人工神经网络
人工神经网络的概念
人工神经网络(Artificial Neural Networks,ANN)是对一组输入信号和一组输出信号之间的关系进行建模,使用的模型来源于人类大脑对来自感觉输入的刺激是如何反应的理解。通过调整内部大量节点(神经元)之间相互连接的权重,从而达到处理信息的目的。
从广义上讲,人工神经网络是可以应用于几乎所有的学习任务的多功能学习方法:分类、数值预测甚至无监督的模式识别。ANN最好应用于下列问题:输入数据和输出数据相对简单,而输入到输出的过程相对复杂。作为一种黑箱方法,对于这些类型的黑箱问题,它运行的很好。
人工神经网络的构成与分类
常见的人工神经网就是这种三层人工神经网络模型,如果没有隐含层,那就是两层人工神经网络;如果有多层隐含层那就是多层人工神经网络。
小圆圈就是节点,相当于人脑的神经元。节点之间的线称之为边,边表示节点之间存在关联性,关联性的大小由权重表示。
输入层就是我们的输入变量X,通常一个变量X是一个节点,有多少X就有多少个节点。
隐含层对输入变量X进行转化计算,层数和节点个数自行制定,通常只要一层,个数视情况而定。
输出层是我们的输出变量Y,对于回归问题和二分类变量问题,就有一个节点,多分类问题就存在多个节点。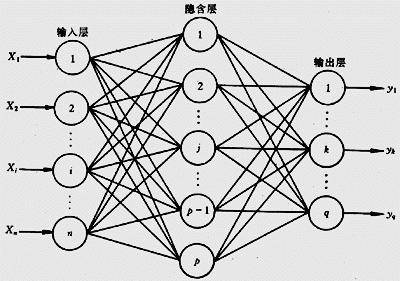 基本构造
基本构造
信息传播的方向
第一种神经网络,如上例所示,箭头用来指示信号只在一个方向上传播。如果网络中的输入信号在一个方向上传送,直达输出层,那么这样的网络成为前馈网络(feedforward network)。这是我们主要使用的B-P神经网络模型就是典型的前馈式神经网络模型。另外,由于层数和每一层的节点数都可以改变,多个结果可以同时进行建模,或者可以应用多个隐藏层(这种做法有时称为深度学习 (deep learning)
第二种是反馈式神经网络,这种神经网络的特点是层间节点的连接是双向的,上层节点向下连接下层节点,下层节点也可以向上连接上层节点。这种神经网络更为复杂,很少使用。
每一层的节点数
除了层数和信息传播方向变化外,每一层的节点数同样可以改变。输入节点的个数由输入数据的特征确定,输出节点的个数由需要建模的结果决定。然而隐藏层的节点个数并没有可信的规则来确定。一般情况下,合适的数目取决于输入节点的个数、训练数据的数量等。
简单实例
今天,主要使用人工神经网络的进行建模分析,涉及的R包是neuralnet和nnet两个包,函数名和包名是一样的。
nnet
formula:公式的形式class ~ x1 + x2 + ..... x,y :矩阵或者数据框
weights:权重
size:隐含层节点个数
range:初始化随机权值
decay:经元输入权重的一个修正参数,表明权重是递减的(可以防止过拟合;
maxit:最大反馈迭代次数;
skip:是否允许跳过隐含层
trace:支出是否要最优化
- 代码
library(nnet)
data("iris")
model.nnet <- nnet(Species ~. , data = iris,linout = F, size = 10 ,
decay = 0.01,maxit= 1000, trace = F)
pre.forest <- predict(model.nnet, iris, type = "class")
table(pre.forest,iris$Species)
- Results:
| pre.forest | setosa | versicolor | virginica |
|---|---|---|---|
| setosa | 50 | 0 | 0 |
| versicolor | 0 | 49 | 0 |
| virginica | 0 | 1 | 50 |
neuralnet
数据来源:https://archive.ics.uci.edu/ml/machine-learning-databases/concrete/compressive/
该数据集包含了1030个混凝土案例,8个描述成分的特征。这些特征被认为与最终的抗压强度相关。
> setwd("I:\\Rwork\\concrete")
> list.files()
[1] "Concrete_Data.csv" "Concrete_Data.xls"
> concrete <- read.csv("Concrete_Data.csv", header = T)
> str(concrete)
'data.frame': 1030 obs. of 9 variables:
$ Cement..component.1..kg.in.a.m.3.mixture. : num 540 540 332 332 199 ...
$ Blast.Furnace.Slag..component.2..kg.in.a.m.3.mixture.: num 0 0 142 142 132 ...
$ Fly.Ash..component.3..kg.in.a.m.3.mixture. : num 0 0 0 0 0 0 0 0 0 0 ...
$ Water...component.4..kg.in.a.m.3.mixture. : num 162 162 228 228 192 228 228 228 228 228 ...
$ Superplasticizer..component.5..kg.in.a.m.3.mixture. : num 2.5 2.5 0 0 0 0 0 0 0 0 ...
$ Coarse.Aggregate...component.6..kg.in.a.m.3.mixture. : num 1040 1055 932 932 978 ...
