DRC简介
DRC(Data Replication Center)是我在阿里听过的一个概念,它的业务域是支持异构数据库实时同步,数据记录变更订阅服务。为跨域实时同步、实时增量分发、异地双活、分库分表等场景提供产品级的解决方案。支持异地多活、大数据实时抽取、搜索实时更新数据、数据表结构重构、多视图数据存储、大屏实时刷新等。DRC在阿里服务了数万个实时通道,已经成为阿里的基础设施,重要性不言而喻。
DRC需要保障数据库的事务一致性,包括DDL(表结构变更)也可以进行同步或过滤。而DBA天生就在这个坑里,绝对不能让主备不一致、或事务不完整,哪怕只是一条数据。而且DBA迫切希望以后不用通知下游了,让DRC自动适配主备切换或拆库。
DRC必须具备的三大特性:1)稳定性,所有环节必须支持HA; 2)实时性(<1S) 3)一致性,数据同步前后必须保证数据的一致性。
我们公司对DRC的需求场景:
- MySQL原生复制
- 大数据实时抽取
- 搜索实时数据
- 数据表结构重构(拆表、合表等)
- 多视图数据存储
- 大屏实时刷新
- 缓存更新
- 支持Oracle、mysql两种数据源数据相互转换
技术选型预研
数据同步中间件开源的主要有canal、databus、kettle、otter四种,下面进行简单的对比说明。
canal:canal是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL。
databus:2011年在LinkedIn正式进入生产系统,2013年开源,Java开发。databus是一个实时的、可靠的、支持事务的、保持一致性的数据变更抓取系统,同canal也是监听mysql的binlog。 Databus通过挖掘数据库日志的方式,将数据库变更实时、可靠的从数据库拉取出来,业务可以通过定制化client实时获取变更。
kettle: kettle可以实现从不同数据源(excel、数据库、文本文件等)获取数据,然后将数据进行整合、转换处理,可以再将数据输出到指定的位置(excel、数据库、文本文件)等;是B/S架构,多用于数仓作业。
otter:阿里巴巴旗下的另一款开源项目,始于中美数据同步需求,纯Java开发。可以理解为canal+ETL,对数据抽取进行了扩展,加入自由门、反查等功能,拓展了已经无法从binlog获取的数据来源。同时提供页面的ETL编辑配置功能,方便快速实现带逻辑的业务数据同步。
Otter的功能更加强大,满足DRC所有特性需求。在otter上进行二次开发成本是最低的。所以我们公司选择基于otter进行二次开发,打造内部的DRC系统。
DRC架构
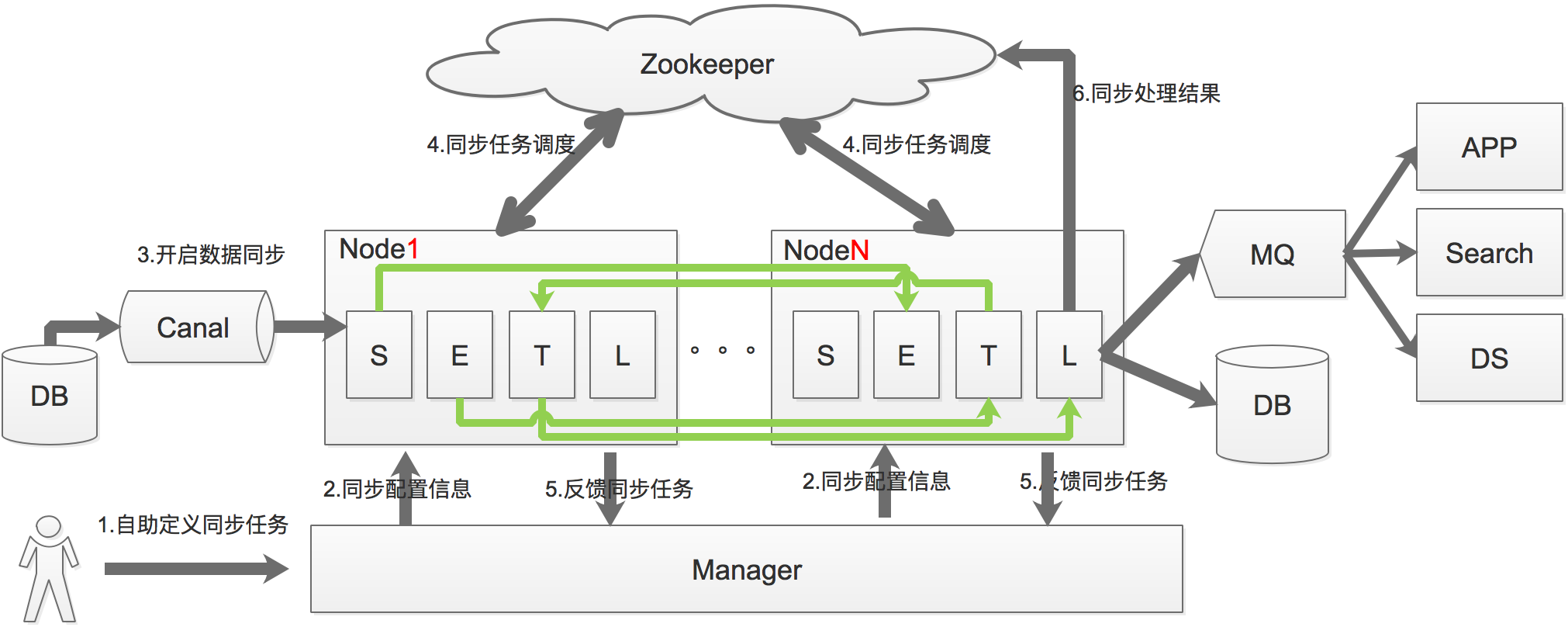
数据同步过程可以分为Select-->Extract、Transform-->Load四个过程,也就是上图中的S、E、T、L,通过将这4个步骤进行服务拆分,每个服务都具有自己的线程池。通过S、L过程的串型,保证数据的一致性,E、T过程的并行提升系统处理的性能。
滑动窗口
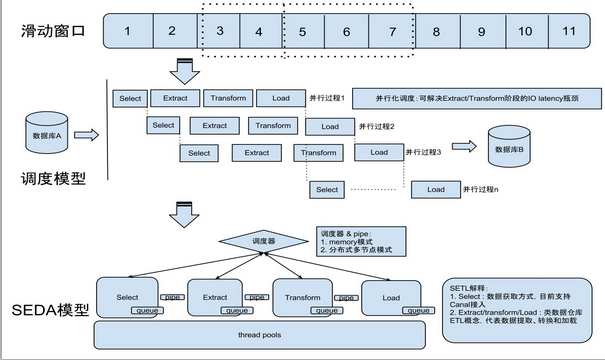
说明:
- otter通过select模块串行获取canal的批数据,注意是串行获取,每批次获取到的数据,就会有一个全局标识,otter里称之为processId.
