引言
【图1】ORACLE RAC架构
OceanBase的负载均衡是通过调整内部数据分区(Partition)的分布来间接改变各个OBServer节点的被请求量,从而改变各个节点的负载。在调整过程中的数据迁移是内部异步进行,不依赖外部同步工具,不需要DBA介入。期间高可用机制一直生效,对业务读写的影响可以控制。
随着互联网业务的普及,海量数据的存储和访问成了应用架构设计常见的问题。业务高峰期,应用几百万几千万的请求落在数据库上时,数据库如何保持稳定和扩展性?通过数据拆分,加上负载均衡设计是首选方法。本文总结了关系数据库在负载均衡方面的架构经验,进而介绍OceanBase分布式数据库的负载均衡的独特魅力。
负载均衡的传统理解
负载均衡是一种设计,原理是用一个统一的中心入口收敛所有请求,然后依据一定的算法将请求分发到后端多个节点处理。节点处理后的结果可以直接返回给客户端或者返回给负载均衡中心,再返回给客户端。
根据这个原理,负载均衡设计可以工作在OSI七层模型的二层(数据链路层MAC)、三层(网络层IP)、四层(传输层TCP)和七层(应用层)。越往上,原理越复杂,设计越智能,越灵活。
市场上负载均衡产品有两类。一类是硬件实现:有独立的硬件如F5,也有集成在网络设备上的。另一类是软件,安装在中心服务器上。如 LVS,HAProxy,Keepalive, DNS LoadBalance等。软件方案优点是配置简单,操作灵活,成本低廉;缺点是依赖系统,有额外资源开销,安全性和稳定性不是很高。硬件方案优点是独立于系统,性能好,策略多;缺点是价格昂贵。
请求转发算法有多种,如轮询(Round Robin,RR)、按权重轮询(Weighted Round Robin)、随机、权重随机、按响应时间、最少连接数、DNS均衡等,可以根据实际场景选择。
请求能够转发到后端任一节点,就表示后端节点都是无状态的集群,是分布式的。所以负载均衡一定是用在分布式集群架构里的。
集中式关系数据库的负载均衡设计
1.集群数据库
