视频摘要 视频浓缩(一)
视频摘要又称视频浓缩,是对视频内容的一个简单概括,以自动或半自动的方式,先通过运动目标分析,提取运动目标,然后对各个目标的运动轨迹进行分析,将不同的目标拼接到一个共同的背景场景中,并将它们以某种方式进行组合。视频摘要在视频分析和基于内容的视频检索中扮演着重要角色。
视频录像存在存储数据量大,存储时间长等特点,通过录像寻找线索,获取证据传统的做法是要耗费大量人力、物力以及时间,效率极其低下,以至于错过最佳破案时机。因此在视频监控系统中,对原始视频进行浓缩,可以快速浏览,锁定检索对象,对于公安加快破案速度,提高大案、要案的破案效率具有重要指导意义。(1)
对于企业应用来说,视频摘要与压缩技术可以使企业管理人员在短时间内浏览完视频。在智能手机大行其道的今天,使用视频摘要技术对监控视频进行处理,供手机浏览,既可以节约管理者的时间,又可以节约大量的流量。(2)
对于我来说,现在存在监控录像查阅的实际需求,更重要的是这个问题是“图像处理”的一个典型运用,非常值得研究探索。所以在这里进行研究和实现 一、行业背景和划分 97年CMU的informedia是针对新闻视频的,而MoCA是针对电影的。在监控视频方面以色列briefcam是行业领导者,此外还有哥伦比亚大学的VideoQ和IBM的CueVideo。国内这块处于初级发展状态。 视频摘要可以继续划分为 1、图片关键帧(提取一些视频截图); 2、剪胶片(机器去除静止画面,只显示有目标的画面); 3、空间换时间(不同时间的事件显示在同一画面)。 第3基本上就是能够用于商业运用的视频摘要项目,类似提供这样效果。(注意图上的两组人是不同时间的人)。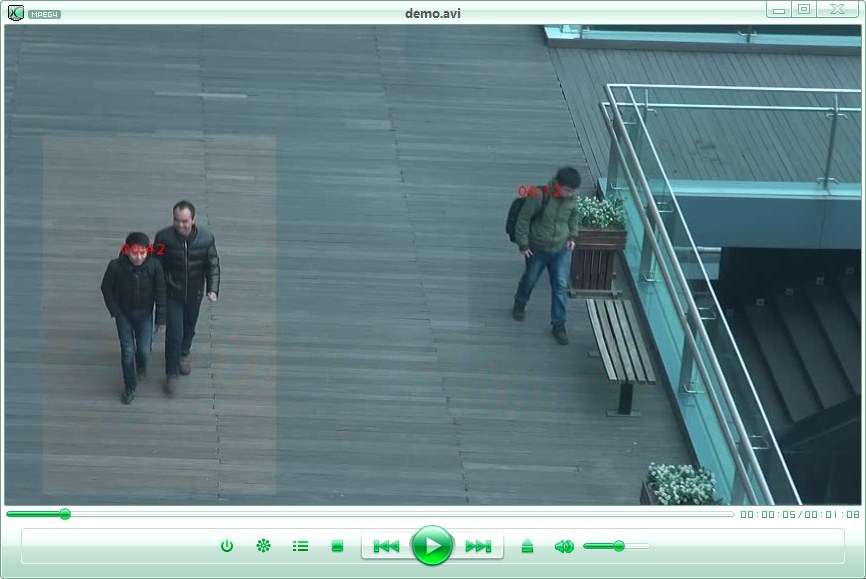 当然了,真实的视频可能是这样的
当然了,真实的视频可能是这样的

我这里实验的背景,首先以768那个avi,然后以营区监控来做(opencv3.0自带视频 768x576.avi)
 二、关键技术和算法流程
(一)背景建模
背景建模的基(you)本(xiao)方法是“背景建模”。能够找到的方法包括(1)均值法(2)中值法(3)滑动平均滤波(4)单高斯(5)混合高斯模型(6)codebook方法。我这里实现(
1)均值法(3)滑动滤波法和(5)混合高斯法
(1)
均值法
对于768*576.avi这个视频来说,是比较经典的监控视频,其特点是主要背景景物、光照等是不变的,前景人物来回走动。处理这种问题,如果想把背景取出来,最直接的方法就是统计一个阶段的帧(比如1到100)中,图像中每个像素在绝大多数时间里面的颜色。
如果直接求平均值,结果是这样的
二、关键技术和算法流程
(一)背景建模
背景建模的基(you)本(xiao)方法是“背景建模”。能够找到的方法包括(1)均值法(2)中值法(3)滑动平均滤波(4)单高斯(5)混合高斯模型(6)codebook方法。我这里实现(
1)均值法(3)滑动滤波法和(5)混合高斯法
(1)
均值法
对于768*576.avi这个视频来说,是比较经典的监控视频,其特点是主要背景景物、光照等是不变的,前景人物来回走动。处理这种问题,如果想把背景取出来,最直接的方法就是统计一个阶段的帧(比如1到100)中,图像中每个像素在绝大多数时间里面的颜色。
如果直接求平均值,结果是这样的
 应该说这种方法是有一定效果的,特别对于背景都是远景,或者变化不是很大的情况,处理的效果比较好。
但是对于前进的图像晃动,效果就不是很理想。
应该说这种方法是有一定效果的,特别对于背景都是远景,或者变化不是很大的情况,处理的效果比较好。
但是对于前进的图像晃动,效果就不是很理想。
 使用第0帧和平均值求absdiff,可以看到那个标识牌是很明显地被认为是前景了。这个效果应该不是太好。
使用第0帧和平均值求absdiff,可以看到那个标识牌是很明显地被认为是前景了。这个效果应该不是太好。
void GoBgModeling(
const
char
* videoFilePath,
const
int frame_num_used, Mat
* bgMat, \
const int size1, const int size2, const int sigma1, const int sigma2 ){
//声明
int frame_no = 0;
Mat frame;
Mat tmp;
VideoCapture pCapture(videoFilePath); //自己选取一段avi视频
if( !pCapture.isOpened()){
printf( "Unable to open video file for background modeling!\n");
return;
}