$ Fine.Aggregate..component.7..kg.in.a.m.3.mixture. : num 676 676 594 594 826 ...
$ Age..day. : num 28 28 270 365 360 90 365 28 28 28 ...
$ Concrete.compressive.strength.MPa..megapascals.. : num 80 61.9 40.3 41 44.3 ...
数据整形:由于神经网络的运行最好是输入数据缩放到0附近的狭窄范围内,但是目前发现数据数值从0到1000多。
通常解决这个问题的方法是规范化或者标准化函数来重新调整数据。如果数据不服从正态分布,可以将其标准化到一个0到1的范围。
normalize <- function(x) {
return ((x - min(x)) / (max(x) - min(x)))}
concrete.norm <- as.data.frame(lapply(concrete, normalize))
训练模型之前应用于数据的任何变换,之后需要应用反变换。
- 训练数据模型
summary(concrete.norm)
library(neuralnet)
concrete.train <- concrete.norm[1:773,]
concrete.test <- concrete.norm[774:1030,]
concrete_model <- neuralnet(strength ~ cement + slag + ash + water +superplastic +
coarseagg +fineagg + age,
data = concrete.train)
plot(concrete_model)
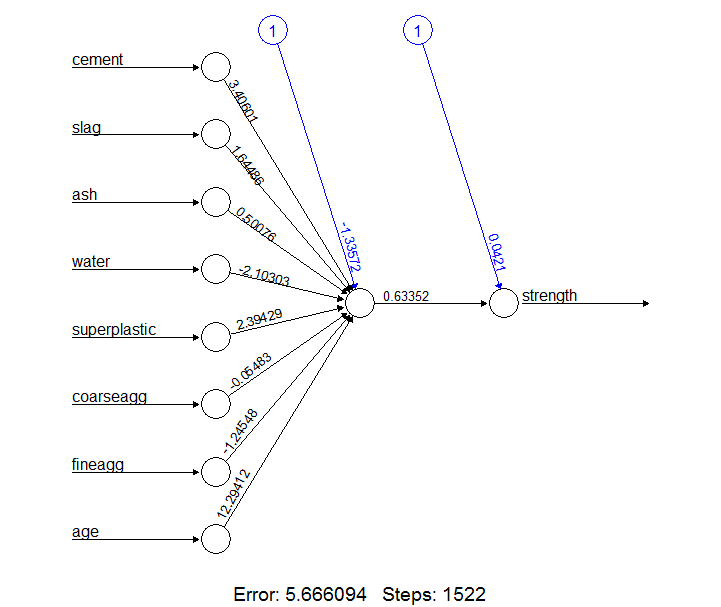
在这个简单模型中,对于8个特征中的每一个特征都有一个输入节点,后面跟着一个单一的隐藏节点和一个单一的输出节点。每一个连接的权重也都被描绘出来,偏差想也被描绘出来(通过带有1的节点表示)。另外还有训练步数和误差平方和(SSE)。
- 评估模型性能
model.result <- compute(concrete_model, concrete.test[1:8])
predicted_strength <- model.result$net.result
cor(predicted_strength, concrete.test$strength)
0.7276065811
compute函数的运行原理与我们已经使用至今的predict()函数有些不同。$neurons代表网络中每一层的神经元;$net.result代表存储预测值,通过cor函数评估两者之间的线性相关。
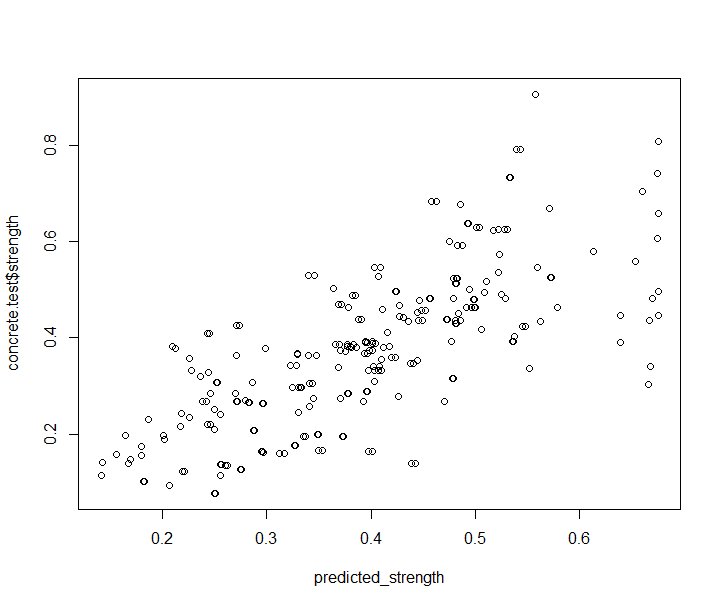
- 提高模型的性能
尝试通过增加隐藏节点数,评估模型性能
| hidden | error | steps | cor |
|---|---|---|---|
| 1 | 5.66 | 1993 | 0.72 |
| 2 | 2.57 | 2228 | 0.75 |
| 3 | 2.58 | 2328 | 0.78 |
| 4 | 1.82 | 55012 | 0.76 |
| 5 | 1.42 | 34287 | 0.65 |