商业关系数据库的架构早期都是集中式的,只有主备架构应对高可用和容灾。后来为了应对性能增长,发展出集群数据库。集群数据库的架构是将实例和数据文件分离,数据文件放在一个共享存储上,实例节点水平扩展为多个,彼此共享同一份数据文件。
实例节点是分布式的,在每个实例节点上,配置一个数据库监听服务监听多个VIP(本地的和远程的),监听服务彼此也是一个小集群,会根据各个实例节点负载信息决定将请求转发到何处。当新增实例节点时,会对各个实例节点的请求重新做负载均衡,平衡压力。
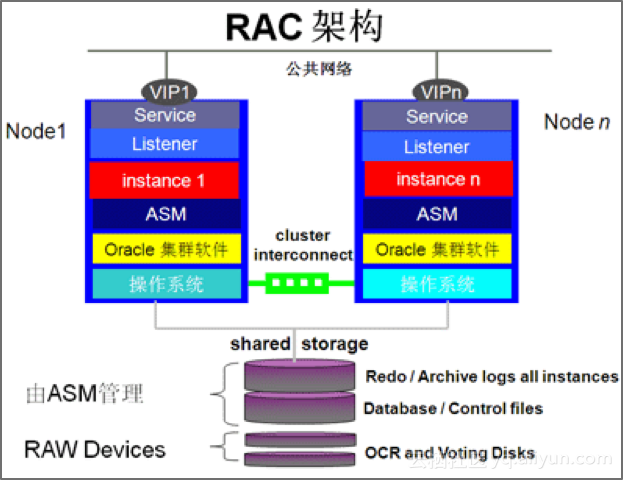
【图1】ORACLE RAC架构
集群数据库的问题也是很明显的,就是数据存储不是分布式的。一旦共享存储发生故障,整个数据库集群都不可用。所以这个分布式架构并不完美。
2.分布式数据库中间件
随着中间件技术的发展,出现了一类分布式MySQL集群。其原理是将数据水平拆分到多个MySQL实例里,然后在MySQL前端部署一组中间件集群负责响应客户端SQL请求。这个中间件具备解析SQL,路由和数据汇聚计算等逻辑,是分布式的,无状态的。在中间件前端会通过一个负载均衡产品(如SLB或LVS等类似产品)接受客户端请求并分发到各个中间件节点上。
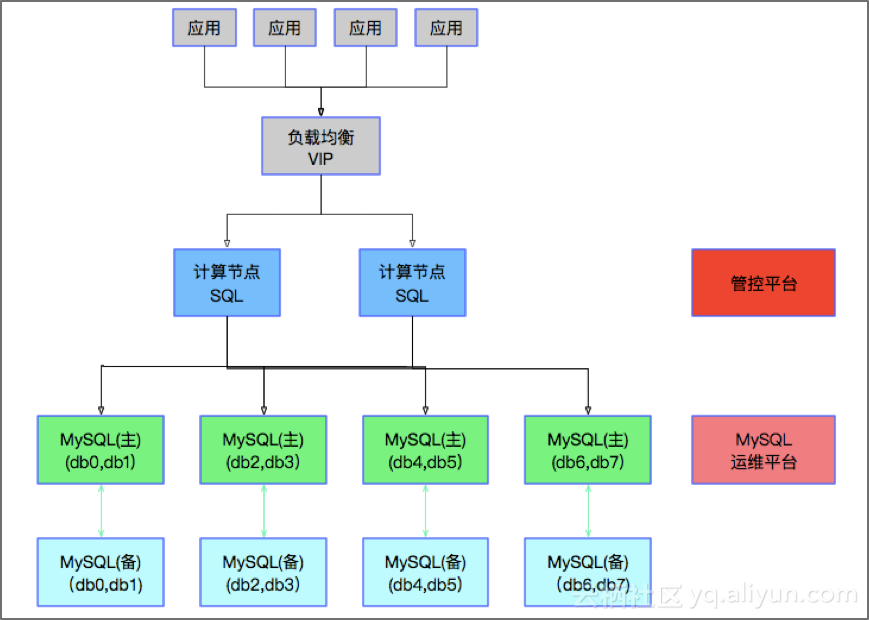
【图2】分布式数据库中间件架构
这个是通过分布式数据库中间件去弥补传统集中式数据库的分布式缺陷。它将计算节点做到分布式,可以水平扩展;同时将数据也水平拆分到多个存储上,也实现了分布式。相比集群数据库架构,分布式数据库中间件能提供更高的性能,更好的扩展性,同时成本也更低。
这个分布式架构下,计算节点因为是无状态的,扩展很容易。数据节点就没那么容易。因为涉及到数据的重分布,需要新增实例,以及做数据迁移和拆分动作。这些必须借助数据库外部的工具实现。这种分布式依然不是最完美的。因为它的数据存储是静止的。
分布式数据库的负载均衡设计
