本教程将会建立一个神经网络模型,通过分析影评文本将影评分为正面或负面。这是一个典型的二分类问题,是一种重要且广泛适用的机器学习问题。
我们将使用包含50,000条电影评论文本的IMDB(互联网电影数据库)数据集,并将其分为训练集(含25,000条影评)和测试集(含25,000条影评)。训练集和测试集是平衡的,也即两者的正面评论和负面评论的总数量相同。
本教程将会使用tf.keras(一个高级API),用于在TensorFlow中构建和训练模型。如果你想了解利用tf.keras进行更高级的文本分类的教程,请参阅MLCC文本分类指南。你可以使用以下python代码导入Keras:
from tensorflow import keras
import numpy as np
print(tf.__version__)
输出:
1.11.0
下载IMDB数据集
IMDB数据集已经集成于TensorFlow中。它已经被预处理,评论(单词序列)已经被转换为整数序列,整数序列中每个整数表示字典中的特定单词。
您可以使用以下代码下载IMDB数据集(如果您已经下载了,使用下面代码会直接读取该数据集):
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
输出:
参数num_words=10000表示数据集保留了最常出现的10,000个单词。为了保持数据大小的可处理性,罕见的单词会被丢弃。
探索数据
让我们花一点时间来了解数据的格式。数据集经过预处理后,每个影评都是由整数数组构成,代替影评中原有的单词。每个影评都有一个标签,标签是0或1的整数值,其中0表示负面评论,1表示正面评论。
print("Training entries: {}, labels: {}".format(len(train_data), len(train_labels)))输出:
Training entries: 25000, labels: 25000
评论文本已转换为整数数组,每个整数表示字典中的特定单词。以下是第一篇评论文本转换后的形式:
print(train_data[0])输出:
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]
电影评论的长度可能不同,但是神经网络的输入必须是相同长度,因此我们需要稍后解决此问题。以下代码显示了第一篇评论和第二篇评论分别包含的单词数量:
len(train_data[0]), len(train_data[1])输出:
(218, 189)
将整数转换回单词:
了解如何将整数转换回文本也许是有用的。在下面代码中,我们将创建一个辅助函数来查询包含有整数到字符串映射的字典对象:
word_index = imdb.get_word_index()
# The first indices are reserved
word_index = {k:(v+3) for k,v in word_index.items()}
word_index["<PAD>"] = 0
word_index["<START>"] = 1
word_index["<UNK>"] = 2 # unknown
word_index["<UNUSED>"] = 3
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
输出:
现在我们可以使用decode_review函数来查看解码后的第一篇影评文本:
decode_review(train_data[0])输出:
"this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robertis an amazing actor and now the same being directorfather came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released forand would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was alsoto the two little boy's that played theof norman and paul they were just brilliant children are often left out of thelist i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all"
在输入到神经网络之前,整数数组形式的评论必须转换为张量。这种转换可以通过以下两种方式完成:
● 方法一:对数组进行独热编码(One-hot-encode),将其转换为0和1的向量。例如序列[3,5]将成为一个10,000维的向量,除索引3和5为1外,其余全部为零。然后,将其作为我们网络中的第一层——全连接层(稠密层,Dense layer)——以处理浮点向量数据。然而,这种方法会占用大量内存,需要一个 num_words * num_reviews 大小的矩阵。● 方法二:填充数组,使它们都具有相同的长度,然后创建一个形状为 max_length * num_reviews 的整数张量。我们可以使用能够处理这种形状的嵌入层(embedding layer)作为我们神经网络中的第一层。
在本教程中,我们使用第二种方法。
由于电影评论的长度必须相同,我们使用pad_sequences函数对长度进行标准化:
value=word_index["<PAD>"],
padding='post',
maxlen=256)
test_data = keras.preprocessing.sequence.pad_sequences(test_data,
value=word_index["<PAD>"],
padding='post',
maxlen=256)
我们来看现在影评的长度:
len(train_data[0]), len(train_data[1])输出:
(256, 256)
查看填充后的第一篇影评:
print(train_data[0])输出:
神经网络是由层的叠加来实现的,因此我们需要做两个架构性决策:
● 模型中要使用多少层?● 每层要使用多少隐藏单元?
