序言
第1章 Scrapy介绍
第2章 理解HTML和XPath
第3章 爬虫基础
第4章 从Scrapy到移动应用
第5章 快速构建爬虫
第6章 Scrapinghub部署
第7章 配置和管理
第8章 Scrapy编程
第9章 使用Pipeline
第10章 理解Scrapy的性能
第11章(完) Scrapyd分布式抓取和实时分析
在上一章,我们学习了如何辨析Scrapy中间件。在本章中,我们通过实例学习编写pipelines,包括使用REST APIs、连接数据库、处理CPU密集型任务、与老技术结合。
我们在本章中会使用集中新的数据库,列在下图的右边:
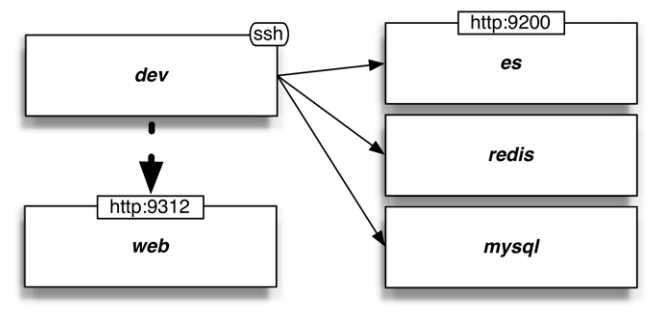
Vagrant已经配置好了数据库,我们可以从开发机向其发送ping,例如ping es或ping mysql。让我们先来学习REST APIs。
使用REST APIs
REST是用来一套创建网络服务的技术集合。它的主要优点是,比起SOAP和专有web服务,REST更简单和轻量。软件开发者注意到了web服务的CRUD(Create、Read、Update、Delete)和HTTP操作(GET、POST、PUT、DELETE)的相似性。它们还注意到传统web服务调用需要的信息可以再URL源进行压缩。例如,http://api.mysite.com/customer/john是一个URL源,它可以让我们分辨目标服务器,,更具体的,名字是john的服务器(行的主键)。它与其它技术结合时,比如安全认证、无状态服务、缓存、输出XML或JSON时,可以提供一个强大但简单的跨平台服务。REST席卷软件行业并不奇怪。
Scrapy pipeline的功能可以用REST API来做。接下来,我们来学习它。
使用treq
treq是一个Python包,它在Twisted应用中和Python的requests包相似。它可以让我们做出GET、POST、和其它HTTP请求。可以使用pip install treq安装,开发机中已经安装好了。
比起Scrapy的Request/crawler.engine.download() API,我们使用treq,因为后者具有性能优势,详见第10章。
一个写入Elasticsearch的pipeline
我们从一个向ES服务器(Elasticsearch)写入Items的爬虫开始。你可能觉得从ES开始,而不是MySQL,有点奇怪,但实际上ES是最容易的。ES可以是无模式的,意味着我们可以不用配置就使用它。treq也足以应付需要。如果想使用更高级的ES功能,我们应该使用txes2和其它Python/Twisted ES包。
有了Vagrant,我们已经有个一个运行的ES服务器。登录开发机,验证ES是否运行:
$ curl http://es:9200
{
"name" : "Living Brain",
"cluster_name" : "elasticsearch",
"version" : { ... },
"tagline" : "You Know, for Search"
}
在浏览器中登录http://localhost:9200也可以看到相同的结果。如果访问http://localhost:9200/properties/property/_search,我们可以看到一个响应,说ES已经进行了全局尝试,但是没有找到索引页。
笔记:在本章中,我们会在项集合中插入新的项,如果你想恢复原始状态的话,可以用下面的命令:
$ curl -XDELETE http://es:9200/properties
本章中的pipeline完整代码还有错误处理的功能,但我尽量让这里的代码简短,以突出重点。
提示:本章位于目录ch09,这个例子位于ch09/properties/properties/pipelines/es.py。
本质上,这个爬虫只有四行:
@defer.inlineCallbacks
def process_item(self, item, spider):
data = json.dumps(dict(item), ensure_ascii=False).encode("utf- 8")
yield treq.post(self.es_url, data)
前两行定义了一个标准process_item()方法,它可以产生延迟项。(参考第8章)
第三行准备了插入的data。ensure_ascii=False可使结果压缩,并且没有跳过非ASCII字符。我们然后将JSON字符串转化为JSON标准的默认编码UTF-8。
最后一行使用了treq的post()方法,模拟一个POST请求,将我们的文档插入ElasticSearch。es_url,例如http://es:9200/properties/property存在settings.py文件中(ES_PIPELINE_URL设置),它提供重要的信息,例如我们想要写入的ES的IP和端口(es:9200)、集合名(properties)和对象类型(property)。
为了是pipeline生效,我们要在settings.py中设置ITEM_PIPELINES,并启动ES_PIPELINE_URL设置:
ITEM_PIPELINES = {
'properties.pipelines.tidyup.TidyUp': 100,
'properties.pipelines.es.EsWriter': 800,
}
ES_PIPELINE_URL = 'http://es:9200/properties/property'
这么做完之后,我们前往相应的目录:
$ pwd
/root/book/ch09/properties
$ ls
properties scrapy.cfg
然后运行爬虫:
$ scrapy crawl easy -s CLOSESPIDER_ITEMCOUNT=90
...
