前几天给大家分享了如何利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例,感兴趣的小伙伴可以点击链接进行查看。今天小编给大家介绍如何利用Python网络爬虫抓取微信好友的省位和城市,并且将其进行可视化,具体的教程如下。
爬取微信好友信息,不得不提及这个itchat库,简直太神奇了,通过它访问微信好友基本信息可谓如鱼得水。下面的代码是获取微信好友的省位信息:
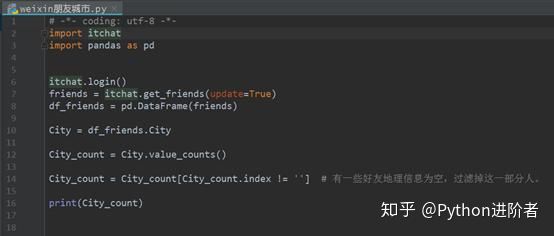
程序运行之后,需要扫描进行授权登录,之后在Pycharm的控制台上会出现如下图的红色提示,这些红色的字体并不是我们通常遇到的Python程序运行报错,属于正常的状态,不用太理会。大意是提示你要用手机扫描下载过来的二维码;确认授权;加载通讯录好友信息;登录成功。之后就会将程序中所需要的内容打印出来,如下图所示:
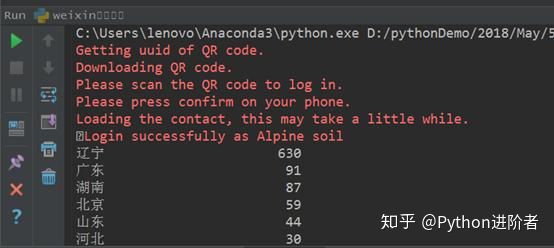
将打印出来的内容放到记事本中,如下图所示:

可以看到小编的大部分好友都是在中国,而且辽宁的朋友最多,其次是广东省和湖南省的好友居多,可以知道小编是和这三个地方结缘了。下图中展示的省位好友数量并没有那么多,除了青海之外,全部都是国外的城市或国家名称,说明小编的青海朋友并不多,希望可以多交几位青海省的朋友。另外经过统计,小编还发现自己并没有云南、海南和甘肃的朋友,希望可以和这几个地方的伙伴们做个朋友 ~

下图展示的是对好友的地图可视化,具体的实现可以参考这篇文章:Python大佬批量爬取中国院士信息,告诉你哪个地方人杰地灵,在此就不再赘述。
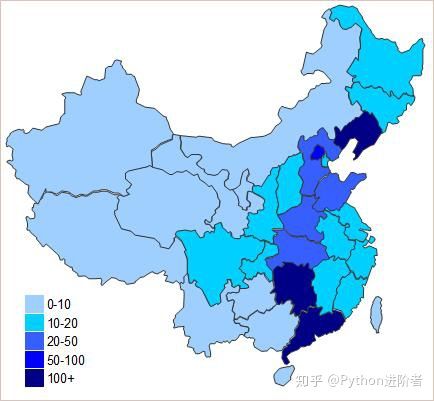
可以看到颜色较深的省位是辽宁省、广东省和湖南省,说明这三个省位小编的好友较多。
接下来继续写代码,抓取微信好友所在的城市,如下图所示:
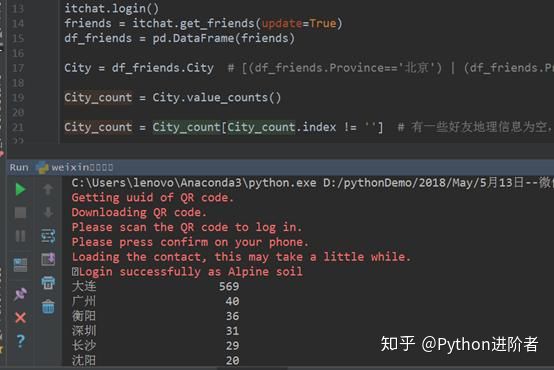
这里代码和程序运行的截图都放到一起了,在此对于红色字体就不再赘述了。就打印出来的信息可以看到,小编的微信好友中大连的朋友最多,其实是广东省的朋友,如广州和深圳,再就是湖南省的朋友了,如衡阳和长沙。
将微信好友城市分布拷贝到记事本中,可以更加清楚的看到好友的分布,如下图所示:
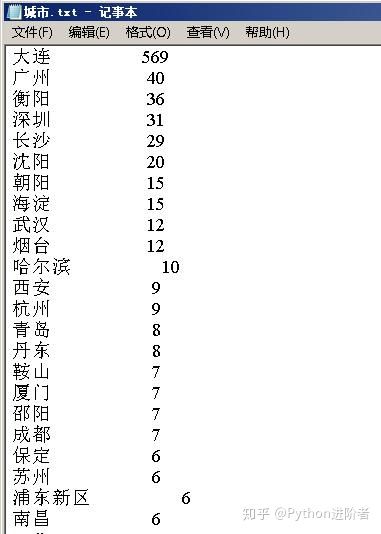
还有部分城市如下图所示:
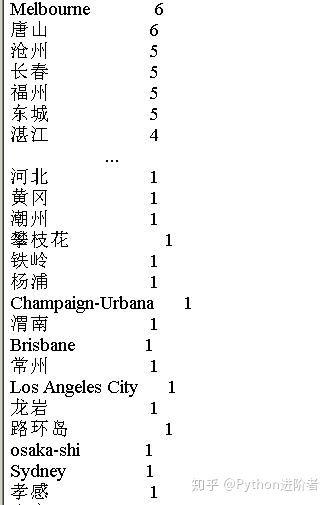
还有一些地区就不再多粘贴出来了。另外,感兴趣的小伙伴可以将城市统计汇总,之后将其做个地图可视化,可以尝试一下噢~~
^_^小编最后祝大家周末愉快^_^



