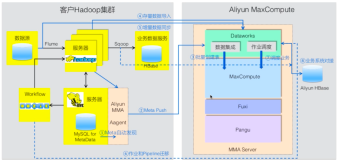
比如需要把生产的hive集群数据迁移到另一个集群,hive提供了2个命令工具,可以实现表的批量迁移。
- 设置默认需要导出的hive数据库
在hive目录/etc/alternatives/hive-conf下添加.hiverc
vi ~/.hiverc
use test;- 创建数据临时目录
hdfs dfs -mkdir /tmp/test- 生成导出数据脚本
hive -e "show tables " | awk '{printf "export table %s to |/tmp/hive-export/%s|;\n",$1,$1}' | sed "s/|/'/g" > /home/hive/qcf/export.hql- 手工导出数据到hdfs
hive -f export.hql- 下载hdfs数据到本地并传送到目标hadoop集群的/tmp/ test 目录 先get到本地:
hdfs dfs -get /tmp/ test /*- 然后put到目标集群上
hdfs dfs -put * /tmp/test- 构造导入语句
cp export.sql import.sql
sed -i 's/export table/import table/g' import.sql
sed -i 's/ to / from /g' import.sql- 导入数据
在hive目录/etc/alternatives/hive-conf下添加.hiverc
vi ~/.hiverc
use test;
hive -f import.sql