INFO: Enabled item pipelines: EsWriter...
INFO: Closing spider (closespider_itemcount)...
'item_scraped_count': 106,
如果现在访问http://localhost:9200/properties/property/_search,除了前10条结果,我们可以在响应的hits/total字段看到插入的文件数。我们还可以添加参数?size=100以看到更多的结果。通过添加q= URL搜索中的参数,我们可以在全域或特定字段搜索关键词。相关性最强的结果会首先显示出来。例如,http://localhost:9200/properties/property/_search?q=title:london,可以让标题变为London。对于更复杂的查询,可以在https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-query-string-query.html查询ES文档。
ES不需要配置,因为它根据提供的第一个文件,进行模式(字段类型)自动检测的。通过访问http://localhost:9200/properties/,我们可以看到它自动检测的映射。
再次运行crawl easy -s CLOSESPIDER_ITEMCOUNT=1000。因为pipelines的平均时间从0.12变为0.15秒,平均延迟从0.78变为0.81秒。吞吐量仍保持每秒约25项。
笔记:用pipelines向数据库插入Items是个好方法吗?答案是否定的。通常来讲,数据库更简单的方法以大量插入数据,我们应该使用这些方法大量批次插入数据,或抓取完毕之后进行后处理。我们会在最后一章看到这些方法。然后,还是有很多人使用pipelines向数据库插入文件,相应的就要使用Twisted APIs。
pipeline使用Google Geocoding API进行地理编码
我们的房子有各自所在的区域,我们还想对它们进行地理编码,即找到相应的坐标(经度、纬度)。我们可以将坐标显示在地图上,或计算距离。建这样的数据库需要复杂的数据库、复杂的文本匹配,还有复杂的空间计算。使用Google Geocoding API,我们可以避免这些。在浏览器中打开它,或使用curl取回以下URL的数据:
$ curl "https://maps.googleapis.com/maps/api/geocode/json?sensor=false&ad
dress=london"
{
"results" : [
...
"formatted_address" : "London, UK",
"geometry" : {
...
"location" : {
"lat" : 51.5073509,
"lng" : -0.1277583
},
"location_type" : "APPROXIMATE",
...
],
"status" : "OK"
}
我们看到一个JSON对象,如果搜索一个location,我们可以快速获取伦敦中心的坐标。如果继续搜索,我们可以看到相同文件中海油其它地点。第一个是相关度最高的。因此如果存在results[0].geometry.location的话,它就是我们要的结果。
可以用前面的方法(treq)使用Google Geocoding API。只需要几行,我们就可以找到一个地址的坐标(目录pipelines中的geo.py),如下所示:
@defer.inlineCallbacks
def geocode(self, address):
endpoint = 'http://web:9312/maps/api/geocode/json'
parms = [('address', address), ('sensor', 'false')]
response = yield treq.get(endpoint, params=parms)
content = yield response.json()
geo = content['results'][0]["geometry"]["location"]
defer.returnValue({"lat": geo["lat"], "lon": geo["lng"]})
这个函数做出了一条URL,但我们让它指向一个可以离线快速运行的假程序。你可以使用endpoint = 'https://maps.googleapis.com/maps/api/geocode/json'连接Google服务器,但要记住它对请求的限制很严格。address和sensor的值是URL自动编码的,使用treq的方法get()的参数params。对于第二个yield,即response.json(),我们必须等待响应主题完全加载完毕对解析为Python对象。此时,我们就可以找到第一个结果的地理信息,格式设为dict,使用defer.returnValue()返回,它使用了inlineCallbacks。如果发生错误,这个方法会扔出例外,Scrapy会向我们报告。
通过使用geocode(),process_item()变成了一行语句:
item["location"] = yield self.geocode(item["address"][0])
设置让pipeline生效,将它添加到ITEM_PIPELINES,并设定优先数值,该数值要小于ES的,以让ES获取坐标值:
ITEM_PIPELINES = {
...
'properties.pipelines.geo.GeoPipeline': 400,
开启数据调试,然后运行:
$ scrapy crawl easy -s CLOSESPIDER_ITEMCOUNT=90 -L DEBUG
...
{'address': [u'Greenwich, London'],
...
'image_URL': [u'http://web:9312/images/i06.jpg'],
'location': {'lat': 51.482577, 'lon': -0.007659},
'price': [1030.0],
...
