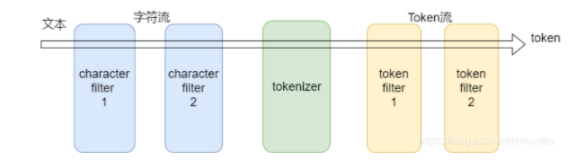
现有的分词算法可分为三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。
交集型歧义——辛勤/劳动;辛/勤劳/动.
组合型歧义——在句子“这个门把手坏了”中,“把手”是个词,但在句子“请把手拿开”中,“把手”就不是一个词。
基于字符串匹配的分词方法
按照扫描方向的不同,串匹配分词方法可以分为正向匹配和逆向匹配;按照不同长度优先匹配的情况,可以分为最大(最长)匹配和最小(最短)匹配理解法
在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。它通常包括三个部分:分词子系统、句法语义子系统、总控部分。在总控部分的协调下,分词子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断,即它模拟了人对句子的理解过程。这种分词方法需要使用大量的语言知识和信息。由于汉语语言知识的笼统、复杂性,难以将各种语言信息组织成机器可直接读取的形式,因此目前基于理解的分词系统还处在试验阶段。统计法
从形式上看,词是稳定的字的组合,因此在上下文中,相邻的字同时出现的次数越多,就越有可能构成一个词。因此字与字相邻共现的频率或概率能够较好的反映成词的可信度。机器学习
首先给出大量已经分词的文本,利用统计机器学习模型学习词语切分的规律(称为训练),从而实现对未知文本的切分。我们知道,汉语中各个字单独作词语的能力是不同的,此外有的字常常作为前缀出现,有的字却常常作为后缀(“者”“性”),结合两个字相临时是否成词的信息,这样就得到了许多与分词有关的知识。这种方法就是充分利用汉语组词的规律来分词。这种方法的最大缺点是需要有大量预先分好词的语料作支撑,而且训练过程中时空开销极大。歧义
歧义是指同样的一句话,可能有两种或者更多的切分方法。主要的歧义有两种:交集型歧义和组合型歧义。交集型歧义——辛勤/劳动;辛/勤劳/动.
组合型歧义——在句子“这个门把手坏了”中,“把手”是个词,但在句子“请把手拿开”中,“把手”就不是一个词。