Numpy:数组和矢量计算包
对于大部分数据分析工具,作者主要关注如下功能
- 快速矢量化矩阵运算,用于数据规整化和清理,筛选,过滤,格式转换等
- 常用矩阵算法,排序、唯一值和集合运算
- 高效描述性统计和聚合分析
- 数据对准,和关联数据操作,从而便于合并不同类型的数据集
- 避免使用if-elif-else和loops进行逻辑判断
- 分组数据操作
而Numpy的部分功能如下:
- ndarray, 一个具有矢量算术运算和复杂广播能力的快速且节省空间的多维数组
- 用于对整组数据进行快速运算的标准数学函数(无需编写循环函数)
- 用于读写磁盘数据的工具以及用于操作内存映射文件的工具
- 线性代数, 随机数生成以及傅里叶变换功能
- 用于继承由C, C++, Fortran等语言编写的代码的工具
尽管Numpy并不满足作者的所有需求,但是熟练掌握的Numpy的面向数组编程(arrary-oriented programming),以数组的方式思考对成为Python数据分析科学家至关重要。
ndarray: 多维数组对象,高效的源头
Python低效的原因有一个就是“在Python里面一切都是对象”,所以它不存在基本数据类型,每次运算都要进行类型判断会降低了效率。而Numpy将数据存放在连续的内存块中,Numpy处理这部分内存块就不需要进行类型检查了。并且Numpy的矢量化运算,避免了Python原生for循环,效率再次提高。
举例说明:
import numpy as np
raw_arr = list(range(10000))
np_arr = np.arange(10000)
%%timeit
raw_arr2 = [x * 2 for x in raw_arr]
# 时间是349 us += 2.83 us
%%timeit
np_arr2 = np_arr * 2
# 时间是6.94 us += 33.5 ns
速度相差了50倍。
注:Java作为一门面向对象语言,保留了8种基本数据类型(不包括字符串)。
ndarrays的思维导图:
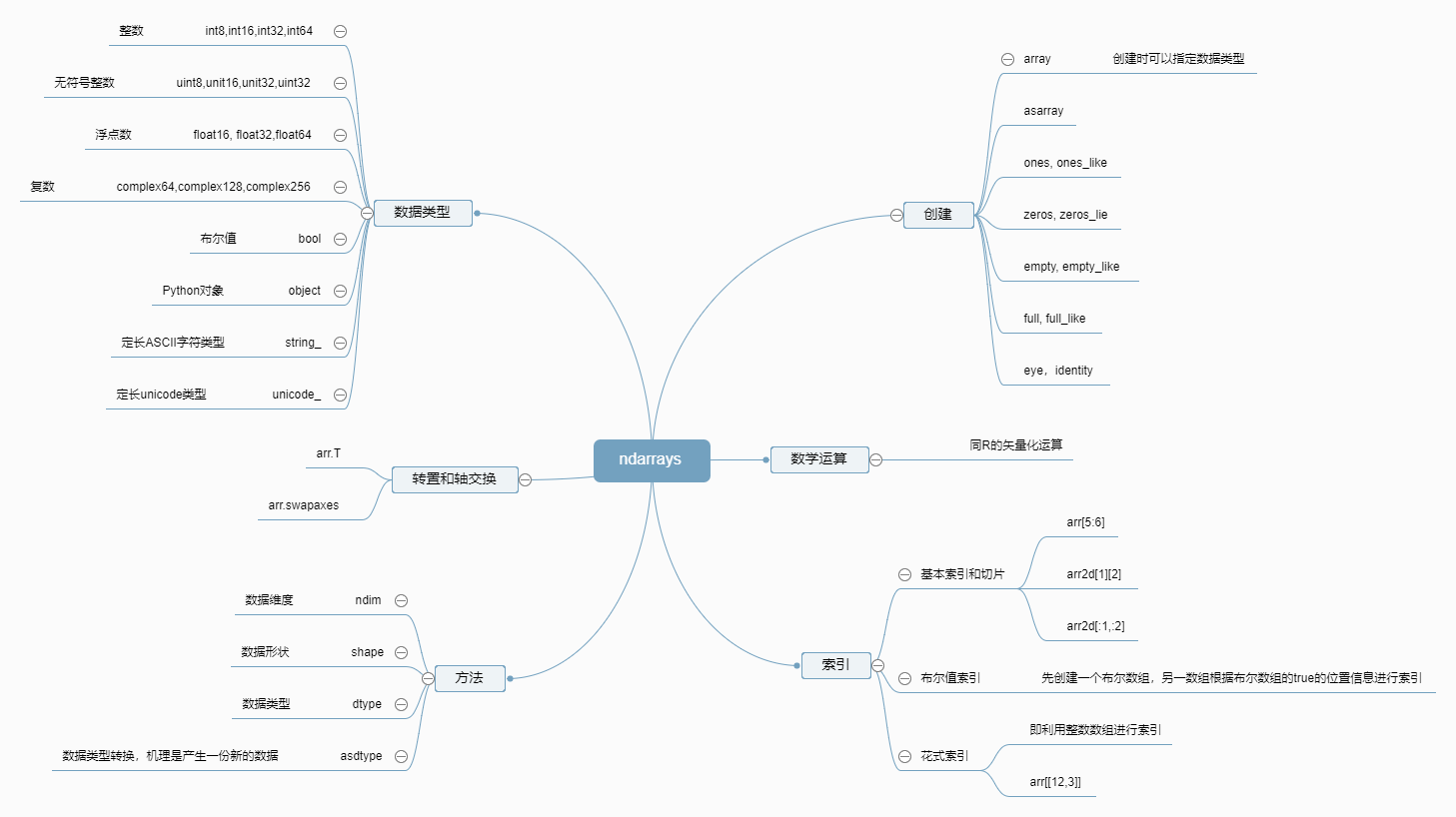
ndarrays
对应的学习笔记
- 关于数据类型, 一般情况下我们没必要对它太过于关注。但是对于大数据集,则需要自己主动声明。因为数据类型(dtype)负责将一块内存解释为特定数据类型,即直接映射到相应的机器表示。在R语言中有一类类型转换函数(例如as.numeric)对数组内的数据类型进行转换,在Numpy则通过dtype.