我们现在可以看到Items里的location字段。如果使用真正的Google API的URL运行,会得到例外:
File "pipelines/geo.py" in geocode (content['status'], address))
Exception: Unexpected status="OVER_QUERY_LIMIT" for
address="*London"
这是为了检查我们在完整代码中插入了地点,以确保Geocoding API响应的status字段有OK值。除非是OK,否则我们取回的数据不会有设定好的格式,进而不能使用。对于这种情况,我们会得到OVER_QUERY_LIMIT状态,它指明我们在某处做错了。这个问题很重要,也很常见。应用Scrapy的高性能引擎,进行缓存、限制请求就很必要了。
我们可以在Geocoder API的文档,查看它的限制,“每24小时,免费用户可以进行2500次请求,每秒5次请求”。即使我们使用付费版本,仍有每秒10次请求的限制,所以这里的分析是有意义的。
笔记:后面的代码看起来可能有些复杂,复杂度还要取决于实际情况。在多线程环境中创建这样的组件,需要线程池和同步,这样代码就会变复杂。
这是一个简易的运用Twisted技术的限制引擎:
class Throttler(object):
def __init__(self, rate):
self.queue = []
self.looping_call = task.LoopingCall(self._allow_one)
self.looping_call.start(1. / float(rate))
def stop(self):
self.looping_call.stop()
def throttle(self):
d = defer.Deferred()
self.queue.append(d)
return d
def _allow_one(self):
if self.queue:
self.queue.pop(0).callback(None)
这可以让延迟项在一个列表中排队,逐个触发,调用_allow_one();_allow_one()检查队列是否为空,如果不是,它会调用第一个延迟项的callback()。我们使用Twisted的task.LoopingCall() API,周期性调用_allow_one()。使用Throttler很容易。我们在pipeline的init初始化它,当爬虫停止时清空它:
class GeoPipeline(object):
def __init__(self, stats):
self.throttler = Throttler(5) # 5 Requests per second
def close_spider(self, spider):
self.throttler.stop()
在使用限定源之前,我们的例子是在process_item()中调用geocode(),必须yield限制器的throttle()方法:
yield self.throttler.throttle()
item["location"] = yield self.geocode(item["address"][0])
对于第一个yield,代码会暂停一下,一段时间之后,会继续运行。例如,当某时有11个延迟项时,限制是每秒5次请求,即时间为11/5=2.2秒之后,队列变空,代码会继续。
使用Throttler,不再有错误,但是爬虫会变慢。我们看到示例中的房子只有几个不同的地址。这时使用缓存非常好。我们使用一个简单的Python dict来做,但这么可能会有竞争条件,这样会造成伪造的API请求。下面是一个没有此类问题的缓存方法,展示了Python和Twisted的特点:
class DeferredCache(object):
def __init__(self, key_not_found_callback):
self.records = {}
self.deferreds_waiting = {}
self.key_not_found_callback = key_not_found_callback
@defer.inlineCallbacks
def find(self, key):
rv = defer.Deferred()
if key in self.deferreds_waiting:
self.deferreds_waiting[key].append(rv)
else:
self.deferreds_waiting[key] = [rv]
if not key in self.records:
try:
value = yield self.key_not_found_callback(key)
self.records[key] = lambda d: d.callback(value)
except Exception as e:
self.records[key] = lambda d: d.errback(e)
action = self.records[key]
for d in self.deferreds_waiting.pop(key):
reactor.callFromThread(action, d)
value = yield rv
defer.returnValue(value)
这个缓存看起来有些不同,它包含两个组件:
- self.deferreds_waiting:这是一个延迟项的队列,等待给键赋值
- self.records:这是键值对中出现过的dict
在find()方法的中间,如果没有在self.records找到一个键,我们会调用预先定义的callback函数,以取回丢失的值(yield self.key_not_found_callback(key))。这个调回函数可能会扔出一个例外。如何在Python中压缩存储值或例外呢?因为Python是一种函数语言,根据是否有例外,我们在self.records中保存小函数(lambdas),调用callback或errback。lambda函数定义时,就将值或例外附着在上面。将变量附着在函数上称为闭包,闭包是函数语言最重要的特性之一。
笔记:缓存例外有点不常见,但它意味着首次查找key时,key_not_found_callback(key)返回了一个例外。当后续查找还找这个key时,就免去了调用,再次返回这个例外。
find()方法其余的部分提供了一个避免竞争条件的机制。如果查找某个键已经在进程中,会在self.deferreds_waiting dict中有记录。这时,我们不在向key_not_found_callback()发起另一个调用,只是在延迟项的等待列表添加这个项。当key_not_found_callback()返回时,键有了值,我们触发所有的等待这个键的延迟项。我们可以直接发起action(d),而不用reactor.callFromThread(),但需要处理每个扔给下游的例外,我们必须创建不必要的很长的延迟项链。
使用这个缓存很容易。我们在init()对其初始化,设定调回函数为API调用。在process_item()中,使用缓存查找的方法如下:
def __init__(self, stats):
self.cache = DeferredCache(self.cache_key_not_found_callback)
@defer.inlineCallbacks
def cache_key_not_found_callback(self, address):
yield self.throttler.enqueue()
value = yield self.geocode(address)
defer.returnValue(value)
@defer.inlineCallbacks
def process_item(self, item, spider):
item["location"] = yield self.cache.find(item["address"][0])
defer.returnValue(item)
提示:完整代码位于ch09/properties/properties/pipelines/geo2.py。
为了使pipeline生效,我们使前一个方法无效,并添加当前的到settings.py的ITEM_PIPELINES:
ITEM_PIPELINES = {
'properties.pipelines.tidyup.TidyUp': 100,
'properties.pipelines.es.EsWriter': 800,
# DISABLE 'properties.pipelines.geo.GeoPipeline': 400,
'properties.pipelines.geo2.GeoPipeline': 400,
}
运行爬虫,用如下代码:
$ scrapy crawl easy -s CLOSESPIDER_ITEMCOUNT=1000
...
