标题中的英文首字母大写比较规范,但在python实际使用中均为小写。
爬取伯乐在线网站所有文章的详情页面
1.网页持久化
1.1 新建爬虫工程
新建爬虫工程命令:scrapy startproject BoleSave2
进入爬虫工程目录命令:cd BoleSave2
新建爬虫文件命令:scrapy genspider save blog.jobbole.com
1.2 编辑save.py文件
网页持久化只需要编辑爬虫文件就可以,下面是save.py文件的代码。
第13行dirName变量的值可以设置网页文件保存的位置,例如:
dirName = "d:/saveWebPage"将网页文件保存在D盘的saveWebPage文件夹中。
可以根据个人情况进行修改,不能将其设置为工程所在文件夹,因为Pycharm对工程内大量新文件进行索引会导致卡顿。
import scrapy
import os
import re
def reFind(pattern,sourceStr,nth=1):
if len(re.findall(pattern,sourceStr)) >= nth:
return re.findall(pattern,sourceStr)[nth-1]
else:
return 1
def saveWebPage(response,id,prefix):
# 持久化目录页面
dirName = "d:/saveWebPage2"
if not os.path.isdir(dirName):
os.mkdir(dirName)
html = response.text
fileName = "%s%05d.html" %(prefix,id)
filePath = "%s/%s" %(dirName, fileName)
with open(filePath, 'w', encoding="utf-8") as file:
file.write(html)
print("网页持久化保存为%s文件夹中的%s文件" %(dirName,fileName))
class SaveSpider(scrapy.Spider):
name = 'save'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/']
def parse(self, response):
pageNum = response.xpath("//a[@class='page-numbers']/text()")[-1].extract()
for i in range(1, int(pageNum) + 1):
url = "http://blog.jobbole.com/all-posts/page/{}/".format(i)
yield scrapy.Request(url, callback=self.parse1)
def parse1(self, response):
page_id = int(reFind("\d+", response.url))
saveWebPage(response,page_id,'directory')
#获得详情页面的链接,并调用下一级解析函数
article_list = response.xpath("//div[@class='post floated-thumb']")
count = 0
for article in article_list:
url = article.xpath("div[@class='post-meta']/p/a[1]/@href").extract_first()
count += 1
article_id = (page_id - 1) * 20 + count
yield scrapy.Request(url,self.parse2,meta={'id':article_id})
def parse2(self, response):
saveWebPage(response,response.meta['id'],'detail')
1.3 编辑settings.py文件
改变并发请求数量,取消变量CONCURRENT_REQUESTS的注释,并改变值为96。
CONCURRENT_REQUESTS = 96
1.4 运行结果
运行命令:scrapy crawl save
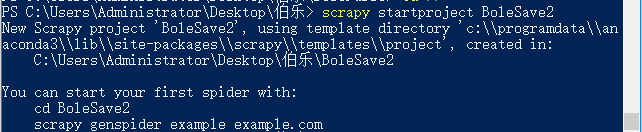
559个目录页面,11172个详情页面,两种页面相加共有11731个页面。
而网页持久化保存的文件个数也是11731个,说明已经完成页面持久化。
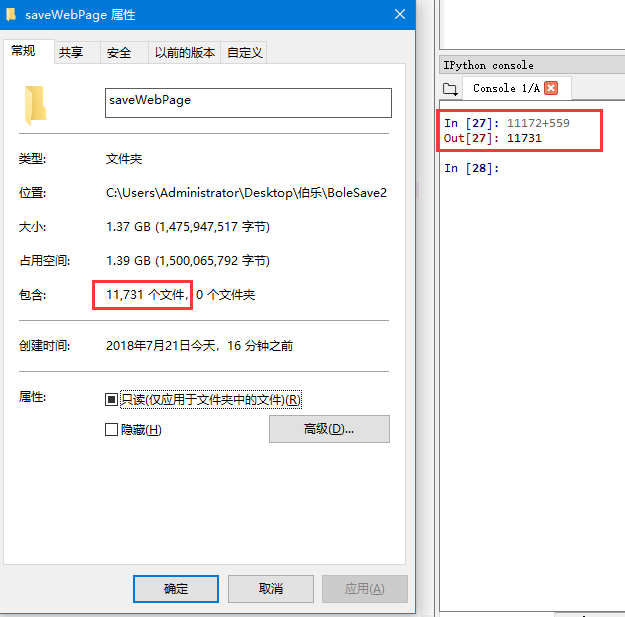
