最近,AI方案设计师Alexandor Honchar在Medium网站上分享一篇文章。他认为生成对抗网络(GAN)目前在生成图像取得了巨大进展,生成的图像几乎能够以假乱真,并且在4年间,面部图像的生成也越来越精细。

但Honchar认为,GAN不该局限在图像生成上,他认为GAN可以应用在更广泛的领域,并提出了GAN在其他领域的应用实例(项目链接见文末)。其中一些已经证实可行,并有学术成果产出,另一些作者目前还在探索中。
以下就是作者总结的GAN的7种”另类“用法:
增加数据
GAN可以训练模型用已有的数据集去产生增加数据。
我们如何检查增加的数据是否真的有帮助呢?主要有两个策略:我们可以在“假”数据上训练我们的模型,并检查它在真实样本上的表现;与之相对的是,我们用真实数据训练模型来做一些分类任务,并且在检查它对生成的”假“数据的表现。
如果它在以上两种情况下都能正常工作,就可以将生成模型中的样本添加到实际数据中并再次重新训练,获得更强的性能。要使此方法更加强大和灵活,请阅读后文第6项。
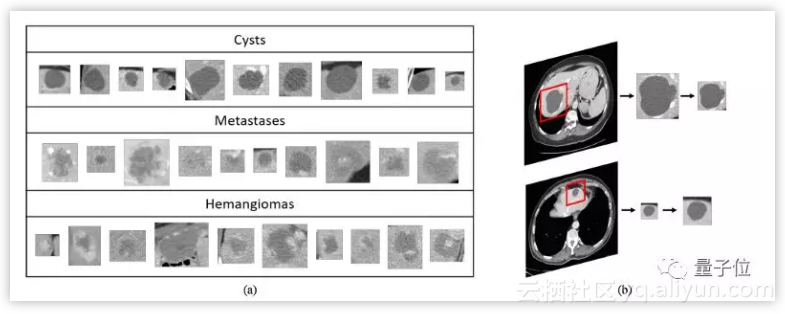
NVIDIA展示过一个很好的例子:他们用GAN去增加不同疾病下的脑部CT图像的数据集。在仅使用经典数据增强的情况下,系统有78.6%的灵敏度和88.4%的特异性;而通过增加合成数据的方法,灵敏度提升至85.7%、特异性提升至92.4%。
隐私保护
许多公司的数据机密而又敏感,例如公司的财务数据、病患的医疗数据等等。但是在某些情况下,有时我们需要与顾问或研究人员等第三方分享。
如果只想分享数据的大致情况,对数据的细节进行隐藏,我们可以利用生成模型来抽象数据,这样就能保护确切的机密数据。
对共享数据进行保密很困难。当然,我们有不同的加密方案,如同态加密,但它们有已知的缺点,例如在海量数据中隐藏少量数据比较困难(比如10GB代码中隐藏1MB信息)。
2016年,谷歌开辟了一条新研究路径,把GAN的竞争框架用到加密加密问题上,让两个网络在加密和解密中竞争来实现目的:
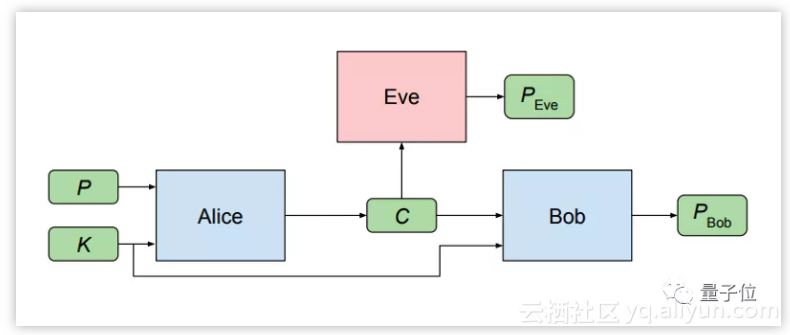
但它的优点不是处理数据的效率,或创造另一个领域的“AI”流行语。我们应该记住,通过神经网络获得的结果通常仍然包含有关输入数据最有用的信息,并且压缩后的数据仍然可以进行分类、回归、聚类或者其他操作。
如果我们将“压缩”替换为“加密”,那么我们就可以做到与第三方共享数据而不显示任何数据集的细节。
异常探测
主要生成模型有变分自动编码器(VAE)和生产对抗网络(GAN)两类,它们都由两部分构成。 VAE有编码器和解码器,分别用于建模和重建。 GAN由生成器和鉴别器组成,前者用于模拟分布,后者判断它是否接近训练数据。
我们可以看到,它们在某种程度上非常相似:都用有建模和判断部分(在VAE中我们可以认为重建是一种判断)。建模部分应该学习数据分布。