Scraped... 15.8 items/s, avg latency: 1.74 s and avg time in pipelines:
0.94 s
Scraped... 32.2 items/s, avg latency: 1.76 s and avg time in pipelines:
0.97 s
Scraped... 25.6 items/s, avg latency: 0.76 s and avg time in pipelines:
0.14 s
...
: Dumping Scrapy stats:...
'geo_pipeline/misses': 35,
'item_scraped_count': 1019,
当填充缓存时,我们看到抓取的延迟变高。缓存结束时,延迟降低。数据还显示有35个遗漏,正好是数据集中不同地点的数目。很明显,上例中一共有1019 - 35= 984次API请求。如果我们使用真正的Google API,并提高每秒的API请求数,例如通过改变Throttler(5)到Throttler(10),使从5提高到10,我们可以将重试添加到geo_pipeline/retries stat记录中。如果有错误的话,例如,使用API找不到某个地点,会扔出一个例外,这会被geo_pipeline/errors stat记录。如果地点通过什么方式已经存在了,会在geo_pipeline/already_set stat中指明。最后,如果我们访问http://localhost:9200/properties/property/_search,以检查ES中的房子,我们可以看到包括地点的记录,例如{..."location": {"lat": 51.5269736, "lon": -0.0667204}...}。(运行前确保清空集合,去除旧的值)
在Elasticsearch进行地理索引
我们已经有了地点,我们可以将它们按距离排序。下面是一个HTTP POST请求,返回标题中包含Angel的房子,按照离点{51.54, -0.19}的距离进行排序:
$ curl http://es:9200/properties/property/_search -d '{
"query" : {"term" : { "title" : "angel" } },
"sort": [{"_geo_distance": {
"location": {"lat": 51.54, "lon": -0.19},
"order": "asc",
"unit": "km",
"distance_type": "plane"
}}]}'
唯一的问题是如果我们运行它,我们会看到一个错误信息"failed to find mapper for [location] for geo distance based sort"。它指出,我们的location字段没有正确的空间计算的格式。为了设定正确的格式,我们要手动覆盖默认格式。首先,我们将自动检测的映射保存起来,将它作为起点:
$ curl 'http://es:9200/properties/_mapping/property' > property.txt
然后,我们如下所示编辑property.txt:
"location":{"properties":{"lat":{"type":"double"},"lon":{"type":"double"}}}
我们将这行代码替换为:
"location": {"type": "geo_point"}
我们还在文件最后删除了{"properties":{"mappings": and two }}。文件现在就处理完了。我们现在可以删除旧的类型,并用下面的schema建立新的类型:
$ curl -XDELETE 'http://es:9200/properties'
$ curl -XPUT 'http://es:9200/properties'
$ curl -XPUT 'http://es:9200/properties/_mapping/property' --data
@property.txt
我们现在可以用之前的命令,进行一个快速抓取,将结果按距离排序。我们的搜索返回的是房子的JSONs对象,其中包括一个额外的sort字段,显示房子离某个点的距离。
连接数据库与Python客户端
可以连接Python Database API 2.0的数据库有许多种,包括MySQL、PostgreSQL、Oracle、Microsoft、SQL Server和SQLite。它们的驱动通常很复杂且进行过测试,为Twisted再进行适配会浪费很多时间。可以在Twisted应用中使用数据库客户端,例如,Scrapy可以使用twisted.enterprise.adbapi库。我们使用MySQL作为例子,说明用法,原则也适用于其他数据库。
用pipeline写入MySQL
MySQL是一个好用又流行的数据库。我们来写一个pipeline,来向其中写入文件。我们的虚拟环境中,已经有了一个MySQL实例。我们用MySQL命令行来做一些基本的管理操作,命令行工具已经在开发机中预先安装了:
$ mysql -h mysql -uroot -ppass
mysql>提示MySQL已经运行,我们可以建立一个简单的含有几个字段的数据表,如下所示:
mysql> create database properties;
mysql> use properties
mysql> CREATE TABLE properties (
url varchar(100) NOT NULL,
title varchar(30),
price DOUBLE,
description varchar(30),
PRIMARY KEY (url)
);
mysql> SELECT * FROM properties LIMIT 10;
Empty set (0.00 sec)
很好,现在已经建好了一个包含几个字段的MySQL数据表,它的名字是properties,可以开始写pipeline了。保持MySQL控制台打开,我们过一会儿会返回查看是否有差入值。输入exit,就可以退出。
笔记:在这一部分中,我们会向MySQL数据库插入properties。如果你想删除,使用以下命令:
mysql> DELETE FROM properties;
我们使用MySQL的Python客户端。我们还要安装一个叫做dj-database-url的小功能模块(它可以帮我们设置不同的IP、端口、密码等等)。我们可以用pip install dj-database-url MySQL-python,安装这两项。我们的开发机上已经安装好了。我们的MySQL pipeline很简单,如下所示:
from twisted.enterprise import adbapi
...
class MysqlWriter(object):
...