printf( "Background Modeling...\n");
//逐帧读取视频
Mat matTmp;
while(frame_no < frame_num_used){
pCapture >>frame;
frame.convertTo(frame,CV_32FC3);
frame_no += 1;
if(frame_no == 1){
//初始化
tmp = Mat : :zeros(frame.rows,frame.cols,CV_32FC3);
matTmp = frame.clone();
}
tmp = tmp + frame /frame_num_used;
*bgMat = tmp;
}
bgMat - >convertTo( *bgMat,CV_8UC3);
matTmp.convertTo(matTmp,CV_8UC3);
absdiff(matTmp, *bgMat,matTmp);
printf( "Background Model has been achieved!\n");
}
const int size1, const int size2, const int sigma1, const int sigma2 ){
//声明
int frame_no = 0;
Mat frame;
Mat tmp;
VideoCapture pCapture(videoFilePath); //自己选取一段avi视频
if( !pCapture.isOpened()){
printf( "Unable to open video file for background modeling!\n");
return;
}
printf( "Background Modeling...\n");
//逐帧读取视频
Mat matTmp;
while(frame_no < frame_num_used){
pCapture >>frame;
frame.convertTo(frame,CV_32FC3);
frame_no += 1;
if(frame_no == 1){
//初始化
tmp = Mat : :zeros(frame.rows,frame.cols,CV_32FC3);
matTmp = frame.clone();
}
tmp = tmp + frame /frame_num_used;
*bgMat = tmp;
}
bgMat - >convertTo( *bgMat,CV_8UC3);
matTmp.convertTo(matTmp,CV_8UC3);
absdiff(matTmp, *bgMat,matTmp);
printf( "Background Model has been achieved!\n");
}


 这个结果我看还不如均值。
这个结果我看还不如均值。
/**
*背景建模
*/
void bgModeling( const char * videoFilePath, const int frame_num_used, IplImage * * bgImg, \
const int size1, const int size2, const int sigma1, const int sigma2){
//声明
IplImage * frame = NULL;
CvMat * frameMat = NULL;
CvMat * bgMat = NULL;
CvCapture * pCapture = NULL;
IplImage * framtmp = NULL;
CvMat * mattmp = NULL;
int frame_no = 0;
pCapture = cvCaptureFromFile(videoFilePath); //自己选取一段avi视频
if( !pCapture){
printf( "Unable to open video file for background modeling!\n");
return;
}
if( *bgImg != NULL){ //非空需先清空*bgImg指向的内存
cvReleaseImage(bgImg);
}
printf( "Background Modeling...\n");
//逐帧读取视频
while(frame_no < frame_num_used){
frame = cvQueryFrame(pCapture);
frame_no += 1;
if(frame_no == 1){
//初始化
framtmp = cvCreateImage(cvSize(frame - >width, frame - >height), frame - >depth, frame - >nChannels);
