1.Python简介
- python是一门面向对象的、解释型的编程语言
- 目前Python常见的版本有Python2.x和Python3.x,总结起来,Python3.x各方面更成熟完善些,Python2.x处理速度更快一些,但Python3.x不断在进步,肯定会是主流。
- Python的优点有很多,比如简洁、易学、几乎全能、支持面向对象等。
2.Python能做什么
- 数据分析与挖掘
- 黑客逆向编程
- 网络爬虫
- 机器学习
- 开发web项目
- 开发游戏
- 自动化运维
- ......
3.Python的安装
- 下载安装包
- 进入Python官网下载电脑对应版本即可
Python官网:https://www.python.org/
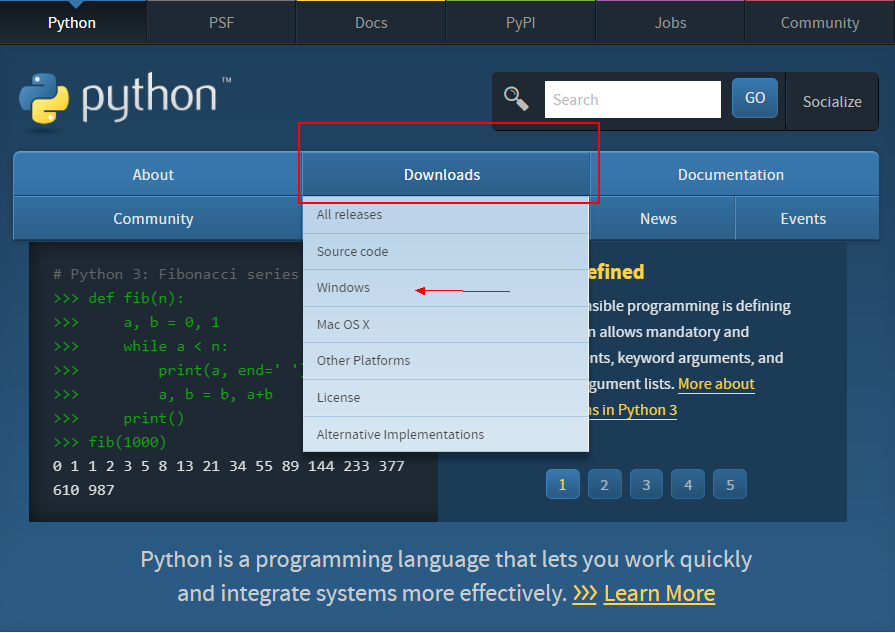
这里下载windows版本演示
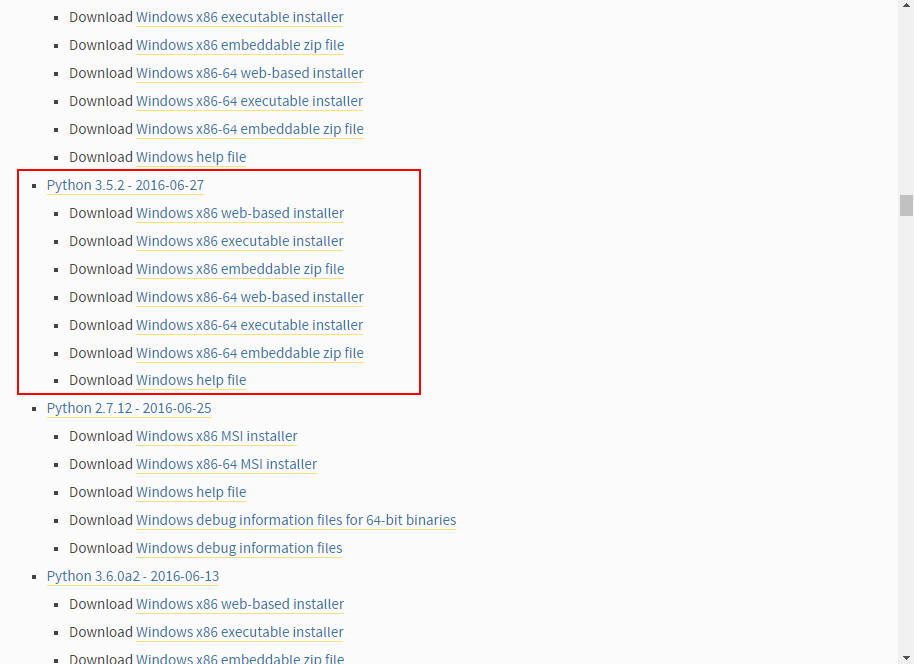
下载电脑对应位数的版本,这里下载的是python3.5.2
由于国内的某一些原因,下载速度可能比较慢,科学上网或者私信笔者,笔者给你发云盘
- 安装
- 点开安装包即可开始安装
注意: 有写时候双击打开可能打不开,这时候只需要右击,使用以管理员身份运行即可
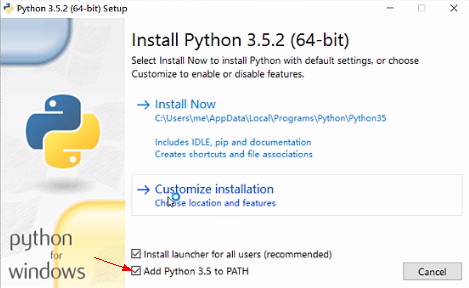
注意箭头位置,最好点上
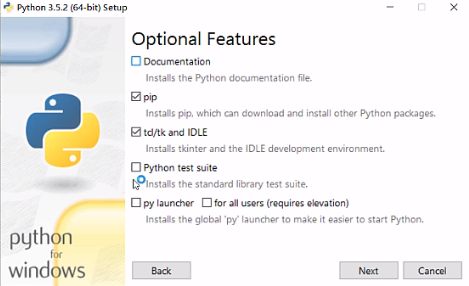
这里建议勾选俩,其他的不勾选
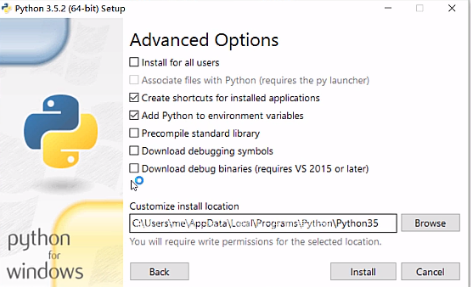
选择自己要安装的盘
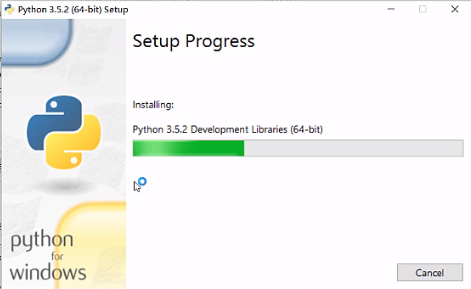
等待安装完成即可
-
测试是否安装成功
使用<windows + r>快捷键输入cmd,打开终端(小黑框)
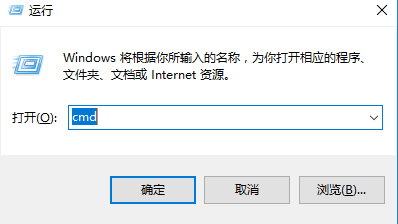 输入cmd后回车
输入cmd后回车
在对话框直接输入python
即可打开python程序

image.png
输入exit()
退出python程序
至此,python已经安装好了

