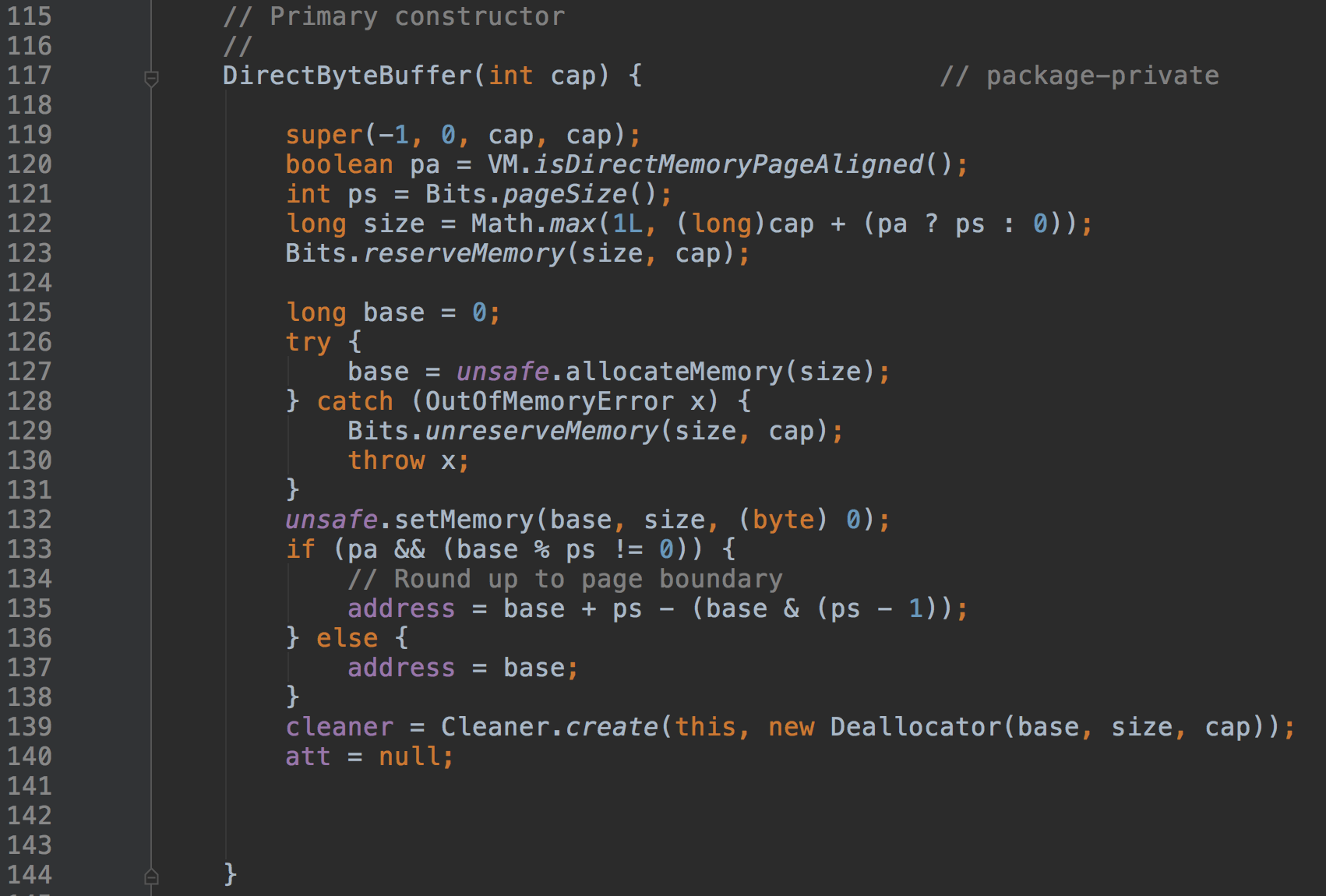
只有一个容量作为参数,而内存是直接通过unsafe分配的,可见内存是直接分配的,而不是在堆上申请的。另外这是一个受保护的方法,也就是说用户是不能直接调用的。
另外还有几个构造方法,可以直接通过内存地址来初始化,或者通过文件描述符来初始化(For memory-mapped buffers),通过已近存在的DirectBuffer来初始化。
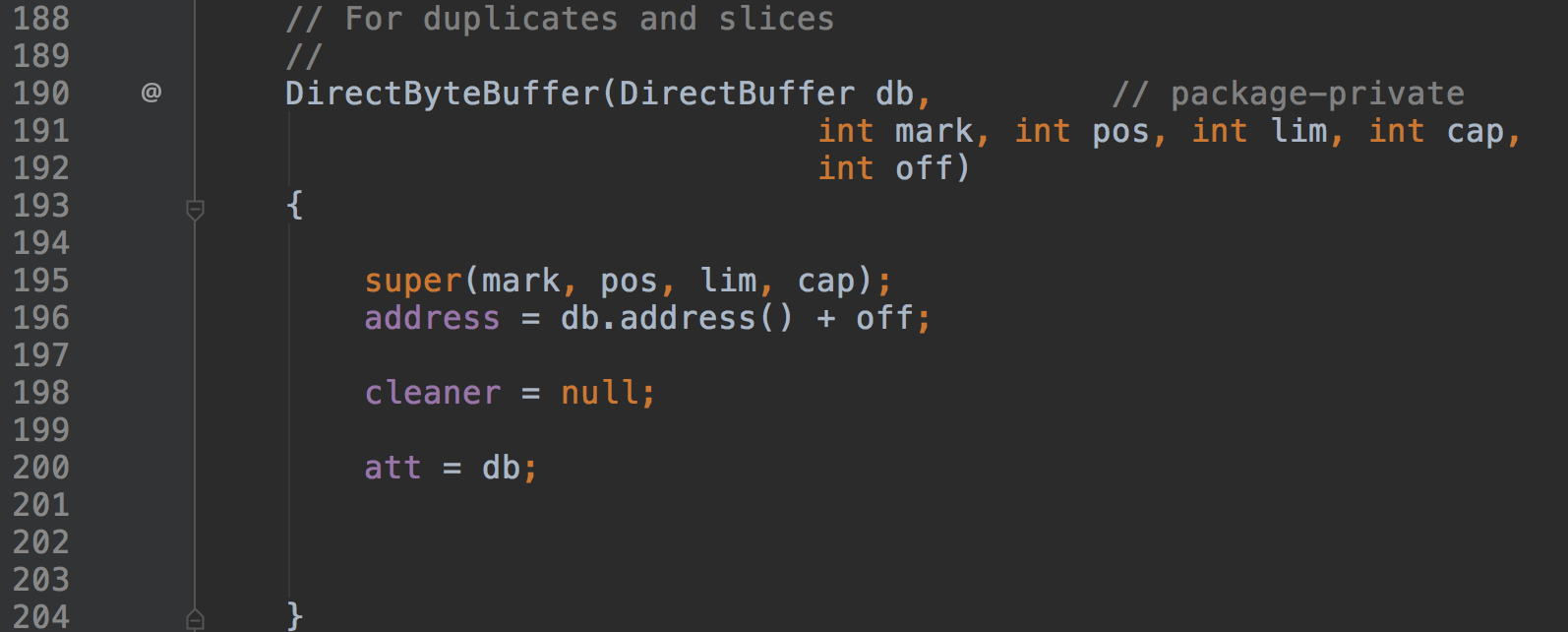
这些方法都是提供给MMAP之类的使用的,一般用户都不会直接调用到。
剩下的方法,像是slice、duplicate,包括通过address返回内存地址都非常简单就不描述了。
另外DirectByteBuffer内部还有一个特殊的方法是asReadOnlyBuffer方法,返回了一个DirectByteBufferR对象。下面看一下DirectByteBufferR做了些什么。
