接下来学习RestFramework框架中的认证、权限、频率组件的使用
一、首先实现用户login登录认证功能
做用户登录认证功能可以通过session、cookie和token三种形式,下面的login认证基于token实现
- 关键点
-- 首先需要设计用户表、用户token表,用户表需要包含用户类型,用户token表包含用户的token值
-- 用户的token值应该是一个随机的、动态的字符串
-- 用户认证成功需要将用户信息和对应的token值返回,后续访问url就可以通过token值来判断用户的状态
附:models.py
from django.db import models
class Userinfo(models.Model):
name = models.CharField(max_length=32)
pwd = models.CharField(max_length=64)
user_type = models.IntegerField(choices=((1,"common_user"),(2,"VIP_user"),(3,"SVIP_user")))
class UserToken(models.Model):
user = models.OneToOneField(to="Userinfo")
token = models.CharField(max_length=128)
- view.py认证逻辑
from rest_framework.views import APIView
from rest_framework.response import Response
import uuid
class LoginView(APIView):
"""
1000:成功
1001:用户名或者密码错误
1002:异常错误
"""
def post(self, request):
#自定义的返回体数据
ret = {"code": 1000, "msg": None, "user": None}
try:
print(request.data) # 重装后的request,request.data从中取所需的数据
name = request.data.get("name")#获取前端用户名
pwd = request.data.get("pwd")#获取前端密码
#数据库校验用户名密码是否正确
user_obj = models.Userinfo.objects.filter(name=name, pwd=pwd).first()
if user_obj:
#通过uuid模块获得随机字符串作为token值
random_str = uuid.uuid4()
#UserToken表中有该用户的信息就用新token值覆盖,没有就创建数据
models.UserToken.objects.update_or_create(user=user_obj, defaults={"token": random_str})
ret["user"] = user_obj.name
ret["token"] = random_str
else:
ret["code"] = 1001
ret["msg"] = "用户名或者密码错误"
except Exception as e:
ret["code"] = 1002
ret["msg"] = str(e)
return Response(ret)
这样就实现了用户的login认证。。。。。。。。。
二、基于RestFramework的认证组件做视图处理类的user认证
首先看一下UserAuth的具体用法:
- 关键点:
--视图处理类下定义名为authentication_classes属性,属性值是一个列表或者元组
--写一个UserAuth(类名随便)认证的类,将类名添加到authentication_classes列表中
--UserAuth认证类必须有一个authenticate(self,request)方法,这个方法下写用户认证逻辑,认证成功:可以返回数据,也可以什么都不做。认证失败:,必须抛异常
-- UserAuth类继承BaseAuthentication类,其实就是给类加了一个authenticate_header方法,没理由,源码要求!
这四点你一定看不懂是什么意思,很正常,这都是RestFramework源码给设定的特定规则,稍后认证源码流程分析会一一分析解答
view.py代码示例:代码实现了book视图类的用户认证功能
from rest_framework.exceptions import AuthenticationFailed
from rest_framework.authentication import BaseAuthentication
#用于认证的类
class UserAuth(BaseAuthentication):
def authenticate(self, request):
token = request.query_params.get("token")
usertoken_obj = models.UserToken.objects.filter(token=token).first()
if usertoken_obj:
return usertoken_obj.user, usertoken_obj.token
else:
raise AuthenticationFailed("用户认证失败,您无权访问!!!")
# book视图处理类
class Booklist(ModelViewSet):
authentication_classes = [UserAuth, ]
queryset = models.Book.objects.all()
serializer_class = BooklistSerializer
接下来一张图带你透析认证组件:

UserAuth认证源码解析.jpg
- 这样的写法只是给book视图类加上了认证,可以将认证类单独卸载一个py文件中,然后在全局settings中添加对应的配置项,这样就可以做到对所有的视图类添加认证功能了!!!
根据实际需求选择合适的方法!!!
app001-utils-Userauth.py
from app001 import models
from rest_framework.exceptions import AuthenticationFailed
from rest_framework.authentication import BaseAuthentication
class UserAuth(BaseAuthentication):
def authenticate(self, request):
token = request.query_params.get("token")
usertoken_obj = models.UserToken.objects.filter(token=token).first()
if usertoken_obj:
return usertoken_obj.user, usertoken_obj.token
else:
raise AuthenticationFailed("用户认证失败,您无权访问!!!")
