温故
在基本数据管理部分,主要是涉及到如何新建数据集,并且对数据集中的变量和观测值进行提取和操作。基本上用到了如下函数,可以根据函数名回忆一下用法:
import pandas as pd
import numpy as np
from pandas import Series, DataFrame
pd.read_table()
# 假设新建一个数据框为df
df.head(), df.tail(), df.shape(), df.dtypes()
df['var'] = values # 新建变量
np.where(), np.logical_and, np.less, np.greater # 变量重编码
df.index, df.columns, df.index.map, df.columns.map, df.index.rename, df.index.reanme # 变量重命名
df.isnull, df.notnull, df.dropna, df,fillna # 缺失值处理
pd.to_datetime# 日期值
df.astype # 数据类型转换
df.sorte_index df.sort.values # 排序
pd.merge, pd.concat, pd.appedn # 合并数据集
df.ix[], df[], df.loc[] # 数据取子集
df.sample # 抽样
知新,一个实际案例
这一次我们使用R语言实战高级数据管理的案例:
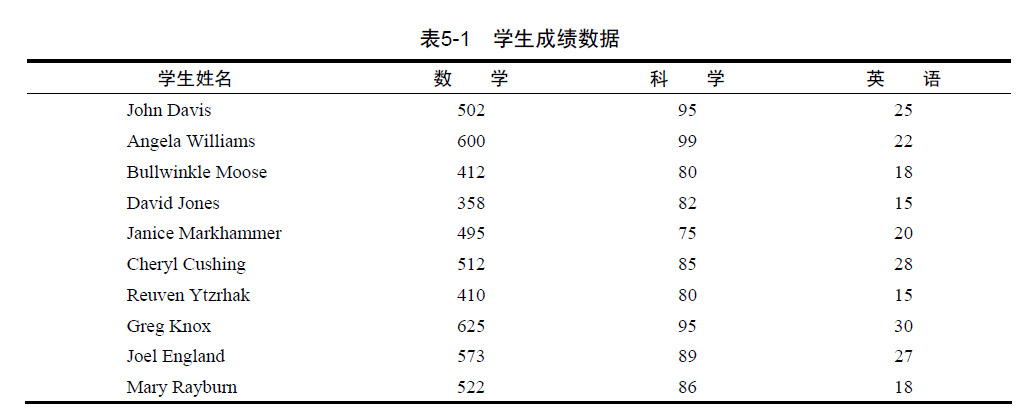
要讨论数值和字符处理函数,让我们首先考虑一个数据处理问题。一组学生参加了数学、科学和英语考试。为了给所有学生确定一个单一的成绩衡量指标,需要将这些科目的成绩组合起来。另外,你还想将前20%的学生评定为A,接下来20%的学生评定为B,依次类推。最后,你希望按字母顺序对学生排序。数据如表5-1所示。
观察此数据集,马上可以发现一些明显的障碍。首先,三科考试的成绩是无法比较的。由于它们的均值和标准差相去甚远,所以对它们求平均值是没有意义的。你在组合这些考试成绩之前,必须将其变换为可比较的单元。其次,为了评定等级,你需要一种方法来确定某个学生在前述得分上百分比排名。再次,表示姓名的字段只有一个,这让排序任务复杂化了。为了正确地将其排序,需要将姓和名拆开。
如下介绍的函数大部分在Python自带库如math,内置函数都有,但是都不是元素级别的,也就是必须要写一个显性的循环函数,和numpy,pandas提供的相比效率相差1000倍以上。
数学函数
数学函数主要由numpy提供,避免用到Python的低效的内置循环,转而使用C封装高效的矢量化运算。用法都是np.func() 。
| 函数 | 描述 |
|---|---|
| abs, fabs | 绝对值。非复数值,用fabs |
| sqrt | 各元素的平方根 |
| square | 计算各元素的平方 |
| exp | 计算个元素的指数 |
| log, log10, log2, log1p | 对数运算 |
| sign | 计算各元素的正负号 |
| ceil(x) | 不小于x的最小整数 |
| floor(x) | 不大于x的最小整数 |
| rint(x) | 将x四舍五入到最接近的整数,保留dtype |
| cos, sin, tan | 余弦,正弦和正切 |
| cosh, sinh, tanh | 双曲余弦,双曲正弦和双曲正切 |
| arccos, arcsin, arctan | 反余弦,反正弦和反正切 |
| arccosh, arcsinh, arctanh | 反双曲余弦,反双曲正弦和反双曲正切 |
我们经常会用到这些函数对数据进行变换。当然,你可能已经忘记了三角函数对应是什么图形了,这个时候就可以尝试一下自己作图了。
%matplotlib
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
x = np.arange(-2*np.pi, 2*np.pi, 0.01*np.pi)
y = np.cos(x)
plt.plot(x,y)

更多有关的numpy的数学函数可以看官方文档的2.8.1节。
统计函数
pandas对象拥有一组常用的数学和统计方法,比如说最大值,最小值,均值,中位数,四分位数等。用法是df.func()。部分函数在numpy也有,因此是np.func。
| 方法 | 说明 |
|---|---|
| desribe | 列计算汇总,列出四分位数等信息 |
| max,min | 最大值和最小值 |