简单从方法出发,大概就是返回只读的一个对象,不能做写入操作。
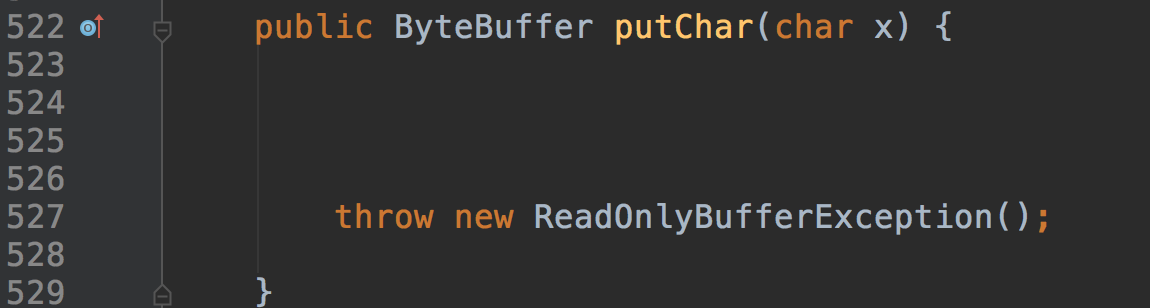
å®é ä¸ä¹æ¯é常ç®åï¼ææçputæä½é½æåºäºå¼å¸¸ãå©ä¸getåsliceçä¹ç±»ä¼¼ï¼ä¸åèµè¿°ã
----------------------------------------------------------------------------------------------------------------------------

这是我的公众号,计划写一个《从0到写一个消息中间件》的系列,目前写了第一篇《什么是消息中间件》,欢迎关注交流。
如果本文对您有帮助,点一下右下角的“推荐”