- select模块获取到数据后,将其传递给后续的ETL模型. 这里E和T模块会是一个并行处理
- 将数据最后传递到Load时,会根据每批数据对应的processId,按照顺序进行串行加载。 ( 比如有一个processId=2的数据先到了Load模块,但会阻塞等processId=1的数据Load完成后才会被执行)
简单一点说,Select/Load模块会是一个串行机制来保证binlog处理的顺序性,Extract/Transform会是一个并行,加速传输效率。
并行度
类似于tcp滑动窗口大小,比如整个滑动窗口设置了并行度为5时,只有等第一个processId Load完成后,第6个Select才会去获取数据。
Otter源码解读
otter核心model关系图
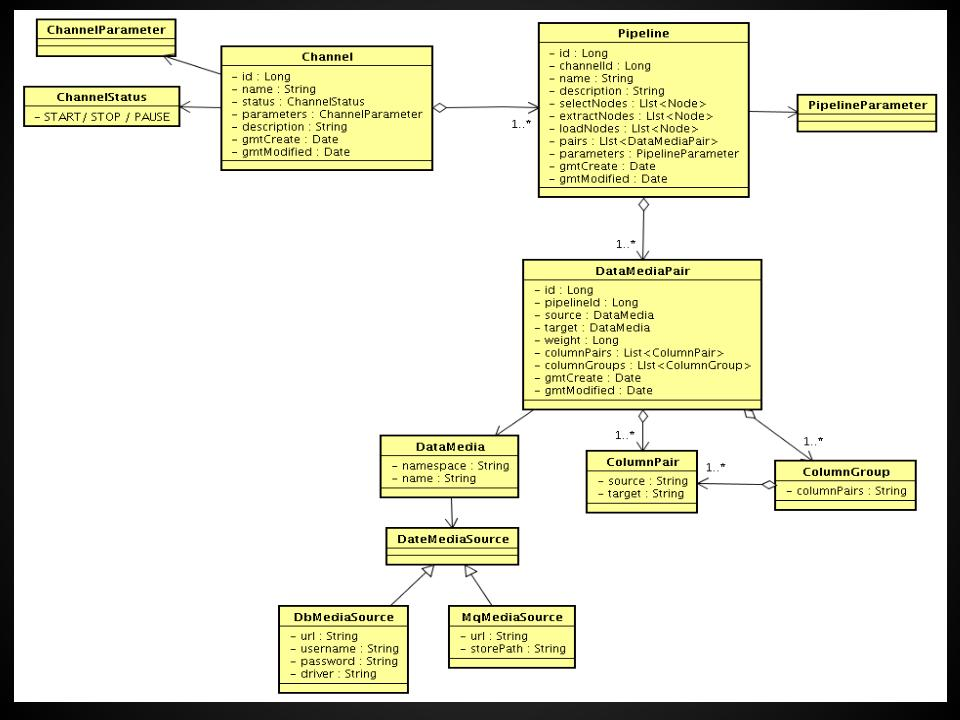
Pipeline:从源端到目标端的整个过程描述,主要由一些同步映射过程组成。可以对应为一个数据库(当然也可以一个实例上的多个库配同一个pipeline)。
Channel:同步通道,单向同步中一个Pipeline组成,在双向同步中由两个Pipeline组成。一个数据库实例一个Channel,一个channel对应一个canal。
DataMediaPair:根据业务表定义映射关系,比如源表和目标表,字段映射,字段组等。
DataMedia : 抽象的数据介质概念,可以理解为数据表/mq队列定义
DataMediaSource : 抽象的数据介质源信息,补充描述DataMedia
ColumnPair : 定义字段映射关系
otter工程结构如下
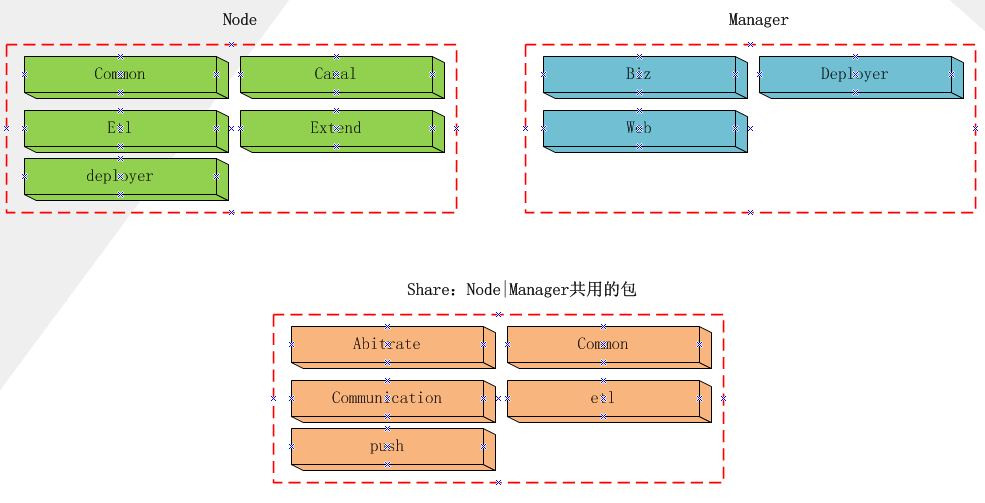
包含三部分:Share | Node | Manager。 其中Share是Node和Manager共享工程,并不是独立部署的节点。Node和Manager是独立部署的。
Node:独立部署的节点,执行SETL过程的服务节点,拥有独立的JVM,数据同步的过程实际上都发生在Node之间。
Manager:管理的节点,逻辑上只有一个(一个Manager管理多个Node节点),如果不考虑HA的话。负责管理同步的数据定义,包括数据源、Channel、PipeLine、数据映射等,各个Node节点从Manager处获取并执行这些信息。另外还有监控等信息。
Share各个子系统的说明:
- Common: 公共内容定义
- Arbitrate: 用于Manager与Node之间、Node与Node之间的调度、S.E.T.L几个过程的调度等;
- Communication: 数据传输的底层,上层的Pipe、一些调度等都是依赖于Communication的,简单点说它负责点对点的Event发送和接收,封装了dubbo、rmi两种方式的调用
- Etl:实际上并不负责ETL的具体实现,只是一些接口&数据结构的定义而已,包括开放给用户自定义Extract阶段处理逻辑的接口,具体的实现在Node里面。
Node各个子系统的说明:
- Common:公共内容定义
- Canal: Canal的封装,Otter采用的是Embed的方式引入Canal(Canal有Embed和独立运行两种模式)
- Deployer:内置Jetty的启动
- Etl: S.E.T.L 调度、处理的实现,是Otter最复杂、也是最核心的部分。
Manager各个子系统的说明:
- Biz:管理页面对应的业务逻辑实现,包含我们公司web工程规范中的manager、dal两个工程的内容。
- Web:页面请求入口,执行controller逻辑。otter采用的是阿里内部的webx框架。
- Deployer:内置Jetty的启动,同时包含页面的template等
核心类设计
Communication的设计
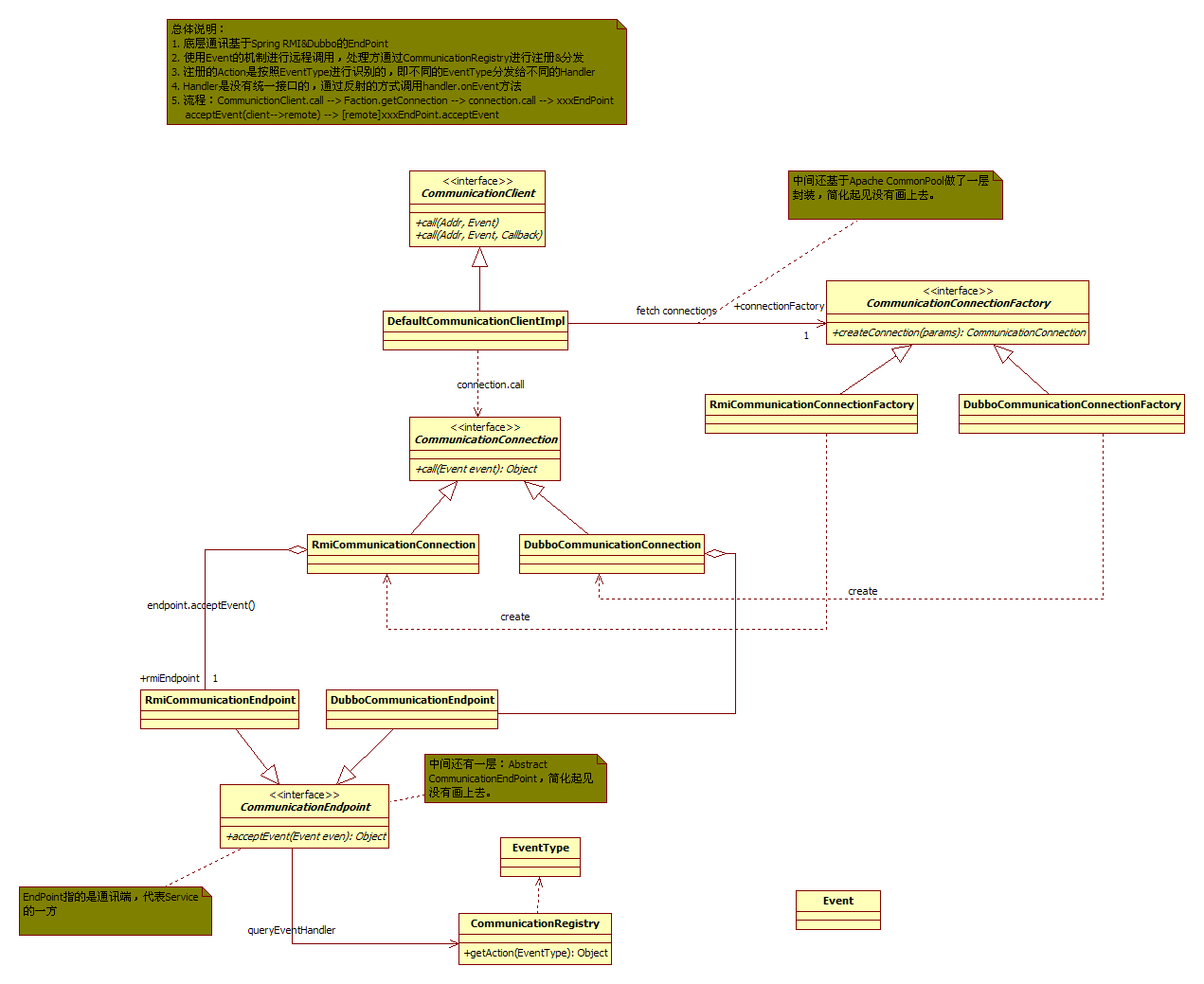
比较关键的部分图中已经使用注释的方式进行了说明。理解Communication的关键在于Event的模式+EndPoint方式进行远程调用。
Node-common关于Node节点管理的机制
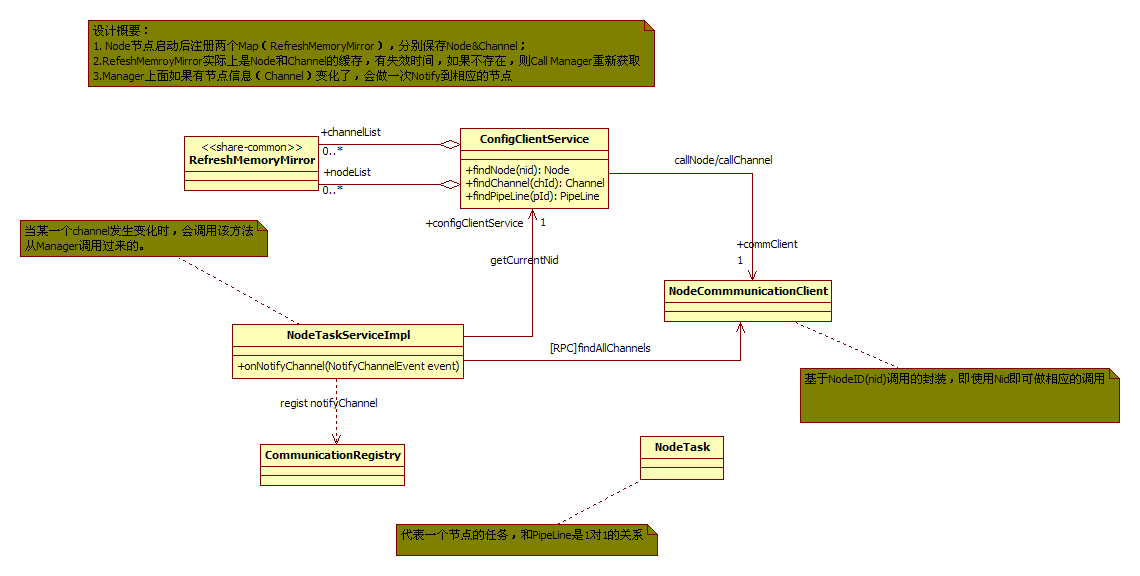