从下图中可以看出开始时间与结束时间相差12分钟,则11731个页面持久化耗时12分钟。
持久化速度:977页/分,16.29页/秒
2.解析伯乐在线文章详情页面
已经把11731个网页文件打包成一个压缩文件,下载链接: https://pan.baidu.com/s/19MDHdwrqrSRTEgVWA9fMzg 密码: x7nk
2.1 新建爬虫工程
新建爬虫工程命令:scrapy startproject BoleParse2
进入爬虫工程目录命令:cd BoleParse2
新建爬虫文件命令:scrapy genspider parse blog.jobbole.com
2.2 在Pycharm中导入工程
导入工程的按钮位置如下图所示:
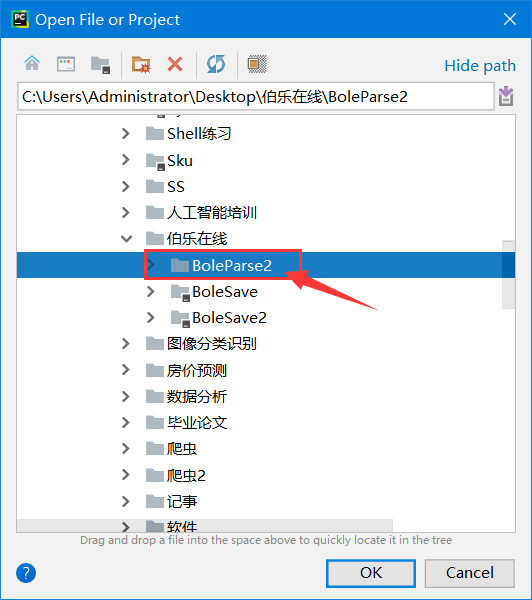
选中工程文件夹,然后点击OK,如下图所示:
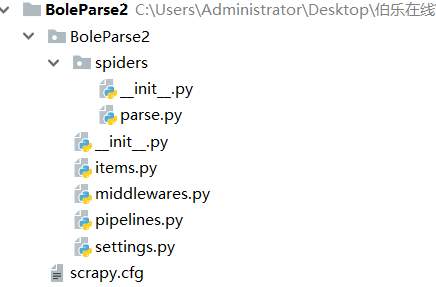
工程文件夹的结构如下图所示:
2.3 编写items.py文件
共有12个字段,文章识别码id、标题title、发布时间publishTime、分类category、摘要digest、图片链接imgUrl、详情链接detailUrl、原文出处originalSource、内容content、点赞数favourNumber、收藏数collectNumber、评论数commentNumber。
import scrapy
from scrapy import Field
class Boleparse2Item(scrapy.Item):
id = Field()
title = Field()
publishTime = Field()
category = Field()
digest = Field()
imgUrl = Field()
detailUrl = Field()
originalSource = Field()
content = Field()
favourNumber = Field()
collectNumber = Field()
commentNumber = Field()
2.4 编写parse.py文件
parse函数解析目录页面,得到7个字段的值添加进item中,并通过response携带meta传递给下一级解析函数。
parse2函数解析详情页面,通过item = response.meta['item']得到已经解析一部分内容的item,再对网页解析得到剩余的5个字段,最后yield item将item传给管道进行处理。
注意:修改第13行变量dirName的值
import scrapy
import re
from ..items import Boleparse2Item
def reFind(pattern,sourceStr,nth=1):
if len(re.findall(pattern,sourceStr)) >= nth:
return re.findall(pattern,sourceStr)[nth-1]
else:
return ''
class ArticleSpider(scrapy.Spider):
name = 'parse'
dirName = "E:/saveWebPage2"
start_urls = []
for i in range(1,560):
fileName = "directory%05d.html" %i
filePath = "file:///%s/%s" %(dirName,fileName)
start_urls.append(filePath)
def parse(self, response):
def find(xpath, pNode=response):
if len(pNode.xpath(xpath)):
return pNode.xpath(xpath).extract()[0]
else:
return ''
article_list = response.xpath("//div[@class='post floated-thumb']")
pattern = self.dirName + "/directory(\d+).html"
page_id_str = reFind(pattern,response.url)
page_id = int(page_id_str)
count = 0
for article in article_list:
count += 1
item = Boleparse2Item()
item['id'] = (page_id - 1) * 20 + count