如果我们将一些不是来自训练分布的样本给模型做出判断,那么将会发生什么?训练有素的GAN鉴别器会输出个0,而VAE的重建误差将高于训练数据的平均值。我们的无监督异常探测器就有了,易于训练也易于评估。我们可以用一些”兴奋剂“来训练它,比如Wasserstein GAN所用的统计距离。
在本文中,你可以找到用于异常检测的GAN示例以及自动编码器。我还添加了自己用Keras写成基于自动编码器的粗略草图:
https://github.com/Rachnog/education/blob/master/anomaly/ae_anomaly.py
判别建模
深度学习所做的一切都是将输入数据映射到某个空间,在这个空间中,通过SVM或逻辑回归等简单的数学模型可以更容易地分离或解释。
生成模型也有自己的映射,让我们从VAE开始。 自动编码器将输入样本映射到一些有意义的潜在空间,基本上我们可以直接训练一些模型。这有什么意义?它和仅用编码器层和训练模型直接进行分类有什么不同吗?确实有。自动编码器的潜在空间是复杂的非线性降维,并且在变分自动编码器的情况下也是多变量分布,这可以比一些随机初始化更好地开始初始化训练判别模型。
GAN对于无任何输入只从随机种子生成样本的任务来说有点难度。但我们仍然可以至少开发两种针对这类任务的分类器。第一种,我们已经研究过,就是利用鉴别器将生成的样本分类,同时只是告诉它是真的还是假的。我们可以期望从获得的分类器来更好地规则化,并且可以分类溢出值/异常值:
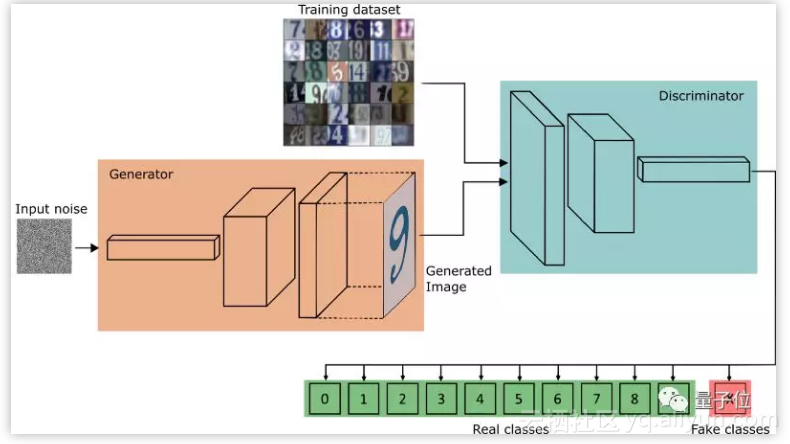
第二种是贝叶斯定理的不公平遗忘分类方法,其中我们基于p(x | c_k)(恰好是条件GAN所做的)和先验p(x),p(c_k)给p(c_k | x)建模。这里的主要问题是GAN真的学习数据分布吗?在最近的一些研究中正在讨论该问题。
领域适配
对我来说,这是最强大的功能之一。 在实践中,我们训练模型所用的数据源,和它们在真实环境中运行的时候几乎不可能相同。
在计算机视觉中,不同的光线条件、相机设置或天气会使非常精确的模型无用。 在自然语言处理(NLP)和语音分析中,俚语或重音会破坏你在基于“语法正确”语言训练模型的表现。 在信号处理中,你很可能用完全不同的设备捕获数据,来训练和生成建模。
不过,这两种数据“类型”彼此非常相似。 我们知道机器学习模型执行从一个条件到另一个条件的映射,保留主要内容,但更改细节。 是的,我说的就是风格迁移,但不是为了艺术创作。

举个例子,例如某个处理闭路电视图像的应用,你训练的模型是建立在高分辨率图像的基础上时,那么你可以尝试用GAN处理图像去除噪点并对其增强。
我可以从信号处理领域举个更激进的例子:有很多与手机加速度计数据相关的数据,描述了不同人的活动。 但是,如果你想在智能手环上使用受过手机数据训练的模型,该怎么办? GAN可以尝试帮助你翻译不同类型的运动。
一般来说,一些预定义的先验模型可以帮助你进行进行领域适配、协方差转换以及处理其他数据中的差异问题。