节点是在Manager上面管理的,但是Node节点实际上是需要与其他的Node节点及manager通讯的,因此NodeList(Group内的其他节点)的信息在Node节点是需要相互知道的。 Otter采用的是类似于Lazy+cache的模式管理的。即:
1)真正使用到的时候再考虑去Manager节点取过来;
2)取过来以后暂存到本地内存,但是伴随着一个失效机制(失效机制的检查是不单独占用线程的,这个同学们可以注意一下,设计框架的时候需要尽可能做到这一点)
PipeLine设计
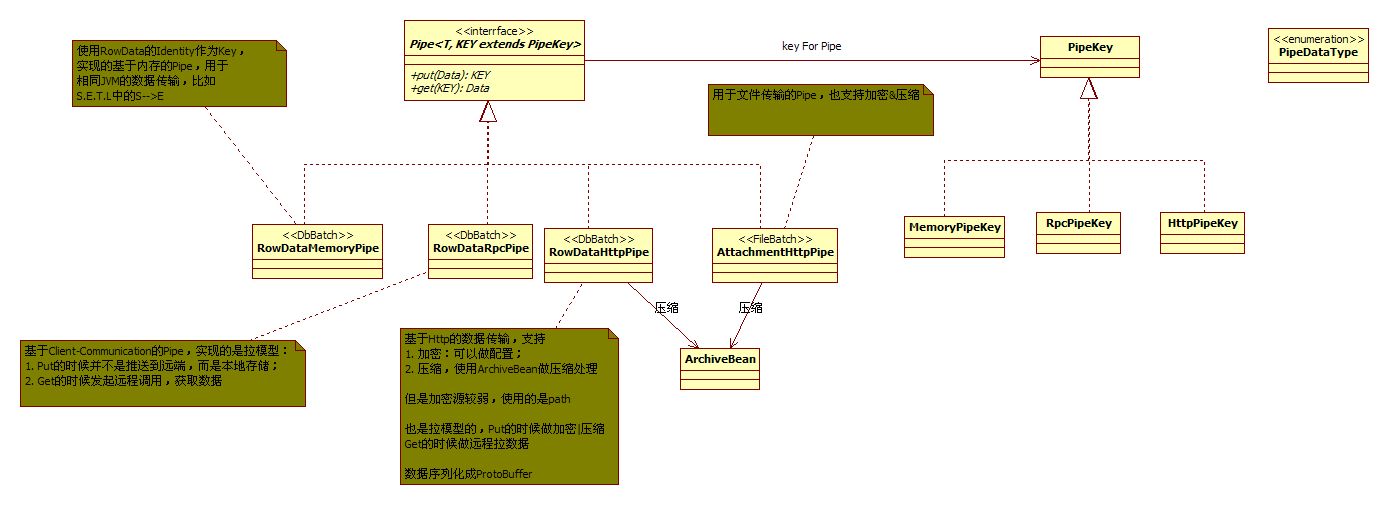
PipeLine主要的操作就是Put/Get,对于S-->E、T-->L,还有节点内部的处理,可以使用基于Memory的PipeLine,对于远程的节点数据传输(比如E-->T的跨节点传输),使用的是RPC或者Http,这里面需要注意的几个事项,图中已经做了说明:
- 数据传输实际上是Pull的模式,并不是Push的模式,即数据准备好以后等待另外一端需要的时候再传输;
- 数据的序列化采用的是ProtoBuf(https://code.google.com/p/protobuf/),也可以做加密传输,但是使用的Key是Path,一般性的安全需求可以满足,但是如果传输的数据是非常敏感的,还是用专线的好;
- 压缩也是在Pipe这一层做掉的,具体就不展开了。
SETL中的Select过程
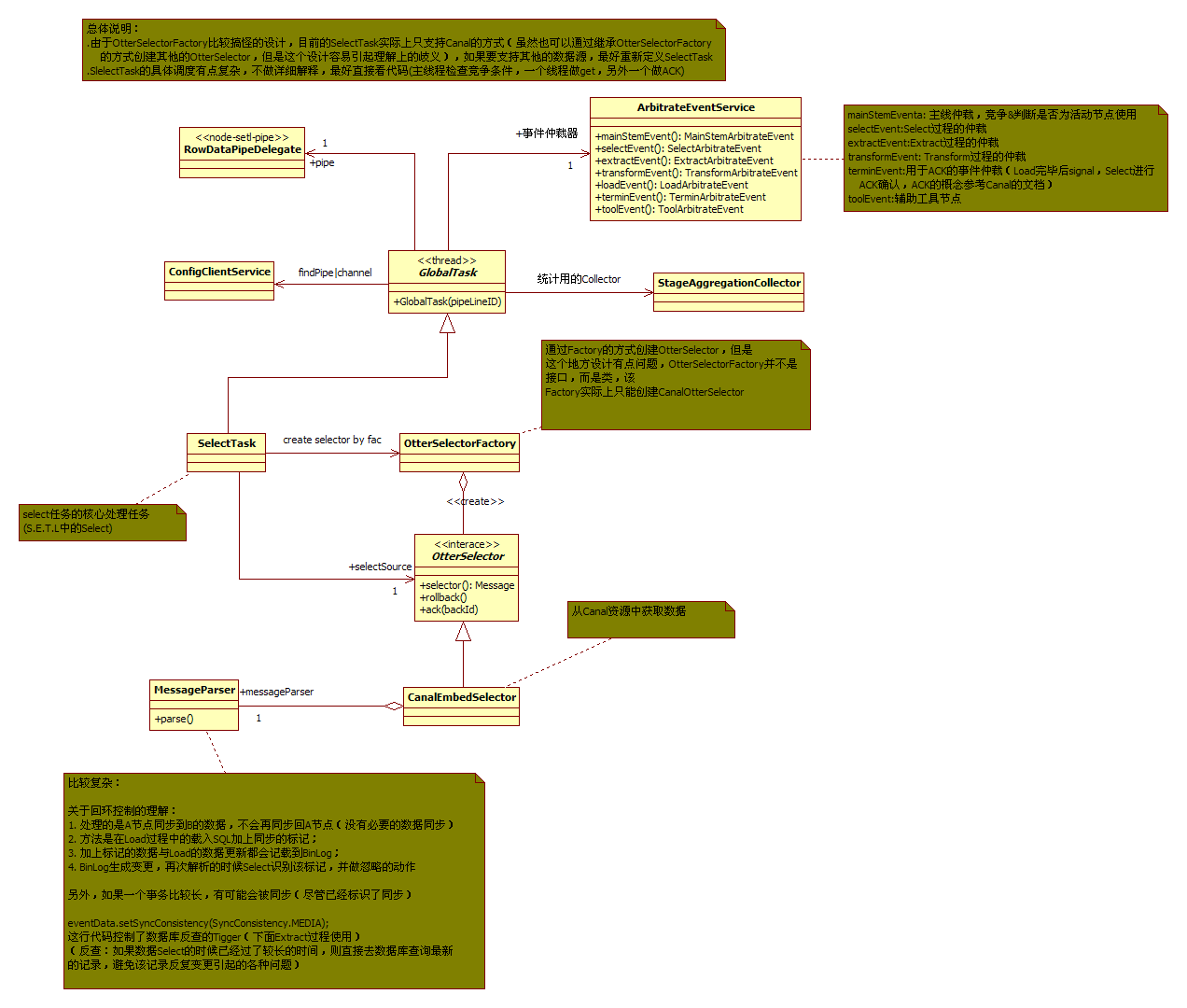
每个SETL过程的设计基本上都是由xxxTask + OtterXXXFactroy + OtterXXX的设计方式,但是细节上差别比较大。
Select过程是需要串行的(需要保证顺序性),但是为了尽可能提高效率,将Get和ACK(Canal的滑动窗口)分在两个线程里面去做,依据的假定就是绝大多数数据是不需要回滚的,但是一旦回滚了,代价就比较大(Otter的官方文档有相关的说明)。Otter采用的是at last once策略,不丢失一条消息,但是异常场景下可能存在消息重发,因为有数据库有主键限制,对数据库同步没影响,业务使用方需要自己保证幂等。
SETL中的Extract过程
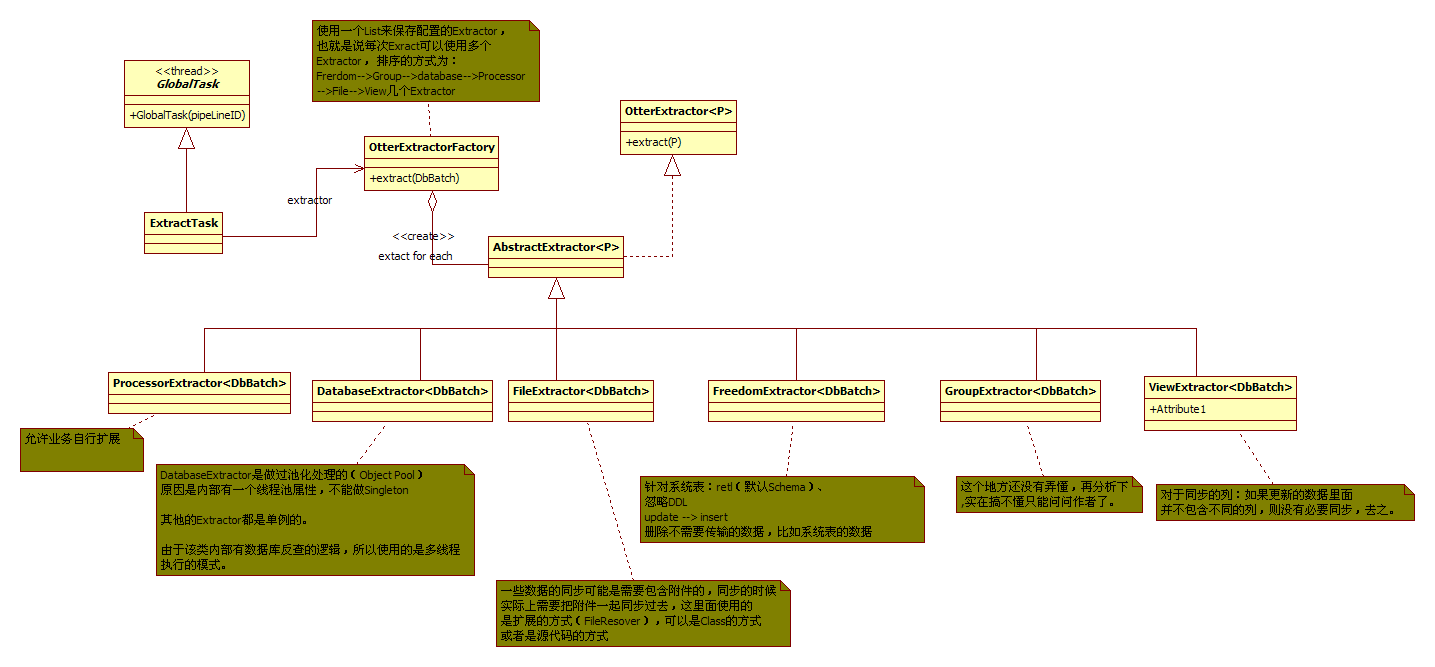
这里的OtterExtractorFactory与OtterExtractor并不是选择一个合适的Extractor处理,而是搭建成一个职责链(但设计上并不完全是,个人觉得设计成职责链更合适一些),每个Extractor顺序处理。
SETL中的Transform过程
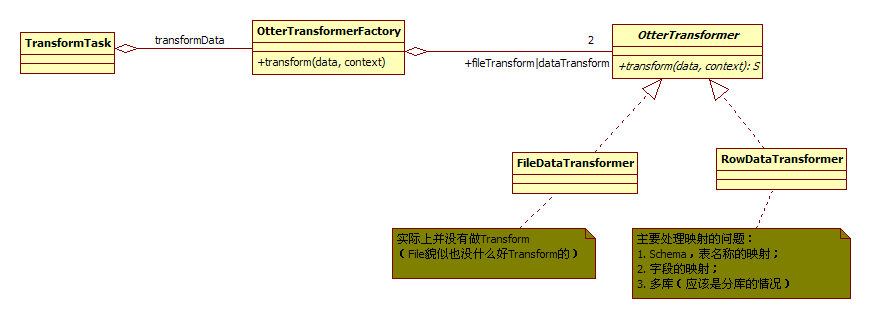
Transform实际上解决的就是异构数据的映射,在Transform这个节点做相应的转换。
SETL中的Load过程
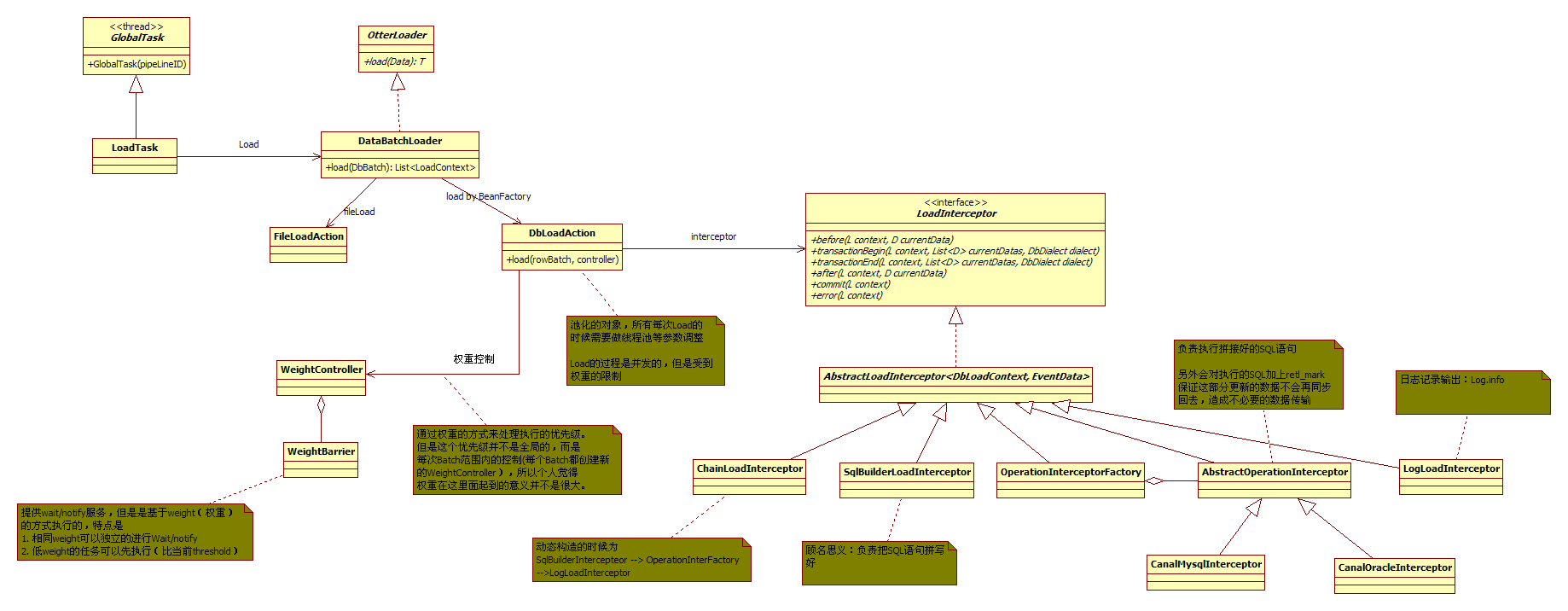
1)Load过程是并发执行的,但是受Weight的控制(并非全局的);
2)在Load过程中包含了打标记的过程(与Select过程是呼应的,即Load打的标记会被Select过程所识别,然后不会同步回去了,这一点官方文档有相关说明
SETL时序
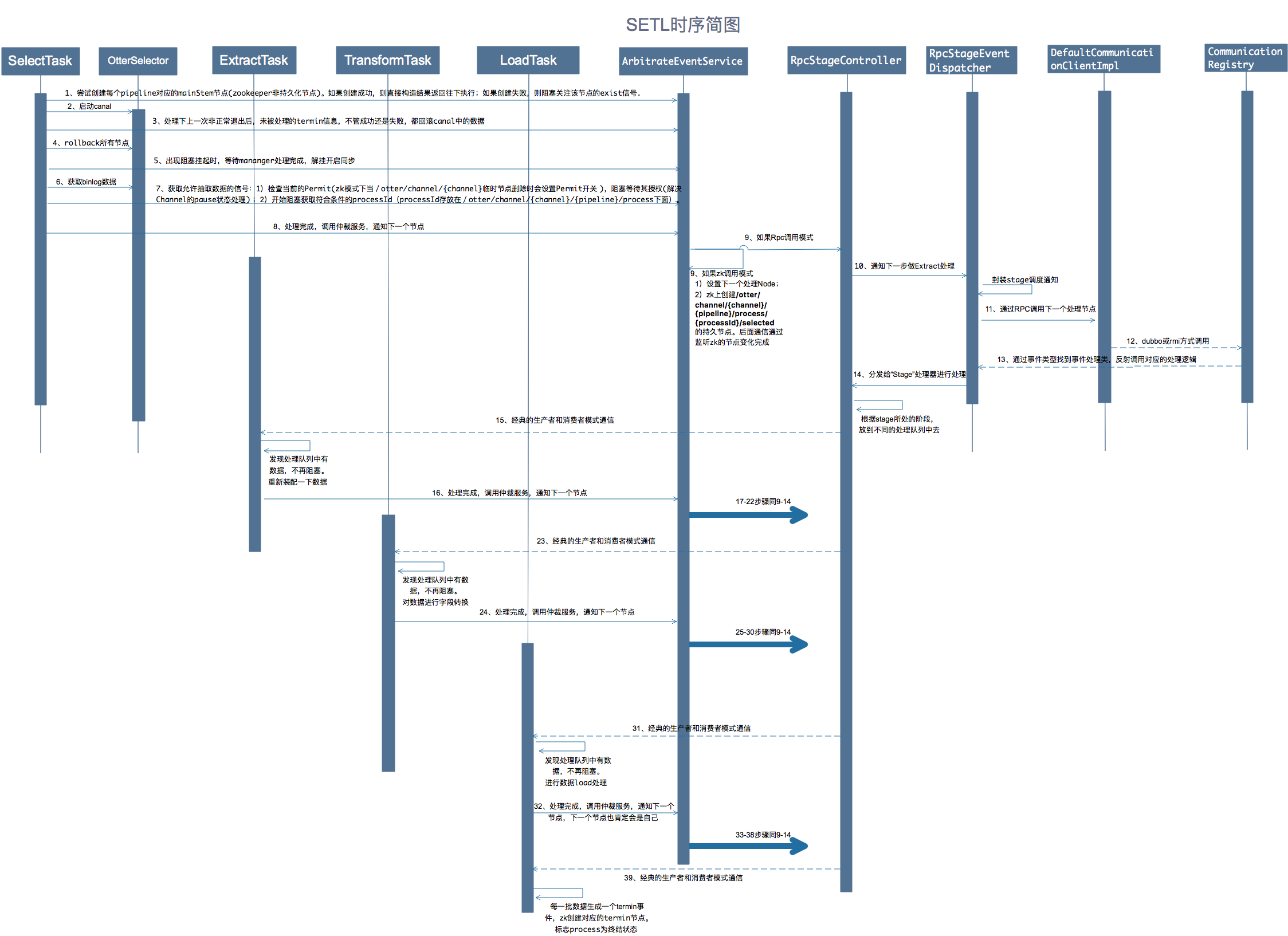
我们做的大改造
模型扩展
在支撑业务重构的数据表重构时,业务方的需求可以归为下面4类:
- 多表中的多条记录 合成 一个表中的一条记录(N:1)
- 一个表中的一条记录 拆成 多表中的多条记录(1:N)
- 单表中的多个字段 合成 一个字段(n:1)
- 单表中的1个字段 拆成 多个字段(1:n)
上面分别从“表”、“列”两个维度进行“拆”和“合”,数据重构其实还有一个维度,就是“行”,一行记录拆分成多行、多行记录合成一行。
由于“行”维度的拆分需求比较少,这一次没有对这种需求进行支持。但是可以部分参考“表”、“列”的拆合,已经在一定层度上支持了。其中一行记录拆分成多行需要放弃原来的行主键(同时update、delete需要在Extract阶段进行主键修复),像
“一个表中的一条记录 拆成 多表中的多条记录”,只不过这个“多表”映射为“同一个表”;其中多行记录合成一行可以参考“多表中的多条记录 合成 一个表中的一条记录”思想去做,Extract阶段的反查对象变成自己。