- 矢量化运算是Numpy用C语言编写,在C语言层面是也是循环。这也是为什么一个数组内的数据类型要一致。
- 我曾经在Python和R的异同(一)里谈到原生Python要想实现R语言的矢量化就要使用列表推导式, 而目前可以用numpy带来的矢量化运算属性了。
- 切片Numpy和原生的Python都有切片的功能, 所谓的切片(slicing) 就是从已有的数组中返回选定的元素,而索引(index)提供指向存储在数组指定位置的数据值的指针。值得注意的是,Python以0为基。和原生Python切片不同,Numpy切片得到只是原始数据的视图(view),也就是浅复制,即你对Numpy切片后的数据进行操作,会影响到原始数据。原因就是Numpy的目的是处理大数据,对大规模的数据进行实际复制会消耗不必要的性能和内存。
- numpy的索引操作和R语言几乎一模一样,分为切片索引,布尔值索引,花式索引。这些都在《R语言实战》基本数据管理章节中的数据集选取子集里面提及。
- 花式索引以及布尔值索引和切片索引不同, 前者将数据复制到新的数组中,而后者是原始数据的视图。 可能原因是前两者的得到数据在原始数据中位置不是整块存放。
- 转置(transpose)是数据重塑的一种特殊形式,返回的是原始数据的视图。数组不仅有transpose方法,还有一个T属性(是np.swapaxes的特殊形式), 这两者在二维数组上是相同的。但是在更高维度上,T属性依旧还是轴对换,transpose方法还需要提供轴编号组成的元组,这个真的是非常难以理解。
更详细的内容见之前写的Numpy:数组合矢量计算
Numpy高级,常用的矢量化运算函数
Numpy提供了大量通用函数(UNIVERSAL FUNCTIONS, UFUNC)进行矢量化运算的函数
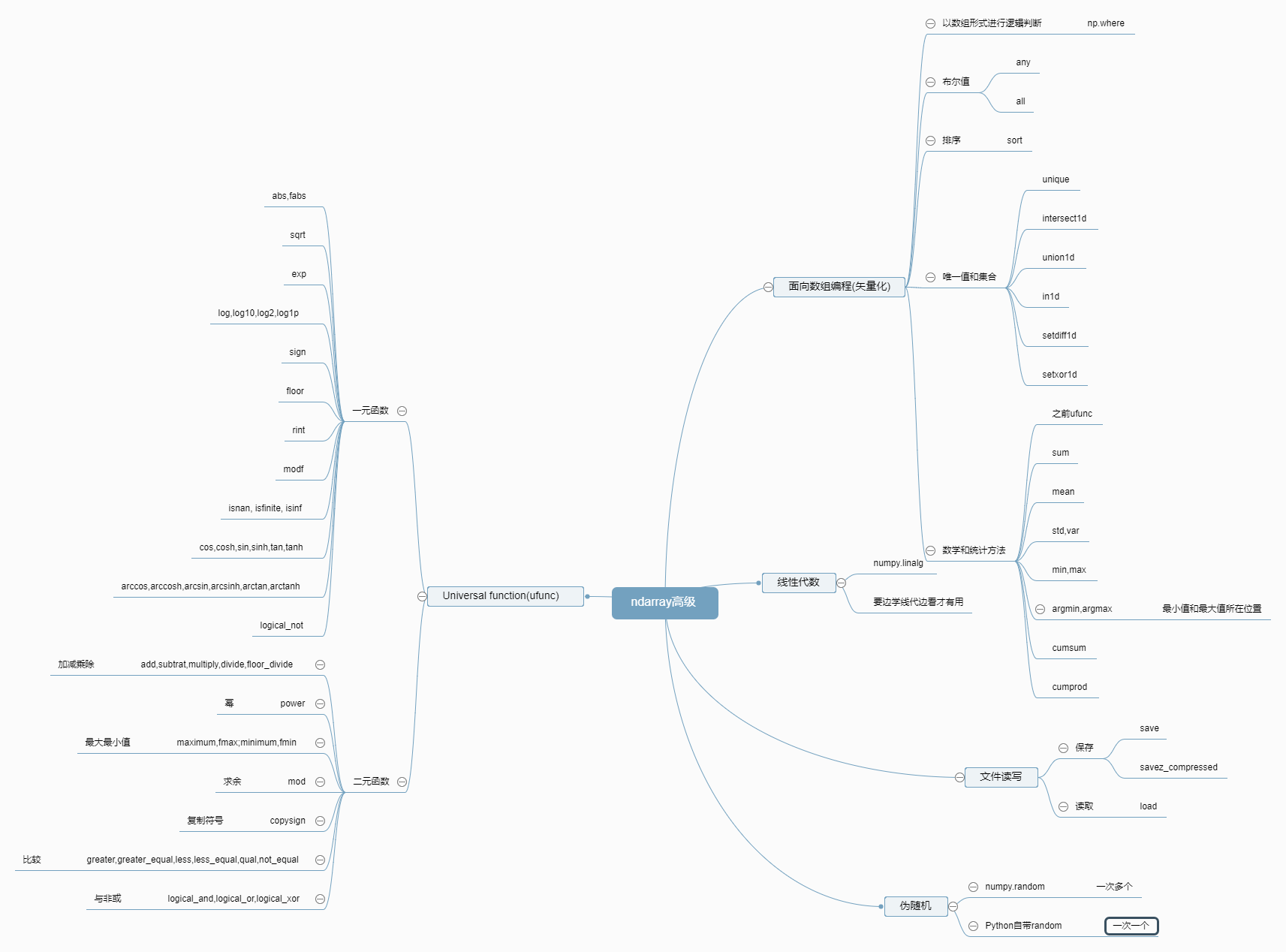
常用函数
基本操作
import numpy as np
a=np.array([0,1,2,3,4]);a #一维数组
array([0, 1, 2, 3, 4])
b = np.array([[0,1,2],[3,4,5]]);b #二维数组
array([[0, 1, 2],
[3, 4, 5]])
c=np.array([[[1],[2],[3],[4]]]); c #三维数组
array([[[1],
[2],
[3],
[4]]])
c.shape
(1, 4, 1)
产生数组的方法
- 均匀分布
np.arange(10)
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
np.arange(1,9,2)
array([1, 3, 5, 7])
- 等间距数组
np.linspace(0,1,6,endpoint=False)
array([ 0. , 0.16666667, 0.33333333, 0.5 , 0.66666667,
0.83333333])
- 常用矩阵
np.ones((3,3)) #全1矩阵
array([[ 1., 1., 1.],
[ 1., 1., 1.],
[ 1., 1., 1.]])
np.zeros((4,4)) #全0矩阵
array([[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.]])
np.eye(5) #对角矩阵
array([[ 1., 0., 0., 0., 0.],
[ 0., 1., 0., 0., 0.],
[ 0., 0., 1., 0., 0.],
[ 0., 0., 0., 1., 0.],
[ 0., 0., 0., 0., 1.]])