cvCopy(frame,framtmp);
*bgImg = cvCreateImage(cvSize(frame - >width, frame - >height), frame - >depth, frame - >nChannels);
cvCopy(frame, *bgImg);
frameMat = cvCreateMat(frame - >height, frame - >width, CV_32FC3);
bgMat = cvCreateMat(( *bgImg) - >height, ( *bgImg) - >width, CV_32FC3);
cvConvert(frame, frameMat);
cvConvert( *bgImg, bgMat);
continue;
}
//视频帧IplImage转CvMat
cvConvert(frame, frameMat);
//高斯滤波先,以平滑图像
cvSmooth(frame, frame, CV_GAUSSIAN, size1, size2, sigma1, sigma2);
//滑动平均更新背景(求平均)
cvRunningAvg(frameMat, bgMat, ( double) 1 /frame_num_used);
}
cvConvert(bgMat, *bgImg);
printf( "Background Model has been achieved!\n");
//释放内存
cvReleaseCapture( &pCapture);
cvReleaseMat( &frameMat);
cvReleaseMat( &bgMat);
}
*背景建模
*/
void bgModeling( const char * videoFilePath, const int frame_num_used, IplImage * * bgImg, \
const int size1, const int size2, const int sigma1, const int sigma2){
//声明
IplImage * frame = NULL;
CvMat * frameMat = NULL;
CvMat * bgMat = NULL;
CvCapture * pCapture = NULL;
IplImage * framtmp = NULL;
CvMat * mattmp = NULL;
int frame_no = 0;
pCapture = cvCaptureFromFile(videoFilePath); //自己选取一段avi视频
if( !pCapture){
printf( "Unable to open video file for background modeling!\n");
return;
}
if( *bgImg != NULL){ //非空需先清空*bgImg指向的内存
cvReleaseImage(bgImg);
}
printf( "Background Modeling...\n");
//逐帧读取视频
while(frame_no < frame_num_used){
frame = cvQueryFrame(pCapture);
frame_no += 1;
if(frame_no == 1){
//初始化
framtmp = cvCreateImage(cvSize(frame - >width, frame - >height), frame - >depth, frame - >nChannels);
cvCopy(frame,framtmp);
*bgImg = cvCreateImage(cvSize(frame - >width, frame - >height), frame - >depth, frame - >nChannels);
cvCopy(frame, *bgImg);
frameMat = cvCreateMat(frame - >height, frame - >width, CV_32FC3);
bgMat = cvCreateMat(( *bgImg) - >height, ( *bgImg) - >width, CV_32FC3);
cvConvert(frame, frameMat);
cvConvert( *bgImg, bgMat);
continue;
}
//视频帧IplImage转CvMat
cvConvert(frame, frameMat);
//高斯滤波先,以平滑图像
cvSmooth(frame, frame, CV_GAUSSIAN, size1, size2, sigma1, sigma2);