原生的otter设计是为了一个表到另一个表的同步,支持对数据的修改,支持简单的列名的转化(支持字段的删减)。没有考虑一个表到多个表的同步,以及字段的新增。
一个表到多个表的同步支持
otter设计是为了一个表到另一个表的同步,始终是一条binlog记录。而一个表到多个表的同步,需要将一条binlog记录在某个阶段进行copy分发,我们将这个阶段选为Transform阶段。在E阶段,各个目标表根据自己对数据的要求进行加工处理,E阶段取的是各个目标表处理结果的并集。在Transform阶段根据每个目标表的字段需求,各取所需,生成多条记录。Transform的拆分逻辑如下:
for (EventData eventData : rowBatch.getDatas()) {
// 处理eventData
Long tableId = eventData.getTableId();
Pipeline pipeline = configClientService.findPipeline(identity.getPipelineId());
List<DataMediaPair> dataMediaPairs = ConfigHelper.findDataMediaPairByMediaId(pipeline, tableId);
List<Object> itemList = new ArrayList<Object>();
Object item = null;
for (DataMediaPair pair : dataMediaPairs) {
//每个目标库数据源过滤不属于自己该处理的数据
if (!pair.getSource().getId().equals(tableId)) { // 过滤tableID不为源的同步
continue;
}
。。。。。。
//每个目标库只处理路由到自己的数据
boolean isSelfNameSpace = false;
for(String value:ConfigHelper.parseMode(pair.getTarget().getNamespace()).getMultiValue()){
if(value.equalsIgnoreCase(slotNode.getDataSourceName())){
isSelfNameSpace = true;
}
}
if(isSelfNameSpace==false){
continue;
}
OtterTransformer translate = lookup(pair.getSource(), pair.getTarget());
// 进行转化
item = translate.transform(eventData, new OtterTransformerContext(identity, pair, pipeline),slotNode);
}else{
OtterTransformer translate = lookup(pair.getSource(), pair.getTarget());
// 进行转化
item = translate.transform(eventData, new OtterTransformerContext(identity, pair, pipeline));
}
if(item != null){
itemList.add(item);
}
}
if (itemList.size() == 0) {
continue;
}
// 合并结果
merge(identity, result, itemList);
}
新增字段的支持
原先的otter支持原表到目标表映射过程中的字段删减和字段内容修改(在Extract阶段可以通过嵌入脚本进行字段内容修改),对字段的新增没有支持。
我们通过对字段映射页面进行扩展,支持手动新增字段,然后在Extract阶段对新增字段进行内容填充,完成对新增字段的支持。
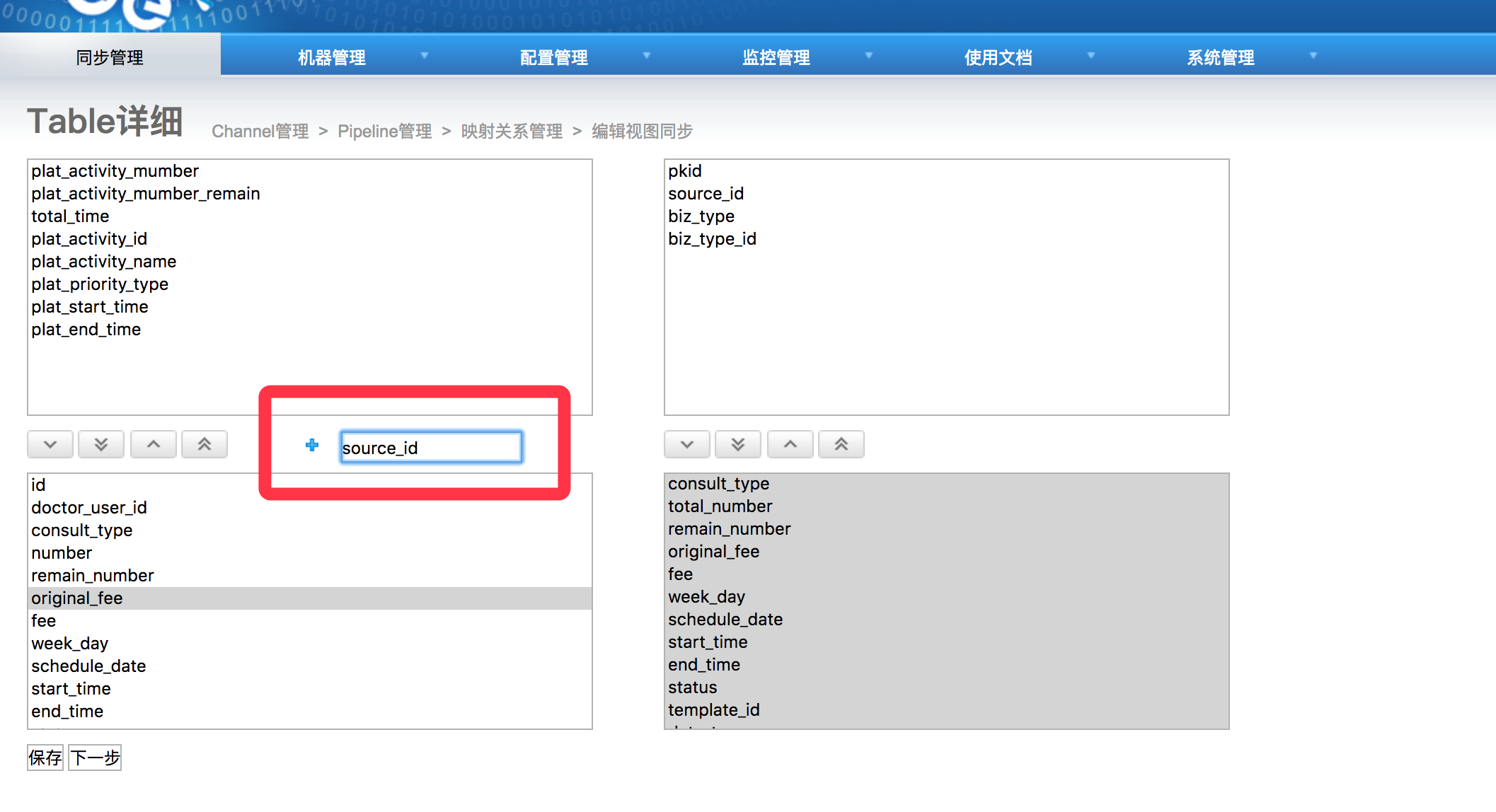
通过在原表增加目标表不存在的字段,完成“虚拟”字段填入,在后续步骤完成“虚拟”字段到实字段的映射配置。在Extract阶段对“虚拟”增字段进行内容填充,将“虚拟”变成实字段。
分库分表支持
