
前言
今天继续APP爬虫,今天爬取的是微博榜单(24小时榜)的数据,采集的字段有:
- 用户id
- 用户地区
- 用户性别
- 用户粉丝
- 微博内容
- 发布时间
- 转发、评论和点赞量
该文分以下内容:
- 爬虫代码
- 用户分析
- 微博分析
爬虫代码
import requests
import json
import re
import time
import csv
headers = {
'Host': 'api.weibo.cn',
'Connection': 'keep-alive',
'User-Agent': 'Weibo/29278 (iPhone; iOS 11.4.1; Scale/2.00)'
}
f = open('1.csv','w+',encoding='utf-8',newline='')
writer = csv.writer(f)
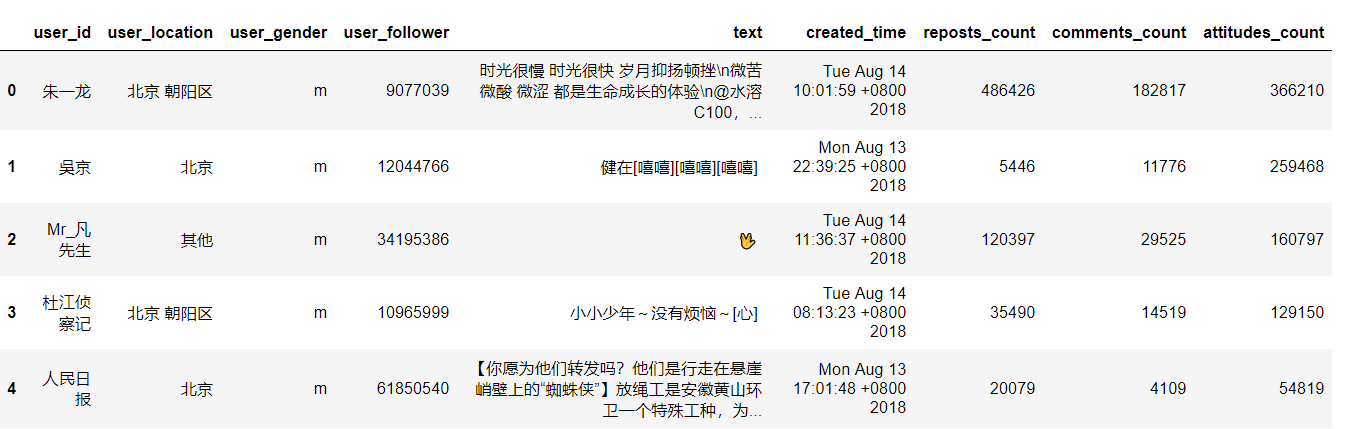
writer.writerow(['user_id','user_location','user_gender','user_follower','text','created_time','reposts_count','comments_count','attitudes_count'])
def get_info(url):
res = requests.get(url,headers=headers)
print(url)
datas = re.findall('"mblog":(.*?),"weibo_position"',res.text,re.S)
for data in datas:
json_data = json.loads(data+'}')
user_id = json_data['user']['name']
user_location = json_data['user']['location']
user_gender = json_data['user']['gender']
user_follower = json_data['user']['followers_count']
text = json_data['text']
created_time = json_data['created_at']
reposts_count = json_data['reposts_count']
comments_count = json_data['comments_count']
attitudes_count = json_data['attitudes_count']
print(user_id,user_location,user_gender,user_follower,text,created_time,reposts_count,comments_count,attitudes_count)
writer.writerow([user_id,user_location,user_gender,user_follower,text,created_time,reposts_count,comments_count,attitudes_count])
time.sleep(5)
if __name__ == '__main__':
urls = ['https://api.weibo.cn/2/cardlist?gsid=_2A252dh7LDeRxGeNM41oV-S_MzDSIHXVTIhUDrDV6PUJbkdANLVTwkWpNSf8_0j6hqTyDS0clYi-pzwDc2Kd8oj_d&wm=3333_2001&i=b9f7194&b=0&from=1088193010&c=iphone&networktype=wifi&v_p=63&skin=default&v_f=1&s=ef8eeeee&lang=zh_CN&sflag=1&ua=iPhone8,1__weibo__8.8.1__iphone__os11.4.1&ft=11&aid=01AuxGxLabPA7Vzz8ZXBUpkeJqWbJ1woycR3lFBdLhoxgQC1I.&moduleID=pagecard&scenes=0&uicode=10000327&luicode=10000010&count=20&extparam=discover&containerid=102803_ctg1_8999_-_ctg1_8999_home&fid=102803_ctg1_8999_-_ctg1_8999_home&lfid=231091&page={}'.format(str(i)) for i in range(1,16)]
for url in urls:
get_info(url)
用户分析
首先对部分用户id进行可视化,字体大一点的是上榜2次的(这次统计中最多上榜的是2次)。