| idxmin, idxmax | 最大值和最小值的索引位置 |
| quantile | 分位数 |
| sum | 求和 |
| mean | 平均数 |
| median | 中位数 |
| mad | 根据平均值计算平均离差 |
| var | 方差 |
| std | 标准差 |
| skew | 样本值的偏度(三阶矩) |
| kurt | 样本值的丰度(四阶矩) |
| cumsum | 样本的累积和 |
| cummin,cummax | 累计最大值和最小值 |
| cumprod | 累积积 |
| diff | 计算一阶差分 |
| pct_change | 计算百分比变化 |
简单案例:均值和标准差的计算
x = np.arange(1,10,1)
x.mean() # np.mean(x)
x.std() # np.std(x)
概率函数
根据定义,概率函数也属于统计类,但是pandas没有提供这类函数。这类函数用到一个专门的科学计算库 scipy, 是一组专门解决科学计算中各种标准问题域的包的集合。
为了能更好的应用,可能需要花一点功夫稍微讲解一下 scipy 的 概率函数(stats)模块。该模块提供了常用的概率分布,大致分为两类,连续型分布和离散型分布,这两类分布都是 rv__continuous 和 rv_discrete 的子类。
比如说标准的正态函数分布,norm, 作为 rv_continuous的子类,它覆写了父类的pdf方法
norm.pdf(x) = exp(-x**2/2)/sqrt(2*pi)
用人类更加可读的形式写出来就是 $f(x) = \frac{1}{\sqrt(2\pi)} e{-\frac{x2}{2}}$ 也就是教科书上的定义方式。如果查看他的均值和方差,也是熟悉的0和1. 也就是说通过rv__continuous 和 rv_discrete 这两个父类还能够构造出 stats 模块没有提供分布函数。
子类继承父类的方法,如 var, std, mean, median 提供分布的各统计量, expect 计算期望值, stats 函数提供了moments参数用于指定需要计算的统计量,m=mean, v=variance, s=Fisher's skew, k=Fisher's kurtosis.
R中的概率函数形如[dpqr] 分布函数英文缩写,scipy.stats则是分布函数英文缩写.方法
- rvs(): 根据概率分布,返回随机数
- pdf(x): 密度函数, 对应R的d
- cdf(x): 给定随机变量(RV)的累积分布函数(),对应R的p
- ppf(x): 分位数函数(quantile function) 对应R的q
- sf(x): 生存函数(1-cdf)
常用的概率函数如下表
| 连续型分布 | 缩写 | 离散型分布 | 缩写 |
|---|---|---|---|
| Beta分布 | beta | 二项分布 | binorm |
| 柯西分布 | cauchy | 几何分布 | geom |
| 卡方分布 | chi2 | 超几何分布 | hypergeom |
| 指数分布 | expon | 负二项分布 | nbinom |
| F分布 | f | 泊松分布 | poisson |
| (通用) Gmamma分布 | (gen)gamma | - | - |
| 对数正态分布 | exponnorm | - | - |
| (通用)正态分布 | (gen)nrom) | - | - |
其他相关的分布用到的时候查官方文档就行了。
以熟悉的正态分布的有关函数和方法为例,了解这些函数的使用方法。如标准正态函数的密度函数(norm.pdf),分布函数(norm.ppf),随机数生成函数
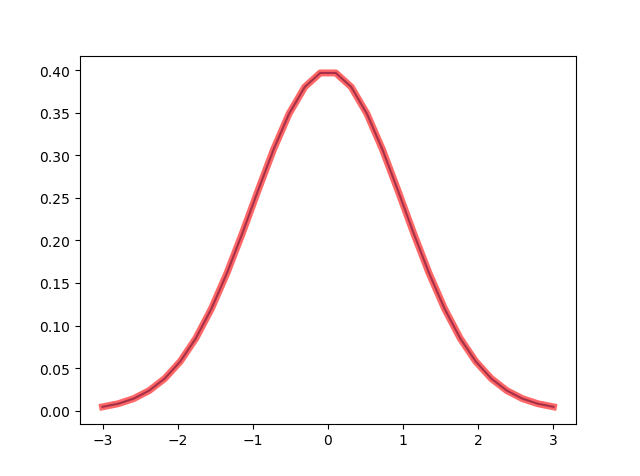
绘制标准正态曲线
from scipy.stats import norm
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1, 1)
x = np.linspace(-3,3,30) # 非常熟悉的MATLAB,对应R的pretty
y = norm.pdf(x) # 对应R的dnrom
ax.plot(x,y,'r-', lw=5, alpha=0.6, label='norm pdf')
)
norm.cdf(1.96)约等于0.975, norm.ppf(0.975) 与等于1.96。norm.rvs(siez=(4,4))生成一个4X4的随机数,等同于np.random.normal(size=(4,4)).