item['title'] = find("div[@class='post-meta']/p[1]/a/@title",article)
pTagStr = find("div[@class='post-meta']/p",article)
item['publishTime'] = re.search("\d+/\d+/\d+",pTagStr).group(0)
item['category'] = find("div[@class='post-meta']/p/a[2]/text()",article)
item['digest'] = find("div[@class='post-meta']/span/p/text()",article)
item['imgUrl'] = find("div[@class='post-thumb']/a/img/@src",article)
item['detailUrl'] = find("div[@class='post-meta']/p/a[1]/@href", article)
fileName = "detail%05d.html" %item['id']
nextUrl = "file:///%s/%s" %(self.dirName,fileName)
yield scrapy.Request(nextUrl,callback=self.parse1,meta={'item':item})
def parse1(self, response):
def find(xpath, pNode=response):
if len(pNode.xpath(xpath)):
return pNode.xpath(xpath).extract()[0]
else:
return ''
item = response.meta['item']
item['originalSource'] = find("//div[@class='copyright-area']"
"/a[@target='_blank']/@href")
item['content'] = find("//div[@class='entry']")
item['favourNumber'] = find("//h10/text()")
item['collectNumber'] = find("//div[@class='post-adds']"\
"/span[2]/text()").strip("收藏").strip()
commentStr = find("//a[@href='#article-comment']/span")
item['commentNumber'] = reFind("(\d+)\s评论",commentStr)
yield item
2.5 编写pipelines.py文件
采用数据库连接池提高往数据库中插入数据的效率。
下面代码有2个地方要修改:1.数据库名;2.连接数据库的密码。
设置数据库编码方式,default charset=utf8mb4创建表默认编码为utf8mb4,因为插入字符可能是4个字节编码。
item['content'] = my_b64encode(item['content'])将网页内容进行base64编码防止发生异常。
from twisted.enterprise import adbapi
import pymysql
import time
import os
import base64
def my_b64encode(content):
byteStr = content.encode("utf-8")
encodeStr = base64.b64encode(byteStr)
return encodeStr.decode("utf-8")
class Boleparse2Pipeline(object):
def __init__(self):
self.params = dict(
dbapiName='pymysql',
cursorclass=pymysql.cursors.DictCursor,
host='localhost',
db='bole',
user='root',
passwd='...your password',
charset='utf8mb4',
)
self.tableName = "article_details"
self.dbpool = adbapi.ConnectionPool(**self.params)
self.startTime = time.time()
self.dbpool.runInteraction(self.createTable)