Google发布了关于Spanner&F1产品架构和运维的论文,引领了NewSQL技术的发展,具体就是分布式数据库技术。这个是真正的分布式数据库架构。在这种架构下,数据是分片存储在多个节点,并且可以在多个节点之间不借助外部工具自由迁移。
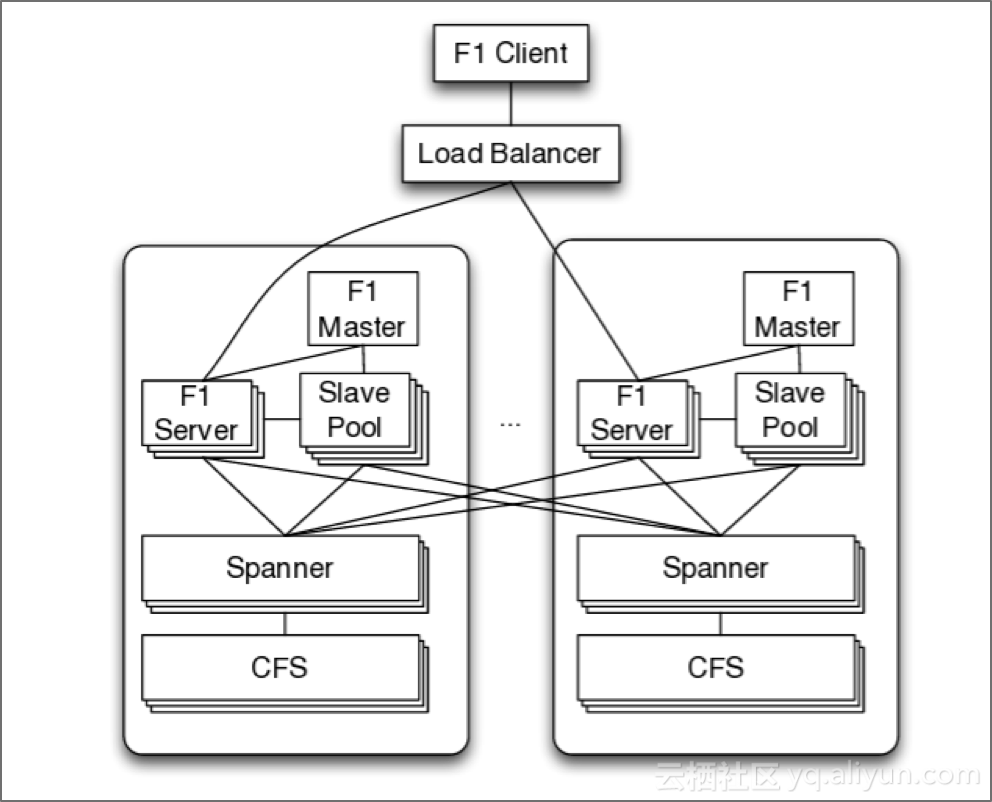
【图3】Google F1架构
Google的F1节点是无状态的,客户端请求经负载均衡再到一个F1节点 ,F1不存储数据,向Spanner请求数据。F1如果加机器就自动做分片的负载均衡。Google描述的分布式数据库的负载均衡逻辑应该就是分布式数据库架构的设计目标。
2010年,阿里巴巴和蚂蚁金服开始自主研发分布式关系数据库OceanBase。单就负载均衡的设计而言,OceanBase不仅实现了增加减少节点后节点间自动负载均衡,自动做数据存储重分布,还进一步支持多种业务场景下负载均衡需求。
OceanBase 2.0的负载均衡设计
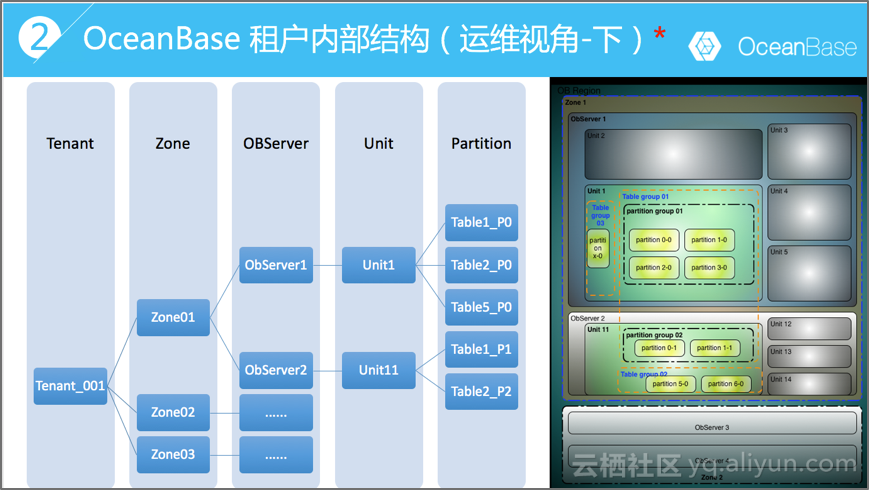
1.OceanBase 架构
在看OceanBase的负载均衡设计之前,先看看OceanBase 1.0版本的架构。在1.x版本里,一个observer进程囊括了计算和存储两项功能。每个节点之间地位都是平等的(有总控服务rootservice的三个节点稍有特殊),每个zone里每个节点的数据都是全部数据的一部分,每份数据在其他几个zone里也存在,通常至少有三份。所以从架构图上看OceanBase的计算和存储都是分布式的。跟Google的区别是1.x版本里,计算和存储还没有分离。但不影响作为分布式数据库的功能。
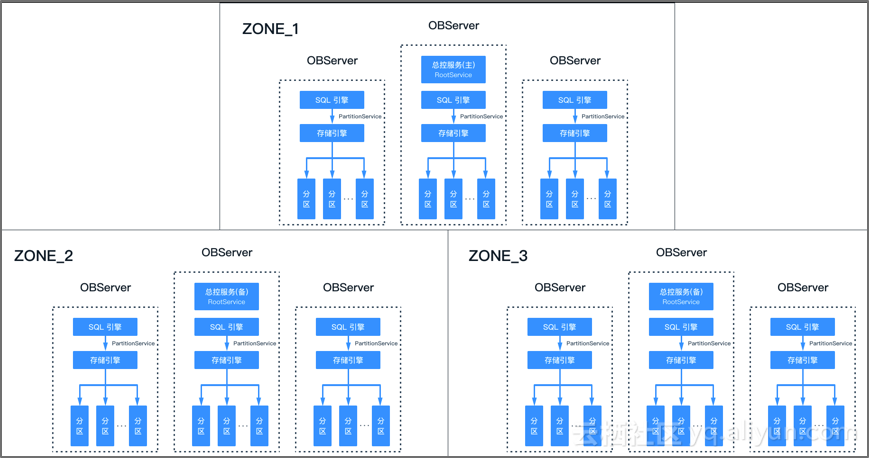
【图4】OceanBase 1.x 架构
2. 分区、副本和OBProxy