def __init__(self, mysql_url):
conn_kwargs = MysqlWriter.parse_mysql_url(mysql_url)
self.dbpool = adbapi.ConnectionPool('MySQLdb',
charset='utf8',
use_unicode=True,
connect_timeout=5,
**conn_kwargs)
def close_spider(self, spider):
self.dbpool.close()
@defer.inlineCallbacks
def process_item(self, item, spider):
try:
yield self.dbpool.runInteraction(self.do_replace, item)
except:
print traceback.format_exc()
defer.returnValue(item)
@staticmethod
def do_replace(tx, item):
sql = """REPLACE INTO properties (url, title, price, description) VALUES (%s,%s,%s,%s)"""
args = (
item["url"][0][:100],
item["title"][0][:30],
item["price"][0],
item["description"][0].replace("\r\n", " ")[:30]
)
tx.execute(sql, args)
提示:完整代码位于ch09/properties/properties/pipelines/mysql.py。
本质上,这段代码的大部分都很普通。为了简洁而省略的代码将一条保存在MYSQL_PIPELINE_URL、格式是mysql://user:pass@ip/database的URL,解析成了独立的参数。在爬虫的init()中,将它们传递到adbapi.ConnectionPool(),它使用adbapi的底层结构,初始化MySQL连接池。第一个参数是我们想要引入的模块的名字。对于我们的MySQL,它是MySQLdb。我们为MySQL客户端另设了几个参数,以便正确处理Unicode和超时。每当adbapi打开新连接时,所有这些参数都要进入底层的MySQLdb.connect()函数。爬虫关闭时,我们调用连接池的close()方法。
我们的process_item()方法包装了dbpool.runInteraction()。这个方法给调回方法排队,会在当连接池中一个连接的Transaction对象变为可用时被调用。这个Transaction对象有一个和DB-API指针相似的API。在我们的例子中,调回方法是do_replace(),它定义在后面几行。@staticmethod是说这个方法关联的是类而不是具体的类实例,因此,我们可以忽略通常的self参数。如果方法不使用成员的话,最好设其为静态,如果你忘了设为静态也不要紧。这个方法准备了一个SQL字符串、几个参数,并调用Transaction的execute()函数,以进行插入。我们的SQL使用REPLACE INTO,而不用更常见的INSERT INTO,来替换键相同的项。这可以让我们的案例简化。如果我们相拥SQL返回数据,例如SELECT声明,我们使用dbpool.runQuery(),我们可能还需要改变默认指针,方法是设置adbapi.ConnectionPool()的参数cursorclass为cursorclass=MySQLdb.cursors,这样取回数据更为简便。
使用这个pipeline,我们要在settings.py的ITEM_PIPELINES添加它,还要设置一下MYSQL_PIPELINE_URL:
ITEM_PIPELINES = { ...
'properties.pipelines.mysql.MysqlWriter': 700,
...
MYSQL_PIPELINE_URL = 'mysql://root:pass@mysql/properties'
执行以下命令:
scrapy crawl easy -s CLOSESPIDER_ITEMCOUNT=1000
运行这条命令后,返回MySQL控制台,可以看到如下记录:
mysql> SELECT COUNT(*) FROM properties;
+----------+
| 1006 |
+----------+
mysql> SELECT * FROM properties LIMIT 4;
+------------------+--------------------------+--------+-----------+
| url | title | price | description
+------------------+--------------------------+--------+-----------+
| http://...0.html | Set Unique Family Well | 334.39 | website c
| http://...1.html | Belsize Marylebone Shopp | 388.03 | features
| http://...2.html | Bathroom Fully Jubilee S | 365.85 | vibrant own
| http://...3.html | Residential Brentford Ot | 238.71 | go court
+------------------+--------------------------+--------+-----------+
4 rows in set (0.00 sec)
延迟和吞吐量的性能和之前相同。结果让人印象深刻。
使用Twisted 特定客户端连接服务
目前为止,我们学习了如何用treq使用类REST APIs。Scrapy可以用Twisted特定客户端连接许多其它服务。例如,如果我们想连接MongoDB,通过搜索“MongoDB Python”,我们可以找到PyMongo,它是阻塞/同步的,除非我们使用pipeline处理阻塞操作中的线程,我们不能在Twisted中使用PyMongo。如果我们搜索“MongoDB Twisted Python”,可以找到txmongo,它可以完美适用于Twisted和Scrapy。通常的,Twisted客户端群体很小,但使用它比起自己写一个客户端还是要方便。下面,我们就使用这样一个Twisted特定客户端连接Redis键值对存储。
用pipeline读写Redis
Google Geocoding API是按照每个IP进行限制的。如果可以接入多个IPs(例如,多台服务器),当一个地址已经被另一台机器做过地理编码,就要设法避免对发出重复的请求。如果一个地址之前已经被查阅过,也要避免再次查阅。我们不想浪费限制的额度。
笔记:与API商家联系,以确保这符合规定。你可能,必须每几分钟/小时,就要清空缓存记录,或者根本就不能缓存。
我们可以使用Redis键值缓存作为分布式dict。Vagrant环境中已经有了一个Redis实例,我们现在可以连接它,用redis-cli作一些基本操作:
$ redis-cli -h redis
redis:6379> info keyspace
# Keyspace
redis:6379> set key value
OK
redis:6379> info keyspace
# Keyspace
db0:keys=1,expires=0,avg_ttl=0
redis:6379> FLUSHALL
OK
redis:6379> info keyspace
# Keyspace
redis:6379> exit
通过搜索“Redis Twisted”,我们找到一个txredisapi库。它最大的不同是,它不仅是一个Python的同步封装,还是一个Twisted库,可以通过reactor.connectTCP(),执行Twisted协议,连接Redis。其它库也有类似用法,但是txredisapi对于Twisted效率更高。我们可以通过安装库dj_redis_url可以安装它,这个库通过pip可以解析Redis配置URL(sudo pip install txredisapi dj_redis_url)。和以前一样,开发机中已经安装好了。
我们如下启动RedisCache pipeline:
from txredisapi import lazyConnectionPool
class RedisCache(object):
...