原生的otter是不支持分库分表的,分库分表已经不属于Otter数据同步的业务域,但是分库分表的支持又是大公司数据同步过程中不可避免。也可能是otter开源版本把分库分表的支持给阉割了。
我们公司业务在改造过程中,涉及单库单表到分库分表的数据同步需求。
1)我们对DataMediaPair进行了扩展,支持简单分库分表配置。
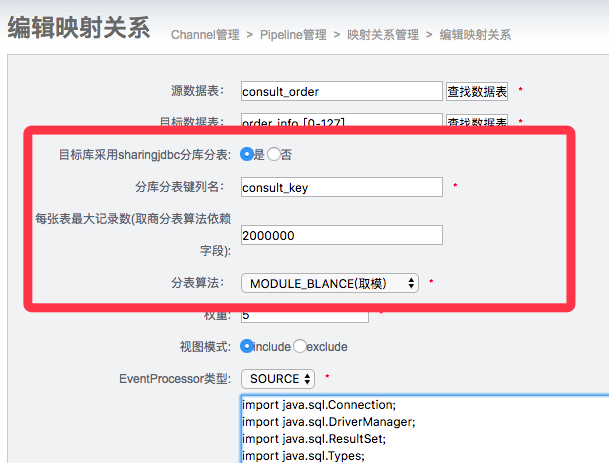
2)我们在transform阶段进行了逻辑扩展。当表的转换映射中目标表是需要分库分表时,这时会加载目标表的分库分表路由器(分库分表的库表是通过解析pipeline下面所有目标表配置而来,分表算法由用户的配置而来)。
for (EventData eventData : rowBatch.getDatas()) {
// 处理eventData
Long tableId = eventData.getTableId();
Pipeline pipeline = configClientService.findPipeline(identity.getPipelineId());
List<DataMediaPair> dataMediaPairs = ConfigHelper.findDataMediaPairByMediaId(pipeline, tableId);
List<Object> itemList = new ArrayList<Object>();
Object item = null;
for (DataMediaPair pair : dataMediaPairs) {
//每个目标库数据源过滤不属于自己该处理的数据
if (!pair.getSource().getId().equals(tableId)) { // 过滤tableID不为源的同步
continue;
}
//如果映射的目标表是分库分表
if(true == pair.getIsTargetSharingJDBC()){
//根据管道信息获取路由器
SlotRouter<String> slotRouter = configClientService.findSlotRouterByPipelineId(identity.getPipelineId(), pair.getId());
//获取分表键的值
List<EventColumn> allColumns = new ArrayList<EventColumn>();
allColumns.addAll(eventData.getKeys());
allColumns.addAll(eventData.getColumns());
String shardValue = null;
int shardValueType = 0;
//获取分库分表路由字段的值
for(EventColumn eventColumn : allColumns){
if(eventColumn.getColumnName().equalsIgnoreCase(pair.getSharingColumn())){
shardValue = eventColumn.getColumnValue();
shardValueType = eventColumn.getColumnType();
break;
}
}
//如果分库分表字段为null
if(shardValue == null){
throw new RuntimeException("分表字段:{"+pair.getSharingColumn()+"}为null,eventData:{"+eventData+"}");
}
SlotNode slotNode = slotRouter.slotRouter(shardValue,shardValueType);
//每个目标库只处理路由到自己的数据
boolean isSelfNameSpace = false;
for(String value:ConfigHelper.parseMode(pair.getTarget().getNamespace()).getMultiValue()){
if(value.equalsIgnoreCase(slotNode.getDataSourceName())){
isSelfNameSpace = true;