OceanBase的数据分布的最小粒度是分区(Partition),分区就是分区表的一个分区或者二级分区,或者非分区表本身就是一个分区。OceanBase的负载均衡的原理就跟分区有关。每个分区(Partition)在整个集群里数据会至少有三份,即通常说的三副本(Replica)。三副本角色为1个leader副本2个follower副本。通常默认读写的是leader副本。leader副本的默认分布在哪个机房(zone),受表的默认primary zone属性和locality属性影响。在异地多活架构里,充分发挥了这个locality属性的作用。
由于Leader副本分布位置是OceanBase内部信息,对客户端是透明的,所以需要一个反向代理OBProxy给客户端请求用。这个OBProxy只有路由的功能,它只会把sql请求发到一个表的leader副本所在的节点。跟HAProxy不同,它没有负载均衡功能,也不需要。不过OBProxy是无状态的,可以部署多个,然后在前面再加一个负载均衡产品,用于OBProxy自身的负载均衡和高可用。
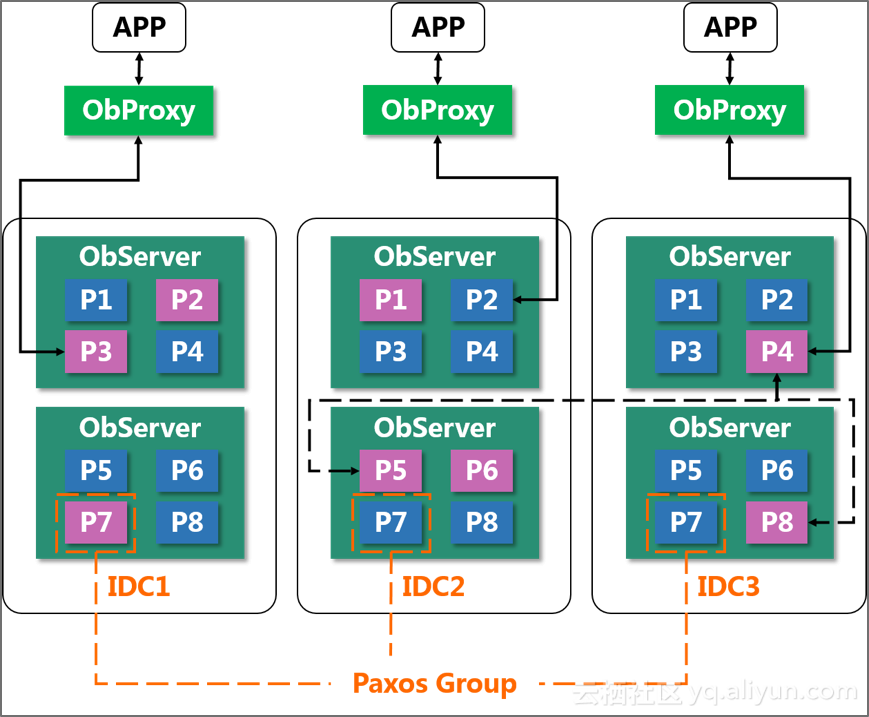
【图5】OceanBase分区、OBProxy
3. 负载均衡的衡量标准
OceanBase的各个节点(OBServer)的地位都是平等的(总控服务rootservice所在的节点作用稍微特殊一些),当前版本每个OBServer还是集计算与存储能力于一个进程中(2.x后期版本会发布计算与存储分离)。OceanBase会维持每个节点的资源利用率和负载尽可能的均衡。这个效果就是当一个大的OceanBase集群里,有若干个资源规格大小不等的租户运行时,OceanBase会避免某些节点资源利用率很高而某些节点上却没有访问或者资源利用率很低等。这个衡量标准比较复杂,还在不断探索完善中。所以目前没有确定的直白的公式可以直接描述。但可以介绍一下会跟下列因素有关:
-
空间:每个节点上Partition总的使用空间以及占用其配额的比例;每个租户的Unit在该节点上的总空间以及占用其配额的比例
-
内存:每个节点的OB的内存里已分配的内存以及占用其配额的比例
