之前写了关于人工智能和机器学习的理论基础文章,今天就理论联系实际,用机器学习算法跑个分。
机器学习最重要的就是数据,Kaggle平台提供了大量数据为机器学习的学习者和研究者提供一个跑分的平台。注册账号登录之后就可以进入比赛了,初学者可以从Digit Recognizer入手,也就是识别手工书写的数字。
作为一个菜鸟,我目前最好的成绩是识别率97.228 排名第1189位。
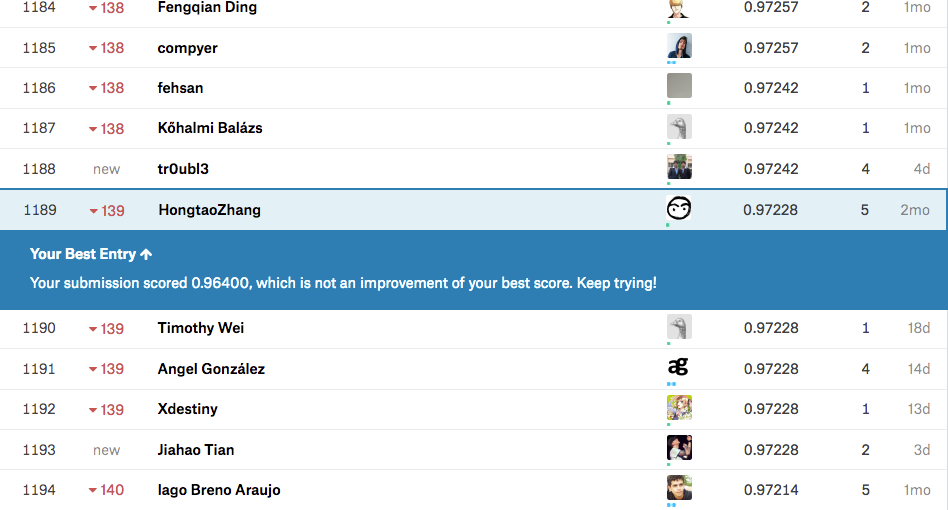
这个成绩是我用支撑向量(SVM)算法获得的,所以今天就来介绍如何用SVM来实现识别手写数字。
一、下载处理数据
首先导入需要用到的python库文件, pandas 和 sklearn 是机器学习非常重要的库文件。
import pandas as pd
import matplotlib.pyplot as plt, matplotlib.image as mpimg
from sklearn.model_selection import train_test_split
from sklearn import svm
%matplotlib inline
数据文件是csv格式的所以需要用panda 库来处理
labeled_images = pd.read_csv('train.csv')
images = labeled_images.iloc[:,1:]
labels = labeled_images.iloc[:,:1]
train_images, test_images,train_labels, test_labels = train_test_split(images, labels,
train_size=0.95, random_state=0)
train_test_split 函数是用来将数据成两组,训练组和验证组,其中训练组占95%。
每一张图片实际上是一个28 x 28 的黑白带灰阶的图片。
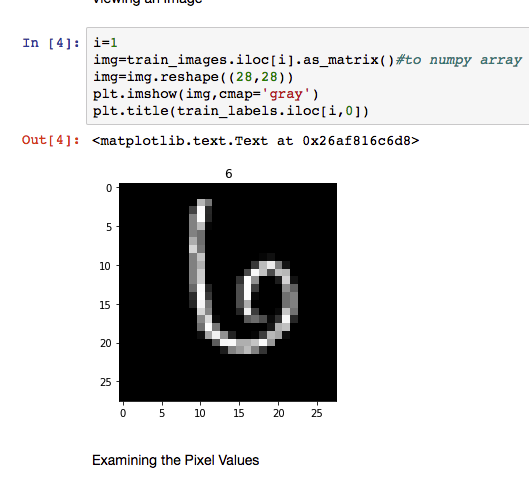
image.png
学习之前还需要将数据normalize, 这里用到了sklearn 中的 standardscaler 函数

image.png
二、用Sklearn的SVM学习数据
将normalize 后的数据送进分类器中,总共四行代码完成训练和评分,结果是0.977142的准确率
from sklearn.svm import SVC
clf = svm.SVC(kernel = "poly", degree = 3, coef0=0.1, C=100)
clf.fit(train_images_scaled, train_labels.values.ravel())
clf.score(test_images_scaled,test_labels)
三、用训练好的分类器来标记数据
导入未标记的测试数据,result 就是标记后的数据
test_data=pd.read_csv('test.csv')
test_data_scaled = scaler.transform(test_data)
results=clf.predict(test_data_scaled)
这就是我用SVM训练分类器,并用分类器标记数据,最后取得97%准确率的训练结果的所有代码,是不是很简单。
————
相关文章
AI学习笔记——循环神经网络(RNN)的基本概念
AI学习笔记——神经网络和深度学习
AI学习笔记——卷积神经网络1(CNN)
————
文章首发steemit.com 为了方便墙内阅读,搬运至此,欢迎留言或者访问我的Steemit主页