}
}
if(isSelfNameSpace==false){
continue;
}
OtterTransformer translate = lookup(pair.getSource(), pair.getTarget());
// 进行转化
item = translate.transform(eventData, new OtterTransformerContext(identity, pair, pipeline),slotNode);
}else{
OtterTransformer translate = lookup(pair.getSource(), pair.getTarget());
// 进行转化
item = translate.transform(eventData, new OtterTransformerContext(identity, pair, pipeline));
}
if(item != null){
itemList.add(item);
}
}
if (itemList.size() == 0) {
continue;
}
// 合并结果
merge(identity, result, itemList);
}
//构建每个映射的路由算法缓存
slotRouterCache = new RefreshMemoryMirror<String, SlotRouter>(DEFAULT_PERIOD, new ComputeFunction<String, SlotRouter>() {
public SlotRouter apply(String key, SlotRouter oldValue) {
if(StringUtils.isBlank(key) || key.split(Pipeline_Pair_Connector).length != 2){
return null;
}
Long pipelineId = Long.parseLong(key.split(Pipeline_Pair_Connector)[0]);
Long pairId = Long.parseLong(key.split(Pipeline_Pair_Connector)[1]);
Pipeline pipeline = findPipeline(pipelineId);
if(pipeline == null){
return null;
}
DataMediaPair dataMediaPair = null;
for(DataMediaPair pair :pipeline.getPairs()){
if(pair.getId().equals(pairId)){
dataMediaPair = pair;
}
}
if(dataMediaPair == null){
return null;
}
//为pipeline下该pair对应目标库表构建路由器
Set<SlotNode> slotSet = new TreeSet<SlotNode>();
String namespace = dataMediaPair.getTarget().getNamespace();
String tableName = dataMediaPair.getTarget().getName();
String nameSpacePrefix = ConfigHelper.getPrefix(namespace);
String tableNamePrefix = ConfigHelper.getPrefix(tableName);
if(nameSpacePrefix == null || tableNamePrefix == null){
return null;
}
for(DataMediaPair pair : pipeline.getPairs()){
String namespaceTemp = pair.getTarget().getNamespace();
String tableNameTemp = pair.getTarget().getName();
String nameSpaceTempPrefix = ConfigHelper.getPrefix(namespaceTemp);