-
CPU:每个节点里的Unit的已分配的CPU总额以及占用其总配额的比例
-
其他:最大连接数、IOPS等。目前定义了这些规格,但还没有用于均衡策略
-
分区组个数(PartitionGroup):每个节点里的分区组个数。同一个表分组的同号分区是一个分区组。如A表和B表都是分区表,分区方法一样,则它们的0号分区是一个分区组,1号分区是一个分区组。如此类推。
4.负载均衡逻辑演进
OceanBase负载均衡的原理就是通过内部调整各个observer节点里的leader副本数量来间接改变各个节点的请求量,从而改变节点里某些用于负载均衡衡量标准的值。调整过程中的数据迁移是内部自动做的,不依赖外部工具,不需要DBA介入,对业务影响可以控制。
在分布式下,跨节点请求延时对性能会有损耗。尤其是当集群是跨多个机房部署的时候。所以,不受控制的负载均衡对业务来说并不是好事。在业务层面,有些表之间是有业务联系的,在读取的时候,相应的Partition最好是在一个节点内部。此外,加上OceanBase的架构还支持多租户特性。不同租户下的数据存储是会在一个或多个Unit里分配。Partition并不是毫无规则的自由分布。对业务来说,能对负载均衡策略进行控制是很有意义的。它方便了应用整体架构设计时能保持上层应用流量分发规则和底层数据拆分规则保持一致,这是做异地多活的前提,同时也定义了负载均衡能力的边界。
所以,Partition的分布实际还受几点规则限制。第一,每个租户下的所有Partition都在一组或多组Unit里。Partition的迁移不能跳出Unit的范围。一个OceanBase集群里有很多租户,也就有很多Unit。OceanBase首先会调整Unit在节点间的分布。这个称为“Unit均衡”。只是Unit的迁移具体过程还是逐个Partition进行迁移。第二,同一个分区组的分区必须在同一个节点里。分区的迁移的终态是同一个PartitionGroup的Partition必须在同一个OBServer节点里。