// L14
//基于ORB实现线性融合
#include "stdafx.h"
#include <vector>
#include <opencv2/core.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/imgproc.hpp>
#include <opencv2/imgproc/imgproc_c.h>
#include <opencv2/core/core.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/features2d/features2d.hpp>
#include <opencv2/calib3d/calib3d.hpp>
using namespace std;
using namespace cv;
int _tmain(int argc, _TCHAR* argv[])
{
cv::Mat image1= cv::imread("parliament1.bmp",1);
cv::Mat image2= cv::imread("parliament2.bmp",1);
if (!image1.data || !image2.data)
return 0;
std::vector<cv::KeyPoint> keypoints1, keypoints2;
//寻找ORB特针点对
Ptr<DescriptorMatcher> descriptorMatcher;
// Match between img1 and img2
vector<DMatch> matches;
// keypoint for img1 and img2
vector<KeyPoint> keyImg1, keyImg2;
// Descriptor for img1 and img2
Mat descImg1, descImg2;
//创建ORB对象
Ptr<Feature2D> b = ORB::create();
//两种方法寻找特征点
b->detect(image1, keyImg1, Mat());
// and compute their descriptors with method compute
b->compute(image1, keyImg1, descImg1);
// or detect and compute descriptors in one step
b->detectAndCompute(image2, Mat(),keyImg2, descImg2,false);
//匹配特征点
descriptorMatcher = DescriptorMatcher::create("BruteForce");
descriptorMatcher->match(descImg1, descImg2, matches, Mat());
Mat index;
int nbMatch=int(matches.size());
Mat tab(nbMatch, 1, CV_32F);
for (int i = 0; i<nbMatch; i++)
{
tab.at<float>(i, 0) = matches[i].distance;
}
sortIdx(tab, index, cv::SORT_EVERY_COLUMN +cv::SORT_ASCENDING);
vector<DMatch> bestMatches;
for (int i = 0; i<60; i++)
{
bestMatches.push_back(matches[index.at<int>(i, 0)]);
}
Mat result;
drawMatches(image1, keyImg1, image2, keyImg2, bestMatches, result);
std::vector<Point2f> obj;
std::vector<Point2f> scene;
for( int i = 0; i < (int)bestMatches.size(); i++ )
{
obj.push_back( keyImg1[ bestMatches[i].queryIdx ].pt );
scene.push_back( keyImg2[ bestMatches[i].trainIdx ].pt );
}
//直接调用ransac,计算单应矩阵
Mat H = findHomography( obj, scene, CV_RANSAC );
//绘制仿射结果
std::vector<Point2f> obj_corners(4);
std::vector<Point2f> scene_corners(4);
obj_corners[0] = Point(0,0);
obj_corners[1] = Point( image1.cols, 0 );
obj_corners[2] = Point( image1.cols, image1.rows );
obj_corners[3] = Point( 0, image1.rows );
perspectiveTransform( obj_corners, scene_corners, H);
//-- Draw lines between the corners (the mapped object in the scene - image_2 )
Point2f offset( (float)image1.cols, 0);
line( result, scene_corners[0] + offset, scene_corners[1] + offset, Scalar(0, 255, 0), 4 );
line( result, scene_corners[1] + offset, scene_corners[2] + offset, Scalar( 0, 255, 0), 4 );
line( result, scene_corners[2] + offset, scene_corners[3] + offset, Scalar( 0, 255, 0), 4 );
line( result, scene_corners[3] + offset, scene_corners[0] + offset, Scalar( 0, 255, 0), 4 );
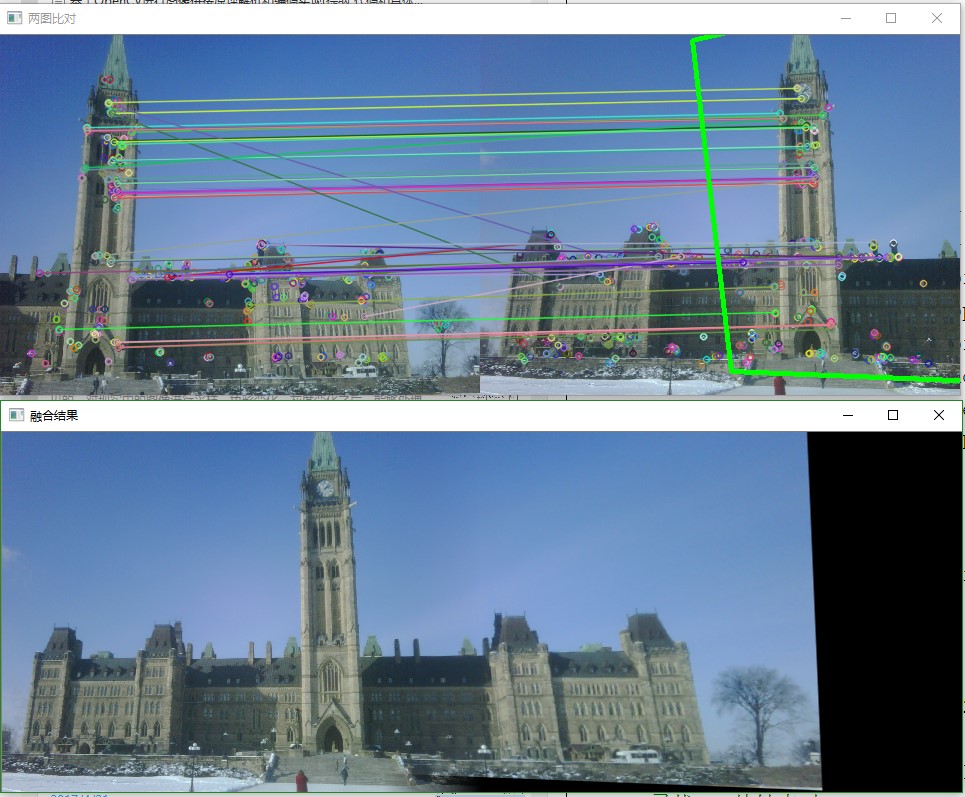
imshow("两图比对", result);//初步显示结果
//通过透视变换转换到一起
cv::Mat resultAll;
cv::warpPerspective(image1, // input image
resultAll, // output image
H, // homography
cv::Size(2*image1.cols,image1.rows)); // size of output image
cv::Mat resultback;
resultAll.copyTo(resultback);
// Copy image 1 on the first half of full image
cv::Mat half(resultAll,cv::Rect(0,0,image2.cols,image2.rows));
image2.copyTo(half);
//进行liner的融合
Mat outImage;//待输出图片
resultAll.copyTo(outImage);//图像拷贝
double dblend = 0.0;
int ioffset =image2.cols-100;//col的初始定位
for (int i = 0;i<100;i++)
{
outImage.col(ioffset+i) = image2.col(ioffset+i)*(1-dblend) + resultback.col(ioffset+i)*dblend;
dblend = dblend +0.01;
}
waitKey();
imshow("融合结果",outImage);
return 0;
}
目前方向:图像拼接融合、图像识别 联系方式:jsxyhelu@foxmail.com