def createTable(self, cursor):
drop_sql = "drop table if exists %s" %self.tableName
cursor.execute(drop_sql)
create_sql = "create table %s(id int primary key," \
"title varchar(200),publishtime varchar(30)," \
"category varchar(30),digest text," \
"imgUrl varchar(200),detailUrl varchar(200)," \
"originalSource varchar(500),content mediumtext," \
"favourNumber varchar(20)," \
"collectNumber varchar(20)," \
"commentNumber varchar(20)) " \
"default charset = utf8mb4" %self.tableName
cursor.execute(create_sql)
self.dbpool.connect().commit()
def process_item(self, item, spider):
self.dbpool.runInteraction(self.insert, item)
return item
def insert(self, cursor, item):
try:
if len(item['imgUrl']) >= 200:
item.pop('imgUrl')
item['content'] = my_b64encode(item['content'])
fieldStr = ','.join(['`%s`' % k for k in item.keys()])
valuesStr = ','.join(['"%s"' % v for v in item.values()])
insert_sql = "insert into %s(%s) values(%s)"\
% (self.tableName,fieldStr, valuesStr)
cursor.execute(insert_sql)
print("往mysql数据库中插入第%d条数据成功" %item['id'])
except Exception as e:
if not os.path.isdir("Log"):
os.mkdir("Log")
filePath = "Log/" + time.strftime('%Y-%m-%d-%H-%M.log')
with open(filePath, 'a+') as file:
datetime = time.strftime('%Y-%m-%d %H:%M:%S')
logStr = "%s log:插入第%d条数据发生异常\nreason:%s\n"
file.write(logStr % (datetime, item['id'], str(e)))
def close_spider(self, spider):
print("程序总共运行%.2f秒" % (time.time() - self.startTime))
2.6 编写settings.py文件
BOT_NAME = 'BoleParse2'
SPIDER_MODULES = ['BoleParse2.spiders']
NEWSPIDER_MODULE = 'BoleParse2.spiders'
ROBOTSTXT_OBEY = False
CONCURRENT_REQUESTS = 96
CONCURRENT_ITEMS = 200
ITEM_PIPELINES = {
'BoleParse2.pipelines.Boleparse2Pipeline': 300,
}
2.7 运行结果
运行命令:scrapy crawl parse
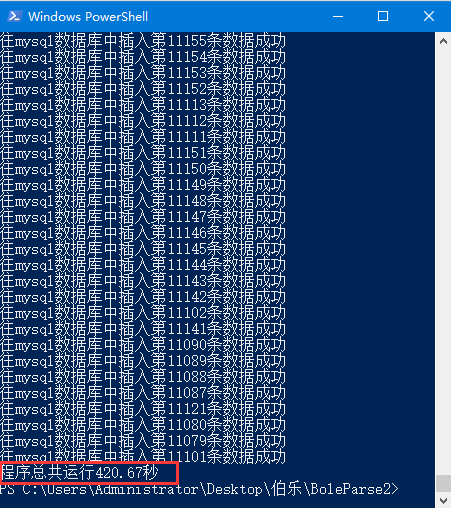
从上图可以看出,插入数据总共需要花费420秒,即25条/秒,1558条/分。
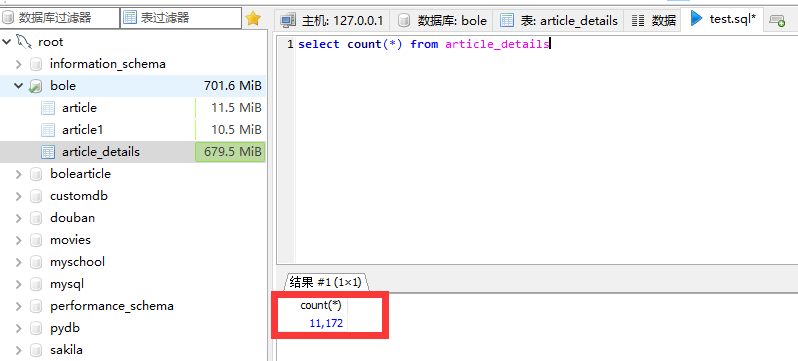
从上图可以看出插入数据总共使用硬盘容量679.5M,条数共11172条,成功插入每一条数据。
3.查找插入异常原因
mysql中查看字符集命令:show variables like "character%"
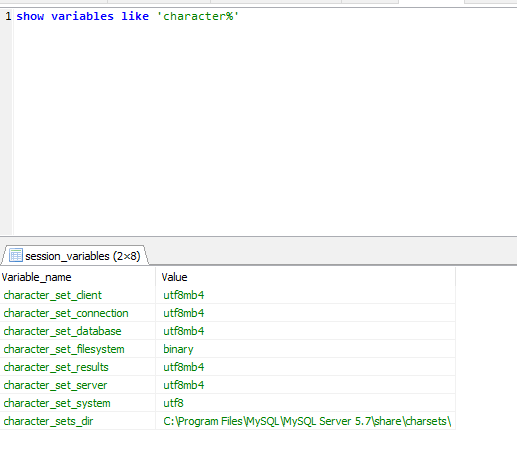
content中有组合字符\"导致发生SQL syntax error