字符处理函数
Python本身的字符处理模块是非常多的,比如说re用于正则,string是常用字符操作模块, 字符串数据类型本身还有许多方法。 我在简书上的一篇文章Python与R的异同(二):字符串操作 就介绍了两则的异同。
这些函数无法直接套用到ndarry, Series, DataFrame数据结构中,需要用到专门的方法。不过,pandas提供了矢量化的字符串方法,更加高效。
| 方法 | 说明 |
|---|---|
| len | 计算字符数量 |
| contains | 是否符合含指定模式的布尔型数组 |
| count | 最大值和最小值的索引位置 |
| findall | 计算各字符串的模式列表 |
| cat | 实现元素级的字符串连接操作 |
| get | 获取第i个元素 |
| lower, upper | 大小写转换 |
| match | 元素级别的re.match |
| split | 根据正则或指定分隔符进行分割 |
| strip, rstrip, lstrip | 去除空白符,包括换行符 |
| join | 根据指定的分隔符进行连接 |
| repeat | 对字符进行重复 |
| replace | 用指定的字符串替换找到的模式 |
以《利用Python做数据分析》的数据为例,介绍如何匹配字符,提取指定内容。
data = {'Dava':'dave@google.com','Steve':'steve@gmail.com','Rob':'rob@gmail.com','Wes':np.nan}
data = Series(data)
data.str.contains('gmail')
import re
# 提取姓名等信息
pattern = re.compile(r'([A-Z0-9._%+-]+)@([A-Z0-9.-]+)\.[A-Z]{2,4}', flags=re.IGNORECASE)
data.str.findall(pattern)
将函数应用到Series和DataFrame中
我们介绍的数学函数和统计函数,大部分都是元素级别的操作,也就是能够直接应用到一系列数据结构上,包括Python自带的序列数据结构,list, tuple, numpy的ndarray,pandas提供的Series和DataFrame.
a = 5
np.sqrt(a) # 如果用math.sqrt(5),效率相差100倍
b = np.array([1.243,5.654,2.99])
np.round(b) # 比[round(x) for x in b] 快5倍
c = np.random.uniform(size=(3,4))
np.log(c)
np.mean(c)
默认情况下,np.mean计算的是总体均值,如果你希望按行按列计算均值的话,可以简单的使用np.meanc(c, axis=1),axis的0表示按列,1表示按行。还有一个比较通用的方法类似于R的apply函数。
numpy使用的apply_along_axis,apply_over_axes;pandas则是为数据框提供了apply和applymap方法. 这里演示pandas的apply方法, 其他查看帮助文档就行。
# df.apply(func, axis=0), func可以是自定义函数
data = DataFrame(c)
data.apply(np.mean, 1)
除了apply外,pandas还允许用applymap映射原来的Python的自带函数成为元素级函数. 比如说直接用math.ceil(data)是不行的,需要用applymap进行映射。
data.applymap(lambda x : math.ceil(x)) #相比较np.ceil 效率相差80倍
解决问题
还记得之前提出的问题吗, 先回顾一下,然后用刚才学到的知识进行解决。
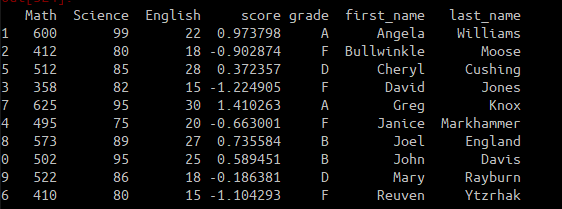
将学生的各科考试成绩组合为单一的成绩衡量指标、基于相对名次(前20%,下20%,等等)给出从A到F的评分、根据学生姓氏和名字的首字母对花名册进行排序
第一步: 数据输入
# 导入库
import numpy as np
from pandas import Series, Dataframe
# 数据
roster = pd.read_csv("student_grade.txt", header=None,names=["Student","Math","Science", "English"])
第二步: 计算综合评分。计算综合得分就是先对每一门学科的成绩进行标准化,然后进行相加。标准化的一种方法是归一化,即将一组数据进行均值为0,标准差为1的标准化。
score = np.mean(roster.ix[:,1:].apply(lambda x : (x-np.mean(x))/np.std(x)), axis=1)
roster['score'] = score
这一步比较复杂的就是我用了匿名函数进行标准化,然后用np.mean进行计算均值。
第三步: 计算四分位数, 并且学生进行评分
y = roster.score.quantile(q=[0.8,0.6,0.4,0.2])
grade = np.where(score > y.ix[0.8], 'A', np.where(score > y.ix[0.6], 'B', np.where(score > y.ix[0.4], 'D','F')))
roster['grade'] = grade
这一步用到了np.where进行元素级别的判断。、复制给grade列。
第四步: 根据学生姓氏和名字的首字母对花名册进行排序
first_name = roster.Student.apply(lambda x: x.split(sep=' ')[0])
last_name = roster.Student.apply(lambda x: x.split(sep=' ')[1])
roster['first_name'] = firt_name
roster['last_name'] = last_name
roster.drop('Student', axis=1, inplace=True)
同样用到了匿名函数, 对所有元素应用字符处理函数。
第五步: 排序
roster.sort_values(by=['first_name','last_name'], inplace=True)
最后结果如下: