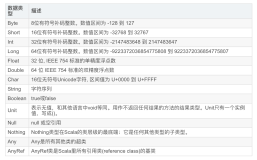
通常,我们希望能够在lambda表达式的闭合方法或类中访问其他的变量,例如:
package java8test;
public class T1 {
public static void main(String[] args) {
repeatMessage("Hello", 20);
}
public static void repeatMessage(String text,int count){
Runnable r = () -> {
for(int i = 0; i < count; i++){
System.out.println(text);
Thread.yield();
}
};
new Thread(r).start();
}
}
注意看lambda表达式中的变量count和text,它们并没有在lambda表达式中被定义,而是方法repeatMessage的参数变量。如果你思考一下,就会发现这里有一些隐含的东西。lambda表达式可能会在repeatMessage返回之后才运行,此时参数变量已经消失了。如果保留text和count变量会怎样呢?
为了理解这一点,我们需要对lambda表达式有更深入的理解。一个lambda表达式包括三个部分:
- 一段代码
- 参数
- 自由变量的值,这里的“自由”指的是那些不是参数并且没有在代码中定义的变量。
在我们的示例中,lambda表达式有两个自由变量,text和count。数据结构表示lambda表达式必须存储这两个变量的值,即“Hello”和20。我们可以说,这些值已经被lambda表达式捕获了(这是一个技术实现的细节。例如,你可以将一个lambda表达式转换为一个只含一个方法的对象,这样自由变量的值就会被复制到该对象的实例变量中)。
注意:含有自由变量的代码块才被称之为“闭包(closure)”。在Java中,lambda表达式就是闭包。事实上,内部类一直都是闭包。Java8中为闭包赋予了更吸引人的语法。
如你所见,lambda表达式可以捕获闭合作用域中的变量值。在java中,为了确保被捕获的值是被良好定义的,需要遵守一个重要的约束。在lambda表达式中,被引用的变量的值不可以被更改。例如,下面这个表达式是不合法的:
public static void repeatMessage(String text,int count){
Runnable r = () -> {
while(count > 0){
count--; //错误,不能更改已捕获变量的值
System.out.println(text);
Thread.yield();
}
};
new Thread(r).start();
}
做出这个约束是有原因的。更改lambda表达式中的变量不是线程安全的。假设有一系列并发的任务,每个线程都会更新一个共享的计数器。
int matches = 0;
for(Path p : files)
new Thread(() -> {if(p中包含某些属性) matches++;}).start(); //非法更改matches的值
如果这段代码是合法的,那么会引起十分糟糕的结果。自增操作matches++不是原子操作,如果多个线程并发执行该自增操作,天晓得会发生什么。
不要指望编译器会捕获所有并发访问错误。不可变的约束只作用在局部变量上,如果matches是一个实例变量或者闭合类的静态变量,那么不会有任何错误被报告出来即使结果同样未定义。同样,改变一个共享对象也是完全合法的,即使这样并不恰当。例如:
List<Path> matches = new ArrayList<>();
for(Path p: files)
//你可以改变matches的值,但是在多线程下是不安全的
new Thread(() -> {if(p中包含某些属性) matches.add(p);}).start();
注意matches是“有效final”的(一个有效的final变量被初始化后,就永远不会再被赋一个新值的变量)。在我们的示例中,matches总是引用同一个ArrayList对象,但是,这个对象是可变的,因此是线程不安全的 。如果多个线程同时调用add方法,结果将无法预测。
lambda表达式的方法体与嵌套代码块有着相同的作用域。因此它也适用同样的命名冲突和屏蔽规则。在lambda表达式中不允许声明一个与局部变量同名的参数或者局部变量。
Path first = Paths.get("/usr/bin");
Comparator<String> comp = (first,second) ->
Integer.compare(first.length(),second.length());
//错误,变量first已经定义了
在一个方法里,你不能有两个同名的局部变量,因此,你也不能在lambda表达式中引入这样的变量。
当你在lambda表达式中使用this关键字,你会引用创建该lambda表达式的方法的this参数,以下面的代码为例:
public class Application{
public void doWork(){
Runnable runner = () -> {....;System.out.println(this.toString());......};
}
}
表达式this.toString()会调用Application对象的toString()方法,而不是Runnable实例的toString()方法。在lambda表达式中使用this,与在其他地方使用this没有什么不同。lambda表达式的作用域被嵌套在doWork()方法中,并且无论this位于方法的何处,其意义都是一样的。