//滑动平均更新背景(求平均)
cvRunningAvg(frameMat, bgMat, ( double) 1 /frame_num_used);
}
cvConvert(bgMat, *bgImg);
printf( "Background Model has been achieved!\n");
//释放内存
cvReleaseCapture( &pCapture);
cvReleaseMat( &frameMat);
cvReleaseMat( &bgMat);
}
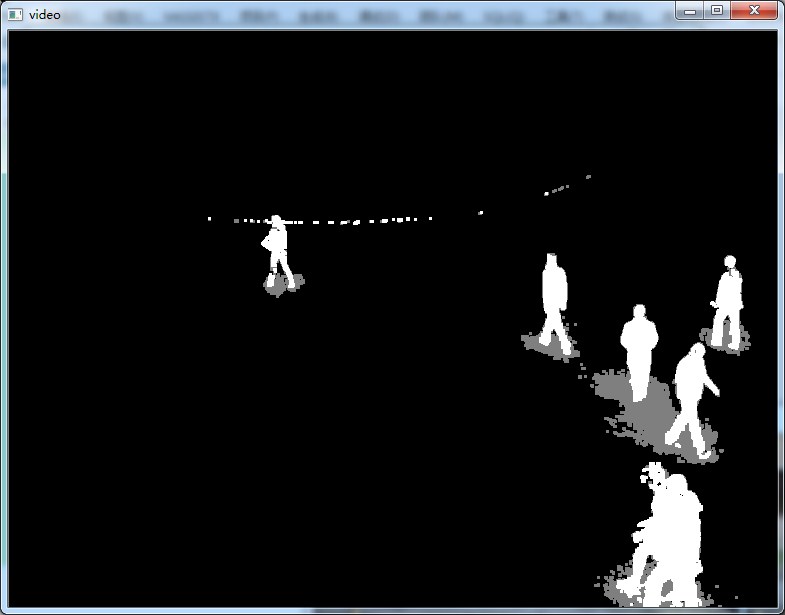 int
_tmain(
int
argc, _TCHAR
*
argv[])
int
_tmain(
int
argc, _TCHAR
*
argv[])
{
Mat bgMat;
// GoBgModeling("1.avi",100,&bgMat);
cv : :VideoCapture capture;
capture.open( "1.avi");
if ( !capture.isOpened())
{
std : :cout << "read video failure" <<std : :endl;
return - 1;
}
cv : :BackgroundSubtractorMOG2 mog;
cv : :Mat foreground;
cv : :Mat background;
cv : :Mat frame;
long frameNo = 0;
while (capture.read(frame))
{
++frameNo;
std : :cout <<frameNo <<std : :endl;
// 运动前景检测,并更新背景
mog(frame, foreground, 0. 001);
// 腐蚀
cv : :erode(foreground, foreground, cv : :Mat());
// 膨胀
cv : :dilate(foreground, foreground, cv : :Mat());
mog.getBackgroundImage(background); // 返回当前背景图像
cv : :imshow( "video", foreground);
cv : :imshow( "background", background);
if (cv : :waitKey( 25) > 0)
{
break;
}
}
return 0;
}
Mat bgMat;
// GoBgModeling("1.avi",100,&bgMat);
cv : :VideoCapture capture;
capture.open( "1.avi");
if ( !capture.isOpened())
{
std : :cout << "read video failure" <<std : :endl;
return - 1;
}
cv : :BackgroundSubtractorMOG2 mog;
cv : :Mat foreground;
cv : :Mat background;
cv : :Mat frame;
long frameNo = 0;
while (capture.read(frame))
{
++frameNo;
std : :cout <<frameNo <<std : :endl;
// 运动前景检测,并更新背景
mog(frame, foreground, 0. 001);
// 腐蚀
cv : :erode(foreground, foreground, cv : :Mat());
// 膨胀
cv : :dilate(foreground, foreground, cv : :Mat());
mog.getBackgroundImage(background); // 返回当前背景图像
cv : :imshow( "video", foreground);
cv : :imshow( "background", background);
if (cv : :waitKey( 25) > 0)
{
break;
}
}
return 0;
}


![论文赏析[EMNLP19]如何在Transformer中融入句法树信息?这里给出了一种解决方案(二)](https://ucc.alicdn.com/pic/developer-ecology/a488c4b851914fdfb2c686dd8ea02a50.png?x-oss-process=image/resize,h_160,m_lfit)