def __init__(self, crawler, redis_url, redis_nm):
self.redis_url = redis_url
self.redis_nm = redis_nm
args = RedisCache.parse_redis_url(redis_url)
self.connection = lazyConnectionPool(connectTimeout=5,
replyTimeout=5,
**args)
crawler.signals.connect(
self.item_scraped,signal=signals.item_scraped)
这个pipeline比较简单。为了连接Redis服务器,我们需要主机、端口等等,它们全都用URL格式存储。我们用parse_redis_url()方法解析这个格式。使用命名空间做键的前缀很普遍,在我们的例子中,我们存储在redis_nm。我们然后使用txredisapi的lazyConnectionPool()打开一个数据库连接。
最后一行有一个有趣的函数。我们是想用pipeline封装geo-pipeline。如果在Redis中没有某个值,我们不会设定这个值,geo-pipeline会用API像之前一样将地址进行地理编码。完毕之后,我们必须要在Redis中缓存键值对,我们是通过连接signals.item_scraped信号来做的。我们定义的调回(即item_scraped()方法,马上会讲)只有在最后才会被调用,那时,地址就设置好了。
提示:完整代码位于ch09/properties/properties/pipelines/redis.py。
我们简化缓存,只寻找和存储每个Item的地址和地点。这对Redis来说是合理的,因为它通常是运行在单一服务器上的,这可以让它很快。如果不是这样的话,可以加入一个dict结构的缓存,它与我们在geo-pipeline中用到的相似。以下是我们如何处理入库的Items:
process incoming Items:
@defer.inlineCallbacks
def process_item(self, item, spider):
address = item["address"][0]
key = self.redis_nm + ":" + address
value = yield self.connection.get(key)
if value:
item["location"] = json.loads(value)
defer.returnValue(item)
和预期的相同。我们得到了地址,给它添加前缀,然后使用txredisapi connection的get()在Redis进行查找。我们将JSON编码的对象在Redis中保存成值。如果一个值设定了,我们就使用JSON解码,然后将其设为地点。
当一个Item到达pipelines的末端时,我们重新取得它,将其保存为Redis中的地点值。以下是我们的做法:
from txredisapi import ConnectionError
def item_scraped(self, item, spider):
try:
location = item["location"]
value = json.dumps(location, ensure_ascii=False)
except KeyError:
return
address = item["address"][0]
key = self.redis_nm + ":" + address
quiet = lambda failure: failure.trap(ConnectionError)
return self.connection.set(key, value).addErrback(quiet)
如果我们找到了一个地点,我们就取得了地址,添加前缀,然后使用它作为txredisapi连接的set()方法的键值对。set()方法没有使用@defer.inlineCallbacks,因为处理signals.item_scraped时,它不被支持。这意味着,我们不能对connection.set()使用yield,但是我们可以返回一个延迟项,Scrapy可以在它后面排上其它信号对象。任何情况下,如果Redis的连接不能使用用connection.set(),它就会抛出一个例外。在这个错误处理中,我们把传递的错误当做参数,我们让它trap()任何ConnectionError。这是Twisted的延迟API的优点之一。通过用trap()捕获错误项,我们可以轻易忽略它们。
使这个pipeline生效,我们要做的是在settings.py的ITEM_PIPELINES中添加它,并提供一个REDIS_PIPELINE_URL。必须要让它的优先级比geo-pipeline高,以免太晚就不能使用了:
ITEM_PIPELINES = { ...
'properties.pipelines.redis.RedisCache': 300,
'properties.pipelines.geo.GeoPipeline': 400,
...
REDIS_PIPELINE_URL = 'redis://redis:6379'
像之前一样运行。第一次运行时和以前很像,但随后的运行结果如下:
$ scrapy crawl easy -s CLOSESPIDER_ITEMCOUNT=100
...
INFO: Enabled item pipelines: TidyUp, RedisCache, GeoPipeline,
MysqlWriter, EsWriter
...
Scraped... 0.0 items/s, avg latency: 0.00 s, time in pipelines: 0.00 s
Scraped... 21.2 items/s, avg latency: 0.78 s, time in pipelines: 0.15 s
Scraped... 24.2 items/s, avg latency: 0.82 s, time in pipelines: 0.16 s
...
INFO: Dumping Scrapy stats: {...