String tableNameTempPrefix = ConfigHelper.getPrefix(tableNameTemp);
if(nameSpacePrefix.equals(nameSpaceTempPrefix) && tableNamePrefix.equals(tableNameTempPrefix)){
ModeValue dataSourceNames = ConfigHelper.parseMode(namespaceTemp);
ModeValue tableNames = ConfigHelper.parseMode(tableNameTemp);
if(dataSourceNames == null || tableNames == null){
continue;
}
DbMediaSource dbMediaSource = (DbMediaSource) pair.getTarget().getSource();
for(String dataSourceNameInPair : dataSourceNames.getMultiValue()){
for(String tableNameInPair : tableNames.getMultiValue()){
SlotNode slotNode = new SlotNode(dataSourceNameInPair,tableNameInPair);
slotNode.setUrl(dbMediaSource.getUrl());
slotNode.setDriver(dbMediaSource.getDriver());
slotNode.setEncode(dbMediaSource.getEncode());
slotNode.setGmtCreate(dbMediaSource.getGmtCreate());
slotNode.setGmtModified(dbMediaSource.getGmtModified());
slotNode.setId(dbMediaSource.getId());
slotNode.setName(dbMediaSource.getName());
slotNode.setPassword(dbMediaSource.getPassword());
slotNode.setProperties(dbMediaSource.getProperties());
slotNode.setType(dbMediaSource.getType());
slotNode.setUsername(dbMediaSource.getUsername());
slotSet.add(slotNode);
}
}
}
}
SlotRouter slotRouter = null;
//获取路由算法的参数,生成具体的路由算法
Integer slotAlgorithm = dataMediaPair.getSlotAlgorithm();
Long tableBalanceSize = dataMediaPair.getTableBalanceSize();
if(null== slotAlgorithm || SlotAlgorithmEnum.MODULO_BALANCE.getValue() == slotAlgorithm){
slotRouter = new ModuloBalanceSlotRouterBuilder(slotSet).build();
}else if(SlotAlgorithmEnum.QUOTIENT_BALANCE.getValue()==slotAlgorithm && tableBalanceSize != null){
slotRouter = new QuotientBalanceSlotRouterBuilder(slotSet,tableBalanceSize).build();
}else{
throw new RuntimeException("目前暂不支持该算法或者算法参数异常");
}
return slotRouter;
}
});
自由门集中控制
数据库的binlog也有删除策略,不可能永久保存所有的binlog。如何迁移binlog已经不存在的存量数据?