np.diag(np.array([1,2,3,4])) #对角矩阵
array([[1, 0, 0, 0],
[0, 2, 0, 0],
[0, 0, 3, 0],
[0, 0, 0, 4]])
np.random.rand(4) #[0,1]均匀分布
array([ 0.80734513, 0.03497501, 0.15490748, 0.35552225])
np.random.randn(4) #符合高斯分布
array([-1.64777274, 0.17147949, -0.61706612, -0.78031714])
基本数据类型
a = np.array([1,2,3,4,5])
a.dtype #查看数据类型
dtype('int32')
b = np.arange(5,dtype=int) #声明数据类型
b.dtype
dtype('int32')
其他数据类型
complex128, bool, S7, int32, int64, unit32, unit64
可视化基础
%matplotlib inline
import matplotlib.pyplot as plt
plt.plot(np.arange(10)) # 直线图
plt.show
一维图
x = np.linspace(1,4,2)
y = np.linspace(5,25,2)
plt.plot(x,y,'-r')
二维矩阵图
image = np.random.rand(30,30)
plt.imshow(image,cmap=plt.cm.hot)
plt.colorbar()
切片和索引
a = np.diag(np.arange(3));a
array([[0, 0, 0],
[0, 1, 0],
[0, 0, 2]])
print(a[1,2],a[1:2])
0 [[0 1 0]]
a[1,2]=2;a
array([[0, 0, 0],
[0, 1, 2],
[0, 0, 2]])
注:切片是原先矩阵上创建的视图,与原先矩阵在内存上的同一位置,使用capy可以强制开一个内存
a = np.arange(10)
b = a[::2]
np.may_share_memory(a,b)
True
a = np.arange(10)
c = a[::2].copy()
np.may_share_memory(a,c)
False

索引和切片
花式索引
np.random.seed(3)
a = np.random.random_integers(0,20,15);a
array([10, 3, 8, 0, 19, 10, 11, 9, 10, 6, 0, 20, 12, 7, 14])
# 使用布尔mask
mask = (a % 3 ==0)
extract_from_a = a[mask];extract_from_a
array([-1, -1, -1, -1, -1, -1])
#使用整数矩阵索引
a = np.arange(0,100,10)
a[[2,3,4,2,4]]
array([20, 30, 40, 20, 40])
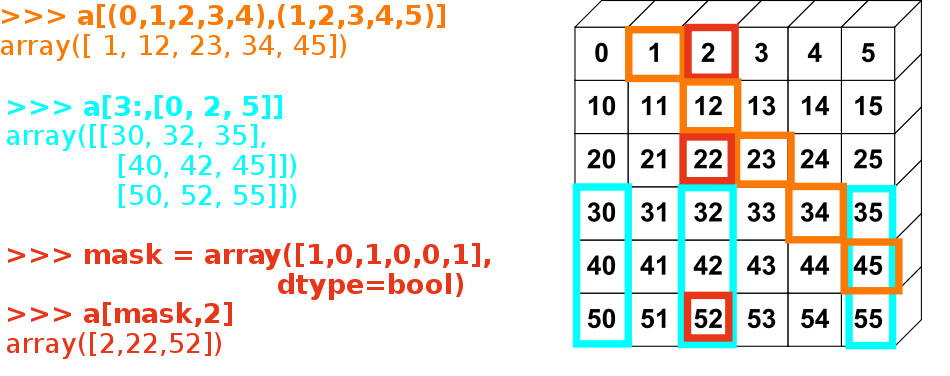
花式索引
数组数值运算
逐个元素运算
a = np.array([1,2,3,4]) # 加一个矢量
a+1
array([2, 3, 4, 5])
b = np.ones(4)+1;b
array([ 2., 2., 2., 2.])
print(b-a,b*a) #数组之间运算
[ 1. 0. -1. -2.] [ 2. 4. 6. 8.]
其他运算
a = np.random.rand(1,3)
b = np.random.rand(1,3)
print(a>b,a==b) 逐个元素比较
[[False False True]] [[False False False]]
np.array_equal(a,b) # 整体比较
False
- 逻辑运算
a = np.array([1, 1, 0, 0], dtype=bool)
b = np.array([1, 0, 1, 0], dtype=bool)
np.logical_or(a, b)
np.logical_and(a, b)
array([ True, False, False, False], dtype=bool)
- 三角函数
a = np.arange(5)
print(np.sin(a),np.log(a),np.exp(a))
[ 0. 0.84147098 0.90929743 0.14112001 -0.7568025 ] [ -inf 0. 0.69314718 1.09861229 1.38629436] [ 1. 2.71828183 7.3890561 20.08553692 54.59815003]
d:\Anaconda3\lib\site-packages\ipykernel\__main__.py:1: RuntimeWarning: divide by zero encountered in log
if __name__ == '__main__':
- 转置
a.T
array([0, 1, 2, 3, 4])
基础归纳
- 求和
x = np.array([1,2,3,4,5])
print(np.sum(x),x.sum())
15 15
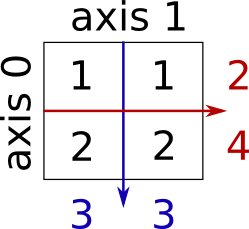
行和列
x = np.array([[1,1],[2,2]])
x.sum(axis=1),x.sum(axis=0)
(array([2, 4]), array([3, 3]))
- 求极值
x = np.arange(10)
print(x.min(),x.argmin()) # 最小值和最小值的索引
0 0
print(x.max(),x.argmax()) # 最大值和最大值的索引
9 9
- 逻辑运算
np.all([True,True,False,False]) #全部为真才是真
False
np.any([True,False,True]) #有一个为真就是真
True
a = np.zeros((100,100))
np.any(a!=0)
False
- 基本统计方法
x = np.array([1, 2, 3, 1])
y = np.array([[1, 2, 3], [5, 6, 1]])
x.mean()
np.median(x)
np.median(y, axis=-1) # last axis
x.std() # full population standard dev.
0.82915619758884995