'geo_pipeline/already_set': 106,
'item_scraped_count': 106,
我们看到GeoPipeline和RedisCache都生效了,RedisCache第一个输出。还注意到在统计中geo_pipeline/already_set: 106。这是GeoPipeline发现的Redis缓存中填充的数目,它不调用Google API。如果Redis缓存是空的,你会看到Google API处理了一些键。从性能上来讲,我们看到GeoPipeline引发的初始行为消失了。事实上,当我们开始使用内存,我们绕过了每秒只有5次请求的API限制。如果我们使用Redis,应该考虑使用过期键,让系统周期刷新缓存数据。
连接CPU密集型、阻塞或旧方法
最后一部分讲连接非Twisted的工作。尽管异步程序的优点很多,并不是所有库都专门为Twisted和Scrapy写的。使用Twisted的线程池和reactor.spawnProcess()方法,我们可以使用任何Python库和任何语言写的编码。
pipeline进行CPU密集型和阻塞操作
我们在第8章中强调,反应器适合简短非阻塞的任务。如果我们不得不要处理复杂和阻塞的任务,又该怎么做呢?Twisted提供了线程池,有了它可以使用reactor.callInThread() API在分线程而不是主线程中执行慢操作。这意味着,反应器可以一直运行并对事件反馈,而不中断计算。但要记住,在线程池中运行并不安全,当你使用全局模式时,会有多线程的同步问题。让我们从一个简单的pipeline开始,逐渐做出完整的代码:
class UsingBlocking(object):
@defer.inlineCallbacks
def process_item(self, item, spider):
price = item["price"][0]
out = defer.Deferred()
reactor.callInThread(self._do_calculation, price, out)
item["price"][0] = yield out
defer.returnValue(item)
def _do_calculation(self, price, out):
new_price = price + 1
time.sleep(0.10)
reactor.callFromThread(out.callback, new_price)
在前面的pipeline中,我们看到了一些基本用法。对于每个Item,我们提取出价格,我们相用_do_calucation()方法处理它。这个方法使用time.sleep(),一个阻塞操作。我们用reactor.callInThread()调用,让它在另一个线程中运行。显然,我们传递价格,我们还创建和传递了一个名为out的延迟项。当_do_calucation()完成了计算,我们使用out调回值。下一步,我们执行延迟项,并未价格设新的值,最后返回Item。
在_do_calucation()中,有一个细微之处,价格增加了1,进而睡了100ms。这个时间很多,如果调用进反应器主线程,每秒就不能抓取10页了。通过在另一个线程中运行,就不会再有这个问题。任务会在线程池中排队,每次处理耗时100ms。最后一步是触发调回。一般的,我们可以使用out.callback(new_price),但是因为我们现在是在另一个线程,这么做不安全。如果这么做的话,延迟项的代码会被从另一个线程调用,这样迟早会产生错误的数据。不这样做,转而使用reactor.callFromThread(),它也可以将函数当做参数,将任意其余参数传递到函数。这个函数会排队并被调回主线程,主进程反过来会打开process_item()对象yield,并继续Item的操作。
如果我们用全局模式,例如计数器、滑动平均,又该怎么使用_do_calucation()呢?例如,添加两个变量,beta和delta,如下所示:
class UsingBlocking(object):
def __init__(self):
self.beta, self.delta = 0, 0
...
def _do_calculation(self, price, out):
self.beta += 1
time.sleep(0.001)
self.delta += 1
new_price = price + self.beta - self.delta + 1
assert abs(new_price-price-1) < 0.01
time.sleep(0.10)...
这段代码是断言失败错误。这是因为如果一个线程在self.beta和self.delta间切换,另一个线程继续计算使用beta/delta计算价格,它会发现它们状态不一致(beta大于delta),因此,计算出错误的结果。短暂的睡眠可能会造成竞争条件。为了不发生这些状况,我们要使一个锁,例如Python的threading.RLock()递归锁。使用它,可以确保没有两个线程在同一时间操作被保护代码:
class UsingBlocking(object):
def __init__(self):
...
self.lock = threading.RLock()
...
def _do_calculation(self, price, out):
with self.lock:
self.beta += 1
...
new_price = price + self.beta - self.delta + 1
assert abs(new_price-price-1) < 0.01 ...
代码现在就正确了。记住,我们不需要保护整段代码,就足以处理全局模式。
提示:完整代码位于ch09/properties/properties/pipelines/computation.py。
要使用这个pipeline,我们需要把它添加到settings.py的ITEM_PIPELINES中。如下所示:
ITEM_PIPELINES = { ...