settings.py
REST_FRAMEWORK = {
'DEFAULT_AUTHENTICATION_CLASSES': (
'app001.utils.Userauth.UserAuth',
)
}
view.py
from app001 import models
from app001.serializers.bookserializer import BooklistSerializer
# 重装了APIView
from rest_framework.viewsets import ModelViewSet
# book视图处理类
class Booklist(ModelViewSet):
queryset = models.Book.objects.all()
serializer_class = BooklistSerializer
三、基于RestFramework的认证组件做视图处理类的权限认证
首先看一下UserAuth的具体用法:
- 关键点:
--视图处理类下定义名为permission_classes属性,属性值是一个列表或者元组
--写一个UserAuth(类名随便)认证的类,将类名添加到permission_classes列表中
--UserAuth认证类必须有一个has_permission(self,request,view)方法,这个方法下写用户认证逻辑,认证成功:返回true。认证失败:,返回false。
permission源码执行流程:
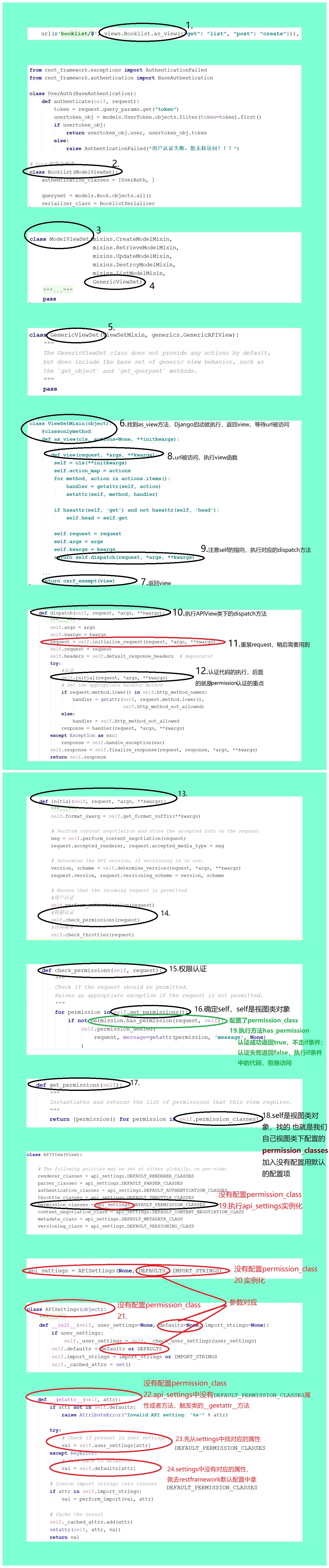
permission源码解析_副本.jpg
- app001-utils-permission_class.py
from rest_framework.permissions import BasePermission
class SVIPPermission(BasePermission):
message="您没有访问权限!"
def has_permission(self,request,view):
if request.user.user_type >= 2:
return True
return False
- view.py
from app001 import models
from app001.serializers.bookserializer import BooklistSerializer
# 重装了APIView
from rest_framework.viewsets import ModelViewSet
from app001.utils.permission_class import SVIPPermission
# book视图处理类
class Booklist(ModelViewSet):
permission_classes = [SVIPPermission,]
queryset = models.Book.objects.all()
serializer_class = BooklistSerializer
四、基于RestFramework的认证组件做视图处理类的访问频率限制
1、访问频率限制和认证、权限的执行流程一样,都是restframework源码提供的一种书写格式,再此就不一一赘述。
- app001-utils-throttle_classes.py
import time
from rest_framework.throttling import BaseThrottle
VISIT_RECORD = {}
class VisitThrottle(BaseThrottle):
def __init__(self):
self.history = None
def allow_request(self, request, view):
# 1. 拿到用户请求的IP
# print(request.META)
ip = request.META.get("REMOTE_ADDR")
# 2. 当前请求的时间
now = time.time()
# 3. 记录访问的历史
if ip not in VISIT_RECORD:
VISIT_RECORD[ip] = []
history = VISIT_RECORD[ip]
self.history = history
# [11:07:20, 10:07:11, 10:07:06, 10:07:01]
while history and now - history[-1] > 60:
history.pop()
# 判断用户在一分钟的时间间隔内是否访问超过3次
if len(history) >= 3:
return False
history.insert(0, now)
return True
def wait(self):
# 当前访问时间
ctime = time.time()
# 访问时间历史记录 self.history
return 60 - (ctime - self.history[-1])
- view.py
from app001 import models
from app001.serializers.bookserializer import BooklistSerializer
# 重装了APIView
from rest_framework.viewsets import ModelViewSet
from app001.utils.throttle_classes import VisitThrottle
# book视图处理类
class Booklist(ModelViewSet):
throttle_classes = [VisitThrottle, ]
queryset = models.Book.objects.all()
serializer_class = BooklistSerializer
2、基于RestFramework给我们提供了几种频率控制组件,省去了我们在自己写了
- SimpleRateThrottle类,A simple cache implementation, that only requires
.get_cache_key()
to be overridden. - AnonRateThrottle类,Limits the rate of API calls that may be made by a anonymous users.
- UserRateThrottle类,Limits the rate of API calls that may be made by a given user.
- ScopedRateThrottle类,Limits the rate of API calls by different amounts for various parts of
the API.
app001-utils-throttle_classes.py
from rest_framework.throttling import SimpleRateThrottle
class VisitThrottle(SimpleRateThrottle):
scope="visit_rate"
def get_cache_key(self,request, view):
return self.get_ident(request)
settings.py
REST_FRAMEWORK = {
"DEFAULT_THROTTLE_CLASSES": ("app001.utils.throttle_classes.VisitThrottle",),
"DEFAULT_THROTTLE_RATES": {
"visit_rate": "10/m",//频率设置
},
}
view.py
from app001 import models
from app001.serializers.bookserializer import BooklistSerializer
# 重装了APIView
from rest_framework.viewsets import ModelViewSet
from app001.utils.throttle_classes import VisitThrottle
# book视图处理类
class Booklist(ModelViewSet):
throttle_classes = [VisitThrottle, ]
queryset = models.Book.objects.all()
serializer_class = BooklistSerializer
五、基于RestFramework的视图处理类的分页组件
Restframework提供了几种很好的分页方式:
- 基于页码的分页的 PageNumberPagination类
- 基于limit offset 做分页的 LimitOffsetPagination类
- 基于游标的分页的 CursorPagination类。但这种方式存在性能问题,如果用户吧page给改的很大,查询速度就会很慢。还有一种页码加密的方式
1、PageNumberPagination类的使用
- 方法一、视图类继承APIView时
-- 参考的API:GET请求:http://127.0.0.1:8000/booklist/?page=2
from rest_framework.views import APIView
from app001 import models
# rest_framework重装的response
from rest_framework.response import Response
from app001.serializers.bookserializer import BooklistSerializer
from rest_framework.pagination import PageNumberPagination
class Booklist(APIView):
def get(self, request):
class MyPageNumberPagination(PageNumberPagination):
page_ size = 2 //指定的每页显示数
page_query_param = "page" //url栏的页码参数
page_size_query_param = "size" //获取url参数中设置的每页显示数据条数
max_page_size = 5 //最大支持的每页显示的数据条数
book_obj = models.Book.objects.all()
# 实例化
pnp = MyPageNumberPagination()
# 分页
paged_book_list = pnp.paginate_queryset(book_obj, request)
bs = BooklistSerializer(paged_book_list, many=True)
data = bs.data # 序列化接口
return Response(data)
- 方式二、视图类继承ModelViewSet时(少用)
from rest_framework.viewsets import ModelViewSet
from rest_framework.pagination import PageNumberPagination
class MyPageNumberPagination(PageNumberPagination):
page_size = 3
# book视图处理
class Booklist(ModelViewSet):
pagination_class = MyPageNumberPagination
queryset = models.Book.objects.all()
serializer_class = BooklistSerializer
2、LimitOffsetPagination类的使用
- 这种分页样式反映了查找多个数据库记录时使用的语法。客户端包含 “limit” 和 “offset” 查询参数。limit 表示要返回的 数据 的最大数量,并且等同于其他样式中的 page_size。offset 指定查询的起始位置与完整的未分类 数据 集的关系。多用于返回的内容是静态的,或者不用实时返回数据最新的变化。Google Search 和一些论坛用了这种方式:
- 参考API:
GET请求:http://127.0.0.1:8000/booklist/?limit=3&offset=3Response响应:{ "count": 7,"next": "http://127.0.0.1:8000/booklist/?limit=3&offset=6", "previous": "http://127.0.0.1:8000/booklist/?limit=3","results": [...]
from app001 import models
from app001.serializers.bookserializer import BooklistSerializer
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework.pagination import LimitOffsetPagination
class MyPageNumberPagination(LimitOffsetPagination):
max_limit = 3 # 最大限制默认是None
default_limit = 2 # 设置每一页显示多少条
limit_query_param = 'limit' # 往后取几条
offset_query_param = 'offset' # 当前所在的位置
class Booklist(APIView):
def get(self, request):
book_obj = models.Book.objects.all()
# 实例化
pnp = MyPageNumberPagination()
# 分页
paged_book_list = pnp.paginate_queryset(book_obj, request)
bs = BooklistSerializer(paged_book_list, many=True)
data = bs.data # 序列化接口
# return Response(data) #不含上一页下一页
return pnp.get_paginated_response(data)
- LimitOffsetPagination 类包含一些可以被覆盖以修改分页样式的属性。要设置这些属性,应该继承 LimitOffsetPagination 类,然后像上面那样启用你的自定义分页类。
default_limit- 一个数字值,指定客户端在查询参数中未提供的 limit 。默认值与 PAGE_SIZE setting key 相同。
limit_query_param - 一个字符串值,指示 “limit” 查询参数的名称。默认为 'limit'。
offset_query_param - 一个字符串值,指示 “offset” 查询参数的名称。默认为 'offset'。
max_limit - 一个数字值,表示客户端可以要求的最大允许 limit。默认为 None。
- 了解LIMIT / OFFSET的实际工作原理。为此,我们举例说明,假如有大约1000个符合要求的结果。你若要前100数据,这很容易,这意味着它只返回与结果集匹配的前100行。但是现在想要900-1000之间的数据。数据库现在必须遍历前900个结果才能开始返回(因为它没有指针告诉它如何获得结果900)。总之,LIMIT / OFFSET在大型结果集上非常慢。
3、CursorPagination类的使用
- 现在很多场景,查询结果在用户浏览过程中是变化的,例如微博时间线,用户看的时候,可能后一页的某些微博会被删除,而前一页又增添了新的微博。这种情况就不适合用 limitoffset分页方式了。Facebook 和 Twitter 都采用了基于游标的分页方法。
- 这种方式有以下两个特点:
-- 1. 查询的结果流可能是动态变化的,例如: 时间线里出现了新的数据,或者删除了数据,这些变化都可以在 “前一页” 或者 “后一页” 上体现出来。
-- 2. Cursor 体现了排序,是持久化的。一般情况下 Cursor 的顺序是和时间有关。如果你的实体(例如:微博)可能展现给用户多种可能的排序(例如:创建时间或者修改时间),那么则需要创建不同的 Cursor。
具体实现时,Cursor 可能分别创建自 创建用户 或者 修改用户 字段。Facebook Relay 用了查询名称 + 时间戳 的 Base64 形式来做 Cursor。 - CursorPagination 类包含一些可以被覆盖以修改分页样式的属性。
要设置这些属性,你应该继承 CursorPagination 类,然后像上面那样启用你的自定义分页类。
-- page_size = 指定页面大小的数字值。如果设置,则会覆盖 PAGE_SIZE 设置。默认值与 PAGE_SIZE setting key 相同。
-- cursor_query_param = 一个字符串值,指定 “游标” 查询参数的名称。默认为 'cursor'.
-- ordering = 这应该是一个字符串或字符串列表,指定将应用基于游标的分页的字段。例如: ordering = 'slug'。默认为 -created。该值也可以通过在视图上使用 OrderingFilter 来覆盖。
-关于限制偏移量和游标分页的分析 请参考:http://cra.mr/2011/03/08/building-cursors-for-the-disqus-api
六、基于RestFramework的视图处理类响应器
- restframework可以根据url的不同来源做出不同的响应,比如说,当来自浏览器端的请求,会返回一个页面,当请求来自于postman等请求软件时,返回的是json数据,这样的效果是restframework的响应器在控制,settings中可以按需配置:
REST_FRAMEWORK={
'DEFAULT_RENDERER_CLASSES': (
'rest_framework.renderers.JSONRenderer', //响应json
'rest_framework.renderers.BrowsableAPIRenderer', //响应页面
),
}
七、基于RestFramework的视图处理类的url注册器
url注册器只是适用于视图类继承ModelViewSet类的写法:
url注册器会生成四条url:^ ^booklist/$ [name='book-list']^ ^booklist\.(?P<format>[a-z0-9]+)/?$ [name='book-list'] //可以指定数据类型^ ^booklist/(?P<pk>[^/.]+)/$ [name='book-detail']^ ^booklist/(?P<pk>[^/.]+)\.(?P<format>[a-z0-9]+)/?$ [name='book-detail'] //可以指定单个数据数据类型
urls.py
from rest_framework import routers
router = routers.DefaultRouter() //实例化
router.register("booklist", views.Booklist) //注册
urlpatterns = [
url(r'^', include(router.urls)),
]
view.py
from app001 import models
from app001.serializers.bookserializer import BooklistSerializer
# 重装了APIView
from rest_framework.viewsets import ModelViewSet
# book视图处理类
class Booklist(ModelViewSet):
queryset = models.Book.objects.all()
serializer_class = BooklistSerializer