在本例中,输入数据由单词索引数组组成,要预测的标签不是0就是1。我们可以建立这样一个模型来解决这个问题:
vocab_size = 10000
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size, 16))
model.add(keras.layers.GlobalAveragePooling1D())
model.add(keras.layers.Dense(16, activation=tf.nn.relu))
model.add(keras.layers.Dense(1, activation=tf.nn.sigmoid))
model.summary()
输出:
在该模型中,以下4层按顺序堆叠以构建分类器:
● 第一层是嵌入层(Embedding layer)。该层采用整数编码的词汇表,并查找每个词索引的嵌入向量。这些向量是作为模型训练学习的。向量为输出数组添加维度,生成的维度为:(batch, sequence, embedding)。● 接下来,全局平均池化层(GlobalAveragePooling1D layer)通过对序列维度求平均,为每个评论返回固定长度的输出向量。这允许模型以最简单的方式处理可变长度的输入。
● 这个固定长度的输出向量通过一个带有16个隐藏单元的全连接层(稠密层,Dense layer)进行传输。
● 最后一层与单个输出节点紧密连接。使用sigmoid激活函数,输出值是介于0和1之间的浮点数,表示概率或置信水平。
隐藏单元:
上述模型在输入和输出之间有两个中间或“隐藏”层。输出(单元、节点或神经元)的数量是层的表示空间的维度。换句话说,网络在学习内部表示时允许的自由度。
如果模型具有更多隐藏单元(更高维度的表示空间)和/或更多层,那么网络可以学习更复杂的表示。但是,它使网络的计算成本更高,并且可能导致学习不需要的模式——这些模式可以提高在训练数据上的表现,而不会提高在测试数据上的表现。这就是所谓的过度拟合,稍后我们将对此进行探讨。
损失函数和优化器:
模型需要一个损失函数和一个用于训练的优化器。由于这是二分类问题和概率输出模型(一个带有sigmoid 激活的单个单元层),我们将使用binary_crossentropy损失函数。
这不是损失函数的唯一选择,例如您也可以选择mean_squared_error函数。但是通常binary_crossentropy在处理概率上表现更好——它测量概率分布之间的“距离”,或者测量真实分布和预测之间的“距离”(我们的例子中)。
日后,当我们探索回归问题(比如预测房价)时,我们将看到如何使用另一种称为均方误差(Mean Squared Error)的损失函数。
现在,使用优化器和损失函数来配置模型:
loss='binary_crossentropy',
metrics=['accuracy'])
在训练时,我们想要检查模型在以前没有见过的数据上的准确性。因而我们通过从原始训练数据中分离10,000个影评来创建验证集。(为什么现在不使用测试集呢?我们的目标是只使用训练数据开发和调整我们的模型,然后仅使用一次测试数据来评估我们模型的准确性)。
partial_x_train = train_data[10000:]
y_val = train_labels[:10000]
partial_y_train = train_labels[10000:]
本教程采用小批量梯度下降法训练模型,每个mini—batches含有512个样本(影评),模型共训练了40个epoch。这就意味着在x_train和y_train张量上对所有样本进行了40次迭代。在训练期间,模型在验证集(含10,000个样本)上的损失值和准确率同样会被记录。
partial_y_train,
epochs=40,
batch_size=512,
validation_data=(x_val, y_val),
verbose=1)
输出:
通过测试集来检验模型的表现。检验结果将返回两个值:损失值(表示我们的误差,值越低越好)和准确率。
print(results)
输出:
本文中使用了相当简单的方法便可达到约87%的准确率。若采用更先进的方法,模型准确率应该接近95%。
model.fit()函数会返回一个History对象,该对象包含一个字典,记录了训练期间发生的所有事情。
history_dict.keys()
输出:
dict_keys(['acc', 'val_loss', 'loss', 'val_acc'])
字典中共有四个条目,每个条目对应训练或验证期间一个受监控的指标。我们可以使用这些条目来绘制训练和验证期间的损失值、训练和验证期间的准确率,以进行对比。
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
输出:
acc_values = history_dict['acc']
val_acc_values = history_dict['val_acc']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
输出:
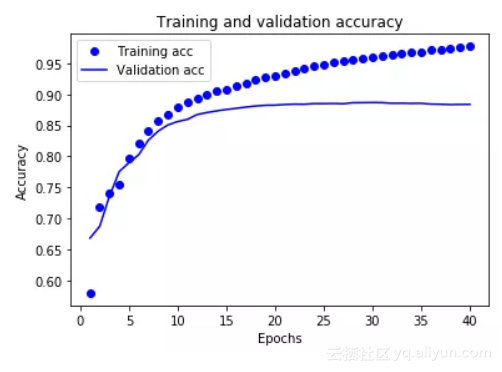
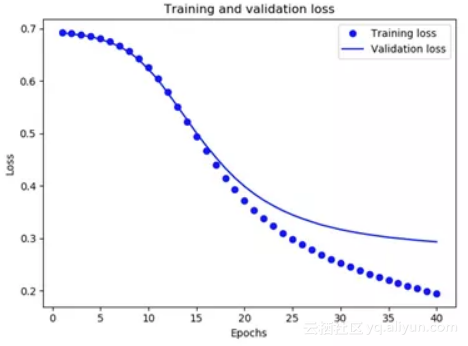
在上面2张图中,点表示训练集的损失值和准确度,实线表示验证集的损失值和准确度。
图中,训练集的损失值随着epoch增大而减少,训练集的准确度随着epoch增大而增大。这在使用梯度下降优化时是符合预期的——在每次迭代时最小化期望数量。
但图中验证集的损失值和准确率似乎在大约二十个epoch后便已达到峰值,这是不应该出现的情况。这是过度拟合的一个例子:模型在训练数据上的表现比它在以前从未见过的数据上的表现要好。在此之后,模型由于在训练集上过度优化,将不适合应用于测试集。
对于这种特殊情况,我们可以通过在二十个左右的epoch后停止训练来防止过度拟合。在以后的教程中,您会看到如何使用回调自动执行此操作。
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.
原文发布时间为:2018-10-25
本文作者:TenorFlow.org