'properties.pipelines.computation.UsingBlocking': 500,
像之前一样运行爬虫,pipeline延迟达到了100ms,但吞吐量没有发生变化,大概每秒25个items。
pipeline使用二进制和脚本
最麻烦的借口当属独立可执行文件和脚本。打开需要几秒(例如,从数据库加载数据),但是后面处理数值的延迟很小。即便是这种情况,Twisted也预料到了。我们可以使用reactor.spawnProcess() API和相关的protocol.ProcessProtocol来运行任何执行文件。让我们来看一个例子。脚本如下:
#!/bin/bash
trap "" SIGINT
sleep 3
while read line
do
# 4 per second
sleep 0.25
awk "BEGIN {print 1.20 * $line}"
done
这是一个简单的bash脚本。它运行时,会使Ctrl + C 无效。这是为了避免系统的一个奇怪的错误,将Ctrl + C增值到子流程并过早结束,导致Scrapy强制等待流程结果。在使Ctrl + C无效之后,它睡眠三秒,模拟启动时间。然后,它阅读输入的代码语句,等待250ms,然后返回结果价格,价格的值乘以了1.20,由Linux的awk命令计算而得。这段脚本的最大吞吐量为每秒1/250ms=4个Items。用一个短session检测:
$ properties/pipelines/legacy.sh
12 <- If you type this quickly you will wait ~3 seconds to get results
14.40
13 <- For further numbers you will notice just a slight delay
15.60
因为Ctrl + C失效了,我们用Ctrl + D必须结束session。我们该如何让Scrapy使用这个脚本呢?再一次,我们从一个简化版开始:
class CommandSlot(protocol.ProcessProtocol):
def __init__(self, args):
self._queue = []
reactor.spawnProcess(self, args[0], args)
def legacy_calculate(self, price):
d = defer.Deferred()
self._queue.append(d)
self.transport.write("%f\n" % price)
return d
# Overriding from protocol.ProcessProtocol
def outReceived(self, data):
"""Called when new output is received"""
self._queue.pop(0).callback(float(data))
class Pricing(object):
def __init__(self):
self.slot = CommandSlot(['properties/pipelines/legacy.sh'])
@defer.inlineCallbacks
def process_item(self, item, spider):
item["price"][0] = yield self.slot.legacy_calculate(item["price"][0])
defer.returnValue(item)
我们在这里找到了一个名为CommandSlot的ProcessProtocol和Pricing爬虫。在init()中,我们创建了新的CommandSlot,它新建了一个空的队列,并用reactor.spawnProcess()开启了一个新进程。它调用收发数据的ProcessProtocol作为第一个参数。在这个例子中,是self的原因是spawnProcess()是被从类protocol调用的。第二个参数是可执行文件的名字,第三个参数args,让二进制命令行参数成为字符串序列。
在pipeline的process_item()中,我们用CommandSlot的legacy_calculate()方法代表所有工作,CommandSlot可以返回产生的延迟项。legacy_calculate()创建延迟项,将其排队,用transport.write()将价格写入进程。ProcessProtocol提供了transport,可以让我们与进程沟通。无论何时我们从进程收到数据, outReceived()就会被调用。通过延迟项,进程依次执行,我们可以弹出最老的延迟项,用收到的值触发它。全过程就是这样。我们可以让这个pipeline生效,通过将它添加到ITEM_PIPELINES:
ITEM_PIPELINES = {...
'properties.pipelines.legacy.Pricing': 600,
如果运行的话,我们会看到性能很差。进程变成了瓶颈,限制了吞吐量。为了提高性能,我们需要修改pipeline,允许多个进程并行运行,如下所示:
class Pricing(object):
def __init__(self):
self.concurrency = 16
args = ['properties/pipelines/legacy.sh']
self.slots = [CommandSlot(args)
for i in xrange(self.concurrency)]
self.rr = 0
@defer.inlineCallbacks
def process_item(self, item, spider):
slot = self.slots[self.rr]
self.rr = (self.rr + 1) % self.concurrency
item["price"][0] = yield
slot.legacy_calculate(item["price"][0])
defer.returnValue(item)
这无非是开启16个实例,将价格以轮转的方式发出。这个pipeline的吞吐量是每秒16*4 = 64。我们可以用下面的爬虫进行验证:
$ scrapy crawl easy -s CLOSESPIDER_ITEMCOUNT=1000
...
Scraped... 0.0 items/s, avg latency: 0.00 s and avg time in pipelines:
0.00 s
Scraped... 21.0 items/s, avg latency: 2.20 s and avg time in pipelines:
1.48 s
Scraped... 24.2 items/s, avg latency: 1.16 s and avg time in pipelines:
0.52 s
延迟增加了250 ms,但吞吐量仍然是每秒25。
请记住前面的方法使用了transport.write()让所有的价格在脚本shell中排队。这个可能对你的应用不适用,,尤其是当数据量很大时。Git的完整代码让值和调回都进行了排队,不想脚本发送值,除非收到前一项的结果。这种方法可能看起来更友好,但是会增加代码复杂度。
总结
你刚刚学习了复杂的Scrapy pipelines。目前为止,你应该就掌握了所有和Twisted编程相关的知识。并且你学会了如何在进程中执行复杂的功能,用Item Processing Pipelines存储Items。我们看到了添加pipelines对延迟和吞吐量的影响。通常,延迟和吞吐量是成反比的。但是,这是在恒定并发数的前提下(例如,一定数量的线程)。在我们的例子中,我们一开始的并发数为N=ST=250.77≅19,添加pipelines之后,并发数为N=25*3.33≅83,并没有引起性能的变化。这就是Twisted的强大之处!下面学习第10章,Scrapy的性能。
序言
第1章 Scrapy介绍
第2章 理解HTML和XPath
第3章 爬虫基础
第4章 从Scrapy到移动应用
第5章 快速构建爬虫
第6章 Scrapinghub部署
第7章 配置和管理
第8章 Scrapy编程
第9章 使用Pipeline
第10章 理解Scrapy的性能
第11章(完) Scrapyd分布式抓取和实时分析