数据操控
我们讨论过图像的风格迁移。如果我们仅仅是想改变照片中的鼻子呢?或者改变汽车的颜色,又或者是替换演讲中的某些词语而不是完全改变它,我们应该怎么办?
如果想做到这些,我们假定处理的对象包含有限的元素集合,以人脸为例,眼、鼻、口、头发等等元素都有自己的属性。
如果我们可以将照片的像素映射到五官,那么我们就可以调整五官的大小了吗? 有一些数学概念可以做到:自动编码器或许可以,GAN也能做到。

对抗训练
你可能不同意我添加关于机器学习模型攻击的段落,但它的确与生成模型(对抗性攻击算法确实非常简单)和对抗性算法(因为我们有一个模型与另一个模型竞争)有关。
也许你熟悉对抗性例子的概念:模型输入中的微小扰动(甚至可能只是图像中的一个像素)就会导致完全错误的表现。我们有一些方法来防止错误结果的发生,其中一个最基本的方法叫做对抗性训练:利用对抗性的例子来构建更准确的模型。

△ 模型中加入微小干扰,导致将熊猫错误识别为长臂猿
如果不深入细节,我们有这样一个双人游戏:对抗模型(只加入一些微小的扰动)需要最大化其影响力,并且分类模型需要最小化其损失。这看起来很像GAN,但它的目的不同:是为了让模型在面对对抗性攻击时更稳定,并通过某种智能数据增强和正规化提高其性能。
小结
GAN和其他一些生成模型主要用于生成图像、旋律或短文本,它的主要长期目标仍是生成以正确情况为条件的真实世界对象。但在本文中,我列举了几个例子,证明GAN还可以用来改进当前的AI、保护数据、发现异常等等。 我希望你会发现这些例子很有用,并将它用在你的项目中。
最后,附上文中项目实例地址:
”假“数据训练医学识别系统:
https://arxiv.org/pdf/1803.01229.pdf
对抗网络如何加密数据:
https://towardsdatascience.com/adversarial-neural-cryptography-can-solve-the-biggest-friction-point-in-modern-ai-cc13b337f969
用GAN做成的图片分类器:
https://towardsdatascience.com/semi-supervised-learning-with-gans-9f3cb128c5e
图片风格转移项目:
https://ml4a.github.io/ml4a/style_transfer/
改变面部局部五官项目:
https://houxianxu.github.io/assets/project/dfcvae
微扰导致图像识别错误的案例:
https://blog.openai.com/adversarial-example-research/
原文发布时间为:2018-10-24
本文作者:Alexandor Honchar
本文来自云栖社区合作伙伴“机器学习算法与Python学习”,了解相关信息可以关注“机器学习算法与Python学习”。