otter针对这种场景需求设计了自由门模块。详见otter中的自由门说明 。
自由门的原理如下:
a. 基于otter系统表retl_buffer,插入特定的数据,包含需要同步的表名,pk信息。
b. otter系统感知后会根据表名和pk提取对应的数据(整行记录),和正常的增量同步一起同步到目标库。
原先需要在每一个迁移的库所在实例建立retl.retl_buffer库表(存量数据迁移控制表)。当迁移的库比较多时,在多个实例上面分别建立retl库,不利于统一控制,同时给库表元数据管理带来一定的难度。为了后续DRC的统一快捷运维和减少运维成本,我们对自由门进行集中控制(不同实例上的数据迁移由同一个retl.retl_buffer库表控制)。通过在retl_buffer表上增加channel、pipeline两个字段,区分retl.retl_buffer库表中的数据属于不同的库表。然后在SelectTask阶段对数据进行分批整理 ,每批的管道改成同步管道信息。(统一控制相对单独控制存在一个风险点:如果同步的这批存量数据在Extract阶段后和Load阶段前存在源库数据对应记录的修改,同时修改的增量binlog又比存量同步的数据同步更快,存在数据老数据覆盖新数据的风险,不过这种场景概率极小)
//如果数据来自RETL库RETL_BUFFER表,将数据分批,每批的管道改成同步管道信息
if (StringUtils.equalsIgnoreCase(RETL_BUFFER, pipeline.getPairs().get(0).getSource().getName())
&& StringUtils.equalsIgnoreCase(RETL, pipeline.getPairs().get(0).getSource().getNamespace())) {
Long lastPipeLineId = null;
Long lastChannelId = null;
for (EventData data : eventData) {
// 获取每一条数据对应的pipeline
EventColumn pipelineColumn = getMatchColumn(data.getColumns(), PIPELINE_ID);
// 获取每一条数据对应的channelID
EventColumn channelColumn = getMatchColumn(data.getColumns(), CHANNEL_ID);
if(pipelineColumn == null || channelColumn == null){
logger.warn("data from RETL.RETL_BUFFER has no PIPELINE_ID OR CHANNEL_ID,the getKeys are {}",new Object[]{data.getKeys().toArray()});
continue;
}
Long pipeLineId = Long.valueOf(pipelineColumn.getColumnValue());
Long channelId = Long.valueOf(channelColumn.getColumnValue());
if (pipeLineId == null || channelId == null) {
continue;
}
//第一条数据,不发送
if (lastPipeLineId == null && lastChannelId == null) {
lastPipeLineId = pipeLineId;
lastChannelId = channelId;
rowBatch.merge(data);
continue;
}
//数据管道或通道有变化时,每个管道号数据作为一批发送
if (pipeLineId != lastPipeLineId || channelId != lastChannelId) {
// 构造唯一标识
Identity identity = new Identity();
identity.setChannelId(lastChannelId);
identity.setPipelineId(lastPipeLineId);
identity.setProcessId(etlEventData.getProcessId());
rowBatch.setIdentity(identity);
long nextNodeId = etlEventData.getNextNid();
List<PipeKey> pipeKeys = rowDataPipeDelegate.put(new DbBatch(rowBatch),
nextNodeId);
etlEventData.setDesc(pipeKeys);
etlEventData.setNumber((long) rowBatch.getDatas().size());
etlEventData.setFirstTime(startTime); // 使用原始数据的第一条
etlEventData.setBatchId(message.getId());
if (profiling) {
Long profilingEndTime = System.currentTimeMillis();
stageAggregationCollector.push(pipelineId, StageType.SELECT,
new AggregationItem(profilingStartTime, profilingEndTime));
}
arbitrateEventService.selectEvent().single(etlEventData);
rowBatch = new RowBatch();
}
lastPipeLineId = pipeLineId;
lastChannelId = channelId;
rowBatch.merge(data);
}
if(rowBatch!=null && rowBatch.getDatas() != null && rowBatch.getDatas().size()>0){
// 构造唯一标识
Identity identity = new Identity();
identity.setChannelId(lastChannelId);
identity.setPipelineId(lastPipeLineId);
identity.setProcessId(etlEventData.getProcessId());
rowBatch.setIdentity(identity);
long nextNodeId = etlEventData.getNextNid();
List<PipeKey> pipeKeys = rowDataPipeDelegate.put(new DbBatch(rowBatch),
nextNodeId);
etlEventData.setDesc(pipeKeys);
etlEventData.setNumber((long) rowBatch.getDatas().size());
etlEventData.setFirstTime(startTime); // 使用原始数据的第一条
etlEventData.setBatchId(message.getId());
if (profiling) {
Long profilingEndTime = System.currentTimeMillis();
stageAggregationCollector.push(pipelineId, StageType.SELECT,
new AggregationItem(profilingStartTime, profilingEndTime));
}
arbitrateEventService.selectEvent().single(etlEventData);
}
}
可以通过下面这个图来理解:
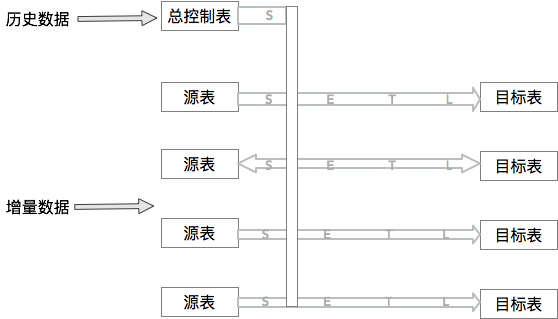
参考资料
https://yq.aliyun.com/articles/2350
http://eyuxu.iteye.com/blog/1941894