接着对地区进行数据处理,进行统计。可以看出,位于北京的用户是最多的(大V都在北京)。
df['location'] = df['user_location'].str.split(' ').str[0]

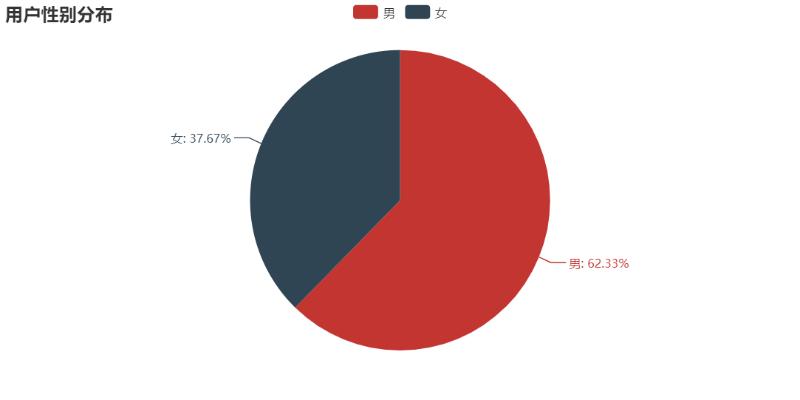
接下来看下用户的性别比例:男性用户占多。
最后再看看上榜大V粉丝前十:

微博分析
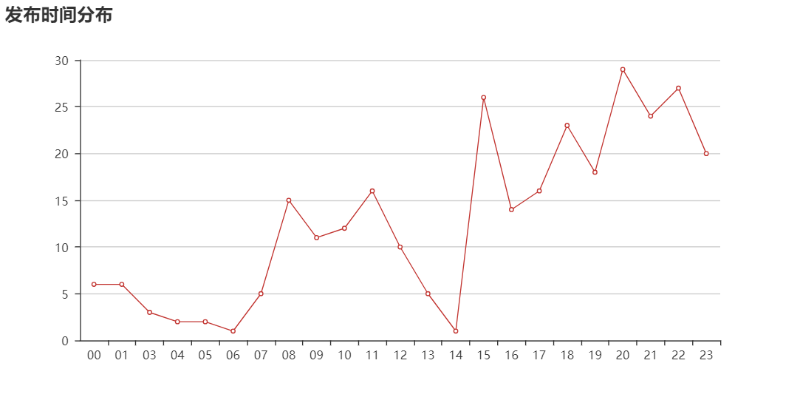
首先,对时间数据进行处理,取出小时时间段。
接着,我们看看微博点赞前十的用户。
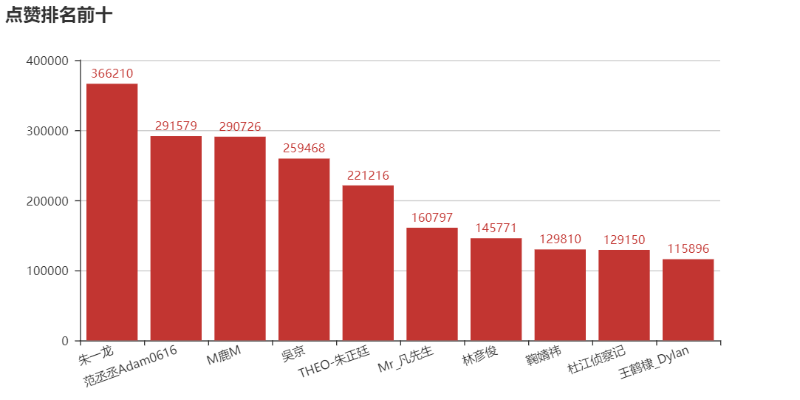
最后,绘制微博文章词云图。



